ABAP程序间数据共享与传递
ABAP提供了IMPORT/EXPORT 和 SET/GET PARAMETER语句,可对用户内存/服务器内存/数据库进行存储和访问。
EXPORT 语句
EXPORT {p1 = dobj1 p2 = dobj2 ...} | {p1 FROM dobj1 p2 FROM dobj2 ...} | (ptab)
TO | { MEMORY ID id }
| { DATABASE dbtab(ar) [FROM wa] [CLIENT cl] ID id }
| { SHARED MEMORY dbtab(ar) [FROM wa] [CLIENT cl] ID id }
| { SHARED BUFFER dbtab(ar) [FROM wa] [CLIENT cl] ID id }
1.{p1 = dobj1 p2 = dobj2 …}与 {p1 FROM dobj1 p2 FROM dobj2 …}的意义一样,只是写法不一样,dobj1、dobj2…变量将会以p1、p2…名称存储到内存或数据库中。p1、p2…名称随便取,如果p1、p2…与将要存储的变量名相同时,只需写变量名即可,即等号与 FROM 后面可以省略。p1、p2…这些名称必须与IMPORT语句中相一致,否则读取不出
2.(ptab):为动态指定需要存储的变量,ptab内表结构要求是这样的:只需要两列,列名任意,但类型需要是字符型;第一列存储如上面的p1、p2…名称,第二列为上面的dobj1、dobj2…变量,如果变量与名称相同,则也可以像上面一样,省略第二列的值。两列的值都必需要大写,实例如下:
TYPES:BEGIN OF tab_type,
para TYPE string,"列的名称任意,类型为字符型
dobj TYPE string,
END OF tab_type.
DATA:text1 TYPE string VALUE `TXT1`,
text2 TYPE string VALUE `TXT2`,
line TYPE tab_type,
itab TYPE STANDARD TABLE OF tab_type.
line-para = 'P1'."值都需要大写
line-dobj = 'TEXT1'."值都需要大写
APPEND line TO itab.
line-para = 'P2'.
line-dobj = 'TEXT2'.
APPEND line TO itab.
EXPORT (itab) TO MEMORY ID 'TEXTS'.
IMPORT p1 = text2 p2 = text1 FROM MEMORY ID 'TEXTS'.
WRITE: / text1,text2."TXT2 TXT1
CLEAR: text1,text2.
IMPORT (itab) FROM MEMORY ID 'TEXTS'.
WRITE: / text1,text2."TXT1 TXT2
3.MEMORY ID:将变量存储到ABAP Memory内存中
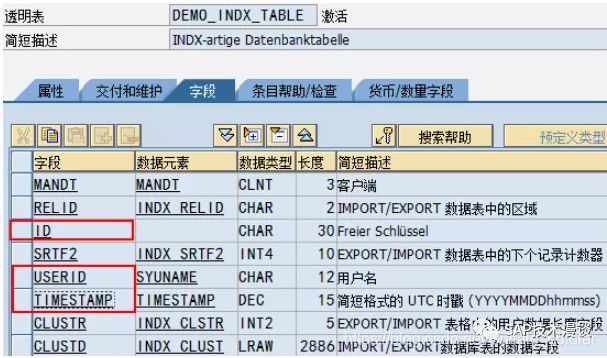
4.DATABASE:将变量存储到数据库中;dbtab为簇数据库表的名称(如系统提供的标准表INDX);ar的值为区域ID,它将数据库表的行分成若干区域,它必须被直接指定,且值是两位字符,被存储到簇数据库表中的RELID字段中;id 的值会存储到簇数据表中的RELID字段的下一用户自定义字段中:
TYPES:BEGIN OF tab_type,
col1 TYPE i,
col2 TYPE i,
END OF tab_type.
DATA:wa_indx TYPE demo_indx_table,
wa_itab TYPE tab_type,
itab TYPE STANDARD TABLE OF tab_type.
WHILE sy-index < 100.
wa_itab-col1 = sy-index.
wa_itab-col2 = sy-index ** 2.
APPEND wa_itab TO itab.
ENDWHILE.
wa_indx-timestamp = sy-datum && sy-uzeit.
wa_indx-userid = sy-uname.
EXPORT tab = itab TO DATABASE demo_indx_table(sq) FROM wa_indx ID 'TABLE'.

5.SHARED MEMORY/BUFFER :将数据存储到SAP应用服务器上的SAP Memory中,可共同一服务上的所有程序访问。两种的作用是一样的,最大不同是在数据达到最大内存限制时的处理方式不同:最大内存限制值分别是通过rsdb/esm/buffersize_kb (SHARED MEMORY)、rsdb/obj/buffersize (SHARED BUFFER)来设置的,当内存占用快满时,SHARED MEMORY必须通过DELETE FROM SHARED MEMORY来手动清理,而SHARED BUFFER会自动删除很少被使用到的数据(当然也可以通过DELETE FROM SHARED BUFFER手动及时的删除不用的数据)
6.FROM wa:wa工作区类型可以参照簇数据库dbtab类型,也可定义成只含有用户数据字段的结构,它是用来设置簇数据库表中SRTF2 与 CLUSTR两个字段之间的用户数据字段(参见簇数据表图中的编号为5的用户数据)的值,然后在Export时将相应的字段存储到SRTF2字段与CLUSTR字段间的相应字段中去。如果使用“TABLES dbtab.”定义语句,可以省略“[FROM wa]”,也会默认将其存储到数据库表中,但如果没有“TABLES dbtab.”这样的定义语句,也没有“[FROM wa]”选项时,将不会有数据存储到簇数据库表中的用户字段中去
7.CLIENT cl:默认为当前客户端,存储到簇数据库表中的MANDT字段中
IMPORT 语句
IMPORT {p1 = dobj1 p2 = dobj2 ...} | {p1 TO dobj1 p2 TO dobj2 ...} | (ptab)
FROM | { MEMORY ID id }
| { DATABASE dbtab(ar) [TO wa] [CLIENT cl] ID id }
| { SHARED MEMORY dbtab(ar) [TO wa] [CLIENT cl] ID id }
| { SHARED BUFFER dbtab(ar) [TO wa] [CLIENT cl] ID id }
从簇数据表中读取数据,各项参数与EXPORT是一样的,请参考EXPORT各项解释
TYPES:BEGIN OF tab,
col1 TYPE i,
col2 TYPE i,
END OF tab.
DATA:wa_indx TYPE demo_indx_table,
wa_itab TYPE tab,
itab TYPE STANDARD TABLE OF tab.
IMPORT tab = itab FROM DATABASE demo_indx_table(sq) TO wa_indx ID 'TABLE'.
WRITE: wa_indx-timestamp, wa_indx-userid.
ULINE.
LOOP AT itab INTO wa_itab.
WRITE: / wa_itab-col1, wa_itab-col2.
ENDLOOP.
DELETE FROM语句
DELETE FROM { {MEMORY ID id}
| {DATABASE dbtab(ar) [CLIENT cl] ID id}
| {SHARED MEMORY dbtab(ar) [CLIENT cl] ID id}
| {SHARED BUFFER dbtab(ar) [CLIENT cl] ID id} }.
用来清理EXPORT语句的存储的数据
其中DELETE FROM MEMORY ID id.与FREE MEMORY ID id.作用一样
DATA: id TYPE c LENGTH 4 VALUE 'TEXT',
text1 TYPE string VALUE 'Tina',
text2 TYPE string VALUE 'Mike'.
EXPORT p1 = text1 p2 = text2 TO SHARED BUFFER demo_indx_table(xy) ID id.
IMPORT p1 = text2 p2 = text1 FROM SHARED BUFFER demo_indx_table(xy) ID id.
...
DELETE FROM SHARED BUFFER demo_indx_table(xy) ID id.
"此语句会执行后,sy-subrc返回4
IMPORT p1 = text2 p2 = text1 FROM SHARED BUFFER demo_indx_table(xy) ID id.
ABAP Memory(同一用户的同一窗口Session)
保存数据
EXPORT[FROM ] [FROM ] ... TO MEMORY ID .
如果省略了FROM 选项,则被存储的数据源就来自于程序中与f1自已同名的变量,否则数据源为g1指定的变量(或者g1本身就是字符常量);key 用来标示ABAP内存。可以将多个变量存储在同一个中,它们是通过来区别的。IMPORT中的必须与EXPORT中的名称相同。
DATA text1(10) VALUE 'Exporting'.
DATA itab LIKE sbook OCCURS 10 WITH HEADER LINE.
DO 5 TIMES.
itab-bookid = 100 + sy-index.
APPEND itab.
ENDDO.
"将 text1 与 text2都存储到 text ID的名下
EXPORT text1 "数据来源于上面定义的 text1变量,并以text1名分类存储
text2 FROM 'Literal'"数据直接来源于From后面指定的常量字符串,也以text1名分类存储
TO MEMORY ID 'text'.
"将前面定义的itab存储到以table为ID的内存中,并以itab名分类存储
EXPORT itab TO MEMORY ID 'table'.
读取数据
IMPORT [TO ] [TO ] ... FROM MEMORY ID .
如果忽略选项TO,则将内存中的数据对象赋给程序中的同名数据对象;如果使用此选项,则将内存中的数据对象写入字段中。IMPORT中的必须与EXPORT中的名称相同。
不必读取存在特定ID下的所有对象,在读取时可以通过指定名称中进行有选择性的读取。如果内存中不包含指定ID下的对象,则将SY-SUBRC设置为4,但是如果内存中存在带此ID的数据簇,无论数据对象是否也存在,SY-SUBRC之值总是为0。如果簇中不存在数据对象,则目标字段保持不变(gi或fi本身)。
DATA text1(10) VALUE 'TEST1'.
DATA itab LIKE sbook OCCURS 10 WITH HEADER LINE.
DO 5 TIMES.
itab-bookid = 100 + sy-index.
APPEND itab.
ENDDO.
EXPORT text1"被存储的数据来自text1变量
text2 FROM 'Literal'"被存储的数据直接来自FORM后面字符串常量
"将'TEST1'与'Literal'存储到ID为text的ABAP内存中,并且分别以
"text1和text2标签来分类存储
TO MEMORY ID 'text'.
EXPORT itab"被存储的数据来自itab变量所对应的内存
TO MEMORY ID 'table'.
SUBMIT zjzjimpt1 AND RETURN."调用其他程序并等待返回
REPORT zjzjimpt1.
DATA: text1(10),
text3 LIKE text1.
"从ID为text的ABAP内存区域读取分类存储标签为text1
"的内存数据并存储到text1变量中去
IMPORT text1 FROM MEMORY ID 'text'.
WRITE: / sy-subrc, text1.
"从ID为text的ABAP内存区域读取分类存储标签为text2
"的内存数据并存储到text3变量中去
IMPORT text2 TO text3 FROM MEMORY ID 'text'.
WRITE: / sy-subrc, text3.
DATA jtab LIKE sbook OCCURS 10 WITH HEADER LINE.
"从ID为table的ABAP内存区域读取分类存储标签为itab
"的内存数据并存储到jtab变量中去
IMPORT itab TO jtab FROM MEMORY ID 'table'.
LOOP AT jtab.
WRITE / jtab-bookid.
ENDLOOP.
删除数据
FREE MEMORY [ID ].
与DELETE FROM MEMORY ID id.等效
如果不附加ID,则此语句删除整个内存,包括此前用EXPORT存储到ABAP/4内存中的所有数据簇。附加ID之后,该语句只删除用此名称命名的数据簇。
用户登陆后,最多一个系统可以开6个窗口,这在SAP中称为External Mode。而同一个窗口中,运行某程序后,可以通过CALL TRANSACTION/SUBMIT或其他代码跳转到其他程序,这个称为Internal Mode。Internal Mode的调用栈最多为9层。那么ABAP Memory,它是属于Internal Mode间可以共享的数据,而External Mode间无法共享。所以,ABAP Memorcy只能在同一窗体中共享,这与浏览器中的Session是一样的。
SAP Memory(同一用户的不同窗口Session)
同一客户端的不同窗体(External Mode)它们之间共享数据必须通过SET/GET PARAMETER语句,不再是EXPORT/IMPORT的模式。
例子. 创建程序A,输入:
DATA matnr TYPE matnr.
GET PARAMETER ID 'ytest' FIELD matnr.
WRITE matnr.
创建程序B,输入:
DATA: matnr TYPE matnr.
matnr = '000000000000012345'.
SET PARAMETER ID 'YTEST' FIELD matnr.
在窗口1运行程序B并关闭后,在窗口2运行程序A,发现程序A仍然读到了SAP Memory的值。
说明:
1、调试时,可通过点击Goto->System Area->SAP Memory,查看到YTEST及其对应的值。
2、SET/GET PARAMETER的值与本次登陆有关,当用户注销后才失效。在用户登陆的时候,系统会根据每个用户System->User Profile->Own Data->Parameter下的设置,载入到SAP Memory。
3、在Data Element中可以看到Further Characteristics下可定义PARAMETER ID,代表该字段作为屏幕元素时,可读取该PARAMETER ID作为默认值。比如VA03会自动显示刚刚创建的订单号。
SHARED MEMORY/SHARED BUFFER(不同Client、Job)
前面介绍的都是用户内存,那么不同用户间如何实现数据共享呢?可以用SHARED MEMORY或SHARED BUFFER,它们是服务器上的某片所有用户共享的内存。关于SHARED MEMORY和SHARED BUFFER的区别,可以F1查看帮助。如果EXPORT SHARED BUFFER,则必须IMPORT SHARED BUFFER才能读到,用IMPORT SHARED MEMORY是读不到的。反过来也是。
例子. 创建程序A,输入:
DATA matnr TYPE matnr.
IMPORT matnr FROM SHARED BUFFER indx(aa) ID 'YTEST_MATNR '.
WRITE matnr.
创建程序B,输入:
DATA: matnr TYPE matnr.
matnr = '000000000000123456'.
EXPORT matnr TO SHARED BUFFER indx(aa) ID 'YTEST_MATNR'.
先在用户1的电脑上运行程序B,然后在用户2的电脑上运行程序A,发现用户2可以读取到值。
说明:
1、既然是服务器上的所有用户共享空间,那么该值将保存到服务器关机重启为止,除非用户用DELETE语句清除它。其实这个跟ENQUEUE/DEQUEUE有点相似之处。
2、数据库也可共享数据,不过服务器共享肯定速度快些。
3、INDX是系统中存在的符合特定格式要求的表。但这不代表该EXPORT/IMPORT语句将在表INDX中增加记录,仅仅代表服务器借用了INDX的结构来管理该片共享内存。
删除:
DELETE FROMSHARED BUFFER dbtab(ar) [CLIENT cl] ID id
DELETE FROMSHARED MEMORY dbtab(ar) [CLIENT cl] ID id
PS:喜欢的同学可以关注微信公众号
