Logstash filter 的插件使用
Logstash filter的使用
一句话就是 通过 logstash 对日志进行格式化(过滤)。
logstash有三个插件 input (接收数据源的数据)、filer(实现数据格式化) 、output(输出到目标)。
Filter插件(过滤器插件)可以实现如: 数据解析、删除字段、类型转换等等统称名词 实现数据格式化
常见的有如下几个:
grok:正则匹配解析
date:日期解析
dissect:对字段做处理,如:重命名、删除、替换等
json:安装 json 解析字段内容到指定字段中
geoip:增加地理位置数据
ruby:利用 ruby 代码来动态修改 Logstash Event
Grok插件
grok是一个十分强大的logstash filter插件,通过正则解析任意文本,将非结构化日志数据解析成结构化和方便查询的结构内容,将其定义成我们平时容易理解的一些字段名称。
使用 grok filter 需要在 logstash 的配置文件中加上这样的内容:
filter {
grok {
match => {
"message" => "grok_pattern"
}
}
}
这段代码中除了 gork_pattern (grok 表达式) 意外都是 logstash 的关键字固定书写, grok_pattern部分需要使用者填充自己的解析方式。
grok_oattern 由零个或多个%{SYNTAAX:SEMANTIC}组成
SYNTAX是表达式的名字,即文本匹配的模式的名称,是由grok提供的,例如:数字的表达式名字式 NUMBER,IP地址表达式名字是 IP
SEMANTIC 给匹配解析出的数据起的字段名,提供一个标识自己定义字段名
例如:IP字段的名字可以是client, %{ IP:client} 表达式 :定义字段名
对下面这条日志解析:
192.168.1.2 GET /index.html 15824 0.043
可以这样解析:

将会得到这样的结果:
* client: 192.168.1.2
* method: GET
* request: /index.html
* bytes: 15824
* duration: 0.043
数字表达式名字是NUMBER,%{NUMBER:duration}可以匹配数值类型,但是grok匹配出的内容都是字符串类型,可以在最后指定为 int (整数类型)或者 float (浮点数)来强制转换,
%{NUMBER:duration:float}
数据类型目前只支持两个值: int 和 float
查看文件 grok-patterns,查看 grok 默认提供的表达式,默认放在路径 /usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/ 目录下
测试:
创建一个测试文件,test.conf
vim /usr/local/logstash-7.3.0/config/test.confinput {stdin{}}
filter {
grok {
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
output {stdout{codec => rubydebug}}使用 test.conf 启动一个logstash 实例,通过键盘输入如下内容:
192.168.30.12 GET /index.html 15824 0.043
logstash -f /usr/local/logstash-7.3.0/config/test.conf --path.data=/aa 注:当本机运行了logstash实例,则在运行一个实例需要加 --path.data=指向一个目录
查看屏幕输出:
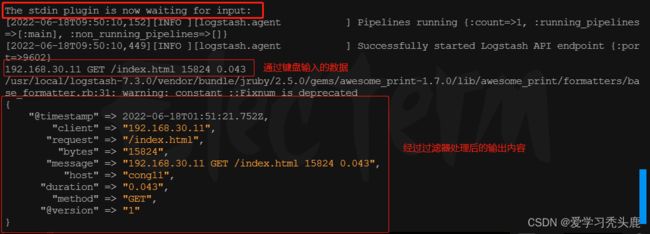
默认 grok 调用的是:
/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/这个目录下的正则
如何自定义表达式
假如要匹配正则表达式为 regexp的字符串, grok 预定义的SYNTAX (表达式)不满足,可以自定义一个表达式。
1)直接在 grok 里面使用自定义表达式
语法格式: (?
?
例如:定制化字段,取出想要的字段
“10.15 beijing sunny”,然后取出每一个字段
编辑test.conf文件,内容如下:
vim /usr/local/logstash-7.3.0/config/test.conf input {stdin{}}
filter {
grok {
match => { "message" => "(?\d+\.\d+)\s+(?\w+)\s+(?\w+)"
}
}
}
output {stdout{codec => rubydebug}} 反斜杠d \d :代表任意一个数字,
+:代表至少一个或多跟
\w:代表匹配单词,包括单词中带有下划的
\s: 匹配任何不可见字符,包括空格、制表符、换页符等等
运行logstash,输入“10.15 beijing sunny”内容,并查看输出结果
logstash -f /usr/local/logstash-7.3.0/config/test.conf --path.data=/aa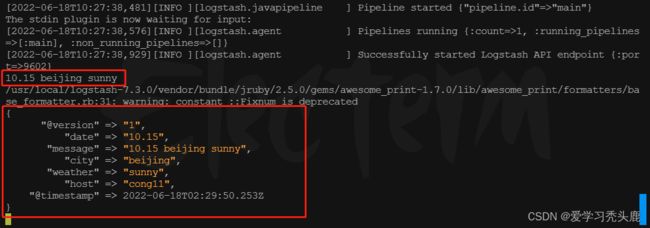
(2)自定义表达式文件
在某个目录下创建一个文件,文件名自定义,如在/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/目录下创建正则表达式文件test
将目录加入grok路径: patterns_dir => "./patterns"
将想要增加的正则表达式写入,格式: SYNTAX_NAME regexp。 前面是表达式的名字,后面是具体的表达式
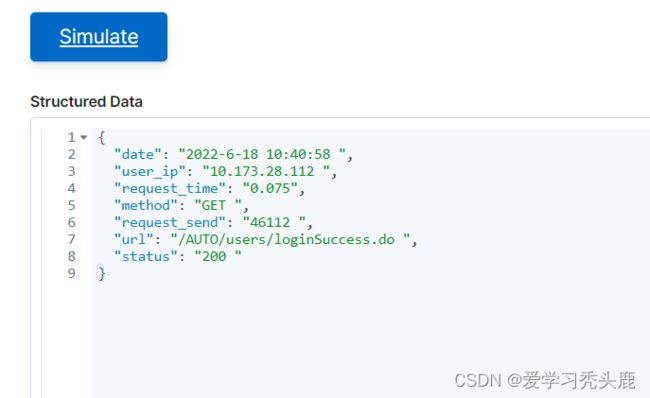
例如:使用grok自定义正则去匹配下边的日志
10.173.28.112 2018-11-22 16:30:58 GET /AUTO/users/loginSuccess.do 200 46112 0.075
在/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/目录下创建正则表达式文件test.
/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns
vim testUSER_IPADDRESS ([0-9\.]+)\s+
DATETIME ([0-9\-]+\s[0-9\:]+)\s+
METHOD ([A-Z]+)\s+
URL ([\/A-Za-z0-9\.]+)\s+
STATUS ([0-9]+)\s+
REQUEST_SEND ([0-9]+)\s+
REQUEST_TIME ([0-9\.]+)注:为了看测试效果。这种书写表达式过于简单,并不严谨
编辑logstash配置文件test.conf文件:
vim /usr/local/logstash-7.3.0/config/test.conf input {stdin{}}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{USER_IPADDRESS:user_ip} %{DATETIME:date} %{METHOD:method} %{URL:url} %{STATUS:status} %{REQUEST_SEND:request_send} %{REQUEST_TIME:request_time}"
}
}
}
output {stdout{codec => rubydebug}}运行logstash 程序 查看输出结果
logstash -f /usr/local/logstash-7.3.0/config/test.conf --path.data=/aa 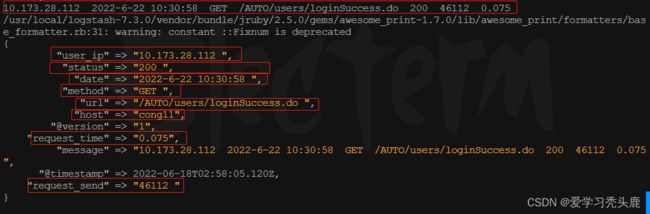
总结:
grok 是通过系统预定义的正则表达式或通过自己定义 正则表达式来匹配日志中的各个值 。
正则解析式比较容易出错,Kibana提供了 grok debbuger调试工具
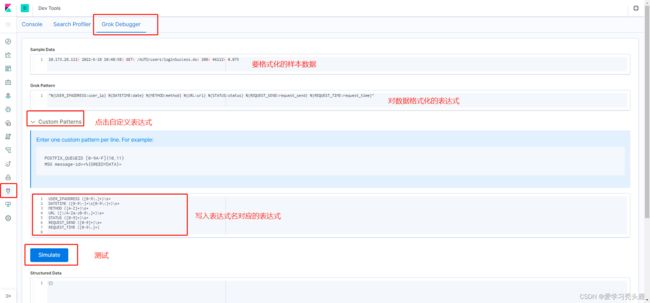
 使用Grok Filter 插件编辑解析 nginx 日志
使用Grok Filter 插件编辑解析 nginx 日志
Grok插件使用详解:
Grok filter plugin | Logstash Reference [8.2] | Elastic
nginx 日志格式
log_format 配置如下:
vim /usr/local/nginx/conf/nginx.conf 打开nginx访问日志,取消注释
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;$remote_addr变量:记录了客户端的IP地址(普通情况下)
$remote_user变量:当nginx开启了用户认证功能后,此变量记录了客户端使用了哪个用户进行了认证
$time_local变量:记录了当前日志条目的时间
$request变量:记录了当前http请求的方法、url和http协议版本
$status变量:记录了当前http请求的响应状态,即响应的状态码,比如200、404等响应码,都记录在此变量中
$body_bytes_sent变量:记录了nginx响应客户端请求时,发送到客户端的字节数,不包含响应头的大小
$http_referer变量:记录了当前请求是从哪个页面过来的,比如你点了A页面中的超链接才产生了这个请求,那么此变量中就记录了A页面的url
$http_user_agent变量:记录了客户端的软件信息,比如,浏览器的名称和版本号
$http_x_forwarded_for变量:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项
编写正则表达式
在 logstash中默认存在一部分正则让我们来使用
/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/
在 grok-patterns 预定义变量中,我们可是使用 其中的正则,但并不是都适合 nginx 字段,我们需自定义正则,通过指定 patterns_dir来调用。
同时在写正则的时候可以使用Grok Debugger或者Grok Comstructor工具来帮助我们更快的调试。在不知道如何使用logstash中的正则的时候也可使用Grok Debugger的Descover(https://grokdebug.herokuapp.com)来自动匹配。(注意网络是否通,需要墙)
我这里编写了一个符合这台nginx服务器的日志过滤器:
对nginx访问日志做格式化的正则表达式文件
cd /usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/
vim nginx-accessNGINXACCESS %{IP:clientip} - (%{USERNAME:user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{NOTSPACE:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status:int} %{NUMBER:body_sent:int} \"-\" \"%{GREEDYDATA:agent}\" \"-\"编写logstash配置文件
Logstash基本格式 input >> codec >> filter >> codec >> output
codec用于文件编码格式转换(字符集)
配置 logstsh
vim /usr/local/logstash-7.3.0/config/http_logstash.conf input{
kafka {
codec => "json" #指明codec为json,因为logstash从kafka读取的日志是json格式
bootstrap_servers => "192.168.1.13:9092"
client_id => "nginx_logs"
group_id => "nginx_logs"
consumer_threads => 5
auto_offset_reset => "latest"
decorate_events => true
topics => "nginx_logs"
}
}
filter {
grok {
patterns_dir => "/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns"
match => { "message" => "%{NGINXACCESS}" }
remove_field => "message" #过滤后丢弃原有信息
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.1.11:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}
注:remove_field 它 的作用就是去重,过滤后将源日志信息丢弃,这样避免了两份日志信息,过滤的目的就是筛选出对我们有用的信息,重复的不要
重启logstash
jps -m
kill 1798
nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf --path.data=/tmp &
查看输出内容:
tail -0f nohup.out访问nginx默认测试页

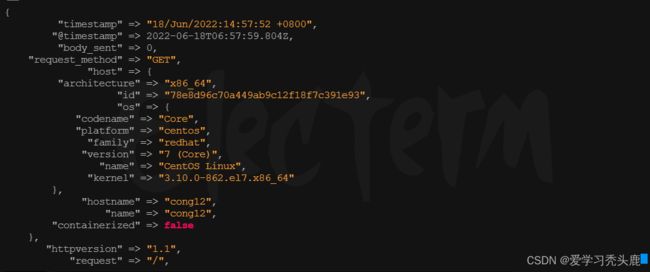 打开kibana页面查看日志数据:
打开kibana页面查看日志数据:
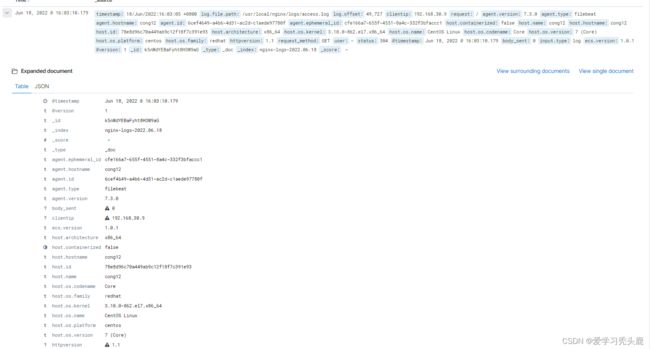
date 插件
在上面例子中 timestamp 字段,表示日志生产时间,还有一行是@timestamp信息,这两个时间是不一样的, timestamp代表日志产生时间,@timestamp代表写入ES的时间两个都是时间戳
@timestamp字段会被elasticsearch用到,用来标注日志的生产时间,如此一来,日志生成时间就会发生混乱,需要用到 date 插件,将@timestamp写入时间和产生时间保持一致
修改logstash配置文件:
在 filter 下加入 date插件
注:确保同一级的是左对齐的
vim /usr/local/logstash-7.3.0/config/http_logstash.conf input{
kafka {
codec => "json"
bootstrap_servers => "192.168.30.13:9092"
client_id => "nginx_logs"
group_id => "nginx_logs"
consumer_threads => 5
auto_offset_reset => "latest"
decorate_events => true
topics => "nginx_logs"
}
}
filter {
grok {
patterns_dir => "/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns"
match => { "message" => "%{NGINXACCESS}" }
remove_field => "message"
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.30.11:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}注意:时区偏移量需要用一个字母Z来转换。还有这里的“dd/MMM/yyyy”,你发现中间是三个大写的M,需固定书写 我尝试只写两个M的话,转换失败
重新启动 logstash

nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf --path.data=/tmp &上kibana 查看时间是否转换成功
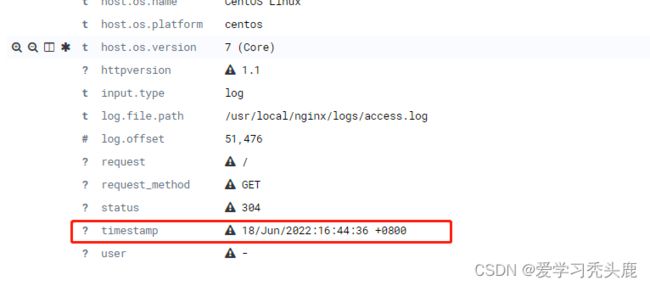
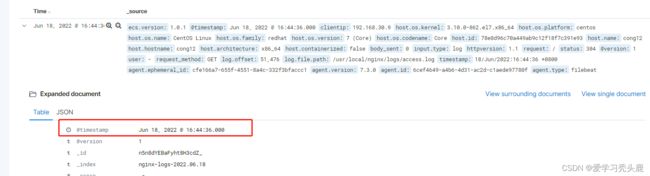 @timestamp时间转换成功
@timestamp时间转换成功
如果你要解析你的时间,你要使用字符来代替,用于解析日期和时间文本的语法使用字母来指示时间(年、月、日、时、分等)的类型。以及重复的字母来表示该值的形式。在上面看到的"dd/MMM/yyy:HH:mm:ss Z",他就是使用这种形l式,我们列出字符的含义
Geoip Filter
geoip是常见的免费的IP地址归类查询库,geoip可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等等,此插件对于可视化地图和区域统计非常有用
geoip插件配置要求指定包含IP地址来查找源字段的名称。在此示例中,该clientip字段包含IP地址
由于过滤器是按顺序进行评估,确保该geoip部分是在grok配置文件之后,无论是grok和geoip部分嵌套在内部filter部分
添加groip插件
input{
kafka {
codec => "json"
bootstrap_servers => "192.168.1.13:9092"
client_id => "nginx_logs"
group_id => "nginx_logs"
consumer_threads => 5
auto_offset_reset => "latest"
#decorate_events => true
topics => "nginx_logs"
}
}
filter {
grok {
patterns_dir => "/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns"
match => { "message" => "%{NGINXACCESS}" }
#match => { "message" => "%{COMBINEDAPACHELOG}" }
remove_field => "message"
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
}
output {
stdout {
#codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.1.11:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}
重新启动logstash
nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf &到nginx服务器上 模拟客户端访问插入测试数据:
echo '61.135.169.125 - - [18/Jun/2022:17:42:05 +0800] "GET /index.html HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0" "-"'>> /usr/local/nginx/logs/access.log我们这里填写一个百度的IP,进行测试
到logstash查看一下日志:
cat nohup.out 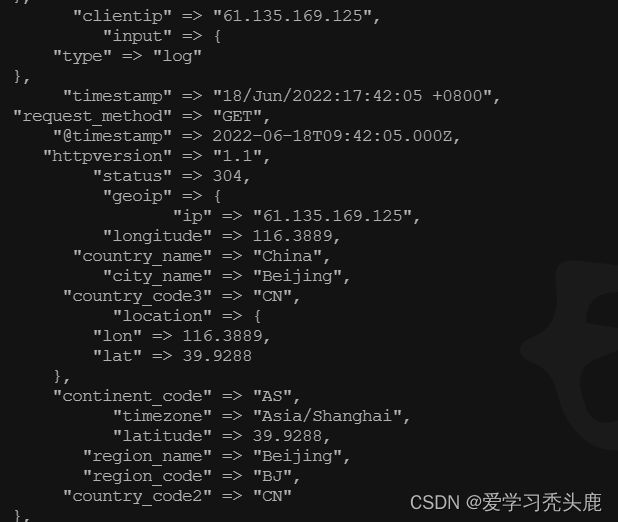
解析到的 IP 地址是中国,北京 就成功了
Logstash支持的插件
除了上面提供的grok,geoip,date插件外,官方还提供了很多logstash过滤插件,点击插件,里面有每个插件的详细解释。请查看连接。
