orc文件的读写及整合hive
还是先说下背景。
为啥想到学习orc文件的读写呢? 我们create table的时候stored as orc就好了呀,读写有什么作用呢?
1.使用datax hdfsreader的时候有时候hdfswriter的写速度过慢,针对的我之前的splitpk,可以一定程度减少这个耗时,但是他慢就是慢,就好像a干活很慢,你现在用10个a干活,比之前肯定快,但是还是慢。
2.了解orc文件的读写,可以有效的排查问题,例如,decimal字段精度不对,怎么调整,文件大小不是128M怎么做?
3.更好的吹牛b。
先说下注意事项hive写orc文件是有两个包的。
要注意,两者都可以写orc但是有些些的差别。
org.apache.hadoop
hadoop-client
2.7.7
org.apache.orc
orc-core
1.5.4
如果上面的不行引用 hive-exec.jar 试下。我引用的有点多分不清了。
以下代码 只用改下main方法的路径,可以直接跑的。
package com.chenchi.learning.fileformat.orc;
/**
*
* org.apache.hadoop
* hadoop-client
* 2.7.7
*
*
* org.apache.orc
* orc-core
* 1.5.4
*
* -----------------------------------
* ©著作权归作者所有:来自51CTO博客作者铁头乔的博客的原创作品,请联系作者获取转载授权,否则将追究法律责任
* ORC 文件层 API 读写 参考了这个的加以拓展
* https://blog.51cto.com/u_15352899/3746656
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.common.type.HiveDecimal;
import org.apache.hadoop.hive.ql.exec.vector.*;
import org.apache.hadoop.hive.ql.io.sarg.PredicateLeaf;
import org.apache.hadoop.hive.ql.io.sarg.SearchArgumentFactory;
import org.apache.hadoop.hive.serde2.io.HiveDecimalWritable;
import org.apache.orc.*;
import java.io.File;
import java.io.IOException;
import java.math.BigDecimal;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.UUID;
public class ReadAndWriteOrcTest {
public static void main(String[] args) throws IOException {
ReadAndWriteOrcTest writeOrc = new ReadAndWriteOrcTest();
writeOrc.writeOrc("D:\\install\\code\\learning\\bigdata_learining\\src\\main\\resources\\out\\my-file.orc");
writeOrc.readOrc("D:\\install\\code\\learning\\bigdata_learining\\src\\main\\resources\\out\\my-file.orc");
}
private void writeOrc(String path) throws IOException {
File file = new File(path);
if (file.exists()) file.delete();
Configuration conf = new Configuration();
TypeDescription schema = TypeDescription.createStruct()
.addField("long_value", TypeDescription.createLong())
.addField("double_value", TypeDescription.createDouble())
.addField("boolean_value", TypeDescription.createBoolean())
.addField("string_value", TypeDescription.createString())
.addField("decimal_value",TypeDescription.createDecimal().withScale(18))
.addField("date_value",TypeDescription.createTimestamp())
.addField("timestamp_value",TypeDescription.createTimestamp());
Writer writer = OrcFile.createWriter(new Path(path),
OrcFile.writerOptions(conf)
.setSchema(schema)
.stripeSize(67108864)
.bufferSize(64 * 1024)
.blockSize(128 * 1024 * 1024)
.rowIndexStride(10000)
.blockPadding(true)
.compress(CompressionKind.ZLIB));
//根据 列数和默认的1024 设置创建一个batch
VectorizedRowBatch batch = schema.createRowBatch();
LongColumnVector longVector = (LongColumnVector) batch.cols[0];
DoubleColumnVector doubleVector = (DoubleColumnVector) batch.cols[1];
LongColumnVector booleanVector = (LongColumnVector) batch.cols[2];
BytesColumnVector stringVector = (BytesColumnVector) batch.cols[3];
DecimalColumnVector decimalVector = (DecimalColumnVector) batch.cols[4];
TimestampColumnVector dateVector = (TimestampColumnVector) batch.cols[5];
TimestampColumnVector timestampVector = (TimestampColumnVector) batch.cols[6];
for (int r = 0; r < 10; ++r) {
int row = batch.size++;
longVector.vector[row] = r;
doubleVector.vector[row] = r;
booleanVector.vector[row] = r %2;
stringVector.setVal(row, UUID.randomUUID().toString().getBytes());
BigDecimal bigDecimal = new BigDecimal((double) r / 3).setScale(18,BigDecimal.ROUND_DOWN);
HiveDecimal hiveDecimal = HiveDecimal.create(bigDecimal).setScale(18);
decimalVector.set(row, hiveDecimal);
long time = new Date().getTime();
Timestamp timestamp = new Timestamp(time);
dateVector.set(row,timestamp);
timestampVector.set(row,timestamp);
if (batch.size == batch.getMaxSize()) {
writer.addRowBatch(batch);
batch.reset();
}
}
if (batch.size != 0) {
writer.addRowBatch(batch);
batch.reset();
}
writer.close();
}
private void readOrc(String path) throws IOException {
Configuration conf = new Configuration();
TypeDescription readSchema = TypeDescription.createStruct()
.addField("long_value", TypeDescription.createLong())
.addField("double_value", TypeDescription.createDouble())
.addField("boolean_value", TypeDescription.createBoolean())
.addField("string_value", TypeDescription.createString())
.addField("decimal_value",TypeDescription.createDecimal().withScale(18))
.addField("date_value",TypeDescription.createTimestamp())
.addField("timestamp_value",TypeDescription.createTimestamp()
);
Reader reader = OrcFile.createReader(new Path(path),
OrcFile.readerOptions(conf));
OrcFile.WriterVersion writerVersion = reader.getWriterVersion();
System.out.println("writerVersion="+writerVersion);
Reader.Options readerOptions = new Reader.Options()
.searchArgument(
SearchArgumentFactory
.newBuilder()
.between("long_value", PredicateLeaf.Type.LONG, 0L,1024L)
.build(),
new String[]{"long_value"}
);
RecordReader rows = reader.rows(readerOptions.schema(readSchema));
VectorizedRowBatch batch = readSchema.createRowBatch();
int count=0;
while (rows.nextBatch(batch)) {
LongColumnVector longVector = (LongColumnVector) batch.cols[0];
DoubleColumnVector doubleVector = (DoubleColumnVector) batch.cols[1];
LongColumnVector booleanVector = (LongColumnVector) batch.cols[2];
BytesColumnVector stringVector = (BytesColumnVector) batch.cols[3];
DecimalColumnVector decimalVector = (DecimalColumnVector) batch.cols[4];
TimestampColumnVector dateVector = (TimestampColumnVector) batch.cols[5];
TimestampColumnVector timestampVector = (TimestampColumnVector) batch.cols[6];
count++;
if (count==1){
for(int r=0; r < batch.size; r++) {
long longValue = longVector.vector[r];
double doubleValue = doubleVector.vector[r];
boolean boolValue = booleanVector.vector[r] != 0;
String stringValue = stringVector.toString(r);
HiveDecimalWritable hiveDecimalWritable = decimalVector.vector[r];
long time1 = dateVector.getTime(r);
Date date = new Date(time1);
String format = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(date);
long time = timestampVector.time[r];
int nano = timestampVector.nanos[r];
Timestamp timestamp = new Timestamp(time);
timestamp.setNanos(nano);
System.out.println(longValue + ", " + doubleValue + ", " + boolValue + ", " + stringValue+", "+hiveDecimalWritable.getHiveDecimal().toFormatString(18)+", "+format+", "+timestamp);
}
}
}
System.out.println("count="+count);
rows.close();
}
}
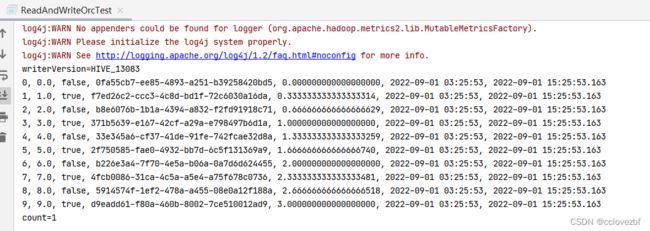
打印结果 可以看到decimal保留了18位小数,date日期ok, timestamp的毫秒也ok
生成的文件
————————————————————————————————————————
整合hive
create table test.orc_read(
long_value bigint ,
double_value double ,
boolean_value boolean,
string_value string,
decimal_value decimal(38,18),
date_value date,
timestamp_value timestamp
)
stored as orc;

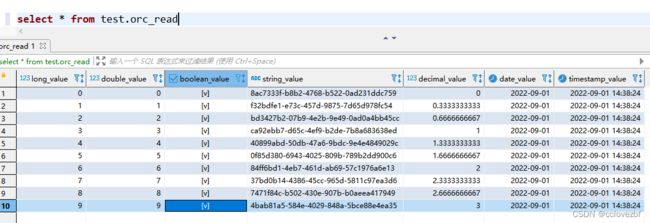
把写好的文件放到表的指定目录下。
然后是见证奇迹的时候了,直接select * 可以看到orc文件内容。一切ok ---其实不ok 有问题。
紧接着我们可以改造datax的hdfsreader。。
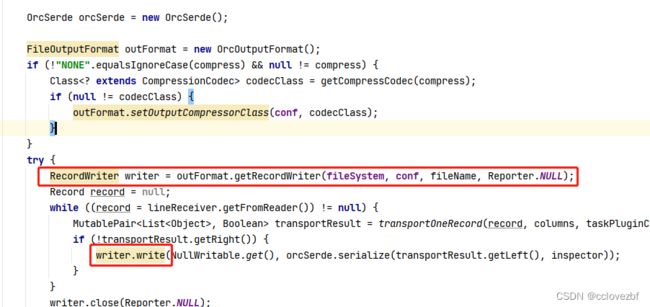
其实就是把这一段换成我们的writer就行,而且我们的write里有个batch是可以控制写出文件的速度的。