朴素贝叶斯:基于概率论的分类模型
欢迎关注”生信修炼手册”!
朴素贝叶斯是建立在贝叶斯定理上的一种分类模型,贝叶斯定理是条件概率的一种计算方式,公式如下
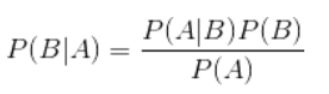
通过比较不同事件发生的概率,选取概率大的事件作为最终的分类。在朴素贝叶斯中, 为了简化计算,假设各个特征之间相互独立, 这也是为何称之为"朴素"的原因。
以下列数据为例,这是一份统计早上是否出去打高尔夫的样本数据,相关的特征有4个
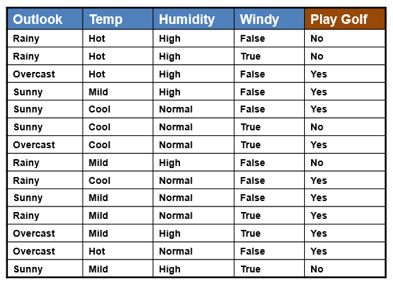
对于一个新的数据点,4个特征的取值分别为sunny, hot, high, false, 求该样本play golf为yes的概率, 通过贝叶斯定理计算如下
P(yes|sunny, hot, high, false) = P(sunny, hot, high, false|yes) * P(yes) / P(sunny, hot, high, false)
=P(sunny|yes) * P(hot|yes) * P(high|yes) * P(false|yes) * P(play) / (P(sunny) * P(hot) * P(high) * P(false))此时,只需要利用输入的样本数据来计算各个概率,以sunny相关的概率为例,计算过程如下

根据大数定理,直接用样本中的频数作为概率,简单统计一下,就可以得到各个条件概率。
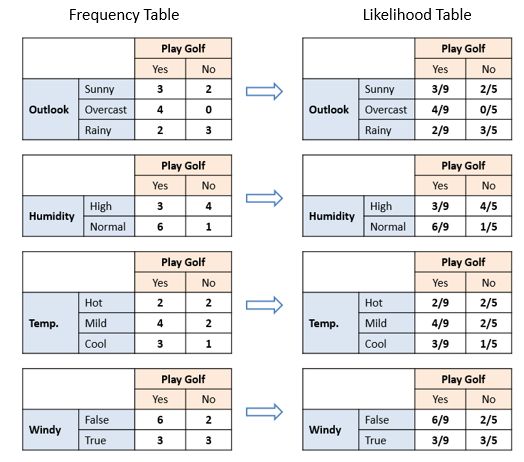
带入公式就可以算出具体的概率值
# P(yes|sunny, hot, high, false)>>> (3/9) * (2/9) * (3/9) * (6/9) * (9/14) / ((5/14) * (4/14) * (7/14) * (8/14))0.36296296296296293# P(no|sunny, hot, high, false)
>>> (2/5) * (2/5) * (4/5) * (2/5) * (5/14) / ((5/14) * (4/14) * (7/14) * (8/14))
0.6272000000000002很明显,对于该新的数据点,分为no的概率值更大,所以通过朴素贝叶斯分类就将该数据点划分为no。
在统计概率的过程中,会遇到某个条件组合的频数为0的情况,称之为零概率问题,此时直接带入公式会导致整个概率为零。为了解决这个问题,拉普拉斯提出了一种做法,直接加1,这样在样本量较多的情况下,并不会对结果产生非常大的影响,这种方法称之为拉普拉斯平滑, 具体的做法如下

将所有的计数都加1,然后再来计数对应的概率

对于离散型变量,直接统计频数分布就可以了。对于连续型的变量,为了计算对应的概率,此时又引入了一个假设,假设特征的分布为正态分布,计算样本的均值和方差,然后通过密度函数计算取值时对应的概率
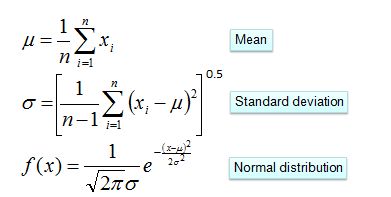
示例如下
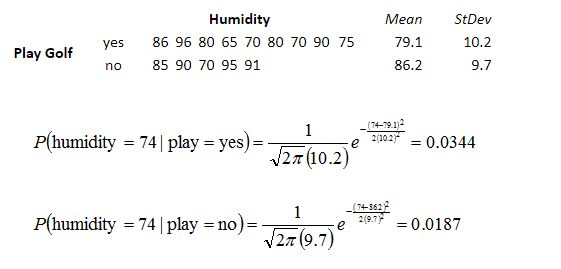
从上面的例子可以看出,朴素贝叶斯假设样本特征相互独立,而且连续型的特征分布符合正态分布,这样的假设前提是比较理想化的,所以称之为"朴素"贝叶斯,因为实际数据并不一定会满足这样的要求。
在scikit-learn中,根据数据的先验分布,提供了以下多种朴素贝叶斯的方法
1. GaussianNB, 基于高斯分布的朴素贝叶斯
2. MultinomialNB, 基于多项式分布的朴素贝叶斯
3. BernoulliNB,基于二项分布的朴素贝叶斯
4. CategoricalNB, 基于离散型的朴素贝叶斯
以GaussianNB为例,用法如下
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.naive_bayes import GaussianNB
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
>>> gnb = GaussianNB()
>>> y_pred = gnb.fit(X_train, y_train).predict(X_test)朴素贝叶斯算法原理简单,计算高效,分类效果较为稳定,但是由于存在各种先验假设,会导致一定的分类错误率。
·end·
—如果喜欢,快分享给你的朋友们吧—
原创不易,欢迎收藏,点赞,转发!生信知识浩瀚如海,在生信学习的道路上,让我们一起并肩作战!
本公众号深耕耘生信领域多年,具有丰富的数据分析经验,致力于提供真正有价值的数据分析服务,擅长个性化分析,欢迎有需要的老师和同学前来咨询。
更多精彩
KEGG数据库,除了pathway你还知道哪些
全网最完整的circos中文教程
DNA甲基化数据分析专题
突变检测数据分析专题
mRNA数据分析专题
lncRNA数据分析专题
circRNA数据分析专题
miRNA数据分析专题
单细胞转录组数据分析专题
chip_seq数据分析专题
Hi-C数据分析专题
HLA数据分析专题
TCGA肿瘤数据分析专题
基因组组装数据分析专题
CNV数据分析专题
GWAS数据分析专题
2018年推文合集
2019年推文合集
2020推文合集
写在最后
转发本文至朋友圈,后台私信截图即可加入生信交流群,和小伙伴一起学习交流。
扫描下方二维码,关注我们,解锁更多精彩内容!

一个只分享干货的
生信公众号