第六讲:非线性优化(上)
第六讲:非线性优化(上)
文章目录
- 第六讲:非线性优化(上)
- 1 概率论与统计学基础
-
- 1.1 概率与统计关系
- 1.2 概率密度函数
- 1.3 贝叶斯公式
- 1.4 矩
- 1.5 方差与协方差矩阵
-
- 1.5.1 方差
- 1.5.2 协方差矩阵
- 1.5.3 方差与协方差的区别
- 1.6 统计独立性与不相关性
- 1.7 高斯概率密度函数
-
- 1.7.1 一维高斯分布
- 1.7.2 二维高斯分布
- 1.7.3 N维高斯分布
- 1.7.4 高斯分布线性运算
- 1.8 似然函数 p ( x ∣ θ ) p(x|\theta) p(x∣θ)
- 1.9 最大似然估计(MLE)
- 1.10 最大后验概率估计(MAP)
- 2 高数与矩阵论基础
-
- 2.1 泰勒展开
- 2.2 矩阵基础
-
- 1 稀疏矩阵
- 2 置换矩阵
- 3 正交矩阵
- 4 特征值、特征向量、特征分解
- 5 Schur 分解
- 6 SVD分解
- 7 二次型
- 8 正定矩阵
- 9 Cholesky 分解
- 10 QR分解
- 2.3 矩阵求导
-
- 2.3.1 标量函数对向量求导(Scalar-by-vector)
- 2.3.2 向量函数对标量求导(Vector-by-scalar)
- 2.3.3 向量对向量求导(Vector-by-vector)
- 2.3.4 常用的几个求导公式
- 2.4 线性方程组
-
- 2.4.1 相容/不相容方程组
- 2.4.2 超定/欠定方程组
- 2.4.3 正规方程组
- 3 最小二乘法
-
- 3.1 线性最小二乘法
- 3.2 多元函数导数、方向导数、梯度
- 3.3 非线性最小二乘法
- 3.4 梯度下降算法
- 3.5 高斯牛顿法
- 3.6 列文伯格-马夸尔特法
1 概率论与统计学基础
要理解这一讲的东西需要很多的概率论基础,所以这里复习一些概率论知识。
1.1 概率与统计关系
概率(probabilty)和统计(statistics)看似两个相近的概念,其实研究的问题刚好相反。概率研究的问题是,已知一个模型和参数,怎么去预测这个模型产生的结果的特性(例如均值,方差,协方差等等)。
统计研究的问题则相反。统计是,有一堆数据,要利用这堆数据去预测模型和参数。比如预测数据服从什么样的分布(已知数据的均值、方差)
总而言之,概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
MLE和MAP都是统计领域的问题。它们都是用来推测参数的方法。
在后续状态估计问题的推导当中,就利用到统计中MLE和MAP。我们要用观测到的数据如像素 z k , j z_{k,j} zk,j来计算均值(观测方程)和方差(信息矩阵),即MLE,什么样的状态下,最可能产生现在的观测数据。详见后续探讨。
1.2 概率密度函数
定义 x 为区间 [a,b] 上的随机变量(random variable),服从某个概率密度函数 p(x),那么这个⾮负函数必须满足:
∫ a b p ( x ) d x = 1 \int_a^b p(x) \mathrm{d} x=1 ∫abp(x)dx=1

引入条件概率。假设 p(x|y) 表示自变量 x ∈ [a,b] 在条件 y ∈ [r,s] 下的概率密度函数,那么它满⾜:
( ∀ y ) ∫ a b p ( x ∣ y ) d x = 1 (\forall y) \quad \int_a^b p(x \mid y) \mathrm{d} x=1 (∀y)∫abp(x∣y)dx=1
N 维连续型随机变量的联合概率密度函数(joint probability densities)可表示为
p ( x 1 , x 2 , … , x N ) p\left(x_1, x_2, \ldots, x_N\right) p(x1,x2,…,xN)
∫ a b p ( x ) d x = ∫ a N b N ⋯ ∫ a 2 b 2 ∫ a 1 b 1 p ( x 1 , x 2 , … , x N ) d x 1 d x 2 ⋯ d x N = 1 \int_{\boldsymbol{a}}^{\boldsymbol{b}} p(\boldsymbol{x}) \mathrm{d} \boldsymbol{x}=\int_{a_N}^{b_N} \cdots \int_{a_2}^{b_2} \int_{a_1}^{b_1} p\left(x_1, x_2, \ldots, x_N\right) \mathrm{d} x_1 \mathrm{~d} x_2 \cdots \mathrm{d} x_N=1 ∫abp(x)dx=∫aNbN⋯∫a2b2∫a1b1p(x1,x2,…,xN)dx1 dx2⋯dxN=1
1.3 贝叶斯公式
我们总是可以把⼀个联合概率密度分解成⼀个条件概率密度和⼀个非条件概率密度的乘积。
p ( x , y ) = p ( x ∣ y ) p ( y ) = p ( y ∣ x ) p ( x ) p(\boldsymbol{x}, \boldsymbol{y})=p(\boldsymbol{x} \mid \boldsymbol{y}) p(\boldsymbol{y})=p(\boldsymbol{y} \mid \boldsymbol{x}) p(\boldsymbol{x}) p(x,y)=p(x∣y)p(y)=p(y∣x)p(x)
我们将等式两边同除以p(y),即可得到贝叶斯公式:
p ( x ∣ y ) = p ( y ∣ x ) p ( x ) p ( y ) p(\boldsymbol{x} \mid \boldsymbol{y})=\frac{p(\boldsymbol{y} \mid \boldsymbol{x}) p(\boldsymbol{x})}{p(\boldsymbol{y})} p(x∣y)=p(y)p(y∣x)p(x)
如果我们有了状态的先验(prior)概率密度函数 p(x) 和传感器模型 p(y|x),p(y|x)也是最大似然,就可以推断(infer)状态的后验(posterior)概率密度函数 。为此,将分母p(y)展开:
p ( y ) = p ( y ) ∫ p ( x ∣ y ) d x ⏟ 1 = ∫ p ( x ∣ y ) p ( y ) d x = ∫ p ( x , y ) d x = ∫ p ( y ∣ x ) p ( x ) d x \begin{aligned} p(\boldsymbol{y})=p(\boldsymbol{y}) \underbrace{\int p(\boldsymbol{x} \mid \boldsymbol{y}) \mathrm{d} \boldsymbol{x}}_1 & =\int p(\boldsymbol{x} \mid \boldsymbol{y}) p(\boldsymbol{y}) \mathrm{d} \boldsymbol{x} \\ & =\int p(\boldsymbol{x}, \boldsymbol{y}) \mathrm{d} \boldsymbol{x}=\int p(\boldsymbol{y} \mid \boldsymbol{x}) p(\boldsymbol{x}) \mathrm{d} \boldsymbol{x} \end{aligned} p(y)=p(y)1 ∫p(x∣y)dx=∫p(x∣y)p(y)dx=∫p(x,y)dx=∫p(y∣x)p(x)dx
然后,把p(y)带入可得到:
p ( x ∣ y ) = p ( y ∣ x ) p ( x ) ∫ p ( y ∣ x ) p ( x ) d x p(\boldsymbol{x} \mid \boldsymbol{y})=\frac{p(\boldsymbol{y} \mid \boldsymbol{x}) p(\boldsymbol{x})}{\int p(\boldsymbol{y} \mid \boldsymbol{x}) p(\boldsymbol{x}) \mathrm{d} \boldsymbol{x}} p(x∣y)=∫p(y∣x)p(x)dxp(y∣x)p(x)
这里解释一下先验与后验:
- 先验概率是通过对以往经验分析对状态进⾏估计得到的概率
- 后验概率指的在当前状态下,得到了⼀定的观测,或者造成了⼀定的效应,得到这个观测或者效应信息之后,对状态修正后的概率。
1.4 矩
概率密度函数的零阶矩正好是整个全事件的概率,因此恒等于 1。概率密度函数⼀阶矩称为期望,用 µ 表示:
μ = E [ x ] = ∫ x p ( x ) d x \boldsymbol{\mu}=E[\boldsymbol{x}]=\int \boldsymbol{x} p(\boldsymbol{x}) \mathrm{d} \boldsymbol{x} μ=E[x]=∫xp(x)dx
概率密度函数的二阶矩是协方差矩阵:
Σ = E [ ( x − μ ) ( x − μ ) T ] \boldsymbol{\Sigma}=E\left[(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}}\right] Σ=E[(x−μ)(x−μ)T]
概率密度函数三阶和四阶矩分别叫做偏度(skewness)和峰度(kurtosis)。
1.5 方差与协方差矩阵
1.5.1 方差
方差 - 维基百科
方差描述的是一个随机变量的离散程度,即一组数字与其平均值之间的距离的度量,是随机变量与其总体均值或样本均值的离差的平方的期望值。
方差是标准差的平方、分布的二阶矩.
Var ( X ) = E [ ( X − μ ) 2 ] \operatorname{Var}(X)=\operatorname{E}\big[(X-\mu)^2\big] Var(X)=E[(X−μ)2]
方差亦可视作随机变量与自身的协方差
Var ( X ) = Cov ( X , X ) \operatorname{Var}(X)=\operatorname{Cov}(X,X) Var(X)=Cov(X,X)
1.5.2 协方差矩阵
假设X是以n个随机变量组成的列向量
X = [ X 1 X 2 ⋮ X n ] \mathbf{X}=\begin{bmatrix}X_1\\ X_2\\ \vdots\\ X_n\end{bmatrix} X= X1X2⋮Xn
μ i \mu_i μi是 X i X_i Xi的期望值,即 μ i = E ( X i ) \mu_i=\operatorname{E}(X_i) μi=E(Xi)。协方差矩阵的第 ( i , j ) (i,j) (i,j)项定义如下
Σ i j = cov ( X i , X j ) = E [ ( X i − μ i ) ( X j − μ j ) ] \Sigma_{ij}=\operatorname{cov}(X_i,X_j)=\operatorname{E}[(X_i-\mu_i)(X_j-\mu_j)] Σij=cov(Xi,Xj)=E[(Xi−μi)(Xj−μj)]
所以,我们可以得到协方差矩阵为下述形式:
Σ = E [ ( X − E [ X ] ) ( X − E [ X ] ) T ] = [ E [ ( X 1 − μ 1 ) ( X 1 − μ 1 ) ] E [ ( X 1 − μ 1 ) ( X 2 − μ 2 ) ] ⋯ E [ ( X 1 − μ 1 ) ( X n − μ n ) ] E [ ( X 2 − μ 2 ) ( X 2 − μ 2 ) ] E ( ( X 2 − μ 2 ) ( X 2 − μ 2 ) ] ⋯ E ( ( X 2 − μ 2 ) ( X n − μ n ) ] ⋮ ⋮ ⋮ ⋮ E [ ( X n − μ n ) ( X 1 − μ 1 ) ] E [ ( X n − μ n ) ( X 2 − μ 2 ) ] ⋯ E ( ( X n − μ n ) ( X n − μ n ) ] ] \begin{aligned} \Sigma& =\mathbf E\left[\left(\mathbf X-\mathbf E[\mathbf X]\right)\left(\mathbf X-\mathbf E[\mathbf X]\right)^{\text T}\right] \\\\= &\begin{bmatrix}\text{E}[(X_1-\mu_1)(X_1-\mu_1)]&\text{E}[(X_1-\mu_1)(X_2-\mu_2)]&\cdots&\text{E}[(X_1-\mu_1)(X_n-\mu_n)]\\ \text{E}[(X_2-\mu_2)(X_2-\mu_2)]&\text{E}((X_2-\mu_2)(X_2-\mu_2)]&\cdots&\text{E}((X_2-\mu_2)(X_n-\mu_n)]\\ \vdots&\vdots&\vdots&\vdots\\ \text{E}[(X_n-\mu_n)(X_1-\mu_1)]&\text{E}[(X_n-\mu_n)(X_2-\mu_2)]&\cdots&\text{E}((X_n-\mu_n)(X_n-\mu_n)]\\ \end{bmatrix} \end{aligned} Σ==E[(X−E[X])(X−E[X])T] E[(X1−μ1)(X1−μ1)]E[(X2−μ2)(X2−μ2)]⋮E[(Xn−μn)(X1−μ1)]E[(X1−μ1)(X2−μ2)]E((X2−μ2)(X2−μ2)]⋮E[(Xn−μn)(X2−μ2)]⋯⋯⋮⋯E[(X1−μ1)(Xn−μn)]E((X2−μ2)(Xn−μn)]⋮E((Xn−μn)(Xn−μn)]
1.5.3 方差与协方差的区别
方差是用来度量单个随机变量的离散程度,而协方差则一般用来刻画两个随机变量的相似程度
所以,方差越小,得到的数据越稳定,也更集中;方差越大,数据越不稳定,也更分散。
对于协方差,协方差越小,表明两个随机变量之间的相关性更小;协方差越大,则两个随机变量之间的相关性更大。
这个专栏中有图表说明
以后面要推到的状态估计问题为例,我们要假设各个输入 u u u、各个观测 z z z之间是独立的,且输入和观测之间也是独立的,那么我们就希望他们的协方差更小(独立一定不相关),方差也要小(更稳定)。
1.6 统计独立性与不相关性
如果两个随机变量 x 和 y 的联合概率密度可以⽤以下的因式分解,那么我们称这两个随机变量是统计独立(statistically independent)的
p ( x , y ) = p ( x ) p ( y ) p(\boldsymbol{x}, \boldsymbol{y})=p(\boldsymbol{x}) p(\boldsymbol{y}) p(x,y)=p(x)p(y)
同样,如果两个随机变量x和y的联合概率密度满足下列等式,称其不相关:
E [ x y T ] = E [ x ] E [ y ] T E\left[\boldsymbol{x} \boldsymbol{y}^{\mathrm{T}}\right]=E[\boldsymbol{x}] E[\boldsymbol{y}]^{\mathrm{T}} E[xyT]=E[x]E[y]T
两者关系:独立一定不相关,但是不相关的两个随机变量不一定独立!
1.7 高斯概率密度函数
多元正态分布
1.7.1 一维高斯分布
高斯概率密度函数:
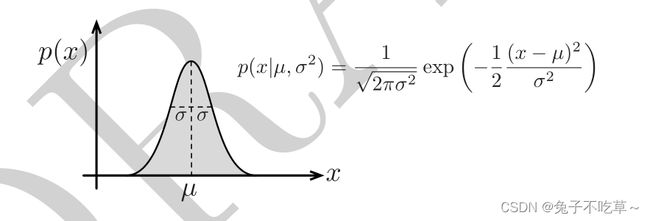
p ( x ∣ μ , σ 2 ) = 1 2 π σ 2 exp ( − 1 2 ( x − μ ) 2 σ 2 ) p\left(x \mid \mu, \sigma^2\right)=\frac{1}{\sqrt{2 \pi \sigma^2}} \exp \left(-\frac{1}{2} \frac{(x-\mu)^2}{\sigma^2}\right) p(x∣μ,σ2)=2πσ21exp(−21σ2(x−μ)2)
其中 µ 称为均值(mean),σ^2 为方差(variance),σ 称为标准差(standard deviation)。下图表示了高斯分布,也即正态分布。
1.7.2 二维高斯分布
f ( x , y ) = 1 2 π σ X σ Y 1 − ρ 2 e − 1 2 ( 1 − ρ 2 ) [ ( x − μ X σ X ) 2 − 2 ρ ( x − μ X σ X ) ( y − μ Y σ Y ) + ( y − μ Y σ Y ) 2 ] \begin{aligned} f(x,y) =\frac{1}{2\pi\sigma_X\sigma_Y\sqrt{1-\rho^2}}\mathrm{e}^{-\frac{1}{2(1-\rho^2)}\left[(\frac{x-\mu_X}{\sigma_X})^2-2\rho(\frac{x-\mu_X}{\sigma_X})(\frac{y-\mu_Y}{\sigma_Y})+(\frac{y-\mu_Y}{\sigma_Y})^2\right]} \end{aligned} f(x,y)=2πσXσY1−ρ21e−2(1−ρ2)1[(σXx−μX)2−2ρ(σXx−μX)(σYy−μY)+(σYy−μY)2]
μ = ( μ X μ Y ) , Σ = ( σ X 2 ρ σ X σ Y ρ σ X σ Y σ Y 2 ) . \boldsymbol{\mu}=\begin{pmatrix}\mu_X\\ \mu_Y\end{pmatrix},\quad\boldsymbol{\Sigma}=\begin{pmatrix}\sigma_X^2&\rho\sigma_X\sigma_Y\\ \rho\sigma_X\sigma_Y&\sigma_Y^2\end{pmatrix}. μ=(μXμY),Σ=(σX2ρσXσYρσXσYσY2).
1.7.3 N维高斯分布
N维高斯分布,随机变量$ x ∈ R^N$
p ( x ∣ μ , Σ ) = 1 ( 2 π ) N det Σ exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(\boldsymbol{x} \mid \boldsymbol{\mu}, \boldsymbol{\Sigma})=\frac{1}{\sqrt{(2 \pi)^N \operatorname{det} \boldsymbol{\Sigma}}} \exp \left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right) p(x∣μ,Σ)=(2π)NdetΣ1exp(−21(x−μ)TΣ−1(x−μ))
µ ∈ R N µ ∈ R^N µ∈RN 是均值, Σ ∈ R N × N Σ ∈ R^N×N Σ∈RN×N 是协方差矩阵(对称正定矩阵),它们可以通过以下⽅式计算:
均值
μ = E [ x ] = ∫ − ∞ ∞ x 1 ( 2 π ) N det Σ exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) d x \begin{aligned} &\boldsymbol{\mu}=E[\boldsymbol{x}]=\int_{-\infty}^{\infty} \boldsymbol{x} \frac{1}{\sqrt{(2 \pi)^N \operatorname{det} \boldsymbol{\Sigma}}} \exp \left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right) \mathrm{d} \boldsymbol{x} \end{aligned} μ=E[x]=∫−∞∞x(2π)NdetΣ1exp(−21(x−μ)TΣ−1(x−μ))dx
协方差矩阵(对称正定矩阵)
Σ = E [ ( x − μ ) ( x − μ ) T ] = ∫ − ∞ ∞ ( x − μ ) ( x − μ ) T 1 ( 2 π ) N det Σ exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) d x \begin{aligned} \boldsymbol{\Sigma} & =E\left[(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}}\right] \\ & =\int_{-\infty}^{\infty}(\boldsymbol{x}-\boldsymbol{\mu})(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}} \frac{1}{\sqrt{(2 \pi)^N \operatorname{det} \boldsymbol{\Sigma}}} \exp \left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right) \mathrm{d} \boldsymbol{x} \end{aligned} Σ=E[(x−μ)(x−μ)T]=∫−∞∞(x−μ)(x−μ)T(2π)NdetΣ1exp(−21(x−μ)TΣ−1(x−μ))dx
1.7.4 高斯分布线性运算
两个独立的高斯分布如下
x ∼ N ( μ x , Σ x x ) , y ∼ N ( μ y , Σ y y ) , x\sim N(\mu_x,\boldsymbol{\Sigma}_{xx}),\quad\boldsymbol{y}\sim N(\boldsymbol{\mu}_y,\boldsymbol{\Sigma}_{yy}), x∼N(μx,Σxx),y∼N(μy,Σyy),
它们的和仍为高斯分布
x + y ∼ N ˉ ( μ x + μ y , Σ x x + Σ y y \boldsymbol{x}+\boldsymbol{y}\sim\bar{N}(\boldsymbol{\mu}_x+\boldsymbol{\mu}_y,\boldsymbol{\Sigma}_{xx}+\boldsymbol{\Sigma}_{yy} x+y∼Nˉ(μx+μy,Σxx+Σyy
乘以常数 a a a
a x ∼ N ( a μ x , a 2 Σ x x ) . a\boldsymbol{x}\sim N(a\boldsymbol{\mu}_x,a^2\boldsymbol{\Sigma}_{xx}). ax∼N(aμx,a2Σxx).
取 y = A x y = Ax y=Ax
y ∼ N ( A μ x , A Σ x x A T ) . \boldsymbol{y}\sim N(\boldsymbol{A}\boldsymbol{\mu}_x,\boldsymbol{A}\boldsymbol{\Sigma}_{xx}\boldsymbol{A}^{\text{T}}). y∼N(Aμx,AΣxxAT).
1.8 似然函数 p ( x ∣ θ ) p(x|\theta) p(x∣θ)
下面式子中, x x x表示某一个具体的数据; θ θ θ 表示模型的参数
p ( x ∣ θ ) p(x|\theta) p(x∣θ)
如果 θ θ θ是已知确定的, x x x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点$ x$ ,其出现概率是多少。
如果 x x x 是已知确定的, θ θ θ 是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现 x x x 这个样本点的概率是多少。
1.9 最大似然估计(MLE)
最大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
换句话说,极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。
f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) f(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) f(x)=2πσ1exp(−2σ2(x−μ)2)
已经有了数据,也知道服从正太分布,那么我们就可以通过最大似然估计估计出它的均值与方差。本章中状态估计就是引入高斯噪声,求出最可能的均值(观测方程)和方差(信息矩阵)。
参考网站1
参考网站2
1.10 最大后验概率估计(MAP)
p ( θ ∣ x ) = p ( x ∣ θ ) p ( θ ) p ( x ) p(\boldsymbol{\theta} \mid \boldsymbol{x})=\frac{p(\boldsymbol{x} \mid \boldsymbol{\theta}) p(\boldsymbol{\theta})}{p(\boldsymbol{x})} p(θ∣x)=p(x)p(x∣θ)p(θ)
其中 p ( x ∣ θ ) p(x|\theta) p(x∣θ)是似然, p ( θ ) p(\theta) p(θ)是先验, p ( θ ∣ x ) p(\theta|x) p(θ∣x)是后验概率。这个公式是利用贝叶斯公式推出来的,因为分母 p ( x ) p(x) p(x)是已知的数,求最大后验时候可以忽略,不对后验概率产生影响。
p ( θ ∣ x ) ∝ p ( x ∣ θ ) p ( θ ) p(\theta|x) \propto p(x|\theta)p(\theta) p(θ∣x)∝p(x∣θ)p(θ)
这里类似于正则化里加惩罚项的思想,不过正则化里是利用加法,而MAP里是利用乘法。
2 高数与矩阵论基础
2.1 泰勒展开
- 一元函数在点 x k x_k xk处的泰勒展开式为:
f ( x ) = f ( x k ) + ( x − x k ) f ′ ( x k ) + 1 2 ! ( x − x k ) 2 f ′ ′ ( x k ) + o n f(x)=f(x_k)+(x-x_k)f'(x_k)+\frac{1}{2!}(x-x_k)^2f''(x_k)+o^n f(x)=f(xk)+(x−xk)f′(xk)+2!1(x−xk)2f′′(xk)+on
- 二元函数在点 ( x k , y k ) (x_k,y_k) (xk,yk)处的泰勒展开式为:
f ( x , y ) = f ( x k , y k ) + ( x − x k ) f x ′ ( x k , y k ) + ( y − y k ) f y ′ ( x k , y k ) + 1 2 ! ( x − x k ) 2 f x x ′ ′ ( x k , y k ) + 1 2 ! ( x − x k ) ( y − y k ) f x y ′ ′ ( x k , y k ) + 1 2 ! ( x − x k ) ( y − y k ) f y x ′ ′ ( x k , y k ) + 1 2 ! ( y − y k ) 2 f y y ′ ′ ( x k , y k ) + o n \begin{gathered} f(x,y)=f(x_{k},y_{k})+(x-x_{k})f_{x}^{\prime}(x_{k},y_{k})+(y-y_{k})f_{y}^{\prime}(x_{k},y_{k}) \\ +\frac{1}{2!}(x-x_k)^2f''_{xx}(x_k,y_k)+\frac{1}{2!}(x-x_k)(y-y_k)f''_{xy}(x_k,y_k) \\ +\frac{1}{2!}(x-x_k)(y-y_k)f''_{yx}(x_k,y_k)+\frac{1}{2!}(y-y_k)^2f''_{yy}(x_k,y_k) \\ +o^{n} \end{gathered} f(x,y)=f(xk,yk)+(x−xk)fx′(xk,yk)+(y−yk)fy′(xk,yk)+2!1(x−xk)2fxx′′(xk,yk)+2!1(x−xk)(y−yk)fxy′′(xk,yk)+2!1(x−xk)(y−yk)fyx′′(xk,yk)+2!1(y−yk)2fyy′′(xk,yk)+on
- 多元函数(n)在点$ x_k$处的泰勒展开式为:
f ( x 1 , x 2 , … , x n ) = f ( x k 1 , x k 2 , … , x k n ) + ∑ i = 1 n ( x i − x k i ) f x i ′ ( x k 1 , x k 2 , … , x k n ) + 1 2 ! ∑ i , j = 1 n ( x i − x k i ) ( x j − x k j ) f i j ′ ′ ( x k 1 , x k 2 , … , x k n ) + o n \begin{gathered} f(x^{1},x^{2},\ldots,x^{n})=f(x_{k}^{1},x_{k}^{2},\ldots,x_{k}^{n})+\sum_{i=1}^{n}(x^{i}-x_{k}^{i})f_{x^{i}}^{\prime}(x_{k}^{1},x_{k}^{2},\ldots,x_{k}^{n}) \\ +\frac{1}{2!}\sum_{i,j=1}^{n}(x^{i}-x_{k}^{i})(x^{j}-x_{k}^{j})f_{i j}^{\prime\prime}(x_{k}^{1},x_{k}^{2},\ldots,x_{k}^{n}) \\ +o^{n} \end{gathered} f(x1,x2,…,xn)=f(xk1,xk2,…,xkn)+i=1∑n(xi−xki)fxi′(xk1,xk2,…,xkn)+2!1i,j=1∑n(xi−xki)(xj−xkj)fij′′(xk1,xk2,…,xkn)+on
大部分情况都写为矩阵形式
f ( x ) = f ( x k ) + [ J ( x k ) ] T ( x − x k ) + 1 2 ! [ x − x k ] T H ( x k ) [ x − x k ] + o n f(\mathbf{x})=f(\mathbf{x}_k)+\left[ J(\mathbf{x}_k)\right]^T(\mathbf{x}-\mathbf{x}_k)+\frac{1}{2!}\left[\mathbf{x}-\mathbf{x}_k\right]^TH(\mathbf{x}_k)[\mathbf{x}-\mathbf{x}_k]+o^n f(x)=f(xk)+[J(xk)]T(x−xk)+2!1[x−xk]TH(xk)[x−xk]+on
其中 J ( x k ) J(\mathbf{x}_k) J(xk)是 f ( x ) f(x) f(x)关于参数 ( x 1 , x 2 , … , x n ) (x^{1},x^{2},\ldots,x^{n}) (x1,x2,…,xn)一阶导数,即 ∑ i = 1 n f x i ′ ( x k 1 , x k 2 , … , x k n ) \sum_{i=1}^{n}f_{x^{i}}^{\prime} (x_{k}^{1},x_{k}^{2},\ldots,x_{k}^{n}) ∑i=1nfxi′(xk1,xk2,…,xkn),也叫雅可比矩阵;
J = [ ∂ f ∂ x 1 ⋯ ∂ f ∂ x n ] = [ ∂ f 1 ∂ x 1 ⋯ ∂ f 1 ∂ x n ⋮ ⋱ ⋮ ∂ f m ∂ x n ⋯ ∂ f m ∂ x n ] \textbf{J}=\begin{bmatrix}\frac{\partial\textbf{f}}{\partial x_1}&\cdots&\frac{\partial\textbf{f}}{\partial x_n}\end{bmatrix}=\begin{bmatrix}\frac{\partial f_1}{\partial x_1}&\cdots&\frac{\partial f_1}{\partial x_n}\\ \vdots&\ddots&\vdots\\ \frac{\partial f_m}{\partial x_n}&\cdots&\frac{\partial f_m}{\partial x_n}\end{bmatrix} J=[∂x1∂f⋯∂xn∂f]= ∂x1∂f1⋮∂xn∂fm⋯⋱⋯∂xn∂f1⋮∂xn∂fm
在雅可比矩阵中,如果f是标量,意味者其它 f i f_i fi处的值为0.
H ( x k ) H(\mathbf{x}_k) H(xk)是海塞矩阵,具体形式如下:
H ( s k ) = [ ∂ f ( x k ) ∂ x 1 2 ∂ f ( x k ) ∂ x 1 2 . . . ∂ f ( x k ) ∂ f ( x k ) ∂ x 2 ∂ f ( x k ) ∂ x 2 2 . . . ∂ f ( x k ) ∂ x n ∂ x n ∂ 2 f ( x k ) ∂ x 2 ∂ x 1 ∂ f ( x k ) ∂ x 2 2 . . . ∂ 2 f ( x k ) ∂ x n ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ f ( x n ) ∂ x n ∂ x 1 ∂ 2 f ( x k ) ∂ x n ∂ x 2 . . . ∂ 2 f ( x n ) ∂ x n 2 ] H(\mathbf{s}_k)=\begin{bmatrix}\frac{\partial f(x_k)}{\partial x_1^2}&\frac{\partial f(x_k)}{\partial x_1^2}&...&\partial f(x_k)\\ \frac{\partial f(x_k)}{\partial x_2}&\frac{\partial f(x_k)}{\partial x_2^2}&...&\frac{\partial f(x_k)}{\partial x_n\partial x_n}\\ \frac{\partial^2f(x_k)}{\partial x_2\partial x_1}&\frac{\partial f(x_k)}{\partial x_2^2}&...&\frac{\partial^2f(x_k)}{\partial x_n\partial x_n}\\ \vdots&\vdots&\ddots&\vdots\\ \frac{\partial f(x_n)}{\partial x_n\partial x_1}&\frac{\partial^2f(x_k)}{\partial x_n\partial x_2}&...&\frac{\partial^2f(x_n)}{\partial x_n^2}\\ \end{bmatrix} H(sk)= ∂x12∂f(xk)∂x2∂f(xk)∂x2∂x1∂2f(xk)⋮∂xn∂x1∂f(xn)∂x12∂f(xk)∂x22∂f(xk)∂x22∂f(xk)⋮∂xn∂x2∂2f(xk).........⋱...∂f(xk)∂xn∂xn∂f(xk)∂xn∂xn∂2f(xk)⋮∂xn2∂2f(xn)
2.2 矩阵基础
1 稀疏矩阵
如果一个矩阵的大部分元素是0,那么就称它是稀疏的。带状矩阵就是典型的稀疏矩阵。
如果对于任何的 i > j + p i>j+p i>j+p都有 a i j = 0 a_{ij} = 0 aij=0,称 A ∈ R m ∗ n A \in R^{m*n} A∈Rm∗n具有下带宽p;如果对于任何的 j > i + p j>i+p j>i+p都有 a i j = 0 a_{ij} = 0 aij=0,称 A ∈ R m ∗ n A \in R^{m*n} A∈Rm∗n具有上带宽p。
比如对角矩阵除主对角线外元素全为0,可知其上带宽和下带宽均为0,是一种典型的稀疏矩阵。
I n = [ 1 0 0 0 1 0 0 0 1 ] I_{n} = \begin{bmatrix}1&0&0\\ 0&1&0\\ 0&0&1\end{bmatrix} In= 100010001
2 置换矩阵
单位矩阵 I n I_n In
I n = [ 1 0 0 0 1 0 0 0 1 ] I_{n} = \begin{bmatrix}1&0&0\\ 0&1&0\\ 0&0&1\end{bmatrix} In= 100010001
把单位矩阵 I n I_n In的行重新排序,得到的矩阵称为置换矩阵P。
P = [ 0 1 0 0 0 1 1 0 0 ] P = \begin{bmatrix}0&1&0\\ 0&0&1\\ 1&0&0\end{bmatrix} P= 001100010
3 正交矩阵
若矩阵 Q ∈ R m ∗ n Q \in R^{m*n} Q∈Rm∗n满足 Q T Q = I Q^{T}Q = I QTQ=I,则 Q Q Q称为正交矩阵。旋转矩阵 R R R即正交矩阵。
4 特征值、特征向量、特征分解
其中 A A A 是一个 n × n n×n n×n 矩阵, x x x 是一个 n n n 维向量,则 λ λ λ 是矩阵 A A A 的一个特征值,而 x x x 是矩阵 A A A 的特征值$ λ$ 所对应的特征向量
A x = λ x Ax=\lambda x Ax=λx
如果 A A A有 n n n个线性无关的特征向量,那么矩阵 A A A相似于对角矩阵
A ( x 1 , x 2 , . . . , x n ) = ( x 1 , x 2 , . . . , x n ) Σ = ( x 1 , x 2 , . . . , x n ) d i a g ( λ 1 , λ 2 , . . . , λ n ) A(x_1,x_2,...,x_n)= (x_1,x_2,...,x_n)Σ = (x_1,x_2,...,x_n)diag(λ_1,λ_2,...,λ_n) A(x1,x2,...,xn)=(x1,x2,...,xn)Σ=(x1,x2,...,xn)diag(λ1,λ2,...,λn)
其中 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)是由特征向量组成的矩阵,记为 X X X, 其中 Σ = d i a g ( λ 1 , λ 2 , . . . , λ n ) Σ= diag(λ_1,λ_2,...,λ_n) Σ=diag(λ1,λ2,...,λn)是特征值组成的对角矩阵。可以写为下述形式:
A X = X Σ AX= XΣ AX=XΣ
令等式左乘 X − 1 X^{-1} X−1,可以得到
X − 1 A X = Σ X^{-1}AX= Σ X−1AX=Σ
或者右乘 X − 1 X^{-1} X−1,可以得到
A = X Σ X − 1 A= XΣX^{-1} A=XΣX−1
上面这一过程可以称之为特征值分解。注意A必须是方阵,有n个线性无关的特征向量
5 Schur 分解
如果矩阵 A A A是对称矩阵,那么存在正交矩阵 Q Q Q,使得
A = Q Σ Q T = Q d i a g ( λ 1 , λ 2 , . . . , λ n ) Q T A= QΣQ^{T} = Qdiag(λ_1,λ_2,...,λ_n)Q^{T} A=QΣQT=Qdiag(λ1,λ2,...,λn)QT
下面这个式子用来刻画特征值的最大最小极值。x指特征向量
λ m i n / m a x = x ‾ T A x x ‾ T x λ_{min/max} = \frac{\overline{x}^TAx}{\overline{x}^Tx} λmin/max=xTxxTAx
6 SVD分解
假设 A A A是 m × n m×n m×n的实矩阵(不要求方阵),则存在正交矩阵 U = [ u 1 , u 2 , . . . , u m ] ∈ R m × m U = [u_1,u_2,...,u_m] \in R^{m×m} U=[u1,u2,...,um]∈Rm×m和 V = [ v 1 , v 2 , . . . , v n ] ∈ R n × n V = [v_1,v_2,...,v_n]\in R^{n×n} V=[v1,v2,...,vn]∈Rn×n,使得
U T A V = Σ = d i a g ( σ 1 , . . . , σ p ) ∈ R m × n U^TAV =Σ = diag(σ_1,...,σ_p)\in R^{m×n} UTAV=Σ=diag(σ1,...,σp)∈Rm×n
其中 P = m i n ( m , n ) P = min(m,n) P=min(m,n), σ 1 > = σ 2 > = . . . > = σ p σ_1>= σ_2 >= ... >=σ_p σ1>=σ2>=...>=σp。 σ i σ_i σi是 A A A的奇异值, u i u_i ui是 A A A的左奇异向量, v i v_i vi是 A A A的右奇异向量。因为是正交矩阵,所以上面的转置也就是矩阵的逆矩阵。上式也可以写为:
A = U Σ V T A =UΣV^T A=UΣVT
下图就可以看出SVD分解的矩阵变化
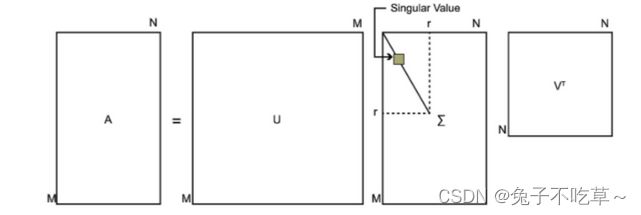
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。
也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。所以SVD可以用于PCA降维。
更多参考维基百科
7 二次型
二次型是关于一些变量的二次齐次多项式,齐次多项式是指各项的总次数均相同的多项式。 4 x 2 + 2 x y − 3 y 2 4x^2 + 2xy - 3y^2 4x2+2xy−3y2是关于变量 x x x和 y y y的二次型。
扩展到矩阵理论中的二次型,设 x = ( x 1 , x 2 , . . . , x n ) T x = (x_1,x_2,...,x_n)^T x=(x1,x2,...,xn)T,矩阵 A = ( a i j ) n ∗ n A = (a_{ij})_{n*n} A=(aij)n∗n是对称矩阵
f ( x 1 , x 2 , . . . , x n ) = x T A x = a 11 x 1 2 + 2 a 12 x 1 x 2 + . . . + 2 a 1 n x 1 x n + a 22 x 2 2 + . . . + a n n x n 2 f(x_1,x_2,...,x_n) = x^T Ax \\ =a_{11}x_1^2 + 2a_{12}x_1x_2 + ... +2a_{1n}x_1x_n + a_{22}x_2^2+...+a_{nn}x_n^2 f(x1,x2,...,xn)=xTAx=a11x12+2a12x1x2+...+2a1nx1xn+a22x22+...+annxn2
若 A A A是正定对称矩阵(A的顺序主子式都大于0),则二次型为实二次型。
8 正定矩阵
如果 x T A x > 0 x^T Ax >0 xTAx>0,那么称 A A A是正定矩阵;特征值都大于0
如果 x T A x > = 0 x^T Ax >=0 xTAx>=0,那么称 A A A是半正定矩阵;特征值都不小于0
如果 x T A x < = 0 x^T Ax<=0 xTAx<=0,那么称 A A A是半负定矩阵;特征值都不大于0
如果 x T A x < 0 x^T Ax<0 xTAx<0,那么称 A A A是负定矩阵。特征值都小于0
如果总存在 p , q p,q p,q ,使得 f ( p ) < 0 < f ( q ) f(p)<0
如果 A A A是对称正定矩阵,那么A中最大的元素位于对角线上且为正。
9 Cholesky 分解
如果A是对称正定矩阵,那么存在唯一一个下三角矩阵G,其有正的对角线元素,使得 A = G G T A = GG^T A=GGT
Cholesky 分解
10 QR分解
任何实数方阵 A A A都是通过使用正交矩阵 Q Q Q和上三角矩阵 R R R给出的
A = Q R A=QR A=QR
如果A是非奇异矩阵,则唯一确定对角线为正的R的因式分解 。
2.3 矩阵求导
2.3.1 标量函数对向量求导(Scalar-by-vector)
先考虑 x x x为向量的情况。假设 x ∈ R m x \in \mathbb{R}^m x∈Rm 为列向量, 那么:
d f d x = [ d f d x 1 , ⋯ , d f d x m ] T ∈ R m . \frac{\mathrm{d} f}{\mathrm{~d} \boldsymbol{x}}=\left[\frac{\mathrm{d} f}{\mathrm{~d} x_1}, \cdots, \frac{\mathrm{d} f}{\mathrm{~d} x_m}\right]^{\mathrm{T}} \in \mathbb{R}^m . dxdf=[ dx1df,⋯, dxmdf]T∈Rm.
这将得到一个 m × 1 m×1 m×1 的向量。有时, 我们也写成对 x T x^T xT的求导:
d f d x T = [ d f d x 1 , ⋯ , d f d x m ] \frac{\mathrm{d} f}{\mathrm{~d} \boldsymbol{x}^{\mathrm{T}}}=\left[\frac{\mathrm{d} f}{\mathrm{~d} x_1}, \cdots, \frac{\mathrm{d} f}{\mathrm{~d} x_m}\right] dxTdf=[ dx1df,⋯, dxmdf]
2.3.2 向量函数对标量求导(Vector-by-scalar)
y是向量,x是标量
y = [ y 1 y 2 ⋯ y m ] T \mathbf{y}=\begin{bmatrix}y_1&y_2&\cdots&y_m\end{bmatrix}^{\mathsf{T}} y=[y1y2⋯ym]T
∂ y ∂ x = [ ∂ y 1 ∂ x ∂ y 2 ∂ x ⋮ ∂ y m ∂ x ] \frac{\partial\textbf{y}}{\partial x}=\begin{bmatrix}\frac{\partial y_1}{\partial x}\\ \frac{\partial y_2}{\partial x}\\ \vdots\\ \frac{\partial y_m}{\partial x}\end{bmatrix} ∂x∂y= ∂x∂y1∂x∂y2⋮∂x∂ym
2.3.3 向量对向量求导(Vector-by-vector)
一个向量函数也可以对向量求导。考虑$ \boldsymbol{F}(\boldsymbol{x}) $为一个向量函数:
F ( x ) = [ f 1 ( x ) , ⋯ , f n ( x ) ] T \ \boldsymbol{F}(\boldsymbol{x})=\left[f_1(\boldsymbol{x}), \cdots, f_n(\boldsymbol{x})\right]^{\mathrm{T}} \ F(x)=[f1(x),⋯,fn(x)]T
其中每一个 $f_k $都是一个自变量为向量, 取值为标量的函数。考虑这样的函数对 $\boldsymbol{x} $求导时, 的做法是写为
∂ F ∂ x T = [ ∂ f 1 ∂ x T ⋮ ∂ f n ∂ x T ] = [ ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 ⋯ ∂ f 1 ∂ x m ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 ⋯ ∂ f 2 ∂ x m ⋮ ⋮ ⋱ ⋮ ∂ f n ∂ x 1 ∂ f n ∂ x 2 ⋯ ∂ f n ∂ x m ] ∈ R n × m 这里是分子布局,分母布局是其转置 \frac{\partial \boldsymbol{F}}{\partial \boldsymbol{x}^{\mathrm{T}}}=\left[\begin{array}{c} \frac{\partial f_1}{\partial \boldsymbol{x}^{\mathrm{T}}} \\ \vdots \\ \frac{\partial f_n}{\partial \boldsymbol{x}^{\mathrm{T}}} \end{array}\right]=\left[\begin{array}{cccc} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \cdots & \frac{\partial f_1}{\partial x_m} \\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \cdots & \frac{\partial f_2}{\partial x_m} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f_n}{\partial x_1} & \frac{\partial f_n}{\partial x_2} & \cdots & \frac{\partial f_n}{\partial x_m} \end{array}\right] \in \mathbb{R}^{n \times m} \\这里是分子布局,分母布局是其转置 ∂xT∂F= ∂xT∂f1⋮∂xT∂fn = ∂x1∂f1∂x1∂f2⋮∂x1∂fn∂x2∂f1∂x2∂f2⋮∂x2∂fn⋯⋯⋱⋯∂xm∂f1∂xm∂f2⋮∂xm∂fn ∈Rn×m这里是分子布局,分母布局是其转置
列函数向量对行向量求导(上面F(x)为列,x^T为行 下面Ax也是一个列向量函数),很多时候是默认这种求导方式的,所以分母的转置符号T没有写出来。
∂ A x ∂ x T = A . {\frac{\partial{\boldsymbol{A}}{\boldsymbol{x}}}{\partial{\boldsymbol{x}}^{\mathrm{T}}}}={\boldsymbol{A}}. ∂xT∂Ax=A.
反之,一个行向量函数也可以对列向量求导,结果为之前的转置:
∂ F T ∂ x = ( ∂ F ∂ x T ) T \frac{\partial\boldsymbol{F}^{\mathrm{T}}}{\partial\boldsymbol{x}}=\left(\frac{\partial\boldsymbol{F}}{\partial\boldsymbol{x}^{\mathrm{T}}}\right)^{\mathrm{T}} ∂x∂FT=(∂xT∂F)T
2.3.4 常用的几个求导公式
分子布局,就是分子是列向量形式,分母是行向量形式
分母布局,就是分母是列向量形式,分子是行向量形式
布局
x x x本身是一个列向量,下面所有的矩阵A都不是x的函数, x T A x x^TAx xTAx是一个标量(二次型)。
| 条件 | 表达式 | 分子布局,结果是行向量 | 分母布局,结果是列向量 |
|---|---|---|---|
| A普通矩阵 | ∂ x ⊤ A x ∂ x = \frac{\partial\mathbf{x}^\top\mathbf{A}\mathbf{x}}{\partial\mathbf{x}}= ∂x∂x⊤Ax= | x ⊤ ( A + A ⊤ ) \mathbf{x}^{\top}\left(\mathbf{A}+\mathbf{A}^{\top}\right) x⊤(A+A⊤) | ( A + A ⊤ ) x \left(\mathbf{A}+\mathbf{A}^\top\right)\mathbf{x} (A+A⊤)x |
| A是对称矩阵 | ∂ x ⊤ A x ∂ x = \frac{\partial\mathbf{x}^\top\mathbf{A}\mathbf{x}}{\partial\mathbf{x}}= ∂x∂x⊤Ax= | 2 x T A 2x^{T}{A} 2xTA | 2 A x 2A x 2Ax |
| A普通矩阵 | ∂ A x ∂ x = {\frac{\partial{\boldsymbol{A}}{\boldsymbol{x}}}{\partial{\boldsymbol{x}}}}= ∂x∂Ax= | A A A | A T A^T AT |
| A普通矩阵 | ∂ x ⊤ A ∂ x = \frac{\partial\mathbf{x}^{\top}\mathbf{A}}{\partial\mathbf{x}}= ∂x∂x⊤A= | A T A^T AT | A A A |
链式法则(左边分子布局,右边分母布局)

2.4 线性方程组
2.4.1 相容/不相容方程组
- 相容方程组
相容方程组是指一个线性方程组存在至少一个解的情况。具体来说,如果线性方程组的每个方程都可以通过一组未知变量的取值得到满足,则该方程组是相容的。
在数学上,一个线性方程组是相容的当且仅当该方程组的增广矩阵的秩等于系数矩阵的秩。增广矩阵是由系数矩阵和常数项组成的扩展矩阵。
如果一个线性方程组是相容的,它可以有多个解。这是因为线性方程组的解集可以是一个超平面或一个线性空间。具体的解取决于方程组的自由变量的取值。自由变量是未知变量中可以任意选择值的变量。
- 不相容方程组
不相容方程组是指一个线性方程组不存在解的情况。具体而言,如果线性方程组的方程之间存在矛盾,即无法找到一组未知变量的取值,使得所有方程都得到满足,则该方程组是不相容的。
在数学上,一个线性方程组是不相容的当且仅当该方程组的增广矩阵的秩大于系数矩阵的秩。增广矩阵是由系数矩阵和常数项组成的扩展矩阵。
当线性方程组是不相容的时,这意味着方程之间存在矛盾或冲突。例如,一个方程要求一个变量取某个值,而另一个方程却要求该变量取另一个不同的值,因此无法找到一个满足所有方程的解。
对于不相容方程组,不存在精确解。然而,有时候我们可以通过最小二乘法或其他优化方法来找到一个近似解,该解最小化方程组的残差。
2.4.2 超定/欠定方程组
- 1 超定方程组(m>n)
超定线性方程组是指方程数量大于未知变量数量的线性方程组。具体而言,对于一个 m × n m × n m×n的系数矩阵 A ( m > n ) A(m > n) A(m>n),超定线性方程组的形式为 A X = b AX = b AX=b,其中 X 是一个 n 维列向量表示未知变量, b b b 是一个 m 维列向量表示常数项。
由于方程数量多于未知变量的数量,超定线性方程组通常没有精确解。这意味着无法找到一个满足所有方程的未知变量值。然而,在某些情况下,我们仍然可以寻找一个近似解来最小化方程的残差。
超定线性方程组的解可以通过最小二乘法来求解。最小二乘法的目标是最小化残差向量 r = b − A X r = b - AX r=b−AX 的二范数,即 m i n ∣ ∣ r ∣ ∣ 2 min ||r||_2 min∣∣r∣∣2。这样可以得到一个最优的近似解 X ∗ X^{*} X∗,使得 A X ∗ AX^* AX∗ 接近 b b b。
最小二乘法可以通过求解正规方程组 A T ∗ A ∗ X = A T ∗ b A^T * A * X = A^T * b AT∗A∗X=AT∗b来得到近似解 X ∗ X^* X∗。在超定情况下,正规方程组的系数矩阵 A T ∗ A A^T * A AT∗A 是一个$ n × n$ 的方阵,可以是非奇异的,从而有唯一解。
- 2 欠定方程组
如果 m < n m < n m<n,即方程数量少于未知变量的数量,那么我们称这个线性方程组为欠定线性方程组。
在欠定线性方程组中,未知变量的数量多于方程的数量,因此无法通过常规的解法得到唯一的解。实际上,欠定线性方程组通常存在无穷多个解,也就是说,可以找到无数个满足所有方程的未知变量组合。
在求解欠定线性方程组时,我们通常会寻找满足特定条件的最优解。这些条件可以是最小范数、最小二范数、最小一范数等。根据所选择的条件不同,可以得到不同的最优解。
为了求解欠定线性方程组,常用的方法包括最小二乘法、正则化方法和压缩感知方法。最小二乘法通过最小化残差向量的二范数来寻找最优解。正则化方法引入额外的约束条件来获得更加稳定的解。压缩感知方法利用稀疏表示和稀疏恢复算法来找到稀疏解。
需要注意的是,由于欠定线性方程组存在无穷多个解,我们在求解时通常需要添加额外的约束或使用先验知识来确定最合适的解。这是因为在没有足够的信息约束的情况下,我们无法得到唯一的解。
- 3 A为方阵
如果 m = n,即方程数量等于未知变量的数量,那么我们称这个线性方程组为方程数量等于未知变量数量的方程组。
在这种情况下,方程组可能有唯一解、无解或无穷多个解,具体取决于系数矩阵 A 的特性。
- 如果系数矩阵 A 是非奇异的(可逆矩阵),那么方程组有唯一解。这意味着可以找到一个确定的未知变量值,使得方程组中的每个方程都得到满足。
- 如果系数矩阵 A 是奇异的(不可逆矩阵),那么方程组可能无解或者有无穷多个解。无解意味着无法找到满足所有方程的未知变量值。有无穷多个解意味着可以找到无数个满足所有方程的未知变量组合。
2.4.3 正规方程组
正规方程组是最小二乘问题的一种解法,用于求解形如$ Ax = b$ 的线性方程组,其中 A A A 是一个 m × n m × n m×n 的矩阵, x x x 是一个 n n n 维向量,$b 是一个 是一个 是一个m$ 维向量。
正规方程组的形式是 A T ∗ A ∗ x = A T ∗ b A^T * A * x = A^T * b AT∗A∗x=AT∗b,其中 $A^T $是 A 的转置。解 x 可以通过求解正规方程组得到。
具体求解步骤如下:
- 确保 A T ∗ A A^T * A AT∗A 是可逆的或非奇异的。如果 A T ∗ A A^T * A AT∗A 是奇异的,即它的行列式为零,那么正规方程组可能没有解,或者有无穷多个解。
- 计算 A T ∗ A A^T * A AT∗A 和 A T ∗ b A^T * b AT∗b。
- 解正规方程组 A T ∗ A ∗ x = A T ∗ b A^T * A * x = A^T * b AT∗A∗x=AT∗b。常用的求解方法包括直接求解法(如LU分解、QR分解等)和迭代法(如共轭梯度法、最小二乘迭代法等)。
- 得到最小二乘问题的近似解 x̂。
正规方程组的解 x ^ x̂ x^是最小化残差向量 r = b − A x ^ r = b - Ax̂ r=b−Ax^的二范数的最优解。然而,需要注意的是,直接求解正规方程组的方法在矩阵 A A A 的条件数较大时可能导致数值不稳定的结果,这种情况下可以考虑使用其他数值稳定的方法,如奇异值分解(SVD)。
3 最小二乘法
最小二乘法建模常见于线性(非线性)方程问题中 f i ( x ) : R n → R , i = 1 , 2 , ⋯ , m f_{i}(x)\colon\mathbb{R}^{n}\to\mathbb{R},i=1,2,\cdots,m fi(x):Rn→R,i=1,2,⋯,m 为n元函数(m×n矩阵),且有如下方程组:
b i = f i ( x ) , i = 1 , 2 , ⋯ , m , b_{i}=f_{i}(x),\quad i=1,2,\cdots,m, bi=fi(x),i=1,2,⋯,m,
其中 b i ∈ R b_i∈R bi∈R 是已知的实数.方程组的求解在实际中应用广泛,但这个问题并不总是可解的.
首先,方程组的个数 m 可以超过自变量个数 n(超定方程),因此方程组的解可能不存在;其次,由于测量误差等因素,方程组的等式关系可能不是精确成立的.为了能在这种实际情况下求解出 x,最小二乘法的思想是极小化误差2范数平方,即
min x ∈ R n ∑ i = 1 m ( b i − f i ( x ) ) 2 . \min\limits_{x\in\mathbb{R}^n}\quad\sum\limits_{i=1}^m(b_i-f_i(x))^2. x∈Rnmini=1∑m(bi−fi(x))2.
若方程存在解,则求解问题的全局最优解就相当于求出了方程的解;当方程的解不存在时,实际给出了某种程度上误差最小的解.
最小二乘并不一定是合理的,有时候会根据1范数和无穷范数来构建数学模型:
保证偏差的绝对值之和最小
min x ∈ R n ∑ i = 1 m ∣ b i − f i ( x ) ∣ ; \min\limits_{x\in\mathbb{R}^n}\quad\sum\limits_{i=1}^m|b_i-f_i(x)|; x∈Rnmini=1∑m∣bi−fi(x)∣;
保证最大偏差最小化
min x ∈ R n max i ∣ b i − f i ( x ) ∣ . \begin{aligned} & \operatorname*{min}_{x\in\mathbb{R}^{n}} & \max\limits_{i}|b_i-f_i(x)|. \\ & \end{aligned} x∈Rnminimax∣bi−fi(x)∣.
注意,如果噪声服从高斯分布,那么最小二乘问题的解对应于原问题的最大似然解。
3.1 线性最小二乘法
如果上面的二次项都是线性函数,那么就是线性最小二乘法,比如线性回归模型。
线性回归模型为 Y = H x + e Y=Hx+e Y=Hx+e, 模型的基本假设有
- 假设1:解释变量X是确定性变量,不是随机变量;
- 假设2: e ~N(0,∑) 正态分布, ∑ ∑ ∑是对称矩阵
这里因为是线性的,且噪声服从高斯部分,那么由上面可知,最小二乘解即对应最大似然解!下面分析最大似然.首先,Y是服从下式的高斯分布的:
p ( y i ∣ h i ; x ) = 1 2 π σ 2 exp ( − ( y i − h i T x ) 2 2 σ 2 ) , p(y_i\mid h_i;x)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left(-\frac{(y_i-h_i^{\text{T}}x)^2}{2\sigma^2}\right), p(yi∣hi;x)=2πσ21exp(−2σ2(yi−hiTx)2),
通过对数似然函数分析极值
ℓ ( x ) = ln ∏ i = 1 m p ( y i ∣ h i ; x ) = − m 2 ln ( 2 π ) − m ln σ − ∑ i = 1 m ( y i − h i T x ) 2 2 σ 2 . \ell(x)=\ln\prod\limits_{i=1}^{m}p(y_i\mid h_i;x)=-\frac{m}{2}\ln(2\pi)-m\ln\sigma-\sum\limits_{i=1}^{m}\frac{(y_i-h_i^{\mathrm{T}}x)^2}{2\sigma^2}. ℓ(x)=lni=1∏mp(yi∣hi;x)=−2mln(2π)−mlnσ−i=1∑m2σ2(yi−hiTx)2.
很明显,上面这个式子只有最后一项是和x有关系的,所以我们只需要求最小二乘解,便可知最大似然解!注意这里的方差 σ 2 \sigma^2 σ2,这里的高斯分布是一维的,所以实际考虑并不需要考虑方差,因为它只是一个常数,不会对最小值造成影响。就比如这一章曲线拟合的问题中,实际上给出了方差 σ 2 = 1 \sigma^2 = 1 σ2=1,它会对模型的最小值产生影响,但不会对取得最小值处的参数值 x i x_i xi产生影响。具体请见后面分析。
关于最小二乘法的求解
所以可以直接通过求导,令导数为0求出最优解
f ( x ∗ ) = e T Σ − 1 e = ( Y − H x ) T Σ − 1 ( Y − H x ) \begin{gathered} f(x*)=e^{\mathrm{T}}\Sigma^{-1}e =(Y-Hx)^{\mathrm{T}}\Sigma^{-1}(Y-Hx) \\ \end{gathered} f(x∗)=eTΣ−1e=(Y−Hx)TΣ−1(Y−Hx)
线性最小二乘法的唯一解(通解):
x ∗ = ( H T Σ − 1 H ) − 1 H T Σ − 1 Y x^*=(H^{\mathrm T}\Sigma^{-1}H)^{-1}H^{\mathrm T}\Sigma^{-1}Y x∗=(HTΣ−1H)−1HTΣ−1Y
求解方法1:把每一部分展开
∣ ∣ y − H x ∣ ∣ Σ − 1 2 = ( y − H x ) T Σ − 1 ( y − H x ) = y T Σ − 1 y − 2 x T H T Σ − 1 y + x T H T Σ − 1 H x \begin{aligned} &||y-Hx||_{\Sigma^{-1}}^2=(y-Hx)^T\Sigma^{-1}(y-Hx)=y^T\Sigma^{-1}y-2x^T H^T\Sigma^{-1}y \\ &+x^TH^T\Sigma^{-1}Hx \end{aligned} ∣∣y−Hx∣∣Σ−12=(y−Hx)TΣ−1(y−Hx)=yTΣ−1y−2xTHTΣ−1y+xTHTΣ−1Hx
− 2 H T Σ − 1 y + 2 H T Σ − 1 H x = 0 ⇒ H T Σ − 1 H x = H T Σ − 1 y -2H^{T}\Sigma^{-1}y+2H^{T}\Sigma^{-1}H x=0\Rightarrow H^{T}\Sigma^{-1}H x=H^{T}\Sigma^{-1}y −2HTΣ−1y+2HTΣ−1Hx=0⇒HTΣ−1Hx=HTΣ−1y
x = ( H T Σ − 1 H ) − 1 H T Σ − 1 y x =(H^{T}\Sigma^{-1}H)^{-1}H^{T}\Sigma^{-1}y x=(HTΣ−1H)−1HTΣ−1y
求解方法2:链式法则:这里是分母布局
令 f = ( y − H x ) T Σ − 1 ( y − H x ) = e T Σ − 1 e 令f=(y-Hx)^{T}\Sigma^{-1}(y-Hx)=e^{T}\Sigma^{-1}e 令f=(y−Hx)TΣ−1(y−Hx)=eTΣ−1e
∂ f ∂ x = ∂ ( y − H x ) ∂ x ⋅ ∂ f ∂ ( y − H x ) = H T ⋅ 2 ⋅ Σ − 1 ( y − H x ) = 0 \frac{\partial f}{\partial x}=\frac{\partial\left(y-Hx\right)}{\partial x}\cdot\frac{\partial f}{\partial\left(y-Hx\right)}\\ = H^{T}\cdot2\cdot\Sigma^{-1}(y-Hx)=0 ∂x∂f=∂x∂(y−Hx)⋅∂(y−Hx)∂f=HT⋅2⋅Σ−1(y−Hx)=0
H T Σ − 1 y = H T Σ − 1 H x H^{T}\Sigma^{-1}y=H^{T}\Sigma^{-1}Hx HTΣ−1y=HTΣ−1Hx
x = ( H T Σ − 1 H ) − 1 H T Σ − 1 y x =(H^{T}\Sigma^{-1}H)^{-1}H^{T}\Sigma^{-1}y x=(HTΣ−1H)−1HTΣ−1y
3.2 多元函数导数、方向导数、梯度
一元函数的导数就是直接求导,而多元函数在一点处的导数则是分别对变量x,y,…求偏导数。比如下面z=x^2+ y^2在一点处导数。对x和y的偏导数就是用x轴平面和y轴平面来切割,切割会有一条曲线形成,这条曲线上的点的导数都是对应于x,y的导数。

方向导数的直观理解就是,对任意方向L上的导数,上面x和y方向就是它的特例。

梯度,实际上就是函数在x,y处偏导数(以二元函数为例)的向量。当方向导数L对应的方向与梯度一致时,方向导数取得最大值。因为cos(o) = 1,即夹角是0.这个说明了一个很重要的事情,就是说这个函数在当前方向L上的导数是最大的(正),沿着这个方向函数必然是增大的。即梯度方向是函数值上升最快的方向。我们在最小二乘法中利用梯度下降,即反向梯度,函数值减小最快方向。所以这里是非常重要的!

之所以能够引出上面梯度的结论,是因为方向导数 = 梯度 * (cosa, cosb)= 梯度的模长绝对值 * cos(夹角)。就是两个向量的内积形式。方向导数的模长为1。

3.3 非线性最小二乘法
最小二乘法基本形式如下,通常就是一个误差函数向量的2-范数的平方,即对应每一个元素的平方。如果这个函数比较简单,比如f(x) = x*x,那么我们直接求导就知道它的最大值。但很多时候函数比较复杂,求导行不通。
min x F ( x ) = 1 2 ∥ f ( x ) ∥ 2 2 \min _{\boldsymbol{x}} F(\boldsymbol{x})=\frac{1}{2}\|f(\boldsymbol{x})\|_2^2 xminF(x)=21∥f(x)∥22
为了解决无法求导的问题,可以选择迭代法。这里是书上的一个解释,实际上迭代要联系后面的梯度下降算法。我们在x处沿着反向梯度方向,步长为d。通过不停迭代的方式一定可以找到最小值。这里说增量足够小时停止迭代也是可以理解的,就是到当前迭代时,在沿着梯度方向改变相应增量已经变化不大,这个时候就要退出了。实际中可能有精度要求,或者说已经无法取得更小的函数值的时候。

3.4 梯度下降算法
我们把F(x)泰勒展开,得到下式(两种形式,自由转换 a = a k + Δ a k a = a_k + Δa_k a=ak+Δak),其中 J J J是雅可比矩阵,也即梯度和一阶导数。H是海塞矩阵,就是二阶导。
下面这两个式子在同一点 a k a_k ak处的展开式,通常都写第二种,书上写的是第一种。注意这里是多元泰勒展开。
F ( a k + Δ a k ) ≈ F ( a k ) + J ( a k ) T Δ a k + 1 2 Δ a k T H ( a k ) Δ a k . F\left(\boldsymbol{a}_k+\Delta \boldsymbol{a}_k\right) \approx F\left(\boldsymbol{a}_k\right)+\boldsymbol{J}\left(\boldsymbol{a}_k\right)^{\mathrm{T}} \Delta \boldsymbol{a}_k+\frac{1}{2} \Delta \boldsymbol{a}_k^{\mathrm{T}} \boldsymbol{H}\left(\boldsymbol{a}_k\right) \Delta \boldsymbol{a}_k . F(ak+Δak)≈F(ak)+J(ak)TΔak+21ΔakTH(ak)Δak.
F ( a ) ≈ F ( a k ) + J ( a k ) T ( a − a k ) + 1 2 ( a − a k ) T H ( a k ) ( a − a k ) . F(\boldsymbol{a}) \approx F\left(\boldsymbol{a}_k\right)+\boldsymbol{J}\left(\boldsymbol{a}_k\right)^{\mathrm{T}} (\boldsymbol{a}- \boldsymbol{a}_k)+\frac{1}{2} (\boldsymbol{a}- \boldsymbol{a}_k)^{\mathrm{T}} \boldsymbol{H}\left(\boldsymbol{a}_k\right) (\boldsymbol{a}- \boldsymbol{a}_k) . F(a)≈F(ak)+J(ak)T(a−ak)+21(a−ak)TH(ak)(a−ak).
如果只使用一阶导数,那么就是一阶梯度下降。方向梯度*步长即得到增量,然后在求此时函数相应的参数。*表示多个参数。
注意,书上是x。但我认为写x容易使得参数abc…和真正的变量混肴。所以我统一改为了a。就是表明我们实际上是对参数求得导数,而不是对自变量x求得导数。对abc等参数求导,是在求解同一自变量的条件下,沿着梯度下降方向,寻找一个最合适的参数,使得误差函数值最小!当然这里负号并不意味着它一定是让参数的绝对值变小,不要混肴参数值变小和误差函数变小两个概念!
Δ a ∗ ( 参数变化量 ) = − J ( a k ) ∗ 步长 . \Delta \boldsymbol{a}^* (参数变化量)=-\boldsymbol{J}\left(\boldsymbol{a}_k\right) *步长. Δa∗(参数变化量)=−J(ak)∗步长.
二阶梯度下降,即使用二阶导数。下面式子的意思是,在目标函数(右)最小时,参数的变化取值。
Δ a ∗ = arg min ( F ( a ) + J ( a ) T Δ a + 1 2 Δ a T H Δ a ) . \Delta \boldsymbol{a}^*=\arg \min \left(F(\boldsymbol{a})+\boldsymbol{J}(\boldsymbol{a})^{\mathrm{T}} \Delta \boldsymbol{a}+\frac{1}{2} \Delta \boldsymbol{a}^{\mathrm{T}} \boldsymbol{H} \Delta \boldsymbol{a}\right) . Δa∗=argmin(F(a)+J(a)TΔa+21ΔaTHΔa).
对上面式子求导Δa的导数,且令式子为0(解释一下求导的过程,第一项肯定为0,第二项可以看作是两个列向量的内积,所以 J J J取得是转置,求导后就剩下 J J J(见矩阵求导法则,分母布局),第三项类似二次型一样,黑塞矩阵是实对称正定阵,直接套公式)
J + H Δ a = 0 ⇒ H Δ a = − J . J+H \Delta a=0 \Rightarrow \boldsymbol{H} \Delta a=-J . J+HΔa=0⇒HΔa=−J.
求完上面式子之后,就可以得到增量。这种方法叫做牛顿法,但H比较难计算,一般不用。一阶梯度法过于贪心,反而可能增加迭代次数。所以,我们一般使用下面改良的高斯牛顿法。
3.5 高斯牛顿法
我们在这里直接分析误差函数f(x),而不是目标函数F(x)。注意这里的雅可比只是形式上和原先相同,但实际上是两个不同函数的一阶导数!
f ( a + Δ a ) ≈ f ( a ) + J ( a ) T Δ a . f(\boldsymbol{a}+\Delta \boldsymbol{a}) \approx f(\boldsymbol{a})+\boldsymbol{J}(\boldsymbol{a})^{\mathrm{T}} \Delta \boldsymbol{a} . f(a+Δa)≈f(a)+J(a)TΔa.
寻找一个参数增量Δa,使得误差函数最小,写成下面最小二乘法形式
Δ a ∗ = arg min Δ a 1 2 ∥ f ( a ) + J ( a ) T Δ a ∥ 2 . \Delta \boldsymbol{a}^*=\arg \min _{\Delta \boldsymbol{a}} \frac{1}{2}\left\|f(\boldsymbol{a})+\boldsymbol{J}(\boldsymbol{a})^{\mathrm{T}} \Delta \boldsymbol{a}\right\|^2 . Δa∗=argΔamin21 f(a)+J(a)TΔa 2.
把右边的最小二乘展开,看作两个向量的内积,即向量转置*向量本身
1 2 ∥ f ( x ) + J ( x ) T Δ x ∥ 2 = 1 2 ( f ( x ) + J ( x ) T Δ x ) T ( f ( x ) + J ( x ) T Δ x ) = 1 2 ( ∥ f ( x ) ∥ 2 2 + 2 f ( x ) J ( x ) T Δ x + Δ x T J ( x ) J ( x ) T Δ x ) . \begin{aligned} \frac{1}{2}\left\|f(\boldsymbol{x})+\boldsymbol{J}(\boldsymbol{x})^{\mathrm{T}} \Delta \boldsymbol{x}\right\|^2 & =\frac{1}{2}\left(f(\boldsymbol{x})+\boldsymbol{J}(\boldsymbol{x})^{\mathrm{T}} \Delta \boldsymbol{x}\right)^{\mathrm{T}}\left(f(\boldsymbol{x})+\boldsymbol{J}(\boldsymbol{x})^{\mathrm{T}} \Delta \boldsymbol{x}\right) \\ & =\frac{1}{2}\left(\|f(\boldsymbol{x})\|_2^2+2 f(\boldsymbol{x}) \boldsymbol{J}(\boldsymbol{x})^{\mathrm{T}} \Delta \boldsymbol{x}+\Delta \boldsymbol{x}^{\mathrm{T}} \boldsymbol{J}(\boldsymbol{x}) \boldsymbol{J}(\boldsymbol{x})^{\mathrm{T}} \Delta \boldsymbol{x}\right) . \end{aligned} 21 f(x)+J(x)TΔx 2=21(f(x)+J(x)TΔx)T(f(x)+J(x)TΔx)=21(∥f(x)∥22+2f(x)J(x)TΔx+ΔxTJ(x)J(x)TΔx).
求导和之前的很像,得到Δa的线性方程组,也叫增量方程。也叫高斯牛顿方程或正规方程。
J ( x ) f ( x ) + J ( x ) J T ( x ) Δ x = 0. J ( x ) J T ⏟ H ( x ) ( x ) Δ x = − J ( x ) f ( x ) ⏟ g ( x ) . \begin{aligned} &\boldsymbol{J}(\boldsymbol{x}) f(\boldsymbol{x})+\boldsymbol{J}(\boldsymbol{x}) \boldsymbol{J}^{\mathrm{T}}(\boldsymbol{x}) \Delta \boldsymbol{x}=\mathbf{0} .\\ &\underbrace{\boldsymbol{J}(\boldsymbol{x}) \boldsymbol{J}^{\mathrm{T}}}_{\boldsymbol{H}(\boldsymbol{x})}(\boldsymbol{x}) \Delta \boldsymbol{x}=\underbrace{-\boldsymbol{J}(\boldsymbol{x}) f(\boldsymbol{x})}_{\boldsymbol{g}(\boldsymbol{x})} . \end{aligned} J(x)f(x)+J(x)JT(x)Δx=0.H(x) J(x)JT(x)Δx=g(x) −J(x)f(x).
H Δ x = g H \Delta x=g HΔx=g
- 缺点

证明 ( A T ∗ A ) (A^T * A) (AT∗A)是半正定的,我们需要证明对于任意非零向量 x x x,都有 x T ∗ ( A T ∗ A ) ∗ x ≥ 0 x^T * (A^T * A) * x ≥ 0 xT∗(AT∗A)∗x≥0。
首先,我们可以注意到 ( A T ∗ A ) (A^T * A) (AT∗A) 是一个对称矩阵,因为 ( A T ∗ A ) T = A T ∗ ( A T ) T = A T ∗ A (A^T * A)^T = A^T * (A^T)^T = A^T * A (AT∗A)T=AT∗(AT)T=AT∗A。
然后,我们来证明它是半正定的:
对于任意非零向量 x x x,有 x T ∗ ( A T ∗ A ) ∗ x = ( A ∗ x ) T ∗ ( A ∗ x ) x^T * (A^T * A) * x = (A * x)^T * (A * x) xT∗(AT∗A)∗x=(A∗x)T∗