滴滴可观测平台 Metrics 指标实时计算如何实现了又准又省?
在滴滴,可观测平台的 Metrics 数据有一些实时计算的需求,承载这些实时计算需求的是一套又一套的 Flink 任务。之所以会有多套 Flink 任务,是因为每个服务按照其业务观测需要不同的指标计算,也就对应了不同数据处理拓扑。我们尽力抽象用户相同的计算需求,不过由于 Flink 实时计算任务开发模式和实时计算框架的限制,这些观测指标计算任务设计的都不够通用。使用 Flink 做 Metrics 指标的实时计算,维护多套 Flink 任务面临如下一些问题:
本应抽象出来的通用 Metrics 计算能力被重复建设且良莠不齐,无法沉淀
处理逻辑被随意的 hardcode 到流任务的代码中不易更新和维护
Flink 发布、扩容、缩容需要重启任务,会导致指标产出延迟、断点、错点
Flink 平台收费相对较贵,在我们内部成本账单中占大头,有一定成本压力
为了解决这些问题,我们自行开发了一套实时计算引擎: observe-compute(简称 OBC),以下是对 OBC 实现的介绍。
设计目标
在立项之初,OBC 确定的设计目标如下:
1、打造一款 Metrics 指标计算领域通用的实时计算引擎,这个引擎有如下特性:
接轨业界标准: 以 PromQL 作为流处理任务的描述语言
任务灵活管控: 策略配置化,计算任务实时生效,执行计划能够人为干预
计算链路溯源: 能够实现策略级别的计算结果溯源
云原生容器化: 引擎容器化部署,可以做到无停机的动态扩缩容
2、产品能够满足可观测平台全部的 Metrics 指标计算需求,替换重复计算任务,降本增效,重塑观测采集传输计算链路。
目前除了计算链路溯源这一特性,其余引擎特性已全部实现。OBC 目前已经在线上稳定运行数月有余,可观测平台最核心的几套 Flink 计算任务已经完成迁移 OBC 的工作,预计到年底已经迁移的任务能累计为可观测平台节约成本 100 万元。
引擎架构
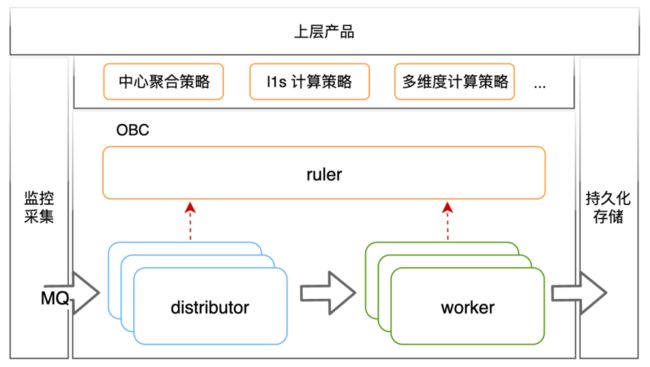
引擎架构如上图所示,分成三个组件: 其中 obc-ruler 是引擎中的控制组件,对引擎内的其他组件提供服务注册发现能力,同时负责外部计算策略的接入和执行计划的管控。obc-distributor 从 Metrics 消息队列摄取 Metrics 指标,匹配计算策略,并按照策略的执行计划转发数据到 obc-worker。obc-worker 是引擎中实际负责计算的组件,负责按照执行计划完成指标计算并将计算结果投递到外部持久化存储。
可用性讨论
具体介绍各个组件的核心逻辑前,先介绍下我们对可用性的思考和妥协,以及为了达到可用性目标而引入的一些概念,这部分讨论有助于理解各组件的核心逻辑。
可用性思考
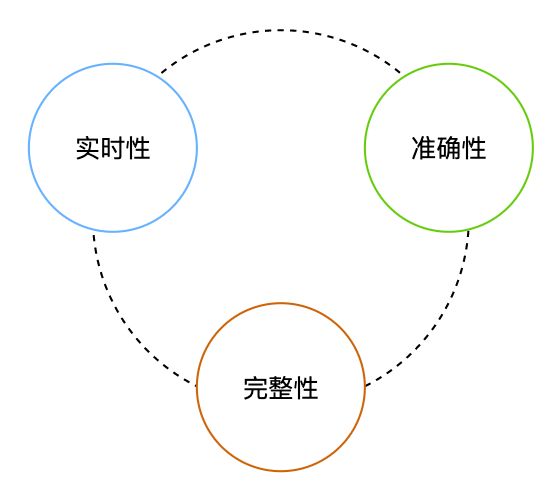
实时计算场景对于数据可用性的要求可以拆分为实时性要求和精准性要求,要求数据低延时、高精准。精准性又可以描述为数据不错、不丢。数据不错的要求我称之为准确性要求,数据不丢的要求我称之为完整性要求。
对于业务观测数据来说,从最终产出的结果上来看,也适合从上述三个角度讨论可用性:
实时性: 落到存储中的数据不能出现较大延迟
准确性: 落到存储中的数据必须准确的反应系统的状态
完整性: 落到存储中的数据不能出现丢点、断点
简单的观测数据处理流程可以简化为: 采集 => 存储。在这样的流程中采集到什么就是什么,不需要讨论数据的准确性。实时性和完整性两个要求中,为了降低系统的实现复杂度和运行开销,一般采取的做法是保证实时性、牺牲完整性。
观测数据参与实时计算的场景,会比一般场景更为复杂,需要进一步讨论数据的准确性。我们内部从 observe-agent(采集端) => mq => obc-distributor => obc-worker => 持久化存储的数据流,在同一计算窗口的数据到达 obc-worker 的延迟分布满足假设的前提下,至少需要保证从采集端到 obc-worker 的 at least once 语义,且在 obc-worker 上实现数据去重和保障计算窗口完整性的逻辑才能保证结果的准确。这对我们来说,不论是设计实现的成本,还是为了保证准确性而额外付出的计算资源成本都略高。并且我们使用 Flink 做 Metrics 指标计算时也无法保证最终产出的数据一定准确,所以 OBC 在方案设计时也做了一些必要的妥协,在保障计算结果产出实时性的前提下,尽量保证计算结果只会断点(完整性)不会错点(准确性),但是不承诺产出的数据一定准确。
可用性设计
首先引入一个叫做 cutover 时间的概念,cutover 的含义是切换,这个概念是我们从 m3aggregator 中借鉴来的。在 OBC 中,cutover 时间会被设置为一个晚于配置发生变化的时间作为配置的实际生效时间,这样 obc-distributor & obc-worker 在变化的配置实际生效之前有多次机会同步到相同的配置。这里引入 cutover 时间的概念最初是因为 obc-distributor 将数据转发到 obc-worker 的时候会在 obc-worker 构成的 hash 环上选择需要转发到哪台 worker 实例,一旦某个 worker 实例状态发生变化导致 worker 构成的 hash 变化时,会出现一个问题:如果变化立即生效,那么 obc-distributor 感知到 hash 变化的过程有先有后,会出现短时间的 distributor 集群内生效的 worker hash 环不一致,通过 cutover 将配置实际生效时间延迟,可以给 distributor 更充分的时间感知配置的变化。更具体的在可用性上的设计分为如下的几点:
1、obc-worker 发生死机、漂移、重启至多导致部分曲线出现三个断点,不发生错点
worker 到 ruler 有心跳同步机制,每 3s 同步一次
distributor 从 ruler 同步 worker hash 环频率 3s 同步一次
ruler 根据 worker 的状态完成 hash 环的版本更新逻辑,一个 cutover 是一个版本,历史版本最多保留 10min
ruler 对于 worker 死亡的判断: 8s 心跳未更新,或者主动调用接口注销自己 ruler
对于 hash 环的传播延迟时间: 8s

2、obc-distributor 发生漂移、重启不会导致曲线断点、错点
obc 部署在我们内部的云平台上,我们内部的云平台有一些对于优雅重启的支持能力:容器漂移、重启时会向业务进程发送 SIGTERM 信号。distributor 会监听这个信号,收到信号后做两件事情:
停止从 MQ 消费
Metrics 数据点、将缓存中还未发送到 worker 的数据点尽快发送完
3、obc-distributor 发生 panic、所在物理节点死机会导致断点、错点
这种情况 distributor 没有机会做善后工作,已经缓存在内存中还没来及发送到 worker 的部分数据丢失,会造成计算结果过错点
这种情况的用户影响有多大呢?我们旧的 metrics 计算链路 observe-agent(采集端) => mq => router => kafka => flink,链路中的 router 模块承担了类似 distributor 的部分工作,也存在同样的问题,运行这么多年来看用户感知不明显
4、指标产出的精度要求是 60s 以及 60s 以下的策略更新时不发生断点、错点
策略更新后在集群内生效不同步会出现短时间的错点,为了解决这个问题在策略上也引入了 cutover 时间的概念,cutover 时间 60s 对齐
各组件介绍
obc-ruler
ruler 这个模块有两大职能,服务注册/发现和策略管理,如下图所示:
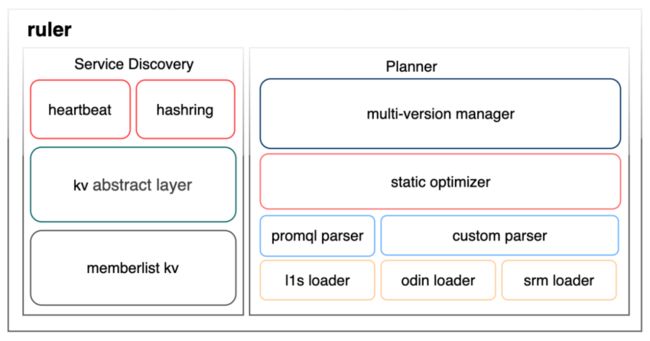
服务注册/发现能力的构建分为三层,其中 kv abstract layer 和 memberlist kv 这两层使用了 grafana/dskit 这个三方库,这个库在 kv abstract layer 之下支持 consul、etcd 等多种 kv,我们最终选择了使用 memberlist kv,在 gossip 协议提供的数据同步能力之上构建最终一致性 kv,原因是我们希望可观测自身要尽可能减少外部依赖,避免出现我们依赖外部组件来提供观测能力,而这些外部组件又依赖我们的观测能力保障其稳定性这样的循环依赖问题。上层的 heartbeat 和 hashring 直接的解释就是注册在 kv store 上的两个 key 及其配套的冲突 merge 逻辑。其中 heartbeat 这个 key 里面保存 worker 的地址、注册时间、最近心跳时间、分配给这个 worker 的 hash tokens 等信息,而 hashring 这个 key 则保存了 cutover 不同的多个版本的 worker 哈希环。
策略管理模块分成四层,最底层是各种 loader,负责从外部策略源加载配置,图中列出的是我们内部几个最核心产品的计算策略加载器。对于存量的计算任务,我们为了迁移 OBC 会定制 parser 来做计算策略的转换,对于新增的计算任务会要求统一通过 PromQL 来描述其计算需求,走 PromQL parser 解析。parser 产出的执行计划是一颗树,optimizer 会对执行计划做一些优化,其实目前只是简单做了一些算子的合并。multi-version manager 做策略更新的总体调度、封禁异常策略。
obc-distributer
distributor 这个模块的核心职能是 Metrics 数据点关联计算策略和转发。

策略匹配这里做的工作是按照指定的 label 筛选数据点,将筛选出的数据点打上对应策略的id。我们线上较大的一个 OBC 计算集群入点量近 1,000w/s,生效计算策略数量 1.2w,数据量确实太大,所以为了提高筛选效率我们对生效的策略做了一些限制:策略筛选必须要包含 __name__ 和 __ns__ 两个 label,且这两个 label 不能使用正则匹配。__name__ 是指标的名字,__ns__ 的含义是 namespace,代表指标上报的服务集群。我们依赖这两个 label 构建了两级索引来提升策略匹配的效率。
relabel 动作是按照策略的要求对数据点的 label 进行增/删/改操作。在配置的语法上,为了描述统一,我们把这些规则处理成了 PromQL 的 function,并且限制这些函数的 vector 参数只能是一个 selector 或者其他 relabel function。mapping 动作类比于其他流式计算中的维度表 join,是为了接入已存在的计算任务而妥协的产物,不做过多介绍。
选择 worker 的过程:
数据点 event_time 对齐时间: align_time = event_time - event_time % resolution,其中 resolution 是策略中给出的期望产出指标的精度
worker hash 环选择: 用 align_time 去 hash 环列表里面找 cutover 不大于 align_time 的最新的一个 worker hash 环
worker 实例选择: 用 planid + align_time + 指定的一系列 label 的 value 作为 key 计算 hash 值,拿 hash 值去 worker hash 环中找 worker 实例。其中指定的一系列 label 是由 ruler 分析策略后生成,对于需要处理的数据量较小的策略一般为空。
obc-worker
worker 的核心职能是 Metrics 指标计算
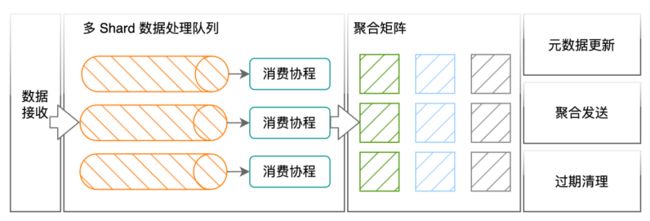
distributor 保证同一条策略、同聚合维度、同运算窗口的 Metrics 点一定会被转发到同一个 worker。worker 收到的 Metrics 数据点会携带策略 id 信息,worker 依此寻找计算策略内容。计算策略的最小逻辑运算单元是 Action,PromQL 中的函数、二元运算、聚合运算都被翻译为了 Action。在 worker 的聚合矩阵内,每个 Action 下是一系列按照 resolution 对齐的时间窗口,在时间窗口内,需要被放到一起计算的一组数据被写入到同一个计算单元,计算单元是 worker 中最小物理运算单元。被添加到同一计算单元中的数据如非必须,并不会被缓存而是实时的被用于计算。
这么说可能比较难理解,我举个例子,以计算规则 sum by (caller, callee) (rpc_counter) 为例,其中 rpc_counter 原始指标的筛选在 distributor 完成, sum by (caller, callee) 的动作被处理为一个 Action,Action 的类型是聚合操作,聚合类型是求和,聚合后产出数据的维度是 caller、callee 两个维度,worker 在处理数据点时会把 caller & callee 两个 label 的 value 相同的数据点投送到同一个聚合单元中,聚合单元每收到一个点就会执行 sum += point.value 这样的动作。
worker 处理二元运算、聚合运算需要关注的一个问题是开窗时间的设置,一个窗口用多长时间来等待他需要的数据全部到齐,这个值直接影响指标产出的实时性和准确性。我们根据自身 Metrics 在链路传输中的延迟分布情况设置了如下默认策略:
原始指标 step 值小于等于 10 的,开窗时间设置为 25s
原始指标 step 值大于 10 的,开窗时间设置为 2*step + 5,如果开窗时间大于 120s,则将开窗时间设置为 120
这部分对于各个组件实现的介绍相对简略,只介绍了核心的流程,对于很多我们在性能、功能上做的权衡和优化等以后有机会再单独介绍。
补充性内容
为了便于大家理解,这里也额外补充一些内容。
计算策略样例

OBC 内部的策略是以树的形式表达的,树的叶子节点必须是 Metrics 的筛选条件或者常数,且不允许叶子节点都是常数(这样的策略对事件驱动的计算引擎没有意义),Metrics 的筛选条件在策略里面被叫做 Filter,Filter 在 distributor 上执行,其余的 Action 都在 worker 上执行。如果策略没有特别做过设置,策略匹配到的 Metrics 点同一个窗口的会被发送到同一个 worker,后续 Action 的处理都在这个 worker 上完成,不同窗口的数据可能会发送到不同的 worker,之所以这么做是因为单纯在策略维度上打散无法做到 worker 间的负载均衡。
这里有个点要特别说明,如果某个策略单个窗口的数据量大到单个 worker 无法处理的程度,我们会手动做一些设置,让策略按照一些聚合计算的维度打散到多个 worker。如果无法打散或者打散后单个 worker 仍然没法处理,我们会选择一禁了之。当然因为我们限制计算策略中筛选数据必须有 __ns__ label,只能是同一个服务的 metrics 数据做计算,所以到目前为止还没有遇到过需要封禁策略的情况。对于单个 worker 处理不了的情况也可以选择实现 worker 间的级联计算的能力,以归并的方式处理大数据量的任务,如果后续有需求在当前的架构上也可以快速扩展实现该能力。
对PromQL的支持
OBC 希望以 PromQL 作为计算策略的用户接入方式,这样可以降低用户对策略的理解和接入成本。截止到成文之日,我们对 PromQL 语法 & 函数支持的完成度并不高,这其中的主要原因是有不少操作和算子存量的策略接入并不会用到,需求驱动我们逐步按需实现中,也有一些 PromQL 语法并不适合在实时计算中实现,比如 offset 修饰符、@ 修饰符、subquery。
前文中有介绍到 distributor 保证同一条计算策略的同一个运算窗口的数据转发到同一个 worker,这里大家可能会疑惑,对于 range vector 呢?类似 irate(http_request_total[10s])这样的运算前后窗口的两个点转发到不同的 worker 该怎么算 irate ?如果你有这样的疑惑,那么我应该恭喜自己前边写的内容能让你认真看下去并且让你看明白了。
对于 range vector 包括 range vector selector 和 range vector function 在当前版本的 OBC 中并不支持,不支持的原因是因为我们暂时用不到,你可以认为我们内部的数据都是 Prometheus 中的 Gauge 类型,对于请求量这样所谓的 Counter 指标在我们这边实际统计的是每个 10s 周期的请求量,周期与周期之间的数据并不会累加,就像是我们的 Counter 数据在上报之前就做了 increace(http_request_total[10s])这样的运算。当然后续我们肯定会考虑实现 range vector 相关语法的支持,但也会作出一些语法上的限制。
准确的集群粒度请求延迟
滴滴可观测平台在没有支持 Prometheus Exporter 采集与 PromQL 取数之前没有 histogram 这种数据类型的概念。对于服务的请求延迟,我们会在采集端使用 t-digest 算法近似的统计每个服务实例的接口延迟分布,并且默认上报 99 & 95 & 90 & 50 几个分位值的延迟数据。因为原始信息的缺失,无法提供给用户计算相对准确的集群粒度接口延迟分位值,只能勉强用单机粒度的延迟分位值指标求均值或者求最大值来替代。
在 OBC 上我们也顺便解决了这个问题,具体的做法是 OBC 与采集端配合,采集端在上报延迟分位值指标时顺便把接口延迟分布的分桶信息一起上报。分桶的信息不落持久化存储,只会按需摄取到 OBC 中,OBC 将相关操作扩展成了一个 PromQL Aggregation Operator,这个 Operator 的名字叫 percentile,做的动作是将单机的分桶信息合并得到一个新的延迟分布,按需产出这个分布的分位值。
总结与展望
截止到目前,OBC 已经在线上稳定运行数月有余,可观测平台最核心的几套 Metrics 计算任务已完成迁移 OBC 的工作,并且取得了显著的成本收益。
对于后续的项目迭代思路,这里介绍其中比较核心的一个点,我们希望将采集端也纳入到这套计算引擎中,实现采算一体:对于用户的计算需求,能前移的尽可能前移到采集端完成,能在采集端做预计算也尽可能在采集端做预计算。
经计算引擎计算后,我们产出的观测数据更多了,包括原始数据和新增的计算结果。这些数据最终存在了哪里,是选择了行存还是列存,是选用已有方案还是自研,又是如何解决海量的数据问题的,下一篇将讲述观测数据存储在滴滴的故事。
云原生夜话
大家在生产环境中是如何支持可观测指标的计算需求呢?欢迎在评论区留言,如需与我们进一步交流探讨,也可直接私信后台。
作者将选取1则最有意义的留言,送出滴滴定制行李箱,祝您十一无忧出行。9月26日晚9点开奖。
