mongodb实战分享
mongodb实战分享
- 前言
- 首先介绍下什么是mongodb
- 2018年由StackOverflow开发者调查发布
- MongoDB的文档结构模型
- MongoDB的应用场景
- 不适用的场景
- MongoDB的安装配置
- linux下操作MongoDB的命令
- 管理MongoDB
- 使用java操作MongoDB
- Mysql转入MongoDB
- MongoDB存储引擎
- mongodb数据会丢失?你需要了解WT写入的原理
- mongodb配置文件详解
- 索引管理实战
-
- 创建索引
- 删除索引
- 部署模型概述
-
- 可复制集
-
- 可复制集的搭建过程
- 使用正确的姿势连接复制集
- 分片集群
-
- 为什么要用分片集群?
前言
前段时间公司项目中就使用了mongodb技术,主要将海量的位置信息从mysql转到mongodb中,这里和大家分享下什么是mongodb,以及mongodb在实际项目中如何使用。希望大家以后在自己公司的项目中也能运用。
首先介绍下什么是mongodb
1.MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
2.支持的数据结构非常松散,是类似 json 的 bson 格式,因此可以存储比较复杂的数据类型。
3.MongoDB 最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
4.它是一个面向集合的,模式自由的文档型数据库。
2018年由StackOverflow开发者调查发布
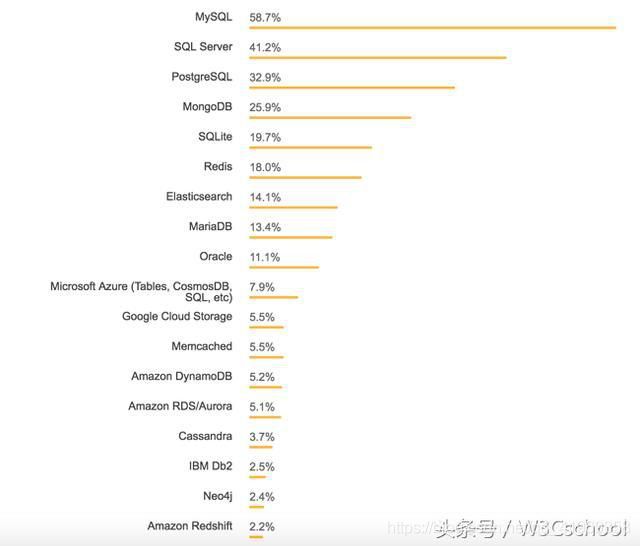
看图感受下mongodb吧
MongoDB的文档结构模型
MongoDB 的逻辑结构是一种层次结构。主要由:文档(document)、集合(collection)、数据库(database)这三部分组成的。
MongoDB 的文档(document), 相当于关系数据库中的一行记录。多个文档组成一个集合( collection), 相当于关系数据库的表。多个集合( collection), 逻辑上组织在一起,就是数据库( database)。一个 MongoDB 实例支持多个数据库( database)。

MongoDB的应用场景
1)表结构不明确且数据不断变大
MongoDB是非结构化文档数据库,扩展字段很容易且不会影响原有数据。内容管理或者博客平台等,例如圈子系统,存储用户评论之类的。
2)更高的写入负载
MongoDB侧重高数据写入的性能,而非事务安全,适合业务系统中有大量“低价值”数据的场景。本身存的就是json格式数据。例如做日志系统。
3)数据量很大或者将来会变得很大
Mysql单表数据量达到5-10G时会出现明细的性能降级,需要做数据的水平和垂直拆分、库的拆分完成扩展,MongoDB内建了sharding、很多数据分片的特性,容易水平扩展,比较好的适应大数据量增长的需求。
4)高可用性
自带高可用,自动主从切换(副本集)
不适用的场景
1)MongoDB不支持事务操作,需要用到事务的应用建议不用MongoDB。
2)MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
MongoDB的安装配置
1.官网上下载完安装包后,上传linux服务器并解压
tar zxvf mongodb-linux-x86_64-4.0.4.tgz
2.更改配置文件mongodb.conf如下:
#启用日志文件,默认启用
journal=true
bind_ip=0.0.0.0
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=false
# 日志文件位置
logpath=/usr/mongodb/mongodb-linux-x86_64-4.0.4/logs
# 以追加方式写入日志
logappend=true
# 是否以守护进程方式运行
fork = true
# 默认27017
port = 10037
# 数据库文件位置
dbpath=/usr/mongodb/mongodb-linux-x86_64-4.0.4/data
# 启用定期记录CPU利用率和 I/O 等待
#cpu = true
# 是否以安全认证方式运行,默认是不认证的非安全方式(设置完用户再打开)
#auth = true
#noauth = true
3.用户授权和管理
I. mongodb安装好后第一次进入是不需要密码的,也没有任何用户,通过shell命令可直接进入,cd到mongodb目录下的bin文件夹,执行命令./mongo即可
II. 添加管理用户(mongoDB 没有无敌用户root,只有能管理用户的用户 userAdminAnyDatabase)
III. 添加完管理用户后,关闭MongoDB,并使用权限方式再次开启MongoDB,这里注意不要使用kill直接去杀掉mongodb进程,(如果这样做了,请去data/db目录下删除mongo.lock文件),可以使用db.shutdownServer()关闭
IV. 使用权限方式启动MongoDB
V.进入mongo shell,使用admin数据库并进行验证,如果不验证,是做不了任何操作的。
VI. 验证之后还是做不了操作,因为admin只有用户管理权限,下面创建用户,用户都跟着库走
VII. 使用创建的用户root登录进行数据库操作
具体操作可以参考这篇博客:https://blog.csdn.net/qq_22206899/article/details/81412802
linux下操作MongoDB的命令
show dbs //显示数据库列表
show collections //显示集合列表
db //显示当前数据库
db.stats() //显示数据库信息
db.serverStatus() // 查看服务器状态
db.dropDatabase() //删除数据库
db.help(),db.collection.help() //内置帮助,显示各种方法的说明;
db.users.find().size() //获取查询集合的数量;
db.users.drop() //删除集合;
管理MongoDB
我们使用的是客户端工具(Robo 3T ),客户端下可以:
创建索引
db.getCollection('t_user_position').createIndex({"serviceOrderId":1,"userId":1})
查看索引
db.getCollection('t_service_position').getIndexes()
使用java操作MongoDB
可以参考这篇博客:https://blog.csdn.net/cy4ttty/article/details/49706393
Mysql转入MongoDB
1.将mysql中数据转为csv格式文件(使用数据库管理软件中的导出向导即可)
2.将csv文件上传至linux
3.导入mongodb的命令
./mongoimport -d nwow -c t_service_position --type csv --file ./t_service_position.csv -h 127.0.0.1 --port 10037 -u root -p 03874 --headerline --drop
MongoDB存储引擎
MongoDB从3.0开始引入可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger存储引擎可供选择。在3.2版本之前MMAPV1是默认的存储引擎,其采用linux操作系统内存映射技术,但一直饱受诟病;3.4以上版本默认的存储引擎是wiredTiger,相对于MMAPV1其有如下优势:
1.读写操作性能更好,WiredTiger能更好的发挥多核系统的处理能力;
2.MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。WiredTiger使用文档级锁,由此带来并发及吞吐的提高
3.相比MMAPV1存储索引时WiredTiger使用前缀压缩,更节省对内存空间的损耗;
4.提供压缩算法,可以大大降低对硬盘资源的消耗,节省约60%以上的硬盘资源;
WiredTiger 支持对所有集合和索引进行Block压缩和前缀压缩(如果数据库启用了journal,journal文件一样会压缩),已支持的压 缩选项包括:不压缩、Snappy压缩和Zlib压缩。这为广大Mongo使用者们带来了又一福音,因为很多Mongo数据库都是因为MMAP存储引擎消 耗了过多的磁盘空间而不得已进行扩容。其中Snappy压缩为数据库的默认压缩方式,用户可以根据业务需求选择适合的压缩方式。理论上来说,Snappy 压缩速度快,压缩率OK,而Zlib压缩率高,CPU消耗多且速度稍慢。当然,只要选择使用压缩,Mongo肯定会占用更多的CPU使用率,但是考虑到 Mongo本身并不是十分耗CPU,所以启用压缩完全是值得的。
配置文件中如何修改:
blockCompressor: snappy(zlib,snap,none可选 db压缩)//默认snappy,推荐snappy
journalCompressor:snappy(zlib,snap,none可选 log压缩)//默认snappy,推荐snappy
mongodb数据会丢失?你需要了解WT写入的原理
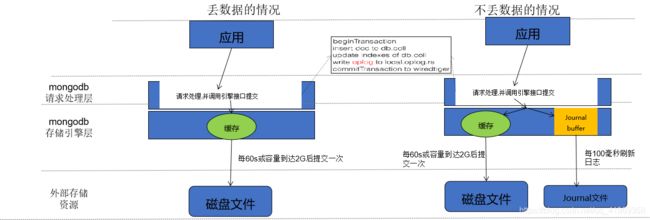
Journaling类似于关系数据库中的事务日志。Journaling能够使MongoDB数据库由于意外故障后快速恢复。MongoDB2.4版本后默认开启了Journaling日志功能,mongod实例每次启动时都会检查journal日志文件看是否需要恢复。由于提交journal日志会产生写入阻塞,所以它对写入的操作有性能影响,但对于读没有影响。在生产环境中开启Journaling是很有必要的。
1.写策略配置相关的类是?
答:com.mongodb.WriteConcern,其中有如下几个常用写策略配置:
UNACKNOWLEDGED:不等待服务器返回或确认,仅可以抛出网络异常;
ACKNOWLEDGED:默认配置,等待服务器返回结果;
JOURNALED:等待服务器完成journal持久化之后返回;
W1 :等待集群中一台服务器返回结果;
W2 :等待集群中两台服务器返回结果;
W3 :等待集群中三台服务器返回结果;
MAJORITY:等待集群中多数服务器返回结果;
2.Java代码中如何加入写策略
答:Java客户端可以按两种方式来设置写策略:
在MongoClient初始化过程中使用MongoClientOptions. writeConcern(writeConcern)来进行配置;
在写操作过程中,也可动态的指定写策略,mongodb可以在三个层次来进行写策略的配置,既MongoClient、 MongoDatabase 、MongoCollection这三个类都可以通过WriteConcern方法来设置写策略;
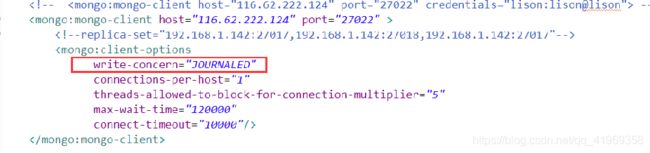
3.Spring中如何配置写策略
答:在配置文件中配置,如下图:
Q4:WriteConcern类的几个常用写策略配置满足不了项目的需求,怎么修改?
答:通过配置类,在Spring容器中加入自己定制化的MongoClient
mongodb配置文件详解
storage:
journal:
enabled: true
dbPath: /data/zhou/mongo1/
##是否一个库一个文件夹
directoryPerDB: true
##数据引擎
engine: wiredTiger
##WT引擎配置
wiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB: 1
##是否将索引也按数据库名单独存储
directoryForIndexes: true
journalCompressor:none (默认snappy)
##表压缩配置
collectionConfig:
blockCompressor: zlib (默认snappy,还可选none、zlib)
##索引配置
indexConfig:
prefixCompression: true
索引管理实战
创建索引
单键唯一索引:db.users. createIndex({username :1},{unique:true});
单键唯一稀疏索引:db.users. createIndex({username :1},{unique:true,sparse:true});
复合唯一稀疏索引:db.users. createIndex({username:1,age:-1},{unique:true,sparse:true});
创建哈希索引并后台运行:db.users. createIndex({username :‘hashed’},{background:true});
删除索引
根据索引名字删除某一个指定索引:db.users.dropIndex(“username_1”);
删除某集合上所有索引:db.users.dropIndexs();
重建某集合上所有索引:db.users.reIndex();
查询集合上所有索引:db.users.getIndexes();
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。索引主要用于排序和检索
单键索引
在某一个特定的属性上建立索引,例如:db.users. createIndex({age:-1});
mongoDB在ID上建立了唯一的单键索引,所以经常会使用id来进行查询;
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引;
复合索引
在多个特定的属性上建立索引,例如:db.users. createIndex({username:1,age:-1,country:1});
复合索引键的排序顺序,可以确定该索引是否可以支持排序操作;
在索引字段上进行精确匹配、排序以及范围查找都会使用此索引,但与索引的顺序有关;
为了性能考虑,应删除存在与第一个键相同的单键索引
多键索引
在数组的属性上建立索引,例如:db.users. createIndex({favorites.city:1});针对这个数组的任意值的查询都会定位到这个文档,既多个索引入口或者键值引用同一个文档
哈希索引
不同于传统的B-树索引,哈希索引使用hash函数来创建索引。
例如:db.users. createIndex({username : ‘hashed’});
在索引字段上进行精确匹配,但不支持范围查询,不支持多键hash;
Hash索引上的入口是均匀分布的,在分片集合中非常有用;
部署模型概述


可复制集
可复制集是跨多个MongDB服务器(节点)分布和维护数据的方法。mongoDB可以把数据从一个节点复制到其他节点并在修改时进行同步,集群中的节点配置为自动同步数据;旧方法叫做主从复制,mongoDB 3.0以后推荐使用可复制集;
为什么要用可复制集?它有什么重要性?
避免数据丢失,保障数据安全,提高系统安全性;(最少3节点,最大50节点)
自动化灾备机制,主节点宕机后通过选举产生新主机;提高系统健壮性; (7个选举节点上限)
读写分离,负载均衡,提高系统性能;
生产环境推荐的部署模式;
可复制集的搭建过程
1.安装好3个以上节点的mongoDB;
2.配置mongodb.conf,增加跟复制相关的配置如下:
replication:
replSetName: configRS //集群名称
oplogSizeMB: 50 //oplog集合大小
3.在primary节点上运行可复制集的初始化命令,初始化可复制集,命令如下:
//复制集初始化,在主节点上执行,ip禁止使用localhost
rs.initiate({
_id: "configRS",
version: 1,
members: [{ _id: 0, host : "192.168.1.142:27017" }]});
rs.add("192.168.1.142:27018");//有几个节点就执行几次方法
rs.add("192.168.1.142:27019");//有几个节点就执行几次方法
4.在每个节点运行rs.status()或isMaster()命令查看复制集状态;
5.测试数据复制集效果;
6.测试故障失效转移效果;
使用正确的姿势连接复制集
MongoDB复制集里Primary节点是不固定的,不固定的,不固定的!
所以生产环境千万不要直连Primary,千万不要直连Primary,千万不要直连Primary!
配置Tips:
1.关注Write Concern参数的设置,默认值1可以满足大多数场景的需求。W值大于1可以提高数据的可靠持久化,但会降低写性能。
2.在options里添加readPreference=secondaryPreferred即可实现读写分离,读请求优先到Secondary节点,从而实现读写分离的功能
分片集群
分片是把大型数据集进行分区成更小的可管理的片,这些数据片分散到不同的mongoDB节点,这些节点组成了分片集群。
为什么要用分片集群?
数据海量增长,需要更大的读写吞吐量 → 存储分布式
单台服务器内存、cpu等资源是有瓶颈的 → 负载分布式
具体过程这里不详细介绍。