深度学习YOLOv4环境配置
软件安装
1、什么是CUDA
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
CUDA下载地址为CUDA Toolkit Archive | NVIDIA Developer
版本号选择11.6与nvidia-smi.exe命令所显示对应
安装属性选择如下:

点击运行cuda_11.6.1_511.65_windows.exe
运行后会先安装,后检查版本兼容性,无问题将会弹出许可协议。选择自定义安装,
注意,在此之前应需安装Visual studio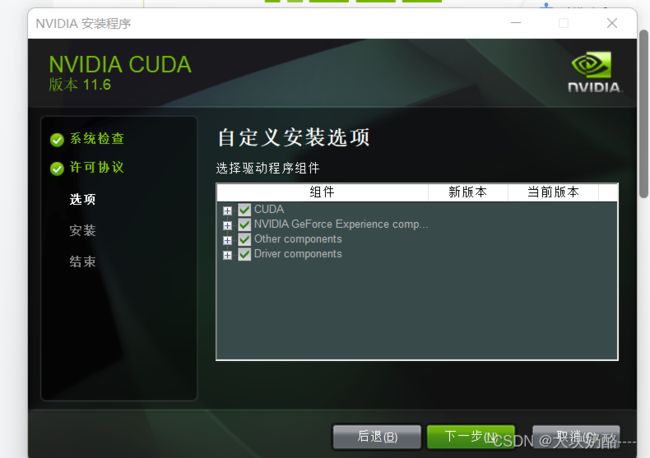
下一步:选择安装位置


安装完成后会显示与vs的整合情况,之前安装过vs2022,显示如下:此时就能在vs2022中做GPU方面的开发了。

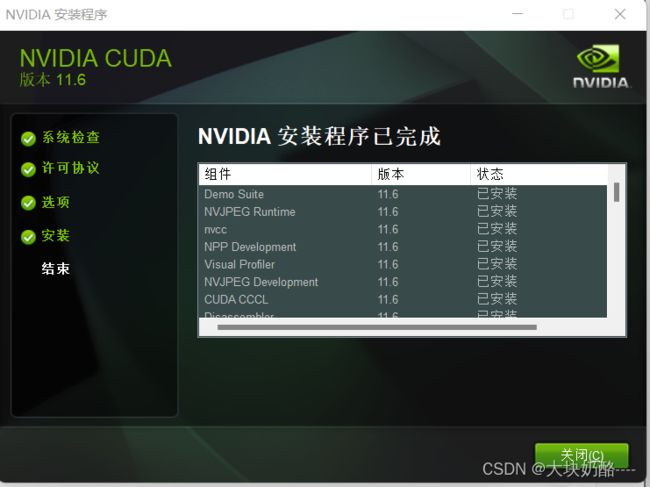 此时组件安装成功。
此时组件安装成功。
检查安装是否成功
nvcc -V
将其设置成系统变量
![]()


2、什么是CUDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
即GPU的加速库,使用nvidia-smi.exe命令查看自己计算机所支持的最高版本

下载官网:cuDNN 历史版本 | NVIDIA 开发者
注意下载的cudnn不能大于的CUDA的版本号,故要下载低于CUDA的版本,选择v11.0版本

将cudnn解压,把这三个文件夹的文件分别拷贝到CUDA安装目录对应的(bin、include、lib)文件夹中即可。CUDA的lib目录有x64 、Win32、cmake三个文件夹,拷到其中的x64这个文件夹中
在vs2022中创建CUDA项目,进行测试
点击下一步,默认会创建一个数组相加的例子,直接运行,显示如下此时成功

3、opencv安装
进入官网下载,版本为opencv3.4.14,运行安装

配置环境变量

二、配置YOLOv4环境
1、darknet
Darknet是一个用C和CUDA编写的开源神经网络框架。它速度快,易于安装,并支持CPU和GPU计算。
下载路径:
 GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet )
解压后,文件结构如下:
\opencv\build\x64\vc15\bin的两个dll文件: opencv_ffmpeg3415_64.dll和opencv_ffmpeg3415_64.dll复制到D:\darknet\build\darknet\x64
2、vs2022项目配置
用vs2022打开E:\darknet\build\darknet下darknet.sln文件

点击确定,使得重定向到vs2015
点击项目----->属性:

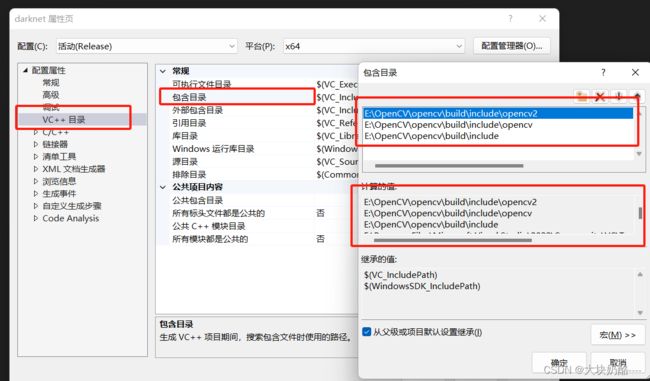
3.修改包含目录和库目录
添加opencv3.4的包含目录和库目录(按照自己的opencv3.4的路径)
包含目录:
C:\Program Files (x86)\opencv\build\include
C:\Program Files (x86)\opencv\build\include\opencv
C:\Program Files (x86)\opencv\build\include\opencv2
库目录:
C:\Program Files (x86)\opencv\build\x64\vc14\lib

4.附加依赖项
添加附加依赖项(按照自己的opencv3.4的路径)
示范:
C:\Program Files (x86)\opencv\build\x64\vc14\lib\opencv_world3415d.lib
需要添加的是opencv_world3415d.lib
 5、 修改darknet.vcxproj
5、 修改darknet.vcxproj
darknet\build\darknet下,右键,可以txt打开
ctrl+f搜索 11.1 全部改成 11.6(因为我们的CUDA版本是11.6)
6、拷贝CUDA文件
1.将NVIDIA CUDA的安装程序(.exe文件)数据解压到一个指定文件夹中(最好是新建一个文件夹CUDA,解压后会出现很多文件,这样方便查找)
2.将第一个路径下的文件直接拷贝到第二个路径下的文件夹中
7、生成darknet.exe文件
出现大量警告,并且不断提示getopt.c无法打开,尝试多种方法占时未解决。一直以为是外部资源未正常引入,查看darknet结构发现其文件下降getopt.h/c文件丢失!!!
解决办法:将配置环境统一改为vs2019,下载getopt.zip,解压后,直接将getopt.c getopt.h添加到项目中即可!!!!

报错:
错误 LNK1104 无法打开文件“cudnn.lib” darknet F:\darknet-master\darknet-master\build\darknet\LINK 1
查看项目属性依赖库地址,发现没有cudnn.lib这一项
将E:\cudnn-windows-x86_64-8.4.0.27_cuda11.6-archive\cudnn-windows-86_64-8.4.0.27_cuda11.6-archive\lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64即可
E:\cudnn-windows-x86_64-8.4.0.27_cuda11.6-archive\cudnn-windows-86_64-8.4.0.27_cuda11.6-archive\lib:复制以下内容到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64即可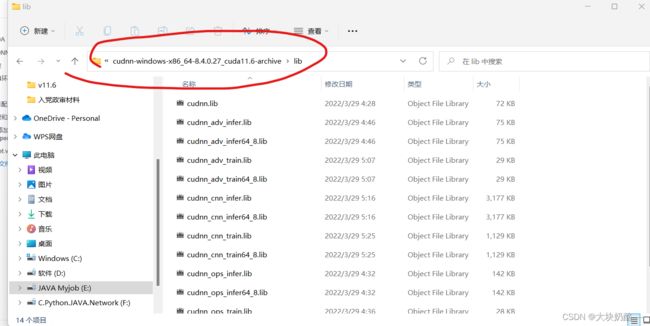
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64:

点击重新生成 成功!!!
将会在 F:\darknet-master\darknet-master\build\darknet\x64文件夹下生成darknet.exe,至此yolov4环境搭建成功
三、测试安装
将权重文件赋值到F:\darknet-master\darknet-master\build\darknet\x64

运行如下命令:(在F:\darknet-master\darknet-master\build\darknet\x64目录下)
darknet.exe detector test cfg\coco.data cfg\yolov4.cfg yolov4.weights显示:无法找到 zlibwapi.dll. Please make sure it is in your library path!

zlibwapi.lib文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\lib

zlibwapi.dll文件放到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\bin

路径文件已经解决:但仍出现错误,显示如下:
无法打开 yolov4.weights文件
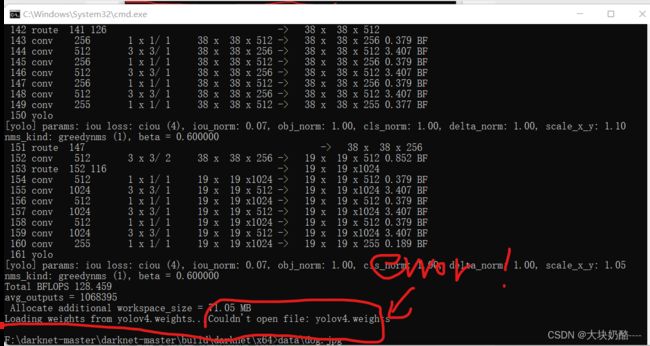
缺少如下两个文件:

将其复制到 F:\darknet-master\darknet-master\build\darknet\x64目录下:
再次运行尝试:

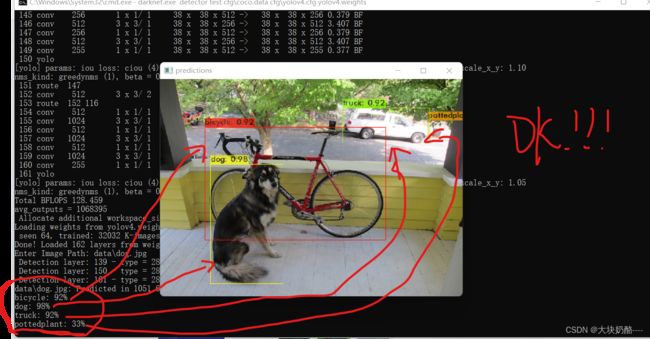 测试照片成功!!!
测试照片成功!!!
测试视频:
darknet.exe detector demo cfg\coco.data cfg\yolov4.cfg yolov4.weights
driving.mp4
无法访问媒体摄像头,显示无法打开文件
cap_ffmpeg_impl.hpp打开,定位到966代码如下:
当err值小于0时,输出error opening file与文件名,并返回goto语句,err值由avformat_open_input与av_open_input_file函数决定


判断为opencv无法正常打开mp4文件引起。
<-------------------------------------------------------------------------------------------------------------------------->
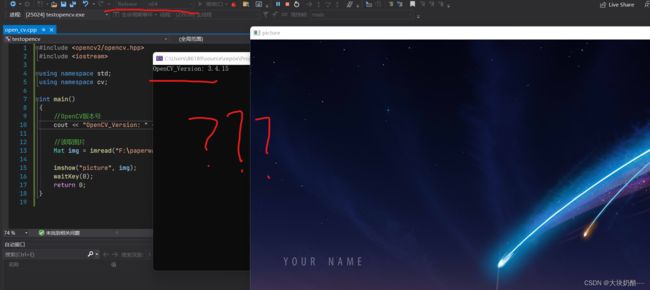
单独测试opencv,在vs2019中以相同的方法配置一个项目,在此一定要注意:配置的环境为Debug x64!!!!!!!!!!!!!!而不是x86,否则将会出现以下错误:

再次运行出现以下错误:
LNK2019
错误 LNK2019 无法解析的外部符号 "void __cdecl cv::imshow(class cv::String const &,class cv::debug_build_guard::_InputArray const &)" (

将debug x64的属性表复制到release x64,再次运行,又可以运行了???
有点懵。。。
<-------------------------------------------------------------------------------------------------------------------------->
视频问题的解决:我只能说是人傻了,在浏览F:\darknet-master\darknet-master\build\darknet\x64文件夹时候,突然记起来driving.mp4并没有指定文件路径。。。。。。(未对项目的结构和流程做分析的后果。。。)
将driving.mp4单独放一个文件夹下,使用下述命令:(不要包含中文路径,防止报错)
darknet.exe detector demo cfg\coco.data cfg\yolov4.cfg yolov4.weights "E:\yolov4_mp4\driving.mp4"result:ok
或将driving.mp4直接放在F:\darknet-master\darknet-master\build\darknet\x64下,使用下述命令:
darknet.exe detector demo cfg\coco.data cfg\yolov4.cfg yolov4.weights driving.mp4但是不建议这样做,还是分开好
至此视频问题解决。(在网上东找办法西找办法,就是自己没有想办法。。。。解决一切的根源还得从自己入手。。。。)
四、标定数据集
这段写的有些乱,工具包一直下载不下来,一直在尝试
labelimg 是一个可视化的图像标定工具。它是用Python编写的,并将Qt用于其图形界面。批注以PASCAL VOC格式(ImageNet使用的格式)另存为XML文件。此外,它还支持YOLO格式。Faster R-CNN,YOLO,SSD等目标检测网络所需要的数据集,均需要借此工具标定图像中的目标。
1、安装labelimg与pyqt5 pyqt-tools
1、安装labelimg法一:
使用pip安装,开始菜单选择anaconda3-anaconda prompt进入命令行。
输入pip --version检查pip是否安装成功

在命令行窗口中依次输入下列代码,安装labelimg依赖的第三方库。
pip install PyQt5
pip install pyqt5-tools
pip install lxml
输入pip install PyQt5显示如下:pyQt5已经安装版本为12.11
目录为f:\anaconda3\lib\site-packages (from PyQt5)


输入pip install pyqt5-tools
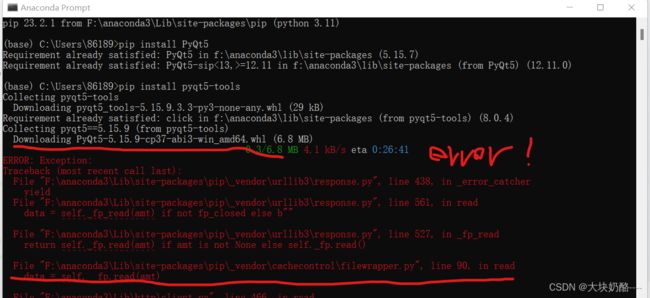
pip下载报错,应该是网站访问超时的原因,更换镜像
pip install xxxx -i http://pypi.douban.com/simple --trusted-host=pypi.douban.com
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/更换阿里云镜像还是不行。或使用如下命令(没有尝试):
pip install lightgbm -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2、安装labelimg法二:
直接在GitHub上下载labelimg:GitHub - HumanSignal/labelImg: LabelImg is now part of the Label Studio community. The popular image annotation tool created by Tzutalin is no longer actively being developed, but you can check out Label Studio, the open source data labeling tool for images, text, hypertext, audio, video and time-series data.
下载将zip解压,用Anaconda安装,以管理员身份运行Anaconda Prompt并到labelImg-master所解压目录下执行命令
命令如下:
conda install pyqt=5
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
在运行时pyrcc5 -o libs/resources.py resources.qrc还出现了错误,仍要安装pip install pyqt5-tools
两种安装labelimg的方法都需要pyqt5 pyqt5-tools
尝试了好多方法安装pip install pyqt5-tools的问题依旧没有解决。应该是python(11.1)与pip版本太高的原因。(在pyqt5-tools的安装(深度学习))中将此问题解决。
继续使用法二进行安装labelimg(因为我已解压labelimg原文件),在pyqt5与pyqt5-tools安装好后,以管理员身份运行Anaconda Prompt并到labelImg-master目录下执行命令pyrcc5 -o libs/resources.py resources.qrc与python labelImg.py,执行结果如下:
注意(此时已经完全安装了pyqt5与pyqt5-tools)!!

将会打开labelimg.py:

此时labelimg标注工具安装成功。
2、添加自定义类别
修改文件labelImg-master\data\predefined_classes.txt
原文件默认类别名如下:

修改为
ball
messi
trophy此时将labelimg重启,否则类别文件有错误,即在 以管理员身份运行Anaconda Prompt并到labelImg-master目录下执行命令python labelImg.py即可
3、使用labelImg进行图像标注
labelimg的标注模式分为VOC和YOLO两种,两种模式下生成的标注文件分别为.xml文件和.txt文件,因此在进行标注前需要优先选择好标注的模式。
标注教程:【教程】标注工具Labelimg的安装与使用 - 知乎 (zhihu.com)
标注效果如下:
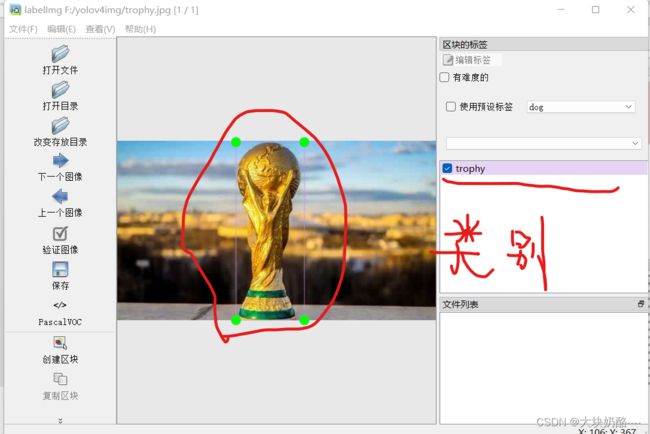
使用VOC标注模式将其保存为xml格式
xml文件内容如下:

对其xml中参数解释如下:其中hight,width为图片的最大高、宽,而Xmin,Ymin,Xmax,Ymax分别是所标定类别图形的坐标。

使用YOLO模式将其保存为.txt,内容如下:
2 0.478125 0.503704 0.214583 0.992593
class_id为2,因为在其classes.txt文件下:trophy在第2行(count从0开始)

与VOC的转换关系如下:

也可以使用python对其两者进行转换
size为照片最大尺寸,box为标注框尺寸
box[0]:xmin box[1]: xmax box[2]: ymin box[3]: ymax
def convert(size, box) :
dw = 1./size[0]
dh = 1./size[1]
x = (box[o] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
X = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)4、组织自己的数据集
1、下载项目文件
(项目文件已提前下载好)从百度网盘下载到F:\darknet-master\darknet-master\build\darknet\x64目录下并解压

2、解压建立或自行建立数据集
使用PASCAL VOC数据集(还有 ImageNet 、 COCO后期介绍)的目录结构:
建立文件夹层次为 D:\darknet\build\darknet\x64\VOCdevkit\ VOC2007 VOC2007下面建立两个文件夹:

VOC2007下面建立两个文件夹:Annotations和JPEGImages
JPEGImages放所有的训练和测试图片;
Annotations放所有的xml标记文件


3、生成测试集与训练集文件
F:\darknet-master\darknet-master\build\darknet\x64执行python genfiles.py
python genfiles.py 在VOCdevkit \ VOC2007目录下可以看到生成了文件夹labels ,同时在darknet下生成了两个文件 2007_train.txt和2007_test.txt。
在执行后(未抛出异常)并没有在VOCdevkit \ VOC2007文件夹下生成labels文件夹,打开genfiles.py查看,第87、88行如果没有指定目录,则在当前目录下生成VOCdevkit\\VOC2007\\labels,94行probo值为一个1到100的随机整数,并且将其打印显示。该变量不受其他变量控制,而在控制台既没有抛出异常,也没有打印显示,此时可判断为python执行环境有误。直接执行python,发现并没有显示出信息,断定python环境变量有误。

环境变量添加如下:

F:\anaconda3\Scripts下有python依赖包的.exe文件, F:\anaconda3\下具有python.exe。
重新运行python genfiles.py :正常输出、文件夹产生

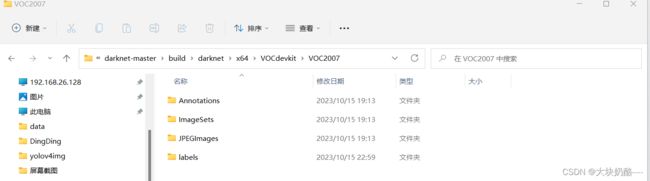

打开..\\darknet-master\build\darknet\x64下,2007_train.txt和2007_test.txt分别给出了训练图片文件和测试图片文件的列表,含有每个图片的路径 和文件名。

 即将源数据集分为两组,一组为测试集,一组为训练集。
即将源数据集分为两组,一组为测试集,一组为训练集。
另外,在VOCdevkit \ VOC2007\ImageSets\Main目录下生产了两个文件test.txt和train.txt,分别给出 了训练图片文件和测试图片文件的列表,但只含有每个图片的文件名(不含路径和扩展名)。
labels下的文件是images文件夹下每一个图像的yolo格式的标注文件,这是由annotations的xml标注文 件转换来的。即通过 执行genfiles.py 文件将annotations的xml标注文 件转成为labels文件夹下的yolo格式标注文件。
最终训练只需要:2007_train.txt,2007_test.txt,labels下的标注文件和 VOCdevkit \VOC2007\JPEGImages下的图像文件。
即只需要训练集、测试集的路径与其yolo标注格式文件和原图像。
五、修改配置文件
1、新建data\voc.names文件
可以复制data\voc.names再根据自己情况的修改;可以重新命名如:data\voc-ball.names
解释如下:
voc.names文件用来存放标签的名字
2、新建 data\voc.data文件
可以复制data\voc.data再根据自己情况的修改;可以重新命名如:data\voc-ball.data
voc.data路径为F:\darknet-master\darknet-master\build\darknet\x64\data\voc.data
解释如下:
classes= 20 # 类别总数
train = /home/xxx/darknet/scripts/train.txt # 训练集样本txt文件
valid = /home/xxx/darknet/scripts/2007_test.txt # 验证集样本txt文件
names = data/voc.names # 类别名称
backup = backup # 权重保存路径
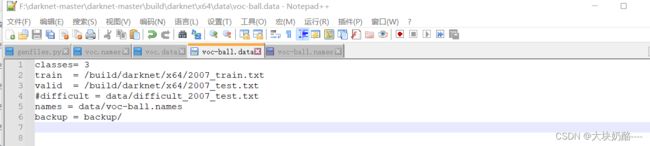
重要的三个配置文件:voc-ball.names(类别名称文件位于data/下)、voc-ball.data(位于x64/下)、cfg\yolov4-voc.cfg(..//x64/cfg)
3、新建cfg\yolov4-voc.cfg
可以复制cfg\yolov4-custom.cfg再根据自己情况的修改;可以重新命名cfg\yolov4-ball.cfg:
batch=16 subdivisions=8 (如果显存溢出改为16) max_batches = 4000 steps=3200, 3600
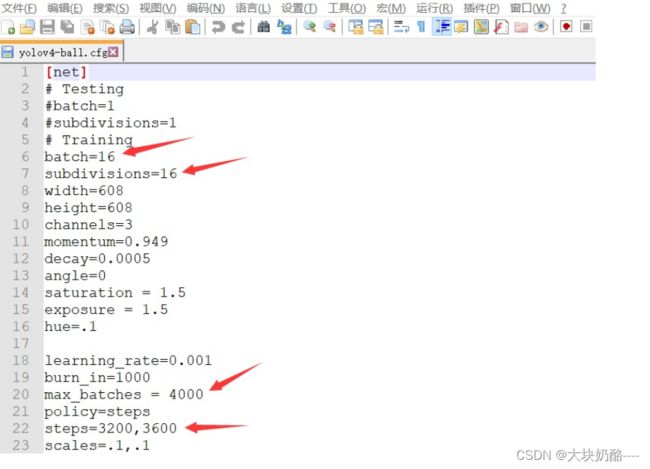
在cfg\yolov4-ball.cfg文件中,三个yolo层和各自前面的convolutional层的参数需要修改:
三个yolo层都要改:yolo层中的classes为类别数,每一个yolo层前的convolutional层中的filters =(类 别+5)* 3
例如:
yolo层 classes=1, convolutional层 filters=18
yolo层 classes=2, convolutional层 filters=21
yolo层 classes=4,convolutional层 filters=27


要注意是[yolo]层,而不是[net]层!!!!注意是三个yolo层!!!!!三个yolo层和各自前面的convolutional层的参数需要修改!!!!共查找到line 967、1055、1143为[yolo]层
总结:

六、训练模型(单目标 足球)
1、下载预训练权重文件
将预训练权重文件yolov4.conv.137放置在F:\darknet-master\darknet-master\build\darknet\x64目录下
出现的问题:
路径问题,老生常谈了,改好了,路径问题主要集中在voc-ball.data文件中
报错cuDNN hasn't found FWD algo for convolution: No error:

subdivisions大小和batch大小需要的内存关系:
将batch设置为32、subdivisions设置为32、width=416、height=416时,正常运行了一下。
改来改去都没有改好.........
偶然!!!当我试着把width、height改为3xx时候,忘记其值必须为32的倍数,将原值352将其改为320,此时开始训练:训练时间27个小时左右,因为不知其训练时间由何参数决定,时间也许很长,但总比无法训练好。。。。

修改cfg\yolov4-ball.cfg参数:训练时间将至6小时
batch=32、subdivisions=64减小了内存压力
width=320、height=320
max_batches = 6000最大迭代次数

avg loss值为0.09左右,迭代次数2000左右时停止了训练(avg loss波动较小)map图如下:
大约训练了4个小时

终端输出如下:

2、训练网络
darknet.exe detector train data\voc-ball.data cfg\yolov4-ball.cfg
yolov4.conv.137 -map如需要显示训练过程的map变化,在命令末尾加-map
3、训练建议

七、测试训练模型
在测试前将yolov4-ball.cfg中batch=32、subdivisions=64的值均改为1
测试训练模型:测试照片与视频均放在x64/testfiles/,每迭代1000次会保存一次权重文件,权重文件路径为x64/backup/,我们使用最终的权重文件测试即yolov4-ball_last.weights

单目标:
darknet.exe detector test data\voc-ball.data cfg\yolov4-ball-test.cfg backup\yolov4-ball_last.weights testfiles\ball-1.jpg
多目标:
darknet.exe detector test data\voc-ball.data cfg\yolov4-ball-test.cfg backup\yolov4-ball_last.weights testfiles\ball-1.jpg测试视频:不知道为什么昨晚测试时平均帧率在89,而今天只有12
darknet.exe detector demo data\voc-ball.data cfg\yolov4-ball-test.cfg backup\yolov4-ball_last.weights testfiles\ball-test.mp4

八、性能统计
统计map
统计 mAP@IoU=0.50:
darknet.exe detector map data\voc-ball.data cfg\yolov4-ball-test.cfg backup\yolov4-ball_last.weights统计 mAP@IoU=0.75:
darknet.exe detector map data\voc-ball.data cfg\yolov4-ball-test.cfg backup\yolov4-ball_last.weights -iou_thresh 0.75 

性能统计后续再学习
Conclusion:
yolov4的环境配置、模型训练至此结束,下来先对其训练过程中对文件的操作流程进行学习,后学习cfg文件的参数含义、性能统计指标、后续再训练多目标,用爬虫采数据集,最后再从底层逻辑学起。
时间越来越紧了,逐渐要和计算机渐行渐远,花了3晚上,搞出来个这,因缺乏基本的概念与认识,思维混乱,中间不断错,不断改,可谓举步维艰,最终也算是搞出来了。这次写完,下次学习就不知何时了。
秋风是清新的,但总夹杂着忧伤,一切都静悄悄的,转眼我也已大三,寄蜉蝣于天地,渺沧海之一粟,又试问:百川东到海,何时复西归?
----2023/10/17