Spark_DataFrame创建及使用
标题
-
-
- DataFrame创建
-
-
- 1.通过sparkSession构建DataFrame
- 2.通过RDD配合case class进行转换DF
- 3.通过DataSet调用.toDF进行转换DF
-
- DataFrame的使用
-
-
- 1.DSL风格语法
- 2.SQL风格语法
-
-
DataFrame创建
1.通过sparkSession构建DataFrame
1、读取文本文件
val personDF2 = spark.read.text("file:///export/servers/person.txt")
2、读取json文件创建DataFrame
val jsonDF = spark.read.json("file:///export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/src/main/resources/people.json")
3、读取parquet列式存储格式文件创建DataFrame
val parquetDF = spark.read.parquet("file:///export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/src/main/resources/users.parquet")
2.通过RDD配合case class进行转换DF
创建文本文件:
cd /export/servers/
vim person.txt
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
定义RDD
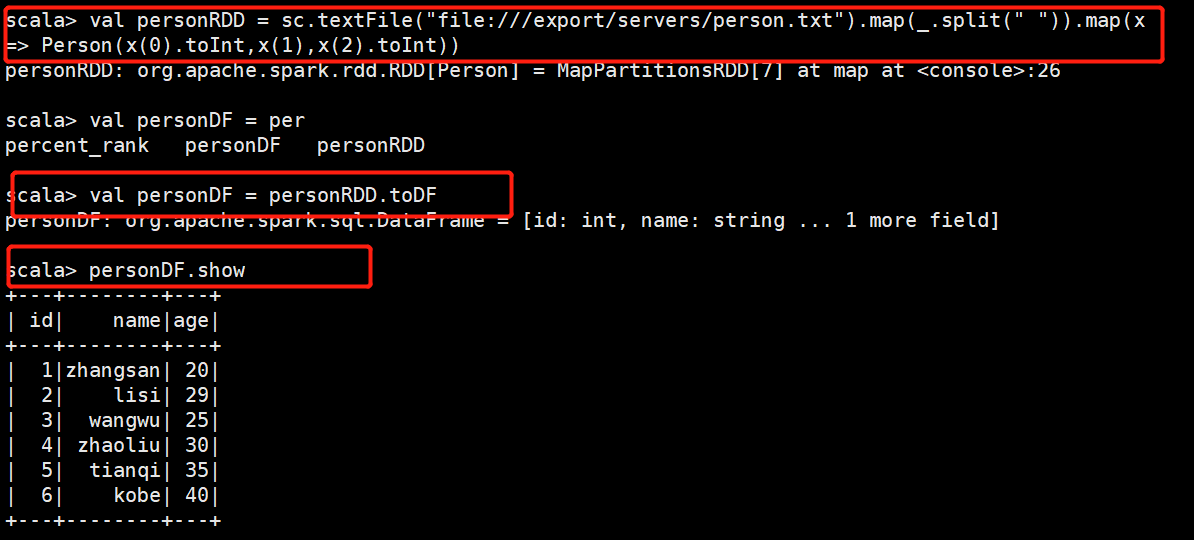
val lineRDD = sc.textFile("file:///export/servers/person.txt").map(x => x.split(" "))
定义case class样例类
case class Person(id:Int,name:String,age:Int)
关联RDD与case class
val personRDD = lineRDD.map(x => Person(x(0).toInt,x(1),x(2).toInt))
将RDD转换成DF
val personDF = personRDD.toDF
3.通过DataSet调用.toDF进行转换DF
都是调用.toDF方法
val personDF = personDS.toDF
DataFrame的使用
1.DSL风格语法
查看DataFrame当中的数据
调用show方法
personDF.show
查看DataFram当中部分字段的数据:
查看字段:
第一种方式:personDF.select(personDF.col("name")).show

第二种方式:personDF.select("name").show
第三种方式:personDF.select(col("name"),col("age")).show
第四种方式:personDF.select($"name",$"age").show
打印DataFrame的Schema信息:
personDF.printSchema

查询所有的name和age,并将age+1:
personDF.select(col("id"), col("name"), col("age") + 1).show或者
personDF.select(personDF("id"), personDF("name"), personDF("age") + 1).show

过滤age大于等于25的,使用filter方法过滤:
personDF.filter(col("age") >= 25).show
统计年龄大于30的人数:
personDF.filter(col("age")>30).count()
按年龄进行分组并统计相同年龄的人数:
personDF.groupBy("age").count().show
2.SQL风格语法
1、将DataFrame注册成表
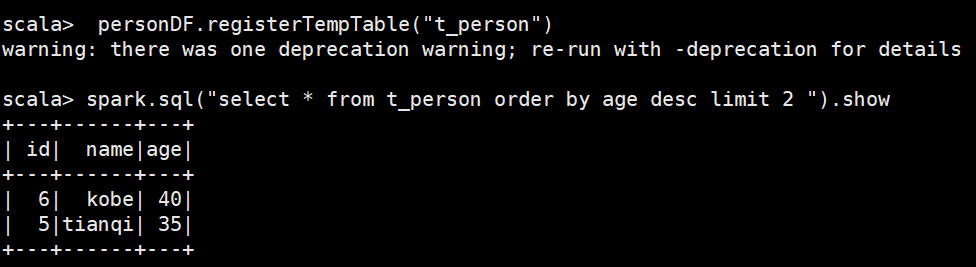
personDF.registerTempTable("t_person")
2、查询年龄最大的前两名
spark.sql("select * from t_person order by age desc limit 2 ").show
3、显示表的Schema信息
spark.sql("desc t_person").show
4、查询年龄大于30的人的信息
spark.sql("select * from t_person where age > 30").show