Hive3.x数仓开发
文章目录
- 一、数仓仓库概念
- 二、数据仓库分层架构
-
- ODS\DW\DA(ADS)
- ETL\ELT
- 三、Apache Hive 概述
-
- 为什么使用Hive
- Hive和Hadoop关系
- 四、Apache Hive架构、组件
-
- 组件
- 五、Apache Hive数据模型
-
- Data Model概念
- Databases数据库
- Partitions分区
- Buckets分桶
- Hive和MySQL对比
- 六、元数据
-
- Hive Metadata
- Hive Metastore
- 七、Metastore配置方式
-
- 内嵌模式
- 本地模式
- 远程模式
- 八、Hive部署
-
- 安装前准备
- Hadoop与Hive整合
- 内嵌模式
- 本地模式
-
- mysql安装
- Hive安装
- 配置hive-site.xml
- 远程模式安装
-
- 配置hive-site.xml
- 远程模式Meatstore
- 九、Hive命令行客户端
-
- bin/hive Client
- bin/beeline Client
- 十、HIve SQL DDL相关
-
- 10.1 Hive数据类型
-
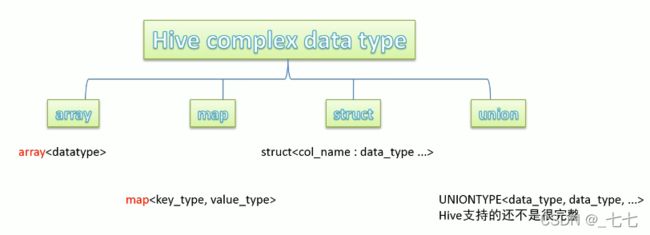
- 原生数据类型
- 复杂数据类型
- 隐式转换
- 显示转换
- 10.2 Hive读写文件机制
-
- SerDe是什么
- SerDe相关语法
- LazysimpleserDe分隔符指定
- 10.3 Hive默认分隔符
- 10.4 Hive数据存储路径
-
- 指定存储路径
- 10.5 Hive建表 且 上传文件
-
- 复杂数据类型
- location指定表路径
- 10.6 Hive 内外部表
-
- 内部表
- 外部表
- 内、外部表差异
- 如何选择内、外部表
- Location关键字的作用
- 10.7 Hive Partitioned Tables 分区表
-
- 概念
- 语法树
- 分区表数据加载--静态分区
-
- 本质
- 多重分区表
- 分区表数据加载--动态分区
- 分区表的注意事项
- 10.8 Hive Bucketed Tables分桶表
-
- 概念
- 规则
- 完整语法树
- 语法
- 分桶表的创建
- 分桶表的数据加载
- 使用好处
- 10.9 Hive Transactional Tables事务表
-
- Hive事务背景知识
- 局限性
- 创建事务表
- 10.10 Hive Views 视图
-
- 概念
- 创建视图的好处
- 10.11 Hive3.0新特性:Materialized Views 物化视图
-
- 概念
- 物化视图、视图区别
- 语法
- 基于物化视图的查询重写
- 十一、Hive Database | Schema(数据库)DDL操作
-
- 11.1 create database 创建数据库
- 11.2 describe database 描述数据库
- 11.3 use database 切换数据库
- 11.4 drop database 删除数据库
- 11.5 alert database 修改数据库
- 十二、Hive Table 表的 DDL操作
-
- 12.1 整体概述
- 12.2 describe table
- 12.3 drop table
- 12.4 truncate table 清空表
- 12.5 alter table
- 十三、Hive Partition (分区) DDL操作
-
- 13.1 add partition
- 13.2 rename partition
- 13.3 delete partition
- 13.4 alter partition
- 13.5 MSCK partition
-
-
- 案例 Hive MSCK 修复partition
-
- 十四、Hive SHOW语法
- 十五、HiveSQL数据操控、查询语言(DML、DQL ) 对数据进行增删改查操作
-
- 15.1 Hive SQL-DML-Load 加载数据
-
- 功能
- 语法规则
- 语法规则之filepath
- LOCAL本地是哪里?
- 语法规则之OVERWRITE
- 本地加载(复制操作)
- 非本地加载(mv移动动作)
- 15.2 Hive SQL-DML-Insert 插入数据
-
- 1、Hive 3.0新特性 insert as select
- 2、 insert的使用方式
- 3、Hive官方推荐加载数据的方式︰
- 4、insert+select
- 5、multiple inserts多重插入
- 6、dynamic partition insert动态分区插入
- 7、insert Directory导出数据
- 15.3 Hive Transaction 事务表
-
- 1、Hive事务背景知识
- 2、实现原理
- 3、实现原理之delta文件夹命名格式
- 4、实现原理
- 5、合并器(Compactor)
- 6、事务表参数限制和使用设置
- 15.4 Hive SQL-DML-Update更新、Delete删除数据
- 15.5 Hive SQL-DQL-Select 查询数据
-
- 1、基础语法
-
- > SELECT 、正则
- > ALL、DISTINCT
- > WHERE
- > 分区查询、分区裁剪
- > GROUP BY
- > HAVING
- > HAVING与WHERE区别
- > LIMIT
- 执行顺序
- 2、高阶语法
-
- > ORDER BY
- > CLUSTER BY
- > DISTRIBUTE BY + SORT BY
- > CLUSTER、DISTRIBUTE、SORT、ORDER BY
- > Union联合查询
- > FROM子句中子查询( Subqueries )
- > Common Table Expressions ( CTE )CTE表达式
- 15.6 Hive SQL Join 连接操作
-
- 1、Hive Join语法规则
-
- > inner join内连接
- > left join左连接
- > right join右连接
- > full outer join全外连接
- > left semi join左半开连接
- > cross join交叉连接
- 2、Hive Join使用注意事项
- 十六、Hive内置运算符
-
- 16.1 关系运算符
-
- - is null \ is not null 空值判断
- - like \ not A like B \ rlike
- - rlike 等同于 regexp
- - regexp
- 16.2 算术运算符
-
- - 取整操作 div
- - 取余操作 %
- - 位与操作 &
- - 位或操作 |
- - 位异或操作 ^
- 16.3 逻辑运算符
-
- 与操作
- 或操作
- 非操作
- 在
- 不在
- 逻辑是否存在 EXISTS
- 16.3 字符串、复杂类型构造、复杂类型取值运算符
-
- 字符串 || concat运算
- 复杂类型构造运算符
- 复杂类型取值操作
- 十七、Hive Functions函数入门
-
- 概述
- 分类标准
- 用户定义函数UDF分类标准
- UDF分类标准扩大化
- 内置函数
-
- ( 1/8 ) string Functions字符串函数
- ( 2/8 ) Date Functions日期函数
- ( 3/8 ) Mathematical Functions数学函数
- ( 4/8 ) collection Functions集合函数
- ( 5/8 ) conditional Functions条件函数
- ( 6/8 ) Type conversion Functions类型转换函数
- ( 7/8 ) Data Masking Functions数据脱敏函数
- ( 8/8 ) Misc. Functions其他杂项函数
一、数仓仓库概念
数据仓库(英语:Data Warehouse,简称数仓、DW ) ,是一个用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持( Decision Support ) 。
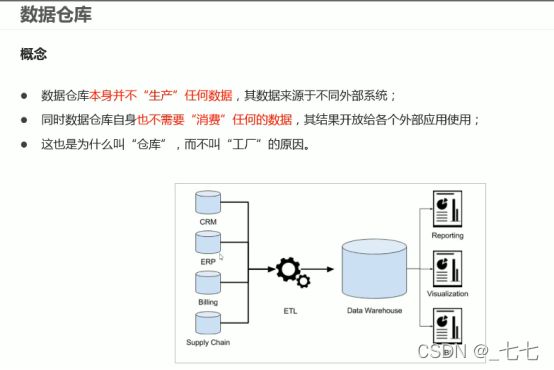

二、数据仓库分层架构

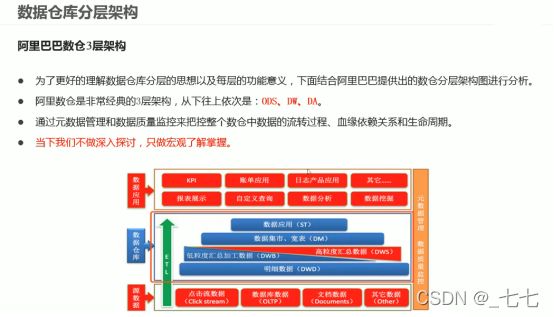
ODS\DW\DA(ADS)


ETL\ELT


三、Apache Hive 概述
为什么使用Hive

Hive和Hadoop关系



四、Apache Hive架构、组件
组件
- 用户接口
包括CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。

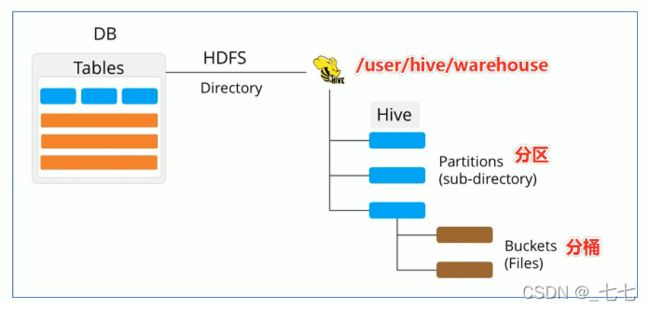
五、Apache Hive数据模型
Data Model概念
- 数据模型︰用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。
- Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型。
- Hive中的数据可以在粒度级别上分为三类:
Table表
Partition分区
Bucket分桶

Databases数据库
- Hive作为一个数据仓库,在结构上积极向传统数据库看齐,也分数据库(Schema ),每个数据库下面有各自的表组成。默认数据库default。
- Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数
hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。 - Hive中的数据库在HDFS上的存储路径为︰
$ {hive.metastore.warehouse.dir} / databasename.db

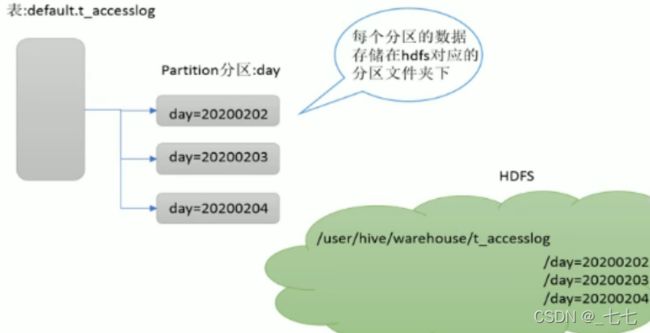
Partitions分区
Partition分区是hive的一种优化手段表。分区是指根据分区列(例如“日期day”)的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
分区在存储层面上的表现是:
table表目录下以子文件夹形式存在。
一个文件夹表示一个分区。子文件命名标准∶分区列=分区值
Hive还支持分区下继续创建分区,所谓的多重分区。
Buckets分桶
- Bucket分桶表是hive的一种优化手段表。分桶是
指根据表中字段(例如“编号ID”)的值,经过hash计算规则将数据文件划分成指定的若干个小文件。 - 分桶规则: hashfunc(字段) % 桶个数,余数相同的分到同一个文件。

Hive和MySQL对比
Hive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都十分相似,但应用场景却完全不同。
Hive只适合用来做海量数据的离线分析。
Hive的定位是数据仓库,面向分析的OLAP系统
Hive不是大型数据库,也不是要取代MySQLi承担业务数据处理。

六、元数据
元数据( Metadata ),又称中介数据、中继数据,为描述数据的数据(data about data ),主要是描述数据属性( property )的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。

Hive Metadata
Hive Metadata即Hive的元数据。
包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore
- Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。

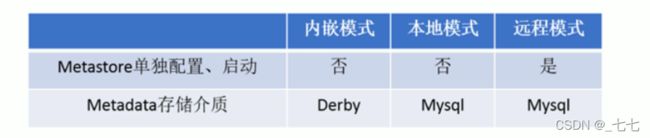
七、Metastore配置方式
概述
- metastore服务配置有3种模式∶内嵌模式、本地模式、远程模式。
- 区分3种配置方式的关键是弄清楚两个问题:
Metastore服务是否需要单独配置、单独启动?
Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
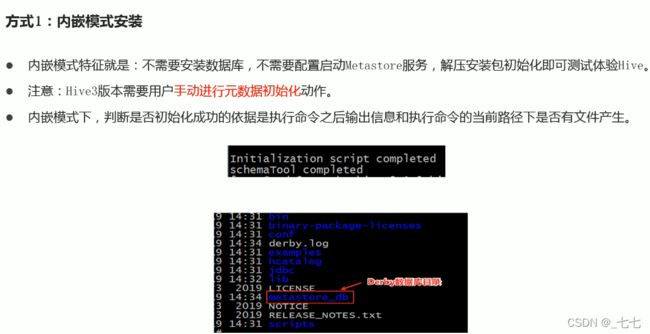
内嵌模式
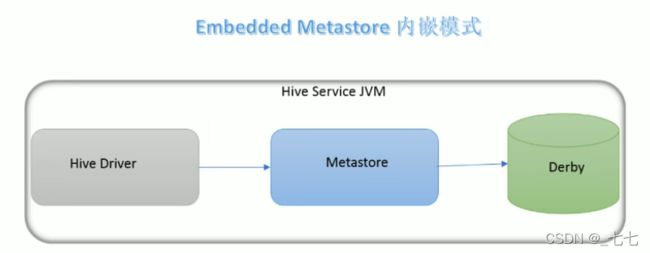
内嵌模式(Embedded Metastore )是metastore默认部署模式。
此种模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。
不需要额外起Metastore服务。
但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。
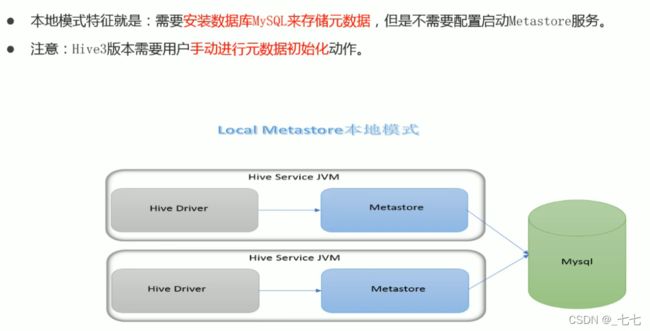
本地模式
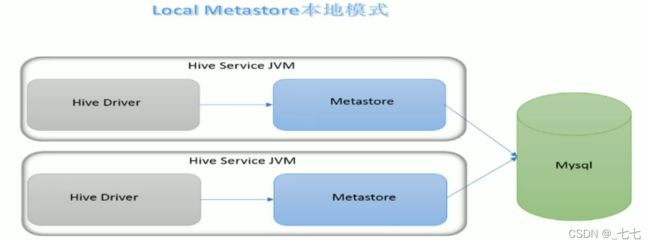
- 本地模式( Local Metastore)下,Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。
- 本地模式采用外部数据库来存储元数据,推荐使用MySQL。
- hive根据hive.metastore.uris参数值来判断,如果为空,则为本地模式。
- 缺点是∶每启动一次hive服务,都内置启动了一个metastore。
远程模式
-
远程模式(Remote Metastore )下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
-
远程模式下,需要配置hive. metastore.uris参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。元数据也采用外部数据库来存储元数据,推荐使用MySQL。
-
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。

八、Hive部署
安装前准备
- 由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
- 服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装 - Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群。特别要注意,需等待HDFS安全模式关闭之后再启动运行Hive。Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
Hadoop与Hive整合
因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行。
修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效。
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
property>

Hive下载 hive-3.1.2/
https://dlcdn.apache.org/hive/
内嵌模式
只适合测试 数据不共享
总体步骤:
#上传解压安装包
cd /export/server/
tar zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin hive
#解决hadoop hive之间guava版本差异
cd /export/ server/hive
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
#修改hive坏环境变量文件添加Hadoop_HOME
cd /export/server/hive/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
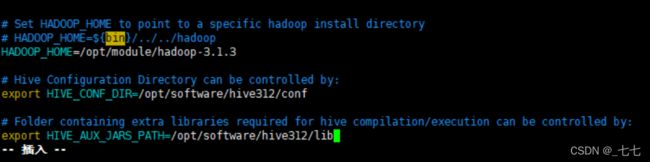
export HADOOP_HOME=/export/server/hadoop-3.1.4
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
#初始化metadata
cd /export/server/hive
bin/ schematool -dbType derby -initschema
#启动hive服务
bin/hive
解压hive
解决版本冲突
[root@hadoop102 hive312]# cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
修改环境变量

[root@hadoop102 conf]# cd ../conf
[root@hadoop102 conf]# mv hive-env.sh.template hive-e
hive-env.sh.template hive-exec-log4j2.properties.template
[root@hadoop102 conf]# mv hive-env.sh.template hive-env.sh
[root@hadoop102 conf]# vim hive-env.sh
初始化metadate
[root@hadoop102 hive312]# bin/schematool -dbType derby -initSchema
启动hive服务
[root@hadoop102 bin]# cd /opt/software/hive312/
[root@hadoop102 hive312]# bin/hive

本地模式

mysql安装

Hive安装
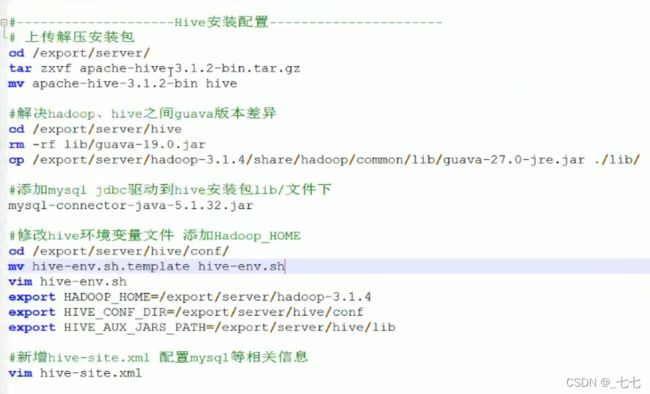
配置hive-site.xml


不管哪里启动hive 都是访问mysql
远程模式安装
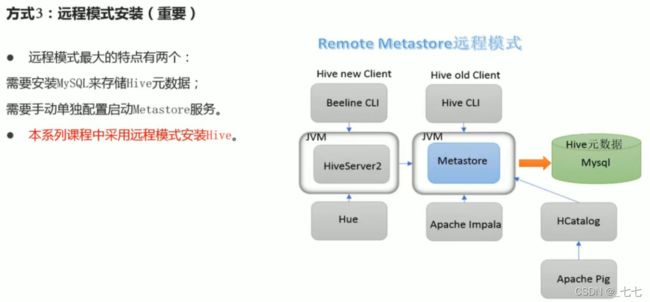
配置hive-site.xml



远程模式Meatstore
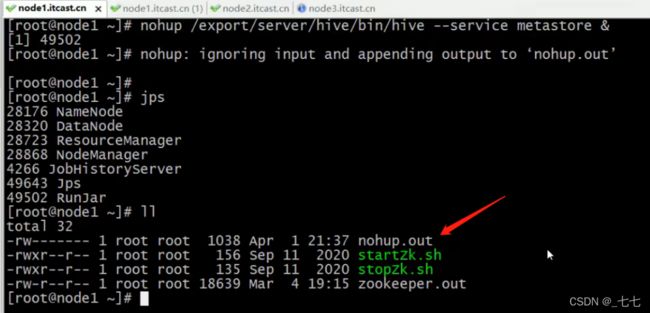
远程模式特点 元数据单独存储 元数据服务单独启动
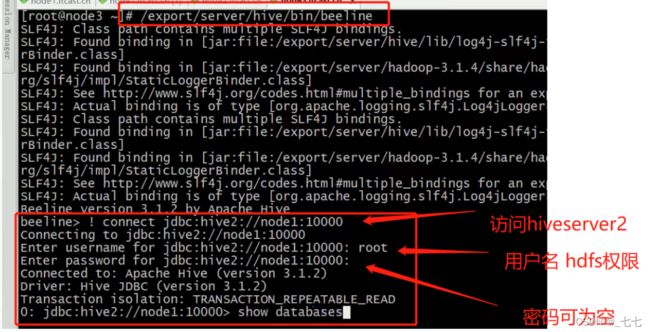
九、Hive命令行客户端

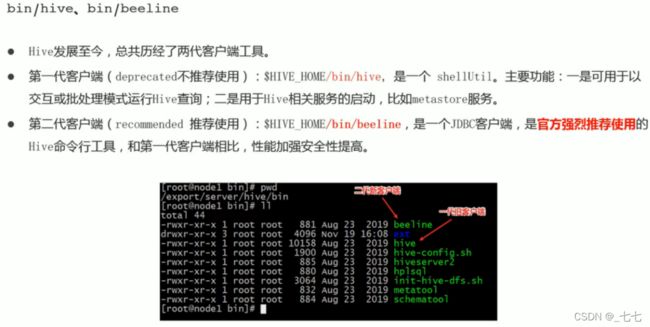

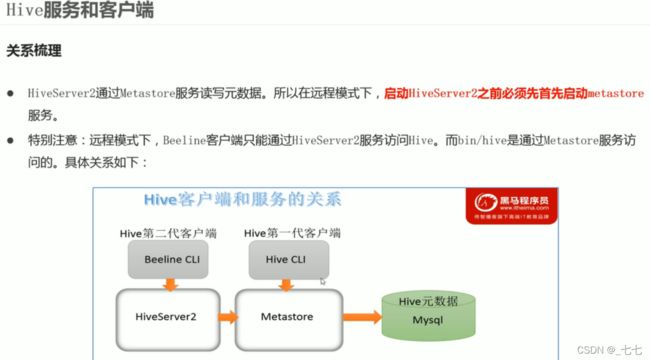
bin/hive Client


其他机器访问


bin/beeline Client


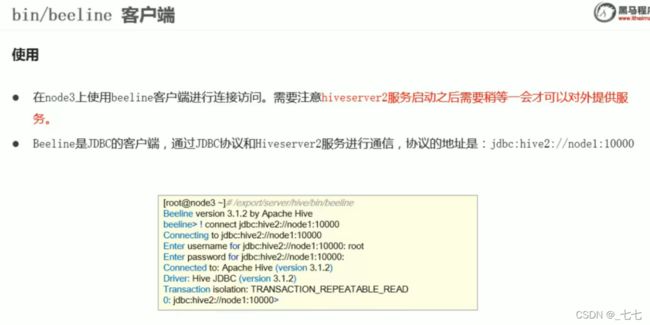

十、HIve SQL DDL相关


10.1 Hive数据类型

原生数据类型

复杂数据类型
注意事项
- Hive SQL中,数据类型英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如字符串string;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用;
- 如果定义的数据类型和文件不一致,Hive会尝试隐式转换,但是不保证成功。

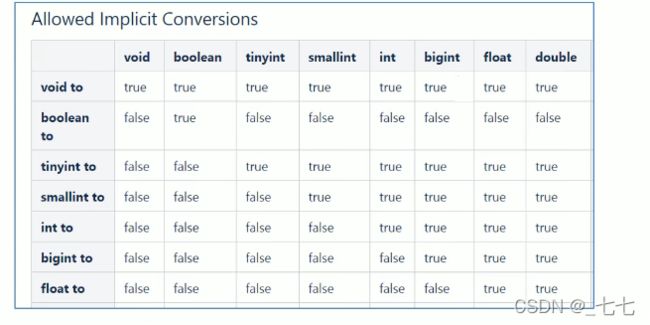
隐式转换
与标准SQL类似,HQL支持隐式和显式类型转换。
原生类型从窄类型到宽类型的转换称为隐式转换,反之,则不允许。
下表描述了类型之间允许的隐式转换︰
显示转换
显式类型转换使用CAST函数。
例如,CAST ( '100' as INT )会将100字符串转换为100整数值。
如果强制转换失败,例如CAST ( ‘Allen'as INT ),该函数返回NULL。

10.2 Hive读写文件机制
SerDe是什么
SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化
序列化是对象转化为字节码的过程 ; 而反序列化是字节码转换为对象的过程。
Hive使用SerDe(包括FileFormat )读取和写入表行对象。
需要注意的是,“key”部分在读取时会被忽略,而在写入时key始终是常数。基本上行对象存储在“value”中。

可以通过desc formatted tablename查看表的相关SerDe信息。默认如下:

-
Hive读取文件机制︰首先调用InputFormat (默认TextInputFormat ),返回一条一条kv键值对记录(默认是一行对应一条键值对)。然后调用Serbe(默认LazySimpleSerDe )的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
-
Hive写文件机制∶将Row写入文件时,首先调用SerDe (默认LazySimpleSerDe )的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS文件中。
ROW FORMAT这一行所代表的是跟读写文件、序列化SerDe相关的语法,功能有二︰
- 使用哪个SerDe类进行序列化;
- 如何指定分隔符。
SerDe相关语法
ROW FORMAT这一行所代表的是跟读写文件、序列化SerDe相关的语法,功能有二︰
- 使用哪个SerDe类进行序列化;
- 如何指定分隔符。
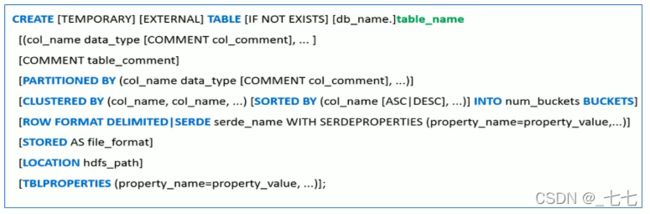
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
- 如果使用delimited表示使用默认的LazySimpleSerDe类来处理数据。
- 如果数据文件格式比较特殊可以使用ROW FORMAT SERDE serde_name指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。

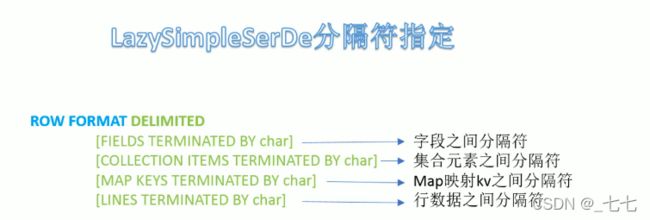
LazysimpleserDe分隔符指定
-
LazySimpleSerDe是Hlive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号。
-
在建表的时候可以根据数据的特点灵活搭配使用。
10.3 Hive默认分隔符
Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
默认的分割符是’ \001’,是一种特殊的字符,使用的是ASCII编码的值,键盘是打不出来的。
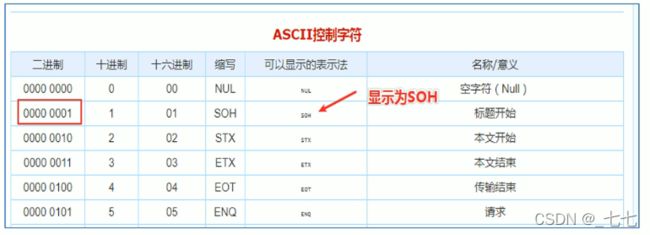
在vim编辑器中,连续按下Ctrl+v/Ctrl+a即可输入'\001',显示^A

在一些文本编辑器中将以SOH的形式显示:

10.4 Hive数据存储路径
- Hive表默认存储路径是由
${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定,默认值是︰/user/hive/warehouse。

指定存储路径
- 在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便。
- 语法∶
LOCATION '。' - 对于已经生成好的数据文件,使用location指定路径将会很方便。

row formate delimited
fileds terminated by ",";
10.5 Hive建表 且 上传文件
DROP TABLE IF EXISTS tmp_test_20220418;
CREATE table if not exists tmp_test_20220418(
id int comment 'id',
name string comment 'name'
)
row format delimited
fileds terminated by ',';
- 建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹
- 把archer.txt文件上传到对应的表文件夹下。
hadoop fs -put /root/hivedata/archer.txt /user/hive/warehouse/mytest.db/tmp_test_20220418
- 执行查询操作,可以看出数据已经映射成功。
- 核心语法:row format delimited fields terminated by指定字段之间的分隔符。
复杂数据类型
例如:前3个字段原生数据类型、最后一个字段复杂类型map。
需要指定字段之间分隔符、集合元素之间分隔符、map kv之间分隔符。

CREATE table tmp_test_20220418(
id int,
name string,
win_rate int,
skin_price map<string,int>
)row format delimited
field terminated by ',' -- 指定字段之间的分隔符
collection items terminated by '-' --指定集合元素之间的分隔符
map keys terminated by ':' --指定map元素kv之间的分隔符
location指定表路径
CREATE table if not exists tmp_test_20220418(
id int comment 'id',
name string comment 'name'
)
LOCATION '/data';--使用location关键字指定表数据在hdfs上的存储路径
10.6 Hive 内外部表
完整语法树

内部表
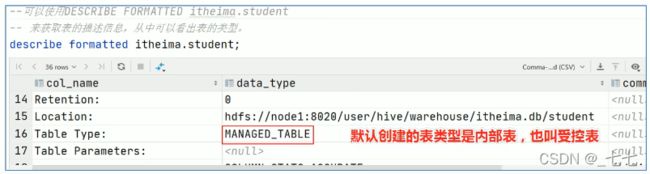
内部表( Internal table )也称为被Hive拥有和管理的托管表(Managed table )。
- 默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。
- 换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。
- 当您删除内部表时,它会删除数据以及表的元数据。

可以使用DESCRIBE FORMATTED tablename,来获取表的元数据描述信息,从中可以看出表的类型。
外部表
外部表(External table )中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。
要创建一个外部表,需要使用EXTERNAL语法关键字。
删除外部表只会删除元数据,而不会删除实际数据。
在Hive外部仍然可以访问实际数据。
实际场景中,外部表搭配location语法指定数据的路径,可以让数据更安全。

内、外部表差异
- 无论内部表还是外部表,Hive都在Hlive Metastore中管理表定义、字段类型等元数据信息。
- 删除内部表时,除了会从Metastore中删除表元数据,还会从HDFS中删除其所有数据文件。
- 删除外部表时,只会从Metastore中删除表的元数据,并保持HDFS位置中的实际数据不变。
如何选择内、外部表
- 当需要通过Hive完全管理控制表的整个生命周期时,请使用内部表。
- 当数据来之不易,防止误删,请使用外部表,因为即使删除表,文件也会被保留。
Location关键字的作用
在创建外部表的时候,可以使用location指定存储位置路径,如果不指定会如何?
如果不指定location,外部表的默认路径也是位于/user/hive/warehouse,由默认参数控制。·创建内部表的时候,是否可以使用location指定?
内部表可以使用location指定位置的。
·是否意味着Hive表的数据在HDFS上的位置不是一定要在/user/hive/warehouse下?
不一定,Hive中表数据存储位置,不管内部表还是外部表,默认都是在/user/hive/warehouse,当然可以在建表的时候通过location关键字指定存储位置在HDFS的任意路径。
10.7 Hive Partitioned Tables 分区表
概念
- 当Hive表对应的数据量大、文件个数多时,为了避免查询时全表扫描数据,Hive支持根据指定的字段对表进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。
- 比如把一整年的数据根据月份划分12个月( 12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。

语法树


分区字段不能和表中字段重复
分区表数据加载–静态分区
所谓静态分区指的是分区的属性值是由用户在加载数据的时候手动指定的。
语法如下:
load data [local] inpath 'filepath' into table tablename partition(分区字段 = '分区值'...);
Local参数用于指定待加载的数据是位于本地文件系统还是HDFS文件系统。

本质
- 外表上看起来分区表好像没多大变化,只不过多了一个分区字段。
- 实际上分区表在底层管理数据的方式发生了改变。这里直接去HDFS查看区别。

多重分区表
- 通过建表语句中关于分区的相关语法可以发现,Hive支持多个分区字段∶PARTITIONED BY (partitionl data_type,partition2 data_type,…)。
- 多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。
从HDFS的角度来看就是文件夹下继续划分子文件夹。比如∶把全国人口数据首先根据省进行分区,然后根据市进行划分,如果你需要甚至可以继续根据区县再划分,此时就是3分区表。



分区表数据加载–动态分区
- 所谓动态分区指的是分区的字段值是基于查询结果(参数位置)自动推断出来的。
核心语法就是insert+select。 - 启用hive动态分区,需要在hive会话中设置两个参数︰

分区表的注意事项
- 一、分区表不是建表的必要语法规则,是一种优化手段表,可选;
- 二、分区字段不能是表中已有的字段,不能重复;
- 三、分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 四、分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
- 五、Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度。
10.8 Hive Bucketed Tables分桶表
概念
- 分桶表也叫做桶表,bucket,是一种用于优化查询而设计的表类型。
- 分桶表对应的数据文件在底层会被分解为若干个部分,通俗来说就是被拆分成若干个独立的小文件。
- 在分桶时,要指定根据哪个字段将数据分为几桶(几个部分)。
规则
- 分桶规则如下∶桶编号相同的数据会被分到同一个桶当中。

- hash_function取决于分桶字段bucketing_column的类型:
- 1.如果是int类型,hash_function(int) == int;
- 2.如果是其他比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。

完整语法树

语法
- CLUSTERED BY (col_name)表示根据哪个字段进行分;
- INTO N BUCKETS表示分为几桶(也就是几个部分)。
- 需要注意的是,分桶的字段必须是表中已经存在的字段。

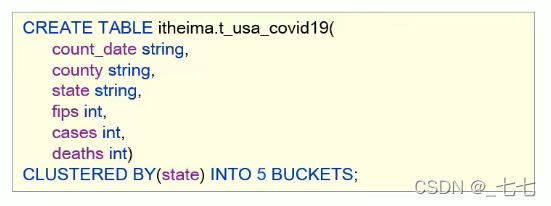
分桶表的创建
- 根据state州把数据分为5桶,建表语句如下∶
- 在创建分桶表时,还可以指定分桶内的数据排序规则:

分桶表的数据加载

使用好处
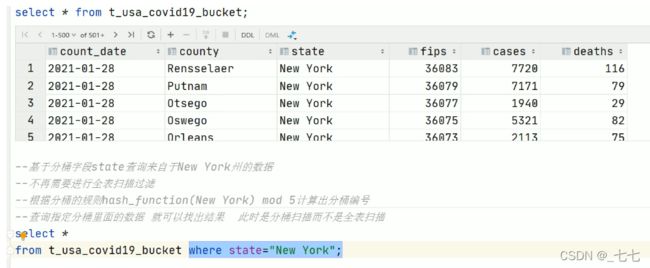
- (1/3)基于分桶字段查询时,减少全表扫描

- (2/3)JOIN时可以提高MR程序效率,减少笛卡尔积数量根据join的字段对表进行分桶操作
(比如下图中id是join的字段)

- (3/3)分桶表数据进行高效抽样
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。
抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
10.9 Hive Transactional Tables事务表
Hive事务背景知识
- Hive本身从设计之初时,就是不支持事务的,因为llive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理,是一款面向分析的工具。且映射的数据通常存储于HDFS上,而HDFS是不支持随机修改文件数据的。
- 这个定位就意味着在早期的Hive的SQL语法中是没有update,delete操作的,也就没有所谓的事务支持了,因为都是select查询分析操作。
- 从Hive0.14版本开始,具有ACID语义的事务已添加到Hive中,以解决以下场景下遇到的问题
- 尺寸变化缓慢
星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改导致需要插入单个记录或更新单条记录(取决于所选策略)。 - 数据重述
有时发现收集的数据不正确,需要更正。
局限性
- 虽然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多局限性。原因很简单,毕竟Hive的设计目标不是为了支持事务操作,而是支持分析操作,且最终基于HDFs的底层存储机制使得文件的增加删除修改操作需要动一些小心思。
- 一、
尚不支持 BEGIN ,COMMIT 和 ROLLBACK 。所有语言操作都是自动提交的。 - 二、
仅支持ORC文件格式(STORED AS ORC )。 - 三、默认情况下事务配置为关闭。需要
配置参数开启使用。 - 四、表必须是
分桶表( Bucketed )才可以使用事务功能。 - 五、表参数
transactional 必须为 true。 - 六、外部表不能成为ACID表,不允许从非ACID会话读取/写入ACID表。
创建事务表


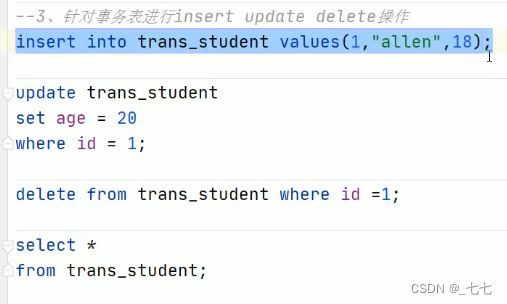
并没有对文件修改 只是对文件进行 删除标记,使文件不能被查询。
10.10 Hive Views 视图
概念
- Hive中的
视图( view )是一种虚拟表,只保存定义,不实际存储数据。 - 通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图。
- 创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败。
视图是用来简化操作的,不缓冲记录,也没有提高查询性能。

创建视图的好处
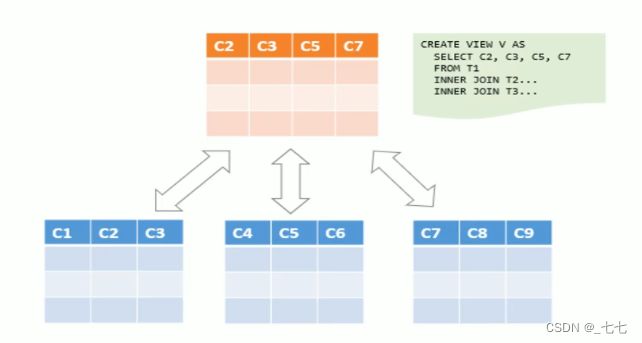
1、将真实表中特定的列数据提供给用户,保护数据隐私

2、降低查询的复杂度,优化查询语句

10.11 Hive3.0新特性:Materialized Views 物化视图
概念
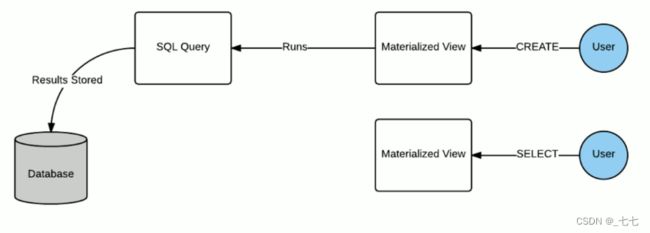
- 物化视图( Materialized View )是一个包括查询结果的数据库对像,可以用于预先计算并保存表连接或聚集等耗时较多的操作的结果。
- 在执行查询时,就可以避免进行这些耗时的操作,而从快速的得到结果。
- 使用物化视图的目的就是通过预计算,提高查询性能,当然需要占用一定的存储空间。
- Hive3.0开始尝试引入物化视图,并提供对于物化视图的查询自动重写机制(基于Apache Calcite实现)。
- Hive的物化视图还提供了物化视图存储选择机制,可以本地存储在Hive,也可以通过用户自定义storage handlers存储在其他系统( 如Druid )。
- Hive引入物化视图的目的就是为了优化数据查询访问的效率,相当于从数据预处理的角度优化数据访问。
- Hive从3.0丢弃了index索引的语法支持,推荐使用物化视图和列式存储文件格式来加快查询的速度。
物化视图、视图区别
- 视图是虚拟的,逻辑存在的,只有定义没有存储数据。
- 物化视图是真实的,物理存在的,里面存储着预计算的数据。
物化视图能够缓存数据,在创建物化视图的时候就把数据缓存起来了,Hive把物化视图当成一张“表”,将数据缓存。而视图只是创建一个虚表,只有表结构,没有数据,实际查询的时候再去改写SQL去访问实际的数据表。 - 视图的目的是简化降低查询的复杂度,而物化视图的目的是提高查询性能。
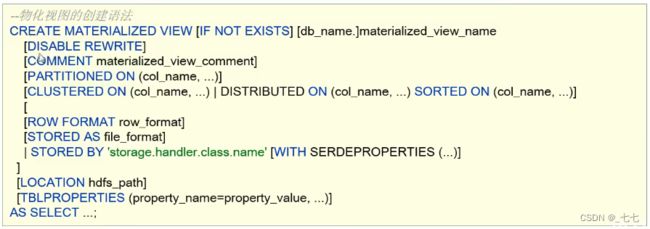
语法
- (1) 物化视图创建后,select查询执行数据自动落地,“自动”也即在query的执行期间,任何用户对该物化视图是不可见的,执行完毕之后物化视图可用;
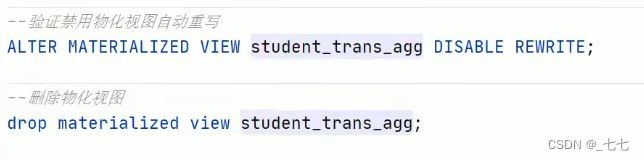
- (2) 默认情况下,创建好的物化视图可被用于查询优化器optimizer查询重写,在物化视图创建期间可以通过DISABLEREWRITE参数设置禁止使用。
- (3)默认SerDe和storage format为hive.materializedview.serde、hive.materializedview.fileformat ;
- (4)物化视图支持将数据存储在外部系统(如druid ),如下述语法所示:

(5)目前支持物化视图的drop和show操作,后续会增加其他操作

( 6 )当数据源变更(新数据插入inserted、数据修改modified ),物化视图也需要更新以保持数据一致性,目前需要用户主动触发rebuild重构。

基于物化视图的查询重写
- 物化视图创建后即可用于相关查询的加速,即∶用户提交查询query,若该query经过重写后可以命中已经存在的物化视图,则直接通过物化视图查询数据返回结果,以实现查询加速。
- 是否重写查询使用物化视图可以通过全局参数控制,默认为true :
hive.materializedview.rewriting=true; - 用户可选择性的控制指定的物化视图查询重写机制,语法如下:

代码:

十一、Hive Database | Schema(数据库)DDL操作
整体概述
- 在Hive中,DATABASE的概念和RDBMS中类似,我们称之为数据库,DATABASE和SCHEMA是可互换的都可以使用。
- 默认的数据库叫做default,存储数据位置位于/user/hive/warehouse下。
- 用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下。
11.1 create database 创建数据库
create database用于创建新的数据库
- COMMENT:数据库的注释说明语句
- LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname. db
- WITH DBPROPERTIES∶用于指定一些数据库的属性配置。

11.2 describe database 描述数据库
describe database
- 显示Hive中数据库的名称,注释(如果已设置)及其在文件系统上的位置等信息。
- EXTENDED关键字用于显示更多信息。
- 可以将关键字describe简写成desc使用。
![]()
11.3 use database 切换数据库
use database
- 选择特定的数据库
- 切换当前会话使用哪一个数据库进行操作
11.4 drop database 删除数据库
drop database
- 删除数据库
- 默认行为是RESTRICT,这意味着仅在数据库为空时才删除它。
- 要删除带有表的数据库(不为空的数据库),我们可以使用CASCADE。

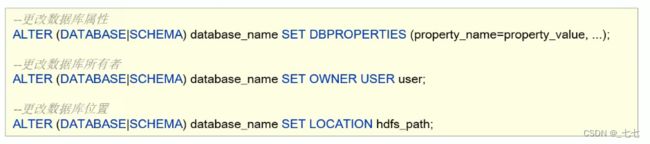
11.5 alert database 修改数据库
十二、Hive Table 表的 DDL操作
12.1 整体概述
- Hive中针对表的DDL操作可以说是DDL中的核心操作,包括建表、修改表、删除表、描述表元数据信息。
- 其中以建表语句为核心中的核心,详见Hive DDL建表语句。
- 可以说表的定义是否成功直接影响着数据能够成功映射,进而影响是否可以顺利的使用Hive开展数据分析。
- 由于Hive建表之后加载映射数据很快,实际中如果建表有问题,可以不用修改,直接删除重建。
12.2 describe table
显示Hive中表的元数据信息

describe formatted table_name;
- 如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。
- 如果指定了FORMATTED关键字,则它将以表格格式显示元数据。
12.3 drop table
drop table
- 删除该表的元数据和数据
- 如果已配置垃圾桶且未指定PURGE,则该表对应的数据实际上将移动到HDFS垃圾桶,而元数据完全丢失。删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据。
- 如果指定了PURGE,则表数据跳过HDFS垃圾桶直接被删除。因此如果DROP失败,则无法挽回该表数据。

12.4 truncate table 清空表
truncate table
- 从表中删除所有行。
- 可以简单理解为清空表的所有数据但是保留表的元数据结构。如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除。

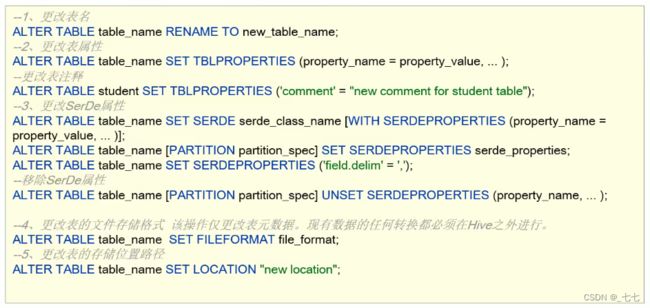
12.5 alter table
十三、Hive Partition (分区) DDL操作
- Hive中针对分区Partition的操作主要包括∶
增加分区、删除分区、重命名分区、修复分区、修改分区。
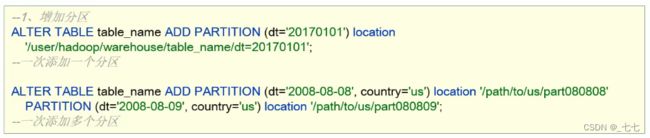
13.1 add partition
- ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询时将不会返回结果。
- 因此需要保证增加的分区位置路径下,数据已经存在,或者增加完分区之后导入分区数据
13.2 rename partition

13.3 delete partition
删除表的分区。这将删除该分区的数据和元数据。

13.4 alter partition

13.5 MSCK partition
- Hive将每个表的分区列表信息存储在其metastore中。但是,如果将新分区直接添加到HDFS( 例如通过使用
hadoopfs -put命令 )或从HDFS中直接删除分区文件夹,则除非用户ALTER TABLE table_name ADD/DROP PARTITION在每个新添加的分区上运行命令,否则metastore ( 也就是Hive )将不会意识到分区信息的这些更改。 MSCK是metastore check的缩写,表示元数据检查操作,可用于元数据的修复。

- MSCK默认行为ADD PARTITIONS,使用此选项,它将把HDFS上存在但元存储中不存在的所有分区添加到metastore。
- DROP PARTITIONS选项将从已经从HDFS中删除的metastore中删除分区信息。
- SYNC PARTITIONS选项等效于调用ADD和DROP PARTITIONS。
- 如果存在大量未跟踪的分区,则可以批量运行MSCK REPAIR TABLE,以避免OOME(内存不足错误
案例 Hive MSCK 修复partition
- example 1 :创建一张分区表,直接使用HDFS命令在表文件夹下创建分区文件夹并上传数据,此时在Hive中
查询是无法显示表数据的,因为metastore中没有记录,使用MSCK ADD PARTITIONS进行修复。


- example 2 :针对分区表,直接使用HDFS命令删除分区文件夹,此时在Hive中查询显示分区还在,因为
metastore中还没有被删除,使用MSCK DROP PARTITIONS进行修复。

十四、Hive SHOW语法
- Show相关的语句提供了一种查询Hive metastore的方法。可以帮助用户查询相关信息。
- 比如我们最常使用的查询当前数据库下有哪些表show tables。
--1、显示所有数据库SCHEMAS.和DATABASES的用法功能一样
show databases;
show schemas;
--2、显示当前数据库所有表/视图/物化视图/分区/索引
show tables;
SHOW TABLES [IN database_name] ; --指定某个数据库
3、显示当前数据库下所有视图
show VIEWS;
shoW VIEWS 'test_* '; -- show dll views that start with "test_"
SHoW VIEWS FROM test1; -- show views from database test1
show VIEWS [IN/FROM database_name];
--4、显示当前数据库下所有物化视图
SHOW MATERIALIZED VIEWS [IN/FROM database_name];
--5、显示表分区信息,分区按字母顺序列出,不是分区表执行该语句会报错
show partitions table_name;
--6、显示表/分区的扩展信息
SHOW TABLE EXTENDED [INIFROM database_name] LIKE table_name;
show table extended like student;
--7、显示表的属性信息
SHOW TBLPROPERTIES table_name;
show tblproperties student;
--8、显示表、视图的创建语句
SHoW CREATE TABLE ([db_name.]table_name|view_name);
show create table student;
--9、显示表中的所有列,包括分区列。
show COLUANS (FROM|IN) table_name [(FROM|IN) db_name];
show columns in student;
--10、显示当前支持的所有自定义和内置的函数
show functions;
--11、Describe desc
--查看表信息
desc extended table_name;
--查看表信恳(格式化美观)
desc formatted table_name;
--查看数据库相关信息
describe database database_name;
十五、HiveSQL数据操控、查询语言(DML、DQL ) 对数据进行增删改查操作
15.1 Hive SQL-DML-Load 加载数据
- 不管路径在哪里,只有把数据文件移动到对应的表文件夹下面,Hive才能映射解析成功
- 最原始暴力的方式就是使用
hadoop fs -put | -mv等方式直接将数据移动到表文件夹下 - 但是,Hive官方推荐使用Load命令将数据加载到表中。

功能
- Load英文单词的含义为∶加载、装载;
- 所谓加载是指︰将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作。
- 纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作。
语法规则
LOAD DATA [LOCAL] INPATH 'filepath'[OVERWRITE] INTO TABLE tablename [PARTITION(partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath'[OVERWRITE] INTO TABLE tablename [PARTITION(partcol1=val1, partcol2=val2 ...)][INPUTFORMAT 'inputformat' SERDE 'serde'](3.0 or later)
语法规则之filepath
-
filepath表示待移动数据的路径。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在这种情况下,Hive将把该目录中的所有文件移动到表中)。
-
filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑︰
-
1、相对路径,例如:
project/datal
2、绝对路径,例如:/user/hive/project/data1
3、具有schema的完整URI,例如:hdfs://namenode:9000/user/hive/project/data1 -
指定LOCAL,将在本地文件系统中查找文件路径。
若指定相对路径,将相对于用户的当前工作目录进行解释;
用户也可以为本地文件指定完整的URI - 例如:file:///user/hive/project/data1。 -
没有指定LOCAL关键字。
如果filepath指向的是一个完整的URI,会直接使用这个URI;
如果没有指定schema,Hive会使用在hadoop配置文件中参数fs.default.name指定的(不出意外,都是HDFS )。

LOCAL本地是哪里?
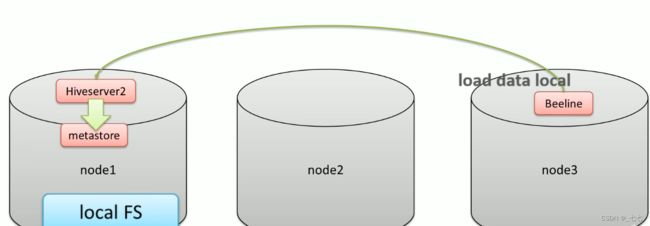
- 如果对HiveServer2服务运行此命令
本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统。
语法规则之OVERWRITE
如果使用了OVERWRITE关键字,则目标表(或者分区)中的已经存在的数据会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中。
本地加载(复制操作)


非本地加载(mv移动动作)

加载分区(前提为分区表)

15.2 Hive SQL-DML-Insert 插入数据
1、Hive 3.0新特性 insert as select
- Hive3.0+,load加载数据时除了移动、复制操作之外,在某些场合下还会将加载重写为
INSERT AS SELECT。 - Hive3.0+,还支持使用inputformat、SerDe指定输入格式,例如Text,ORC等。
比如,如果表具有分区,则load命令没有指定分区,则将load转换为INSERT AS SELECT,并假定最后一组列为分区列,如果文件不符合预期,则报错。

本来加载的时候没有指定分区,语句是报错的,但是文件的格式符合表的结构,前两个是col1, col2,最后一个是分区字段col3,则此时会将load语句转换成为insert as select语句。


2、 insert的使用方式
背景:RDBMS中如何使用insert
- 在MySQL这样的RDBMS中,通常使用insert+values的方式来向表插入数据,并且执行速度很快。
- 这也是RDBMS中表插入数据的核心方式。

假如把Hive当成RDBMS,用insert+values的方式插入数据,会如何? - 执行过程非常非常慢,原因在于底层是使用MapReduce把数据写入Hive表中
试想一下,如果在Hive中使用insert+values,对于大数据环境一条条插入数据,用时难以想象。
3、Hive官方推荐加载数据的方式︰
- 清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高。
- 但是并不意味insert语法在Hive中没有用武之地。
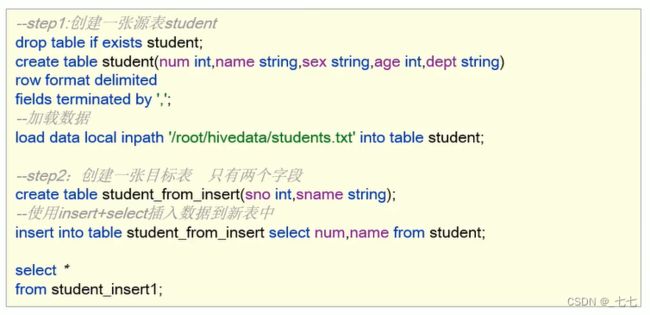
4、insert+select
insert+select表示∶将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据。
-
1.需要保证查询结果列的数目和需要插入数据表格的列数目一致。
-
2.如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL。

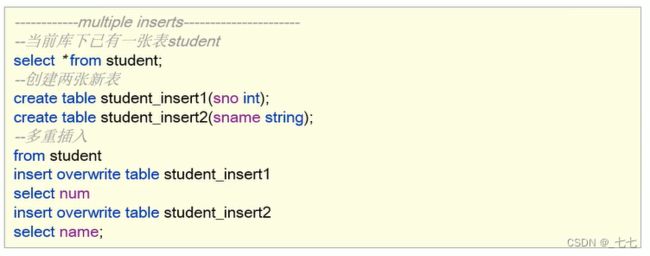
5、multiple inserts多重插入
- 翻译为多次插入,多重插入,其核心功能是:一次扫描,多次插入。
- 语法目的就是减少扫描的次数,在一次扫描中。完成多次insert操作。
6、dynamic partition insert动态分区插入
- 对于分区表的数据导入加载,最基础的是通过load命令加载数据。
- 在load过程中,分区值是手动指定写死的,叫做静态分区。

问题:
1.假如说现在有全球224个国家的人员名单(每个国家名单单独一个文件),导入到分区表中,不同国家不同分区,如何高效实现?
2.使用load语法导入224次?
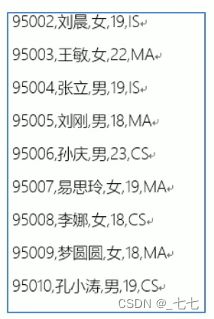
背景
再假如,现在有一份名单students.txt,内容如下;
要求创建一张分区表,根据最后一个字段(选修专业)进行分区,同一个专业的同学分到同一个分区中,如何实现 ?
动态分区
概述
动态分区插入指的是︰分区的值是由后续的select查询语句的结果来动态确定的。
根据查询结果自动分区。



7、insert Directory导出数据
语法格式
Hive支持将select查询的结果导出成文件存放在文件系统中。语法格式如下;注意∶导出操作是一个OVERWRITE覆盖操作,慎重。
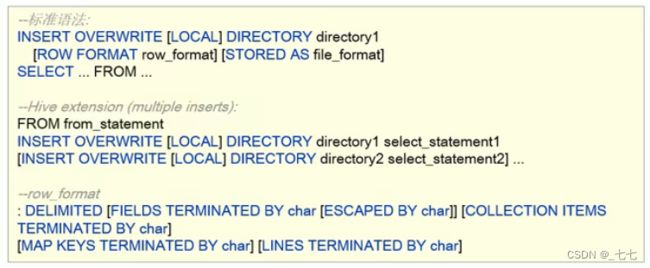
- 目录可以是完整的URI。如果未指定scheme,则Hive将使用hadoop配置变量fs.default.name来决定导出位置;
- 如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录;
- 写入文件系统的数据被序列化为文本,列之间用\001隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式。

15.3 Hive Transaction 事务表
1、Hive事务背景知识
Hive设计之初时,是不支持事务的,原因︰
- Hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理,是—款面向历史、面向分析的工具;
- Hive作为数据仓库,是分析数据规律的,而不是创造数据规律的;
- Hive中表的数据存储于HDFS上,而HDFS是不支持随机修改文件数据的,其常见的模型是一次写入,多次读取。
从Hive0.14版本开始,具有ACID语义的事务(支持INSERT,UPDATE,DELETE)已添加到Hive中。
以解决以下场景下遇到的问题∶
- 流式传输数据
使用如Apache Flume或Apache Kafka之类的工具将数据流式传输到现有分区中,可能会有脏读(开始查询后能看到写入的数据)。- 变化缓慢数据更新
星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改需要插入单个记录或更新记录(取决于所选策略)。- 数据修正
有时发现收集的数据不正确,需要局部更正。
2、实现原理
Hive的文件是存储在HDFS上的,而HDFS上又不支持对文件的任意修改,只能是采取另外的手段来完成。
- 1、用HDFS文件作为原始数据(基础数据),用delta保存事务操作的记录增量数据;
- 2、正在执行中的事务,是以一个staging开头的文件夹维护的,执行结束就是delta文件夹。
每次执行一次事务操作都会有这样的一个delta增量文件夹; - 3、当访问Hive数据时,根据HDFS原始文件和delta增量文件做合并,查询最新的数据。

- INSERT语句会直接创建delta目录;
- DELETE目录的前缀是delete_delta;
- UPDATE语句采用了split-update特性,即先删除、后插入;

3、实现原理之delta文件夹命名格式
- delta_minWID_maxWID_stmtID,即delta前缀、写事务的ID范围、以及语句ID;删除时前缀是delete_delta,里面包含了要删除的文件;
- Hive会为写事务(INSERT、DELETE等)创建一个写事务ID (Write ID),该ID在表范围内唯一;
- 语句ID ( Statement ID )则是当一个事务中有多条写入语句时使用的,用作唯一标识。

4、实现原理
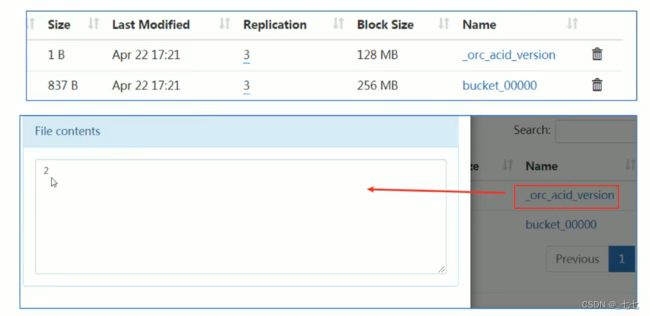
- 每个事务的delta文件夹下,都有两个文件:
- _orc_acid_version的内容是2,即当前ACID版本号是2。和版本1的主要区别是UPDATE语句采用了split-update特性,即先删除、后插入。这个文件不是ORC文件,可以下载下来直接查看。
2. bucket_00000文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以ORC格式
存储,底层二级制,需要使用ORC TOOLS查看。

- operation:0表示插入,1表示更新,2表示删除。由于使用了split-update,UPDATE是不会出现的,所以delta文件中的operation是0 , delete_delta文件中的operation是2。
- originalTransaction、currentTransaction:该条记录的原始写事务ID,当前的写事务ID。
- rowld:一个自增的唯一ID,在写事务和分桶的组合中唯一。
- row:具体数据。对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据。
ORC TOOLS:

5、合并器(Compactor)
- 随着表的修改操作,创建了越来越多的delta增量文件,就需要合并以保持足够的性能。
- 合并器Compactor是一套在Rive Metastore内运行,支持ACID系统的后台进程。所有合并都是在后台完成的,不会阻止数据的并发读、写。合并后,系统将等待所有旧文件的读操作完成后,删除旧文件。
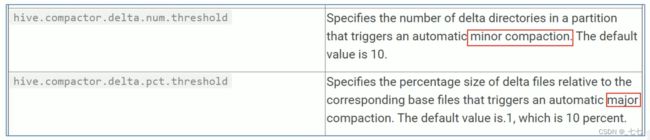
- 合并操作分为两种,minor compaction (小合并)、major compaction(大合并):
小合并会将一组delta增量文件重写为单个增量文件,默认触发条件为10个delta文件;
大合并将一个或多个增量文件和基础文件重写为新的基础文件,默认触发条件为delta文件相应于基础文件占比,10%。
6、事务表参数限制和使用设置
局限性
虽然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多限制;
- 尚不支持BEGIN,COMMIT和 ROLLBACK,所有语言操作都是自动提交的;
- 表文件存储格式仅支持ORC ( STORED AS ORC ) ;
- 需要配置参数开启事务使用;
- 外部表无法创建为事务表,因为Hive只能控制元数据,无法管理数据;
- 表属性参数transactional必须设置为true;
- 必须将Hive事务管理器设置为org.apache.hadoop.hive.ql.lockmgr.DbTxnManager才能使用ACID
- 事务表不支持LOAD DATA …语句。只能使用insert 语法。
设置参数
客户端

服务端

创建使用

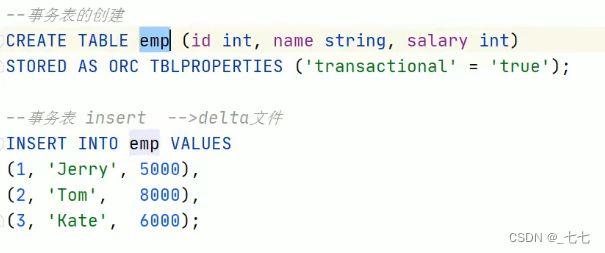
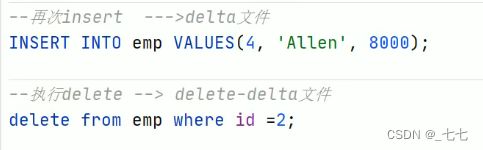

15.4 Hive SQL-DML-Update更新、Delete删除数据
概述
- Hive是基于HIadoop的数据仓库,是面向分析支持分析工具。将已有的结构化数据文件映射成为表,然后提供SQL分析数据的能力。
- 因此在Hive中常见的操作就是分析查询select操作。
- Hive早期是不支持update和delete语法的,因为Hive所处理的数据都是已经存在的的数据、历史数据。
- 后续Hive支持了相关的update和delete操作,不过有很多约束。详见Hive事务的支持。
不是事务表,执行update语句会报错

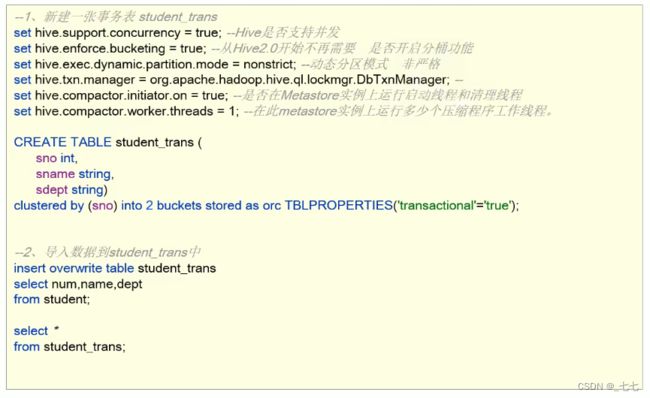
创建事务表

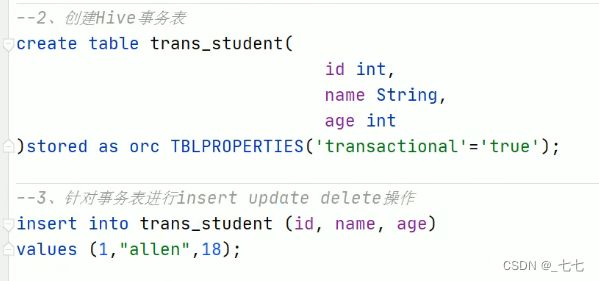
创建事务表后可进行更新删除操作
15.5 Hive SQL-DQL-Select 查询数据
语法树
从哪里查询取决于FROM关键字后面的table_reference。可以是普通物理表、视图、 join结果或子查询结果。
- 表名和列名不区分大小写。

案例


1、基础语法
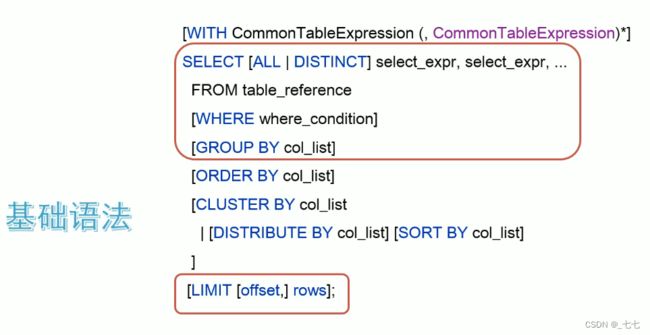
> SELECT 、正则


> ALL、DISTINCT
用于指定查询返回结果中重复的行如何处理。
1、如果没有给出这些选项,则默认值为ALL(返回所有匹配的行)。
2、DISTINCT指定从结果集中删除重复的行。


> WHERE
- WHERE后面是一个布尔表达式,用于查询过滤。
- 在WHERE表达式中,可以使用Hive支持的任何函数和运算符,但聚合函数除外。
- 那么为什么不能在where子句中使用聚合函数呢?
因为聚合函数要使用它的前提是结果集已经确定。而where子句还处于“确定”结果集的过程中,因而不能使用聚合函数。
从Hive 0.13开始,WHERE子句支持某些类型的子查询。



> 分区查询、分区裁剪
- 针对Hive分区表,在查询时可以指定分区查询,减少全表扫描,也叫做分区裁剪。
- 所谓分区裁剪指:对分区表进行查询时,会检查WHERE子句或JOIN中的ON子句中是否存在对分区字段的过滤,如果存在,则仅访问查询符合条件的分区,即裁剪掉没必要访问的分区。
> GROUP BY
- GROUP BY语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
> HAVING
- 在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用。
- HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where ,group by已经执行结束,结果集已经确定。

> HAVING与WHERE区别
-
having是在分组group by后对数据进行过滤where是在分组前对数据进行过滤。
-
having后面可以使用聚合函数where后面不可以使用聚合函数。
> LIMIT

- LIMIT用于限制SELECT语句返回的行数。
- LIMIT接受一个或两个数字参数,这两个参数都必须是非负整数常量。
- 第一个参数指定要返回的第一行的偏移量(从Hive 2.0.0开始),第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为0。
- 如 limit 2,3 从索引2(索引0开始),返回3条数据。
执行顺序
在查询过程中执行顺序:from > where > group(含聚合)>having >order > select;
- 聚合语句(sum, min, max, avg, count) 要比 having子句优先执行
- where子句在查询过程中执行优先级别优先于聚合语句(sum, min, max, avg, count)
2、高阶语法

> ORDER BY
- Hive SQL中的ORDER BY语法类似于标准SQL语言中的ORDER BY语法,会对输出的结果进行全局排序。
因此当底层使用lMapReduce引擎执行的时候,只会有一个reducetask执行。如果输出的行数太大,会导致需要很长的时间才能完成全局排序。 - 默认排序为升序( ASC ) ,也可以指定为DESC降序。
- 在Hive 2.1.0和更高版本中,支持在ORDER BY子句中为每个列指定null类型结果排序顺序。ASC顺序的默认空排序顺序为NULLS FIRST,而DESC顺序的默认空排序顺序为NULLS LAST。

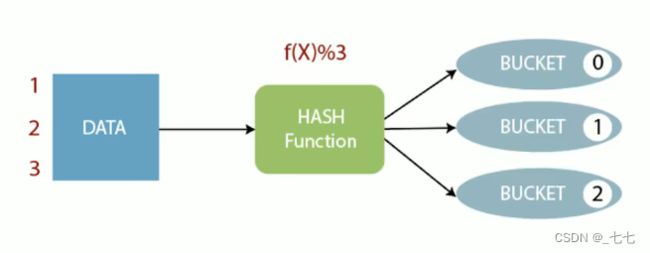
> CLUSTER BY
- 根据指定字段将数据分组,每组内再根据该字段正序排序(只能正序)。
概况起来就是︰根据同一个字段,分且排序。 - 分组规则hash散列(分桶表规则一样) : Hash_Func(col_name) % reducetask个数
- 分为几组取决于reducetask的个数
示例:

排序分组为1
再设置reduces为2


执行结果如下:分为两个部分,每个部分内正序排序。

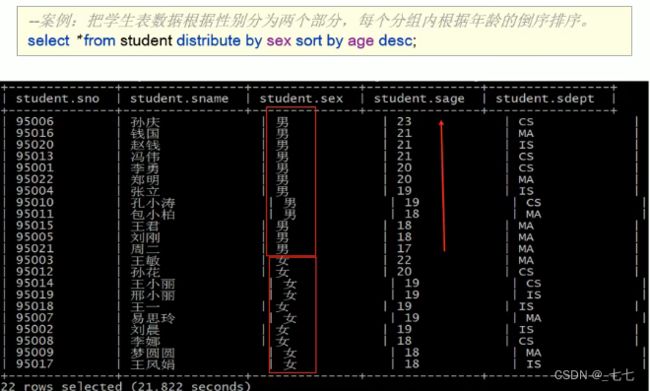
思考需求∶
根据sex性别分为两个部分,每个分组内再根据age年龄的倒序排序。
- CLUSTER BY无法单独完成,因为分和排序的字段只能是同一个;
- ORDER BY更不能在这里使用,因为是全局排序,只有一个输出,无法满足分的需求。
> DISTRIBUTE BY + SORT BY

- DISTRIBUTE BY + SORT BY就相当于把CLUSTER BY的功能一分为二︰
- DISTRIBUTE BY负责根据指定字段分组;
- SORT BY负责分组内排序规则。
- 分组和排序的字段可以不同。
> CLUSTER、DISTRIBUTE、SORT、ORDER BY
- order by全局排序,因此只有一个reducer,结果输出在一个文件中,当输入规模大时,需要较长的计算时间。
- distribute by根据指定字段将数据分组,算法是hash散列。sort by是在分组之后,每个组内局部排序。
- cluster by既有分组,又有排序,但是分组和排序只能是同一个字段。
- 如果distribute和sort的字段是同一个时,此时,cluster by = distribute by + sort by。
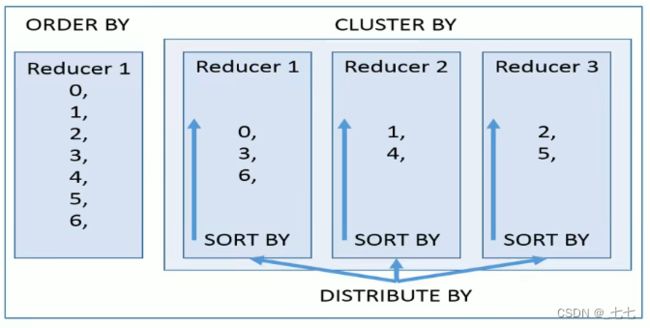
> Union联合查询

UNION用于将来自于多个SELECT语句的结果合并为一个结果集。
- 使用DISTINCT关键字与只使用UNION默认值效果一样,都会删除重复行。1.2.0之前的Hive版本仅支持UNION ALL,在这种情况下不会消除重复的行。
- 使用ALL关键字,不会删除重复行,结果集包括所有SELECT语句的匹配行(包括重复行)。
- 每个 select_statement 返回的列的数量和名称必须相同。
> FROM子句中子查询( Subqueries )
- 在Hive0.12版本,仅在FROM子句中支持子查询。
必须要给子查询一个名称,因为FROM子句中的每个表都必须有一个名称。子查询返回结果中的列必须具有唯一的名称。子查询返回结果中的列在外部查询中可用,就像真实表的列一样。子查询也可以是带有UNION的查询表达式。 - Hive支持任意级别的子查询,也就是所谓的嵌套子查询。
- Hive 0.13.0和更高版本中的子查询名称之前可以包含可选关键字AS。

where子句中子查询( Subqueries )
●从Hive 0.13开始,WHERE子句支持下述类型的子查询∶
- 不相关子查询∶该子查询不引用父查询中的列,可以将查询结果视为IN和NOT IN语句的常量
- 相关子查询:子查询引用父查询中的列;

> Common Table Expressions ( CTE )CTE表达式
CTE介绍
- 公用表表达式(CTE) 是一个临时结果集∶该结果集是从WITH子句中指定的简单查询派生而来的
,紧接在SELECT或INSERT关键字之前。 - CTE仅在单个语句的执行范围内定义。
- CTE可以在 SELECT,INSERT,CREATE TABLE AS SELECT或CREATE VIEW AS SELECT语句中使用。





15.6 Hive SQL Join 连接操作
join语法的出现是用于根据两个或多个表中的列之间的关系,从这些表中共同组合查询数据。

1、Hive Join语法规则
- 在Hive中,当下版本3.1.2总共支持6种join语法。分别是∶
- inner join(内连接)
- left join(左连接)
- right join (右连接)
- full outer join(全外连接)
- left semi join(左半开连接)
- cross join(交叉连接,也叫做笛卡尔乘积)。
-
table_reference : 是join查询中使用的表名,也可以是子查询别名(查询结果当成表参与join )。
-
table_factor : 与table_reference相同,是联接查询中使用的表名,也可以是子查询别名。
-
join_condition : join查询关联的条件,如果在两个以上的表上需要连接,则使用AND关键字。

-
Hive中join语法从面世开始其实并不丰富,不像在RDBMS中那么灵活。
-
从Hive 0.13.0开始,支持隐式联接表示法(请参阅HIVE-5558 )。允许FROM子句连接以逗号分隔的表列表,而省略JOIN关键字。
-
从Hive 2.2.0开始,支持N子句中的复杂表达式,支持不相等连接(请参阅HIVE-15211和HIVE-15251)。在此之前,Hive不支持不是相等条件的联接条件。

> inner join内连接

- 内连接是最常见的一种连接,它也被称为普通连接。
- 其中inner可以省略:inner join == join
- 只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。

> left join左连接
left join中文叫做是左外连接(Left Outer Join)或者左连接,其中outer可以省略,left outer join是早期的写法。
left join的核心就在于left左。左指的是join关键字左边的表,简称左表。
通俗解释∶join时以左表的全部数据为准,右边与之关联;
左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。

> right join右连接
right join中文叫做是右外连接(Right Outer Jion)或者右连接,其中outer可以省略。right join的核心就在于Right右。右指的是join关键字右边的表,简称右表。
通俗解释: join时以右表的全部数据为准,左边与之关联﹔右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回。
- 很明显,right join和left join之间很相似,重点在于以哪边为准,也就是一个方向的问题。
> full outer join全外连接
- full outer join等价 full join ,中文叫做全外连接或者外连接。
- 包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行;
- 在功能上∶等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
> left semi join左半开连接
- 左半开连接(LEFT SEMI JOIN ) 会返回左边表的记录,前提是其记录对于右边的表满足ON语句中的判定条件。
- 从效果上来看有点像inner join之后只返回左表的结果。

> cross join交叉连接
- 交叉连接cross join,将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。对于大表来说,cross join慎用。
- 在SQL标准中定义的cross join就是无条件的inner join。返回两个表的笛卡尔积,无需指定关联键。
- 在HiveSQL语法中,cross join后面可以跟where子句进行过滤,或者on条件过滤。

2、Hive Join使用注意事项
-
a) 允许使用复杂的联接表达式,支持非等值连接

-
b)同一查询中可以连接2个以上的表

c)如果每个表在联接子句中使用相同的列,则Hive将多个表上的联接转换为单个MR作业

d)join时的最后一个表会通过reducer流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少reducer阶段缓存数据所需要的内存

e)在join的时候,可以通过语法STREAMTABLI提示指定要流式传输的表。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。

f)join在WHERE条件之前进行。
g)如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行( mapjoin ) 。

十六、Hive内置运算符

创建一个空表 dual
16.1 关系运算符
- is null \ is not null 空值判断

- like \ not A like B \ rlike
- _单个字符
- %任意数量字符

- rlike 等同于 regexp
判断正则
- regexp
判断字符串是否匹配正则表达式

16.2 算术运算符
- 算术运算符操作数必须是数值类型。分为一元运算符和二元运算符∶
一元运算符,只有一个操作数;二元运算符有两个操作数,运算符在两个操作数之间。

- 取整操作 div

- 取余操作 %

- 位与操作 &

4 & 8 = 0 ; 0100 & 1000 = 0000
6 & 4 = 4 ; 0100
- 位或操作 |

- 位异或操作 ^

16.3 逻辑运算符

与操作
![]()
或操作

非操作

在

不在

逻辑是否存在 EXISTS
- 逻辑是否存在:[NOT] EXISTS (subquery)
- 将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE或FALSE)来决定主查询的数据结果是否得以保留。

验证A.ID是否等于B.ID
16.3 字符串、复杂类型构造、复杂类型取值运算符
官方文档参考地址
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
字符串 || concat运算

-- 其他运算符
select 'a' || 'b';
复杂类型构造运算符
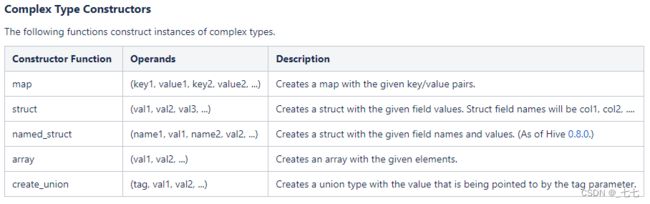
SELECT array(11,22,33);
-- [11||22||33]
复杂类型取值操作

十七、Hive Functions函数入门
概述
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率:
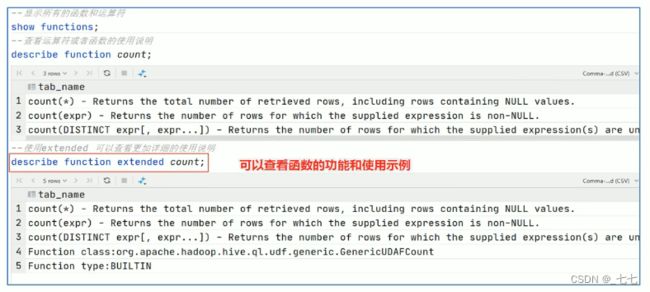
- 使用
show functions查看当下可用的所有函数; - 通过
describe function extended funcname来查看函数的使用方式。
分类标准
Hive的函数分为两大类︰内置函数(Built-in Functions)、用户定义函数UDF (User-Defined
Functions)
- 内置函数可分为︰数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
- 用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
用户定义函数UDF分类标准
根据函数输入输出的行数︰
- UDF ( User-Defined-Function )普通函数,一进一出;
- UDAF ( User-Defined Aggregation Function )聚合函数,多进一出;
- UDTF ( User-Defined Table-Generating Functions )表生成函数,一进多出;

UDF分类标准扩大化
- UDF分类标准本来针对的是用户自己编写开发实现的函数。
- UDF分类标准可以扩大到Hive的所有函数中︰包括内置函数和用户自定义函数。
因为不管是什么类型的函数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何问题。千万不要被UD ( User-Defined )这两个字母所迷惑,照成视野的狭隘。 - 比如Hive官方文档中,针对聚合函数的标准就是内置的UDAF类型。

内置函数
( 1/8 ) string Functions字符串函数



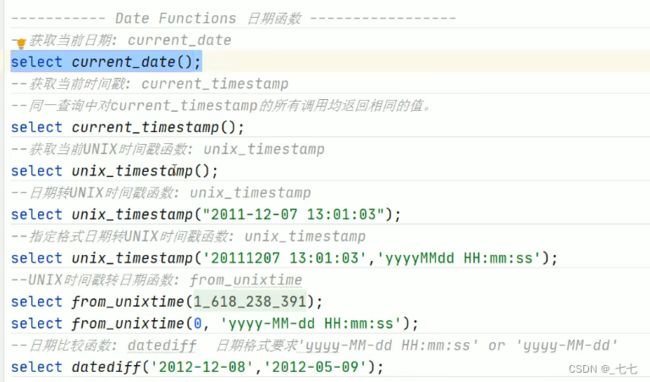
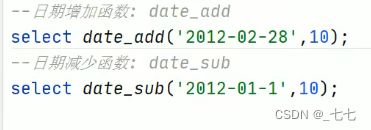
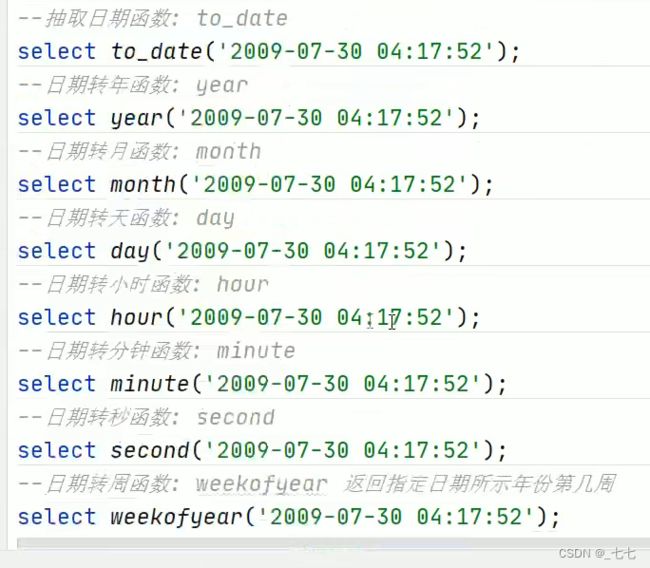
( 2/8 ) Date Functions日期函数

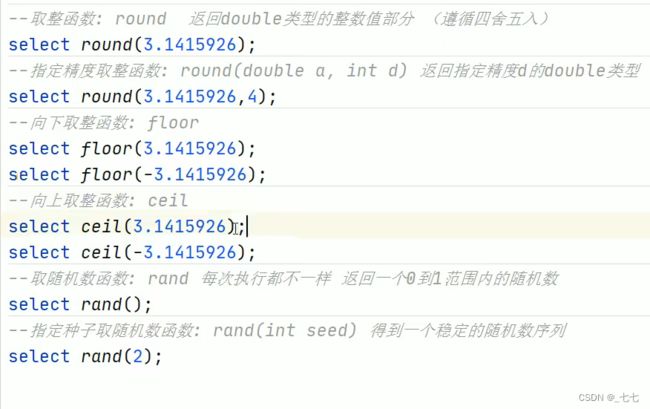
( 3/8 ) Mathematical Functions数学函数

( 4/8 ) collection Functions集合函数


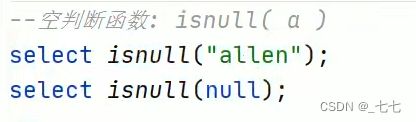
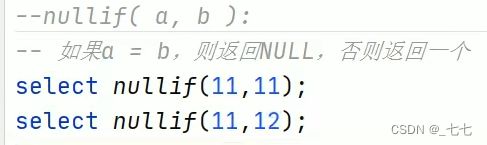
( 5/8 ) conditional Functions条件函数
主要用于条件判断、逻辑判断转换这样的场合






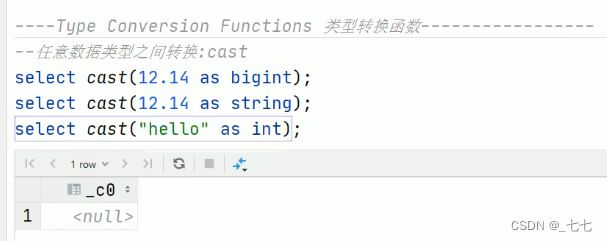
( 6/8 ) Type conversion Functions类型转换函数
主要用于显式的数据类型转换∶
( 7/8 ) Data Masking Functions数据脱敏函数
主要完成对数据脱敏转换功能,屏蔽原始数据,主要如下:




( 8/8 ) Misc. Functions其他杂项函数


