SparkStreaming 整合 Kafka
Spark Streaming 整合 Kafka 架构概述
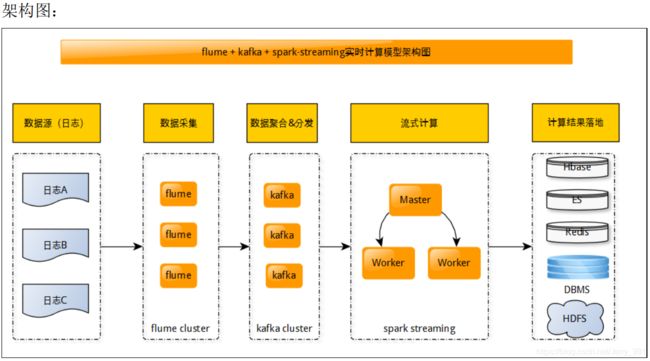
具体实现步骤
- 安装好 ZooKeeper 和 Kafka 和 flume
- 启动好 ZooKeeper 和 Kafka
- 创建一个 Kafka 的 Topic
############ 启动 kafka ############
nohup kafka-server-start.sh \
/home/hadoop/apps/kafka_2.11-1.1.0/config/server.properties \
1>/home/hadoop/logs/kafka_std.log \
2>/home/hadoop/logs/kafka_err.log &
############ 显示所有 kafka 的 topic ############
kafka-topics.sh \
--list \
--zookeeper hadoop02:2181,hadoop03:2181,hadoop04:2181
############ 创建一个 kafka topic ############
kafka-topics.sh \
--create \
--zookeeper hadoop02:2181,hadoop03:2181,hadoop04:2181 \
--replication-factor 3 \
--partitions 3 \
--topic flume_kafka
############ 显示一个 kafka topic 的详细信息 ############
kafka-topics.sh \
--zookeeper hadoop02:2181,hadoop03:2181,hadoop04:2181 \
--describe \
--topic flume_kafka4. 配置 flume 采集方案
Flume 采集方案分为两级架构:
第一级:exec-avro.conf
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1
#define sources
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/hadoop/logs/flume.log
#define channels
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
#define sink
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoop05
agent1.sinks.k1.port = 44444
#bind sources and sink to channel
agent1.sources.r1.channels = c1
agent1.sinks.k1.channel = c1第二级:avro-kafka.conf
agent2.sources = r2
agent2.channels = c2
agent2.sinks = k2
#define sources
agent2.sources.r2.type = avro
agent2.sources.r2.bind = hadoop05
agent2.sources.r2.port = 44444
#define channels
agent2.channels.c2.type = memory
agent2.channels.c2.capacity = 1000
agent2.channels.c2.transactionCapacity = 100
#define sink
agent2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
agent2.sinks.k2.brokerList = hadoop02:9092,hadoop03:9092,hadoop04:9092
agent2.sinks.k2.topic = flume-kafka
agent2.sinks.k2.batchSize = 4
agent2.sinks.k2.requiredAcks = 1
#bind sources and sink to channel
agent2.sources.r2.channels = c2
agent2.sinks.k2.channel = c25. 启动 flume
flume-ng agent \
--conf /home/hadoop/apps/apache-flume-1.8.0-bin/conf/ \
--name agent2 \
--conf-file /home/hadoop/apps/apache-flume-1.8.0-bin/agentconf/avro-kafka.conf \
-Dflume.root.logger=DEBUG,console
flume-ng agent \
--conf /home/hadoop/apps/apache-flume-1.8.0-bin/conf/ \
--name agent1 \
--conf-file /home/hadoop/apps/apache-flume-1.8.0-bin/agentconf/exec-avro.conf \
-Dflume.root.logger=DEBUG,console6. 启动一个 kafka consumer
kafka-console-consumer.sh \
--bootstrap-server hadoop02:9092,hadoop03:9092,hadoop04:9092 \
--from-beginning \
--topic flume-kafka7. 根据采集方案测试 flume 采集数据到 kafka 是否成功
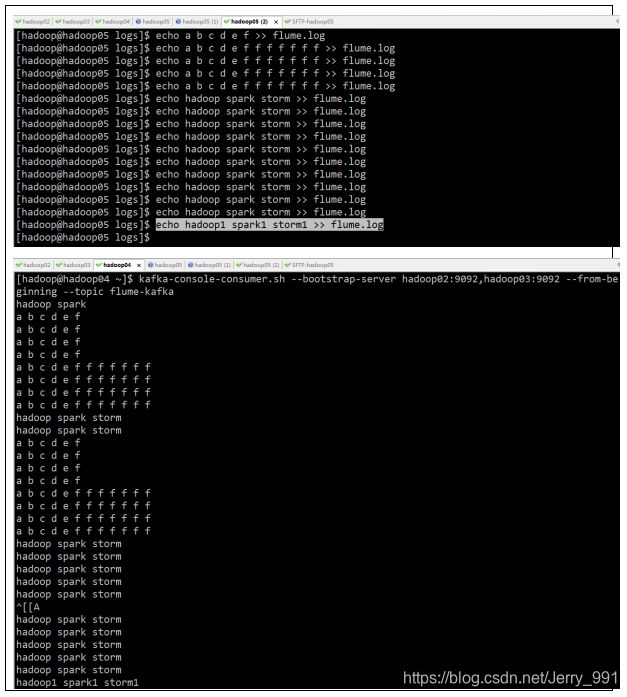
8. 编写 SparkStreaming 程序消费 kafka 中的数据
两种方式:
第一种:receiver 方式
package com.aura.mazh.sparkstreaming.kafka
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 描述: 使用 Receiver 方式整合 Kafka
*/
object SparkStreamDemo_Receiver {
def main(args: Array[String]) {
/**
* 第一步: 获取程序入口, 设置一些必要的参数
*/
//System.setProperty("HADOOP_USER_NAME", "hadoop")
val conf = new SparkConf()
conf.setAppName("SparkStreamDemo_Receiver")
conf.setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setCheckpointDir("hdfs://myha01/flume-kafka-receiver")
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
/**
* 第二步: 连接和读取 kafka 的数据
*/
val topics = Map("flume-kafka" -> 3)
val lines = KafkaUtils.createStream(ssc,"hadoop02:2181,hadoop03:2181,hadoop04:2181", "flume-kafka-group1", topics).map(_._2)
/**
* 第三步: 对数据进行处理
*/
val ds1 = lines.flatMap(_.split(" ")).map((_, 1))
val ds2 = ds1.updateStateByKey[Int]((x:Seq[Int], y:Option[Int]) => {
Some(x.sum + y.getOrElse(0))
})
ds2.print()
/**
* 第四步: 启动 sparkStreaming 应用程序
*/
ssc.start()
ssc.awaitTermination()
}
}第二种方式:direct 方式
package com.aura.mazh.sparkstreaming.kafka
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 描述: 使用 Direct 方式整合 Kafka
*/
object SparkStreamDemo_Direct {
def main(args: Array[String]): Unit = {
/**
* 第一步: 获取程序入口, 设置一些必要的参数
*/
System.setProperty("HADOOP_USER_NAME", "hadoop")
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamDemo_Direct")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(2))
ssc.checkpoint("hdfs://myha01/flume-kafka-direct")
/**
* 第二步: 连接和读取 kafka 的数据
*
* def createDirectStream[K: ClassTag,V: ClassTag,KD <: Decoder[K]:ClassTag,VD <:Decoder[V]: ClassTag] (
* ssc: StreamingContext,
* kafkaParams: Map[String, String],topics: Set[String]
* )
*/
val kafkaParams = Map("metadata.broker.list" -> "hadoop2:9092,hadoop03:9092,hadoop04:9092")
val topics = Set("flume-kafka")
val kafkaDStream: DStream[String] = KafkaUtils.createDirectStream[String,String, StringDecoder, StringDecoder](ssc, kafkaParams, topics).map(_._2)
/**
* 第三步: 对数据进行处理
*/
kafkaDStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
/**
* 第四步: 启动 sparkStreaming 应用程序
*/
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}9. 测试
依次把 zookeeper,flume,kafka,sparkStreaming 应用程序启动起来。然后继续构造数据,看最后的 sparkStreaming 程序是否消费到了数据
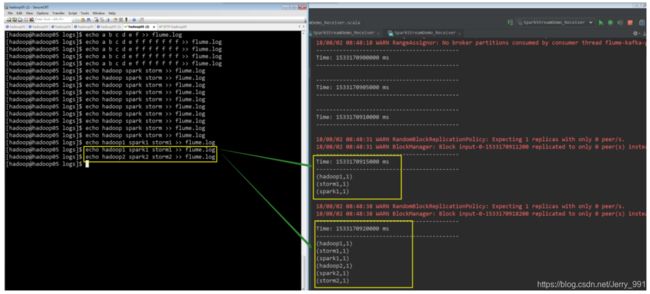
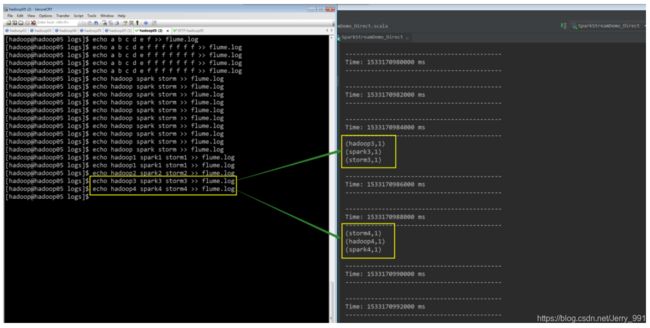
(写在最后:欢迎指正……)