计算机基础篇——深度剖析数据在计算机内存中的存储
本章重点
1. 数据类型详细介绍
C语言中我们学习的内置类型数据有以下几种。
| 类型 | 数据类型名称 | 占用内存空间字节 |
| char |
字符数据类型
|
1 |
| short |
短整型
|
2 |
| int |
整形
|
4 |
| long |
长整型
|
4 |
| long long |
更长的整形
|
8 |
| float |
单精度浮点数
|
4 |
| double |
双精度浮点数
|
8 |
类型的意义:使用这个类型开辟内存空间的大小(大小决定了使用范围)。
在VS2019下观察内置类型数据的大小
#include
#include
int main()
{
INT_MAX;
return 0;
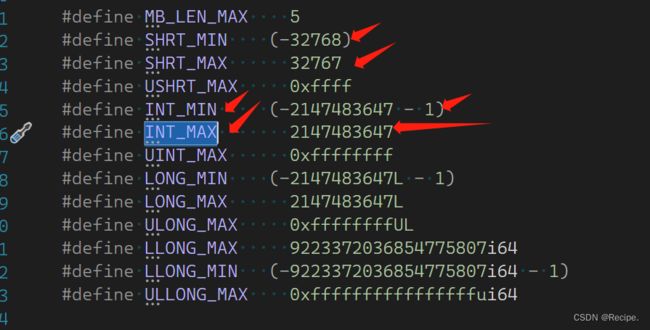
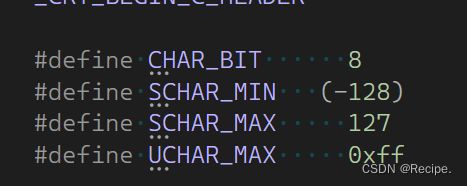
} limist这个库函数可以查看内置类型数据最大值与最小值
右键点击然后转到定义
通过转到定义可以清晰的查看内置数据的最大值与最小值
整形家族分类
| char | signed char | unsigned char |
| shor |
unsigned short
|
signed short [int]
|
| int |
unsigned int
|
signed int
|
| long |
unsigned long [int]
|
signed long [int]
|
为什么char是属于整形家族的呢?因为char类型在内存中存储的是ASCII码值,是整形,因此归类为整形家族。
对整形家族具有无符号和有符号的区分 那么char是unsigned char 还是signed char呢?
这是不确定的,但在VS2019上 char=signed char short=signed short int=signed int
2. 整形在内存中的存储:原码、反码、补码
一个变量在内存中存储是需要开辟空间的,而开辟的空间大小取决于变量的数据类型。
#include
#include
int main()
{
int a = -10;
10000000 00000000 00000000 00001010--源码
11111111 11111111 11111111 11110101--反码
11111111 11111111 11111111 11110110——补码
int b = 20;
00000000 00000000 00000000 00010100——源码==反码==补码
return 0;
} int开辟4个字节空间大小,4个字节=32个比特位(byte)。
而计算机中表达二进制数有三种方法 源码 反码 补码。
三种表达方法均有符号位和数值位两部分组成 0表示正 1表示负 而正数的源反补都相同。
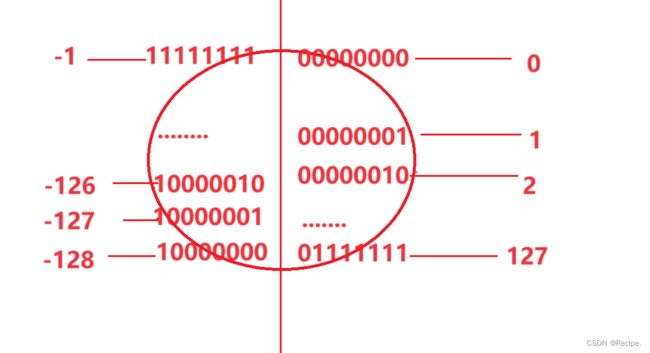
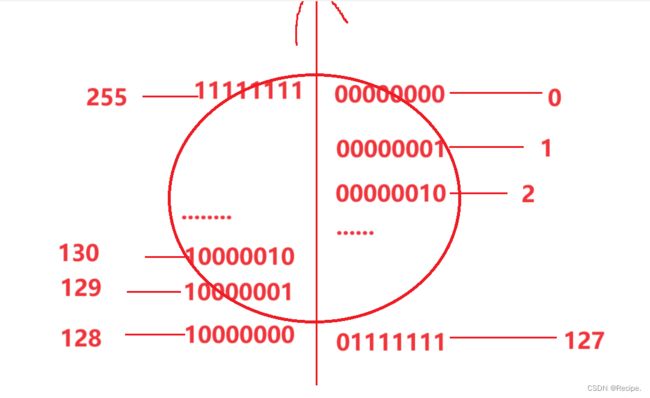
以下是8个比特位的内存空间所放二进制数值的所有可能以及转换。
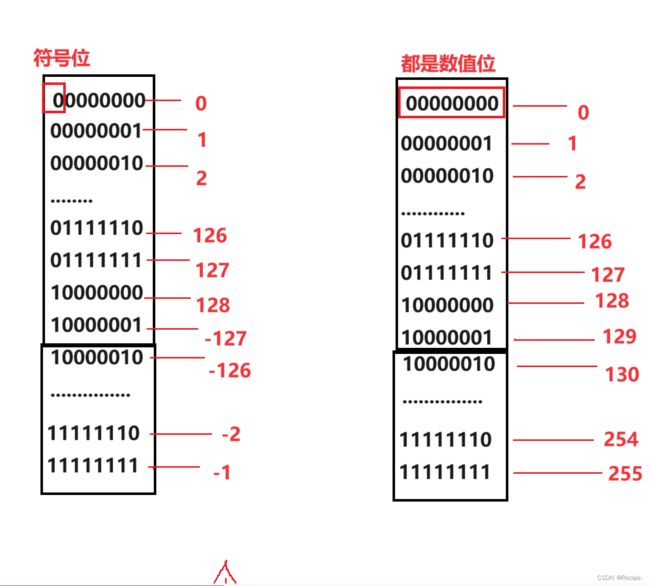
有符号:signed 转换图
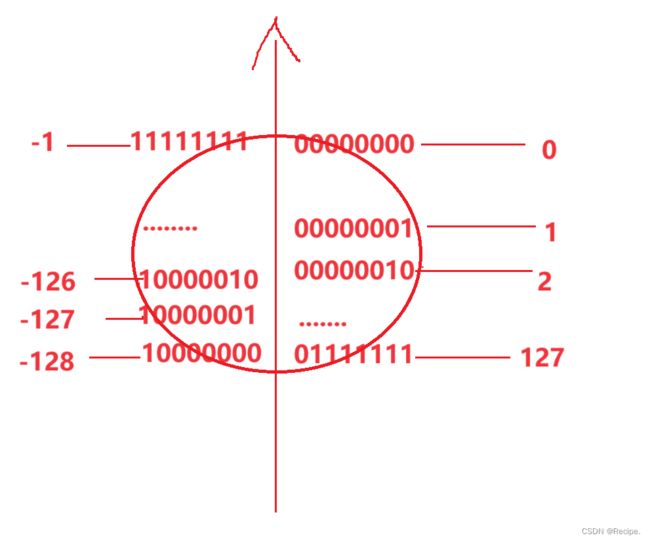
无符号:unsigned 转换图

则负数的源 反 补表达方式不同
源码:直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码:将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码:反码+1就得到补码。
补码到源码可以有两种方式获取
先取反+1 or 先-1取反

3. 大小端字节序介绍及判断
#include
#include
int main()
{
int a = -10;
10000000 00000000 00000000 00001010--源码
11111111 11111111 11111111 11110101--反码
11111111 11111111 11111111 11110110——补码
ff ff ff f6
int b = 20;
00000000 00000000 00000000 00010100——源码==反码==补码
00 00 00 14
return 0;
} 

例如:一个16bit的 short型x,在内存中的地址为 0x0010,x的值为 0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在高地址中,即 0x0011中。小端模式,刚好相反。我们常用的X86 结构是小端模式,而 KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
怎么判断机器字节序是大端还是小端呢?
#include
int check_key()
{
int n = 1;
00000000 00000000 00000000 00000001
00 00 00 01 小端字节 01 00 00 00 大端字节 00 00 00 01
char b = *(char*)&n;
return b;
}
int main()
{
int ret = check_key();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
} 我们先强制类型转换成char类型再取n的地址,再解引用访问地址,如果是1就是小端 否则大端。
4.代码习题
1.第一道习题
输出什么?
#include
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
} 答案是 -1 -1 255 为什么呢?
#include
int main()
{
char a = -1;
10000000 00000000 00000000 00000001——源码
11111111 11111111 11111111 11111110——反码
11111111 11111111 11111111 11111111——补码 ——截断
11111111 -a
整形提升
11111111 11111111 11111111 11111111 ——补码
10000000 00000000 00000000 00000000 ——取反
10000000 00000000 00000000 00000001 ——源码
signed char b = -1;
10000000 00000000 00000000 00000001——源码
11111111 11111111 11111111 11111110——反码
11111111 11111111 11111111 11111111——补码 ——截断
整形提升
11111111 11111111 11111111 11111111 ——补码
10000000 00000000 00000000 00000000 ——取反
10000000 00000000 00000000 00000001 ——源码
unsigned char c = -1;
10000000 00000000 00000000 00000001——源码
11111111 11111111 11111111 11111110——反码
11111111 11111111 11111111 11111111——补码 ——截断
整形提升
11111111
00000000 00000000 00000000 11111111 ——正数 源反补相同
printf("a=%d,b=%d,c=%d", a, b, c);%d打印的是十进制数字 输出的是源码的值
-1 -1 255
return 0;
} 
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
通用CPU (general-purpose CPU) 是难以直接实现两个8比特字节直接相加运算 (虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或unsigned int,然后才能送入CPU去执行运算。
char a = -1;
1000000 0000000 0000000 00000001 ——源码
1111111 1111111 1111111 11111110 ——反码
1111111 1111111 1111111 11111111 ——补码 因为char只有一个字节大小进行截断
11111111 -a 截断
整形提升
1111111 1111111 1111111 11111111
unsigned char a = -1;
1000000 0000000 0000000 00000001 ——源码
1111111 1111111 1111111 11111110 ——反码
1111111 1111111 1111111 11111111 ——补码 因为char只有一个字节大小进行截断
11111111 -a 截断
整形提升
00000000 00000000 00000000 11111111 为正数 源反码相同2.第二道习题
输出什么?
#include
int main()
{
char a = -128;
printf("%u\n",a);
return 0;
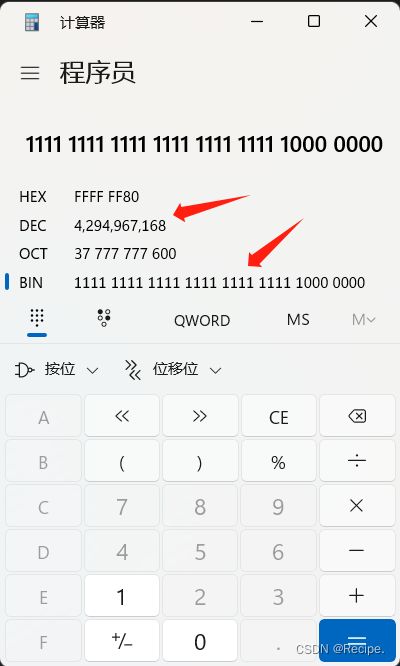
} 答案输出4,294,967,168 为什么呢?
因为是无符号数 没有符号位 全是数值位
不相信的同学 可以win+R 输出calc 弹出计算器切换到程序员
把整形提升后的二进制序列输入进去 就可以看到结果了。
#include
int main()
{
char a = -128;
1000000 0000000 0000000 10000000 ——源码
1111111 1111111 1111111 01111111 ——反码
1111111 1111111 1111111 10000000 ——补码 截断
10000000 -a
整形提升
11111111 11111111 11111111 10000000
printf("%u\n", a);
4,294,967,168
return 0;
} 
3..第三道习题
这个输出什么?
#include
int main()
{
char a = 128;
printf("%u\n",a);
return 0;
} 答案还是4,294,967,168
#include
int main()
{
char a = 128;
00000000 00000000 00000000 10000000——正数 源反码相同
截断10000000
整形提升
11111111 11111111 11111111 10000000
printf("%u\n", a);
return 0;
} 原理与上题相同
4.第四道习题
输出什么?
#include
int main()
{
int i= -20;
unsigned int j = 10;
printf("%d\n", i+j);
} 答案是-10
#include
int main()
{
int i = -20;
1000000 00000000 00000000 00010100 ——源码
11111111 11111111 11111111 11101011 ——反码
11111111 11111111 11111111 11101100 ——补码
unsigned int j = 10;
00000000 00000000 00000000 00001010 ——正数 源反码相同
相加补码
11111111 11111111 11111111 11101100 -i
00000000 00000000 00000000 00001010 -j
11111111 11111111 11111111 11110110 补码相加结果
10000000 00000000 00000000 00001001
10000000 00000000 00000000 00001010 ——源码 -10
printf("%d\n", i + j);
-10
return 0;
} 5.第五道习题
输出什么?
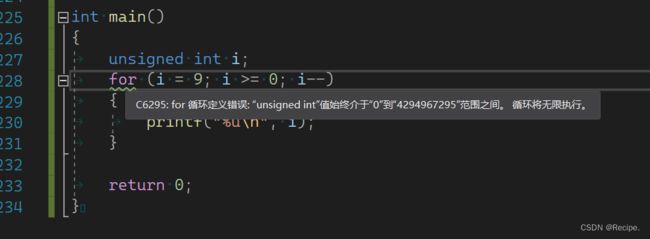
#include
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
} 
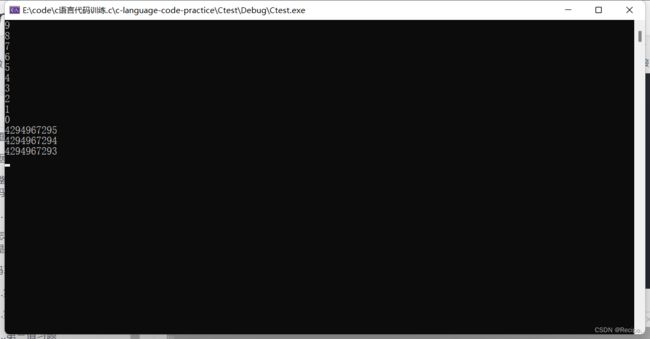
答案是无限循环!为什么呢?因为从上面的转换图可以看出,无符号数是没有符号位的,当i--到0的时候,再-1 会变成全11111111 11111111 11111111 11111111 因为无符号数没有符号位全是数值位,会一直减下去 变成0 又从0开始循环 所以是一个死循环。
我们可以通过Sleep函数观察下此代码
#include
#include
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
Sleep(1000);//毫秒
printf("%u\n", i);
}
return 0;
} 
6.第六道习题
输出什么?
#include
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
} 答案是255。为什么呢?
从数学的角度来讲 代码理论应该是这样的 如下图
 a[i]会从-1一直减到-1000 但实际上不是这样的。
a[i]会从-1一直减到-1000 但实际上不是这样的。
char的范围是-128~127
当从-1减到-128时 再减去1 会变成127 126 ....到0
strlen是求字符串长度的,统计的是\0之前的出现的字符个数,而\0等同于0
-1到-128 是128个数字 127到0 一共是128个数字 但0==\0 所以是128+127=255
因此strlen只统计0之前出现的数字字符个数 因此输出结果是255。