【Java 数据结构】集合类 (精华篇)

点进来你就是我的人了
博主主页:戳一戳,欢迎大佬指点!欢迎志同道合的朋友一起加油喔

目录
前言
一.集合的引入
二. 集合的使用
1. Collection接口中的方法
2.Collection的主要实现类特点
3. Iterator 迭代器的使用
4. Iterator 迭代器的原理
5. List(接口)
6. Set(接口)
7.Queue(接口)
8、Map
三. List集合中:ArrayList 、LinkedList、Vector区别
四. Set集合中:HashSet、TreeSet
TreeSet
HashSet
五. Map:HashMap、TreeMap
HashMap底层原理
JDK7中:
JDK8中: 与JDK7三点不一样
TreeMap底层原理
六. 集合的线程安全
线程安全的集合
将线程不安全的集合转换为安全的
七. Collections工具类
八. Arrays工具类
前言
本章主要是让大家先了解一下集合类的由来和用法,并简单的介绍一下各个集合类的区别,后续我会对每个集合类的底层源码做一个详细的解释!
一.集合的引入
【1】数组,集合都是对多个数据进行存储操作的,简称为容器。
PS:这里的存储指的是内存层面的存储,而不是持久化存储(.txt,.avi,.jpg,数据库)。
【2】数组:特点:
(1)数组一旦指定了长度,那么长度就被确定了,不可以更改。
int[] arr = new int[6];
(2)数组一旦声明了类型以后,数组中只能存放这个类型的数据。数组中只能存放同一种类型的数据。
int[] arr,String[] s,double[] d.....
【3】数组:缺点:
(1)数组一旦指定了长度,那么长度就被确定了,不可以更改。
(2)删除,增加元素 效率低。
(3)数组中实际元素的数量是没有办法获取的,没有提供对应的方法或者属性来获取
(4)数组存储:有序,可重复 ,对于无序的,不可重复的数组不能满足要求。
【4】正因为上面的缺点,引入了一个新的存储数据的结构---》集合
【5】集合一章我们会学习很多集合,为什么要学习这么多集合呢?
因为不同集合底层数据结构不一样。集合不一样,特点也不一样
Collection体系继承树:

蓝色框:接口 红色框:实现类 红色框+阴影:常用实现类
Queue:先进先出的队列。
stack:先进后出的栈
Map体系继承树:

蓝色框:接口 红色框:实现类 红色框+阴影:常用实现类
Map:具有映射关系(k,v)的 集合,其所有key无序且不可重复。
二. 集合的使用
1. Collection接口中的方法
Collection 接口是层次结构中的根接口。构成 Collection 的单位称为元素。Collection 接口通常不能直接使用,但该接口提供了添加元素、删除元素、管理数据的方法。由于 List 接口与 Set 接口都继承了 Collection 接口,因此这些方法对 List 集合与 Set 集合是通用的。
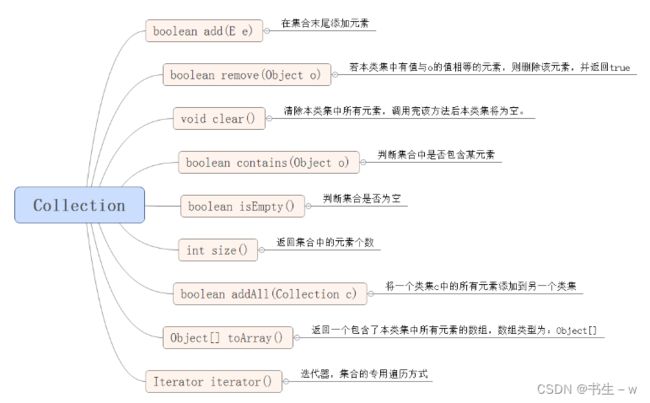
2.Collection的主要实现类特点

3. Iterator 迭代器的使用
三种方式遍历集合: 普通for循环、增强for循环、Iterator迭代器(重点讲解)
在java.util 包中提供了一个 Iterator 接口,该接口是一个专门对 Collection 进行迭代的迭代器。
lterator迭代器的常用方法
| 方法 |
功能描述 |
| hasNext() | 如果仍有元素可以迭代,则返回 true |
| next() | 返回迭代的下一个元素 |
| remove() | 从迭代器指向的Collection中移除迭代器返回的最后一个元素(可选操作) |
注意:
Iterator的next()方法返回的是Object。
4. Iterator 迭代器的原理

5. List(接口)
List 接口继承了 Collection 接口,定义一个允许重复项的有序集合;按照对象进入顺序进行保存对象,List集合就像是一个数组,有序,长度可变
特点: 有序集合、有重复
操作 :add()、get()、set()、size()、remove()等
常用的实体类: ArrayList等
包括的实体类: ArrayList、Vector、Stack等
具体描述见下图:
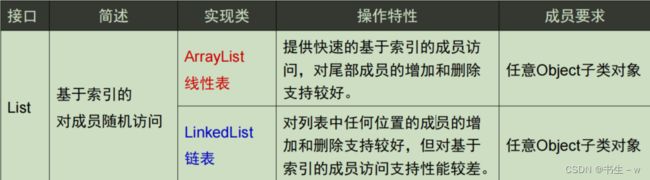
6. Set(接口)
Set 接口继承了 Collection 接口,集合元素无序且无重复。
无重复原理:每个Set实现类依赖添加的对象的 equals() 方法来检查独一性,即任意两个元素e1和e2,都有e1.equals(e2)=false
特点: 无序集合、不可重复
操作 :add()、get()、set()、size()、remove()等
常用的实体类: HashSet、TreeSet等
包括的实体类: HashSet、TreeSet、EnumSet、LinkedHashSet等:
具体描述见下图:

7.Queue(接口)
特点: 队列(先进先出、有序表)
主要实现类有: PriorityQueue、ArrayDeque等
8、Map
Map接口含有两个部分(两列):关键字和值 (key-value,简称键值对);key不可重复,value可重复;添加数据时,如果key重复,则用新值替换原有的值。
操作: put(key,value)、remove()、clear()、size()、containsKey(Object key)、containsValue(Object value)
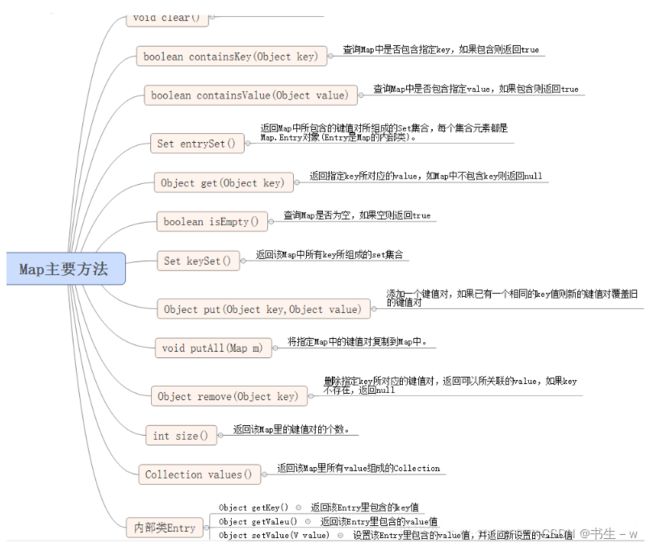
常用实现类: HashMap、TreeMap
具体描述见下图:
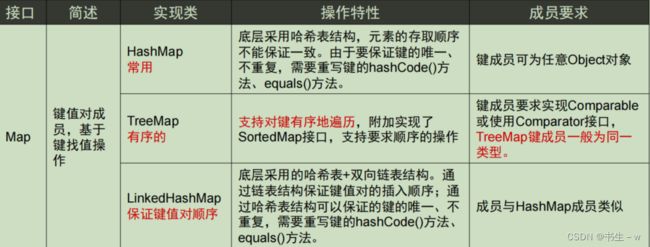
三. List集合中:ArrayList 、LinkedList、Vector区别
ArrayList:底层使用Object数组实现;当数组容量不够时,创建一个新数组,这个新数组的容量是原数组的1.5倍,然后将原数组中的元素复制到这个新数组中。建议使用时,直接在构造方法中指定数组大小。避免扩容,影响效率。
- JDK7:当使用无参构造创建列表时,底层默认创建长度是10的Object数组。
- JDK8:当是用无参构造创建列表时,底层并不会指定数组的容量,第一次添加容量时才默认创建长度为10的数组
LinkedList: 底层使用双向链表实现;内部声明了Node类型的next、prev属性,prev指向前一个元素,next指向下一个元素------体现了双向链表,链表更占内存(多了两个引用)。
Vector:线程安全的,里面的方法基本都加了synchornized,因此效率很慢;底层使用Object数组存储;当使用无参构造创建时,JDK7和JDK8都默认创建一个长度为10的数组;当容量不够时会按照原始用量的100%比例扩容。
- 对于随机访问ArrayList根据下表查找,时间复杂度为O(1),而LinkedList时间复杂为O(n)。
- 对于插入和删除,LinkedList要优于ArrayList;ArrayList需要重新计算位置,移动大量元素,甚至扩容。
四. Set集合中:HashSet、TreeSet
TreeSet
TreeSet有序且不可重复,是基于TreeMap实现的;向TreeSet中添加的对象,一定要是同一类的对象(原理在TreeMap中说)。
HashSet
HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75的HashMap。它封装了一个HashMap对象来存储所有的集合元素,所有放入HashSet集合元素实际上是由HashMap的key来保存的,而HashMap的value则存储一个PRESENT,它是一个静态的Object对象。原理在HashMap中说。
不同点:
- HashSet中元素可以为null,但只有一个null;TreeSet中不能有null;
- HashSet底层使用hash表进行排列,无序;
- TreeSet底层用红黑树进行排列;
五. Map:HashMap、TreeMap
HashMap底层原理
JDK7中:
- HashMap 在实例化后创建一个长度为16的Entry数组;HashMap中有一个加载因子默认值为0.75,当存储的元素超过当前数组容量的0.75时会进行扩容,这个加载因子,我们可以通过有参构造创建对象时自己设定。
- 在存储数据时,会先计算存储元素的key的hash值来判断其所存储的位置,当两个存储元素的hash值相等时,会调用equals方法判断两个对象是否相等。如果对象相等会进行value值的覆盖;若果对象不相等会在同一个位置以链表形式存储元素。补充说明:
- 我们会先调用hashCode方法进行提前校验,避免过多的调用equals方法,以提高效率。这也是为什么我们重写equals方法时要重写hashCode方法。
- 同一链表上key的hashCode值不一定相等,且大多数都不相等;因为他的存储方式让我们误以为相等:例如,当前HashMap的容量为16,有两个元素key的Hash值分别为1和17;这时1会被存入数组下标为1的位置,而17此时的存储位置由他的值对存储容量取模的值决定的,取模的值也是1,他们都存在1号位置。但他们hash值根本不一样。
- 扩容问题:当容量达到临界时,进行扩容后会重新获得元素的hash值,对hash值”一样“的采用头插法将元素添加到链表。-----会出现扩容循环链表(多线程中出现)。
JDK8中: 与JDK7三点不一样
- HashMap 在实例化并添加元素时才创建一个长度为16的Node数组;
- JDK8中底层是基于数组+链表+红黑树实现的,底层维护的是Node数组;当数组长度>64且链式数据大于8时,会开启红黑树。(当链表长度过长时会影响我们的查找效率,红黑树可以提高查询效率;之所以不用B/B+树,当数据量不是很多时,数据会挤在一个节点中,这个时候遍历效率相当于退化成了链表)
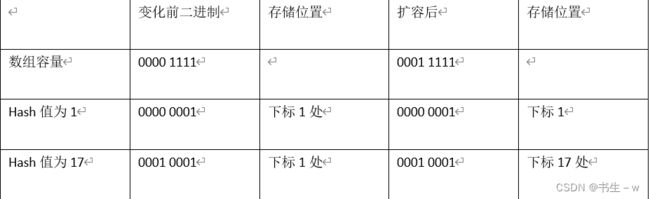
- 扩容时采用尾插法,每次都取最后一个元素放在新的数组链表中,避免了扩容时循环链表的产生。扩容时将元素hash值与旧数组大小做与运算,新增的位为0放在原位置,为1进行移位(原位置+旧数组大小)。
例如:原数组大小为16,存储元素中有Hash值为1和17 的两个元素。
TreeMap底层原理
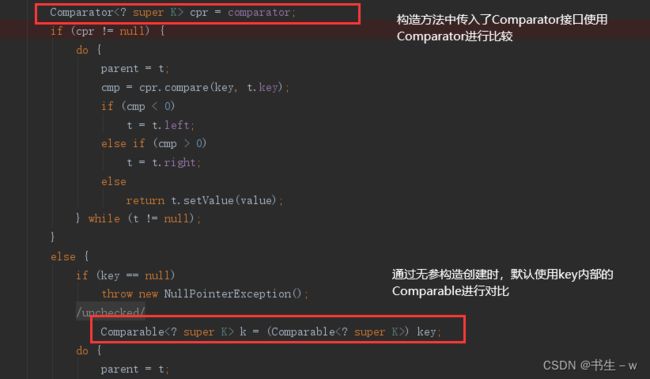
基于红黑树实现。映射根据其键的自然排序进行排序。因为底层调用了其键的compare()方法,所以才能进行排序,但同时也规定了存入的key必须是同一类型对象。也可以调用其构造方法,在构造方法中提供 Comparator的实现类自定义排序策略。
六. 集合的线程安全
线程安全的集合
vector、stack、HashTable、ConcurrentHashMap
将线程不安全的集合转换为安全的
- 集合类工具:Collections提供了synchornizedXxx()方法,将这些集合类包装成线程安全的集合类。所有的方法都带有同步锁(方法上都加了Synchornized)。
- JUC:JUC包下提供了大量支持搞笑并发访问的集合类,既能包装良好的性能,又能包装线程安全。(原理在多线程里面讲)
- 以Concurrent开头的集合类:写操作线程安全;读取不锁定。
- CopyOnWrite开头的集合类:没用锁。采用复制底层数组的方式进行写操作;读的时候读取集合本身;每个线程写的时候复制原数组到当前线程的一个新数组中,然后当前线程对这个副本进行操作。(每个线程拿一个副本数据写操作,写完刷到原数组中)很浪费内存。
七. Collections工具类
Collections是针对集合的工具类,提供了排序、反转、求最值、二分查找等功能, 大大提高了开发人员工作效率。
| Collections常用方法 | 说明 |
|---|---|
| sort(List< T> list) | 根据自然顺序(升序)对指定list集合排序 |
| sort(List< T> list,Comparator< ? super T> c) | list-集合;c比较器:按指定比较器c为list排序 |
| max(Collection< ? extends T> collection) | 根据自然顺序(升序)排序,返回collection的最大元素 |
| min(Collection< ? extends T> collection) | 根据自然顺序(升序)排序,返回collection的最小元素 |
| binarySearch(List<>list,T key) | list-集合,key-指定对象:对List二分查找key(必须先自然升序排序) |
| reverse(List list) | 反转List元素的顺序 |
八. Arrays工具类
Arrays是针对数组的工具类,提供了排序,查找,二分查找等功能。
| Arrays常用方法 | 说明 |
|---|---|
| sort(array) | 对指定的基本数据类型数组array按升序排列 |
| equals(array1,array2) | 如果两个指定的基本数据类型数组相等返回true |
| binarySearch(array,val) | 对基本数据类型数组array进行二分查找val |
| toString(array) | 把基本数据类型数组array内容转换为字符串 |
