数据分析实战项目——自行车销售数据分析
目录
数据集介绍
问题分析
数据预处理
数据分析
区域分析
销售代表分析
RFM模型
趋势分析
交互分析
复购率计算
数据集介绍
数据来源:GitHub - w1449550206/Pandas-Data-analysis-of-bicycle-sales-record-based-on-pandas: 基于pandas的自行车销售记录的数据分析
本数据集有订单编号,客户ID,客户名称,客户编号,客户省份,销售代表ID,下单日期,预计送货日期,实际送货日期,产品ID,产品名称,数量,单价,金额等14个字段。
数据收集的时间从2015年1月开始到2016年12月结束。
问题分析
- 区域分析——每个地区的销售金额、销售数量和订单量的分布情况
- 销售代表分析——每个销售代表的金额、销售数量和订单量的分布情况
- RFM模型——按照最近购买的时间、购买频率和购买金额三者进行客户分类
- 趋势分析——不同时间粒度的金额、数量和下单间隔等分析
- 交互分析——省份与下单间隔、省份与RFM的客户类型、销售人与RFM的客户类型
- 复购率计算
数据预处理
1、查看缺失值
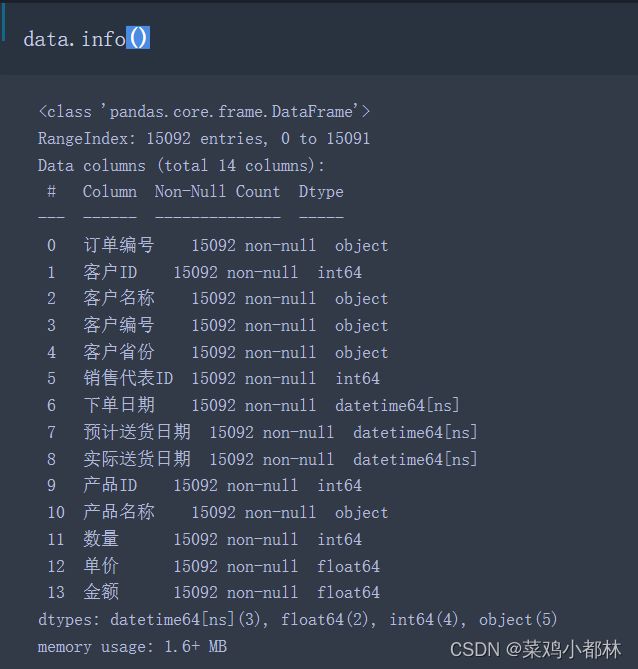
数据的样本个案有15092个,从图中可知,14个特征的样本个数均为15092个,说明该数据集不存在缺失值。
2、查看重复值
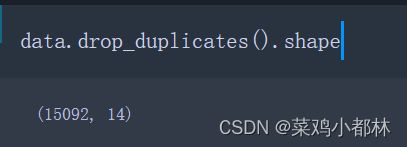
drop_duplicates是去除所有行都相同的行,shape用于查看dataframe的大小。从图中可知,去除重复值后的数据大小也为15092,数据并为减少,说明该数据集不存在重复值。
数据分析
区域分析
# 按照省份名称进行分组计数,得到每个省份的订单量
index = data['客户省份'].value_counts().index.tolist()
values = data['客户省份'].value_counts().values.tolist()
# 按照这种格式 “[[1,2],[2,3]]” 对数据进行处理,这是pyecharts地区的数据格式
index_values = []
for i in range(len(index)):
index_values.append([index[i],values[i]])
index_values.append(['台湾',1000000])
# 省份名称进行格式处理,pyecharts的地图数据格式中的名称一定带有省或者市、自治区等全称
pro_name1 = []
pro = '''
河北、山西、黑龙江、吉林、辽宁、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾
'''
for i in pro.replace('\n','').split('、'):
pro_name1.append(i + '省')
for i in ['内蒙古自治区','广西壮族自治区','西藏自治区','宁夏回族自治区','新疆维吾尔自治区']:
pro_name1.append(i)
for i in ['北京市','天津市','上海市','重庆市']:
pro_name1.append(i)
for i in ['香港特别行政区','澳门特别行政区']:
pro_name1.append(i)
# 获取分析数据中的省份名称,方便后续处理
pro1 = '''
河北、山西、黑龙江、吉林、辽宁、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、海南、四川、贵州、云南、陕西、甘肃、青海、台湾、内蒙古、广西、西藏、宁夏、新疆、北京、天津、上海、重庆、香港、澳门
'''
pro_name2 = []
for i in pro1.replace('\n','').split('、'):
pro_name2.append(i)
pro_name = []
for i in range(len(pro_name1)):
pro_name.append([pro_name1[i],pro_name2[i]])
# 按照处理好的数据进行匹配拼接,得到pyecharts合适的数据格式
pro_name = pd.DataFrame(pro_name,columns = ['含省份','不含省份'])
index_values = pd.DataFrame(index_values,columns = ['不含省份','values'])
province_data = pd.merge(pro_name,index_values,on = '不含省份')
from pyecharts import options as opts
from pyecharts.charts import Map
c = (
Map(init_opts=opts.InitOpts(bg_color='#fff'))
.add("", [list(z) for z in zip(province_data['含省份'].values.tolist(), province_data['values'].values.tolist())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="省份订单量"),
visualmap_opts=opts.VisualMapOpts(max_=759,min_ = 314,is_show=True,
range_color=["#E0ECF8", "#045FB4",'turquoise','darkcyan']))
.render("省份订单量.html")
)
# c.render_notebook()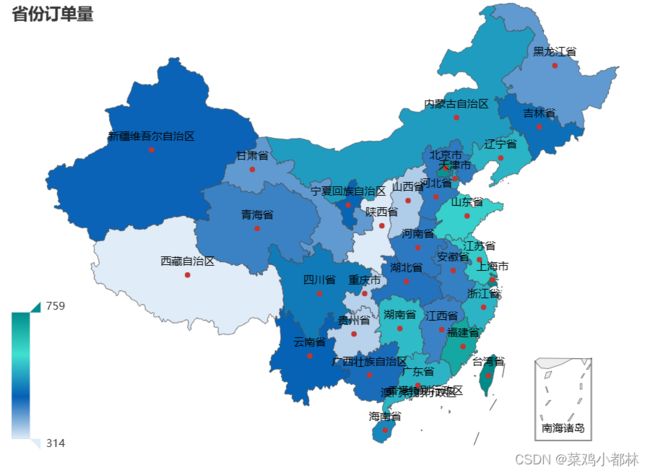
从图中可知,沿海地区的自行车订单量较大;中原地区的订单量剧中,但陕西、重庆和贵州等地区的订单量最少。除此之外,西藏地区的订单量也低,其他地区的订单量属于中等。
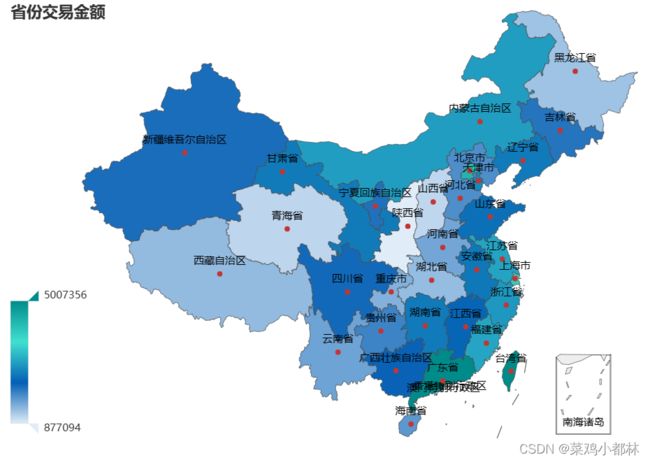 除陕西外的其他地区销售金额都比较可观,其中广东等沿海城市和内蒙古的销售金额较高。同时,可以绘制销售量的省份地图,与订单量的分布大致相同。
除陕西外的其他地区销售金额都比较可观,其中广东等沿海城市和内蒙古的销售金额较高。同时,可以绘制销售量的省份地图,与订单量的分布大致相同。
销售代表分析
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
# c = (
# Pie(init_opts=opts.InitOpts(bg_color='#fff'))
# .add("", [list(z) for z in zip(data.groupby('销售代表ID').sum()['金额'].sort_index().index.tolist(),
# data.groupby('销售代表ID').sum()['金额'].sort_index().values.tolist())])
# .set_global_opts(title_opts=opts.TitleOpts(title="Pie-基本示例"))
# .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# # .render("pie_base.html")
# )
# c.render_notebook()
c = (
Pie(init_opts=opts.InitOpts(bg_color='#fff'))
.add(
"",
[list(z) for z in zip(data.groupby('销售代表ID').sum()['金额'].sort_index().index.tolist(),
[round(i,0) for i in data.groupby('销售代表ID').sum()['金额'].sort_index().values.tolist()])],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title=""),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_scroll_legend.html")
)
c.render_notebook()
从中可知,哪个销售代表的销售业绩最好,以及其业绩数据是多少。从图中,编号为213、214、208的三个销售代表的销售业绩较高。
RFM模型
import time
from sklearn.preprocessing import MinMaxScaler
# 按照客户ID进行聚合分组,获取每个用户最近时间所在的行数据
group_data = data.iloc[data.groupby(['客户ID']).apply(lambda x : x['下单日期'].idxmax())].reset_index(drop = True)
# 在上一行的基础上,筛选出这三个字段
group_data = group_data[['客户ID','下单日期','金额']]
# 获得每个用户的购买数量
user_buy_count = pd.DataFrame(data.groupby('客户ID').sum()['数量']).reset_index()
# 按照用户ID进行拼接
RFM_data = pd.merge(group_data,user_buy_count,on = '客户ID')
pd.set_option('display.float_format',lambda x:'%.6f'%x) #为了直观的显示数字,不采用科学计数法
# 将时间转化为数字,时间越近数字越大
RFM_data['timestamp'] = RFM_data['下单日期'].apply(lambda x:time.mktime(time.strptime(str(x),'%Y-%m-%d %H:%M:%S')))
# 实例化最大最小标准化对象,对三个数值的结果进行标准化,并赋值给RFM三个值
scaler = MinMaxScaler()
RFM_data[['金额','数量','timestamp']] = scaler.fit_transform(RFM_data[['金额','数量','timestamp']])
RFM_data['R'] = RFM_data['timestamp'].apply(lambda x : '低' if x < 0.4 else '高')
RFM_data['F'] = RFM_data['数量'].apply(lambda x : '低' if x < 0.4 else '高')
RFM_data['M'] = RFM_data['金额'].apply(lambda x : '低' if x < 0.4 else '高')
# 将RFM三个值拼接起来
RFM_data['RFM'] = RFM_data['R'] + RFM_data['F'] + RFM_data['M']
# 定义RFM的客户类型评价标准函数
def judge_customer_type(RFM_values):
if RFM_values == '高高高':
return '重要价值客户'
elif RFM_values == '高低高':
return '重要发展客户'
elif RFM_values == '低高高':
return '重要保持客户'
elif RFM_values == '低低高':
return '重要挽留客户'
elif RFM_values == '高高低':
return '一般价值客户'
elif RFM_values == '高低低':
return '一般发展客户'
elif RFM_values == '低高低':
return '一般保持客户'
elif RFM_values == '低低低':
return '一般挽留客户'
RFM_data['客户类型'] = RFM_data['RFM'].apply(judge_customer_type)
RFM_data.head()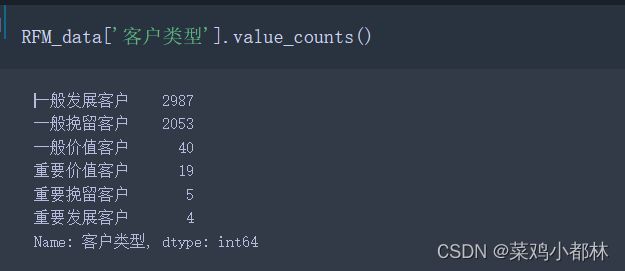 、
、
重要的客户占比较少,一般的客户占比最多。该销售企业需要重点的针对一般发展客户和一般挽留客户两种类型的客户进行留存处理。(得分的划分依据按照企业内部的标准指定,这里只是单纯的为了模型做的划分)
趋势分析
1、以日为颗粒度的时间序列
# 每日的销售金额及其销售数量
data.groupby('下单日期').sum()[['数量','金额']]
plt.figure(figsize=(20,10),facecolor='#fff',dpi = 300)
plt.subplot(2,1,1)
plt.plot(
data.groupby('下单日期').sum()[['数量','金额']].index,
data.groupby('下单日期').sum()[['数量','金额']]['数量'].values
)
plt.subplot(2,1,2)
plt.plot(
data.groupby('下单日期').sum()[['数量','金额']].index,
data.groupby('下单日期').sum()[['数量','金额']]['金额'].values
)
plt.show()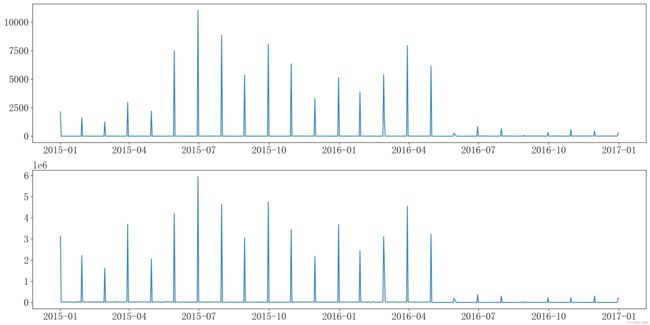
上面的图是销售数量,下面的图的是销售金额,在这个图中很难看出来是什么情况。所以,对销售金额进行平均后可视化。
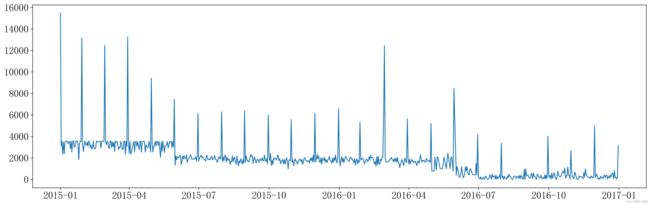 可以看出,每个月总有一天销售金额是最大的。细化分析可以采用上面“找到每个用户的最近时间所在行”的方法,找到每个月销售金额最大的时间点。本文此处不再做过多的分析,详细可以看上文提到的数据链接内,原作者的数据分析内容。
可以看出,每个月总有一天销售金额是最大的。细化分析可以采用上面“找到每个用户的最近时间所在行”的方法,找到每个月销售金额最大的时间点。本文此处不再做过多的分析,详细可以看上文提到的数据链接内,原作者的数据分析内容。
2、以月为颗粒度的时间序列
# 每月的销售量和销售额
data['年月'] = data['下单日期'].apply(lambda x : x.year).astype('str') + '-' + data['下单日期'].apply(lambda x : x.month).astype('str')
month_data = data.groupby('年月').sum()[['数量','金额']].reset_index()
month_data['年月'] = month_data['年月'].astype('datetime64')
month_data = month_data.set_index('年月').sort_index()
plt.figure(figsize=(20,10),facecolor='#fff',dpi = 300)
plt.subplot(2,1,1)
plt.plot(
month_data.index,
month_data['数量']
)
plt.xticks(rotation = 330)
plt.subplot(2,1,2)
plt.plot(
month_data.index,
month_data['金额']
)
plt.xticks(rotation = 330)
plt.show()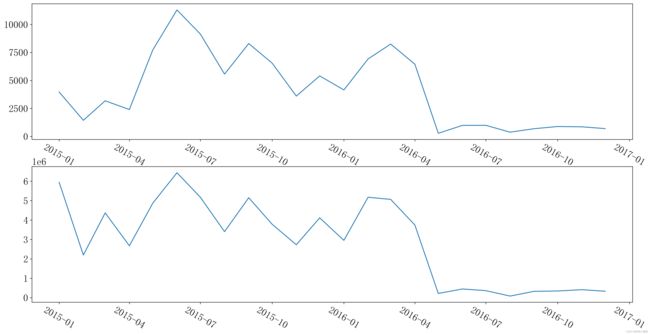 2015年1月到2015年6月这段时期内,销售额是逐步增加的,到2016年3月份之前销售额和销售量都是以较小的幅度增长,之后呈现低迷状态。由此可知,2016年3月份之后的运营状态是有问题的,同时,销售量与销售额的趋势是一致的,说明产品的价值属性较为稳定。
2015年1月到2015年6月这段时期内,销售额是逐步增加的,到2016年3月份之前销售额和销售量都是以较小的幅度增长,之后呈现低迷状态。由此可知,2016年3月份之后的运营状态是有问题的,同时,销售量与销售额的趋势是一致的,说明产品的价值属性较为稳定。
3、下单日期与实际发货日期的时序分析
# 下单日期与实际发货日期的间隔
data['下单间隔'] = data['实际送货日期'] - data['下单日期']
data['下单间隔'] = data['下单间隔'].apply(lambda x : int(str(x).split(' ')[0]))
plt.figure(figsize=(20,6),facecolor='#fff',dpi = 300)
plt.plot(
data.groupby('下单间隔').count().sort_index().index,
data.groupby('下单间隔').count()['金额'].sort_index().values,
)
plt.show()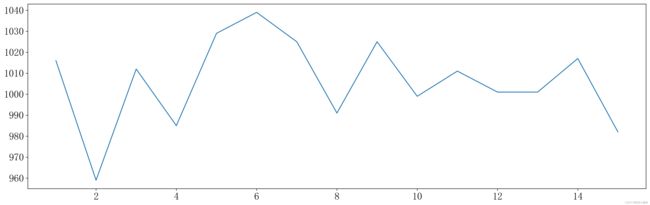
计算下单日期与实际发货日期的间隔可知,间隔相差六天的下单量是最大的,且前四天的产品下单量相对较低。所以,该产品具有较为特殊的实际发货间隔长的属性。
4、时序环比图

从环比结果图看,2015年中仅有4、6、8、9和12五个月份是有增长幅度的,其中九月份增长的稍慢。2016年中3、5、9和12四个月份是由增长幅度的,其中5月份呈现了爆发式增长,且9月份和12月份的也有较大的增长幅度。
5、时序同比图
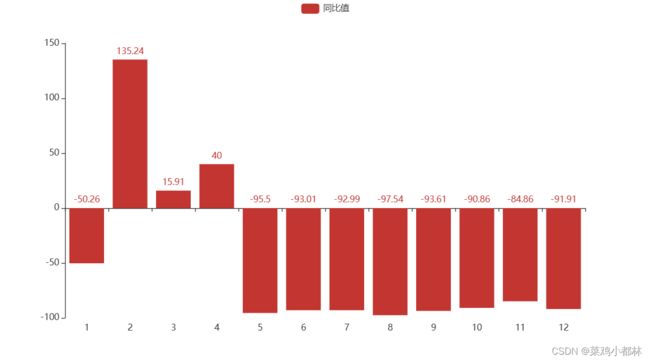 除了2、3和4月份的有所增长,其他时间节点的订单量都比去年有较大的下降幅度。所以,企业需要对整体的运营思路做出调整,并对订单量有所增长幅度的时间点做盈利分析。
除了2、3和4月份的有所增长,其他时间节点的订单量都比去年有较大的下降幅度。所以,企业需要对整体的运营思路做出调整,并对订单量有所增长幅度的时间点做盈利分析。
交互分析
test = pd.pivot_table(data[['客户省份','下单间隔','订单编号']],
index=['客户省份','下单间隔'],aggfunc='count').reset_index(['客户省份','下单间隔'])
tt = pd.pivot(test, index='客户省份', columns='下单间隔', values='订单编号').fillna(0)
import seaborn as sns
plt.figure(figsize = (30,15),facecolor='#fff',dpi = 300)
sns.heatmap(tt,cmap = 'Oranges', cbar_kws={"shrink": .8},
xticklabels=tt.columns.tolist(),
yticklabels=tt.index.tolist(),
linewidths = 5
)
plt.title('不同省份不同发货间隔的订单量',fontdict={'fontsize':22})
plt.show()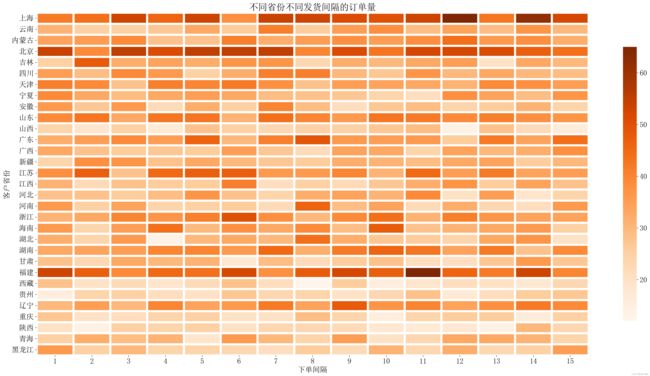 上海、北京和福建三个地区的订单量较高,其中,上海的高订单量主要发生在12和14天两个间隔时间,福建的高订单量主要发生在11天的时间间隔,在北京地区除了2天和9天的时间间隔外的其他时间间隔都有较好的订单量。 其他地区的订单量较为均衡,少部分地区的订单量较低,且省份与金额的分布与省份与订单量的分布大致相同。
上海、北京和福建三个地区的订单量较高,其中,上海的高订单量主要发生在12和14天两个间隔时间,福建的高订单量主要发生在11天的时间间隔,在北京地区除了2天和9天的时间间隔外的其他时间间隔都有较好的订单量。 其他地区的订单量较为均衡,少部分地区的订单量较低,且省份与金额的分布与省份与订单量的分布大致相同。
复购率计算
# 最大最小的间隔数,大于365天作为不复购的人群,反之,则记为复购人群
test = pd.DataFrame(data.groupby('客户ID').count()['订单编号']).reset_index()
test.rename(columns = {"订单编号":'购买次数'},inplace =True)
data = pd.merge(data,test,on = '客户ID')
test = data[data['购买次数'] >=2 ]
max_min_time = pd.DataFrame(test.groupby('客户ID')['下单日期'].max() - test.groupby('客户ID')['下单日期'].min()).reset_index()
max_min_time['间隔长度'] = max_min_time['下单日期'].apply(lambda x : int(str(x).split(' ')[0]))
max_min_time['target'] = max_min_time['间隔长度'].apply(lambda x : 0 if x>365 else 1)
max_min_time['target'].sum()/data['客户ID'].value_counts().count()本文定义的复购率是大于365天不作为复购人数,反之,则记为复购人数。经过计算,在该销售时间内的复购率仅有17.854%,说明产品的复购率较低。复购率低可能产品具备奢侈品类的产品,不存在高复购率情况。