机器学习实践入门(一):神经网络入门
本文参考自深蓝学院课程,所记录笔记,仅供自学记录使用
这里写目录标题
- 逻辑回归
-
- 二分类问题
-
- 思路一:构建超平面分类
- 思路二:估计样本的分布
- 成本函数的优化
- 逻辑回归算法流程
- 感知机
-
-
- 感知机成本函数
-
- 感知机算法流程
-
- 神经网络
-
- 神经元的解释
- 多层神经网络
-
- 前向传播
-
- 神经元前向传播的向量形式
- 反向传播
-
- 梯度下降
-
- 权重求导
-
- 输出层权重求导
- 推广:
- 中间层权重求导
- BP 算法核心公式
- 偏置求导
-
- 输出层偏执求导:
- 对隐藏层偏置求偏导数
- 反向传播整理
- 总结BP算法
- 激活函数
-
- 梯度消失
- Z型更新
逻辑回归
二分类问题
对于一个线性可分的数据集: D = { ( x ( 1 ) , y ( 1 ) ) , … … , ( x ( N ) , y ( N ) ) } D=\{( \bold{x}^{(1)},y^{(1)}),……,( \bold{x}^{(N)},y^{(N)})\} D={(x(1),y(1)),……,(x(N),y(N))},其中特征向量 x ( i ) ∈ R n \bold{x}^{(i)}\in R^n x(i)∈Rn,标签 y ( i ) ∈ { 0 , 1 } y^{(i)}\in \{0,1\} y(i)∈{0,1}
思路一:构建超平面分类
问题就转换为,找到一个超平面 w T x + b = 0 \bold{w}^T\bold{x}+b=0 wTx+b=0将正负样本分开。
若特征向量是二维的,可以表示成下面
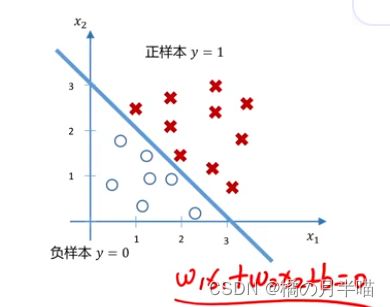
Q:如何将分类平面与估计的(分类值)相对应?
A: 符号函数。
令 y ^ ( i ) = [ s i g n ( w T x ( i ) + b ) + 1 ] / 2 \hat{y}^{(i)}=[sign(\bold{w}^T\bold{x}^{(i)}+b)+1]/2 y^(i)=[sign(wTx(i)+b)+1]/2即可,这样 y ^ ( i ) > 0 时 \hat{y}^{(i)}>0时 y^(i)>0时被分类为正样本,反之为负样本。
Q:当后续优化模型时,根据什么来优化?即代价函数
A: 令 J = ∑ i = 1 N ∣ y ( i ) − y ^ ( i ) ∣ \bold{J}=\sum^{N}_{i=1}|y^{(i)}-\hat{y}^{(i)}| J=∑i=1N∣y(i)−y^(i)∣为(待定)代价函数 .
所谓代价函数不如说是误差函数,误差越大,值应该也越大。
Q:上述代价函数并不好,问题在哪里?
A:绝对值增大了优化难度,要分类讨论,而且维数越多越麻烦。
下一个思路: 让误分类的样本点到超平面的距离之和越小越好。
思路二:估计样本的分布
问题转化为求样本分布概率函数,哪一个可能性大,分到哪一方。
如果还是根据 z = w T x ( i ) + b z=\bold{w}^T\bold{x}^{(i)}+b z=wTx(i)+b 来分类,如果z>0,正样本可能性大,反之,可能性小。但是有概率论知道,可能性应该是概率值,在[0,1]之间, 但是上式是一个线性函数,取值为正无穷到负无穷之间,如何将其变换到[0,1]之间呢?
Q:如何让将 式子映射到[0,1]区间并且不改变单调性?
A:sigmoid函数
s i g m o i d ( z ) = 1 1 + e − z = σ ( z ) sigmoid(z)=\frac{1}{1+e^{-z}}=\sigma(z) sigmoid(z)=1+e−z1=σ(z)
那么令: p ( y = 1 ∣ x ) = s i g m o i d ( w T x ( i ) + b ) = σ ( z ) p(y=1|x)=sigmoid(\bold{w}^T\bold{x}^{(i)}+b)=\sigma(z) p(y=1∣x)=sigmoid(wTx(i)+b)=σ(z)
那么, p ( y = 0 ∣ x ) = 1 − s i g m o i d ( w T x ( i ) + b ) = 1 − σ ( z ) p(y=0|x)=1-sigmoid(\bold{w}^T\bold{x}^{(i)}+b)=1-\sigma(z) p(y=0∣x)=1−sigmoid(wTx(i)+b)=1−σ(z)
采取一种更加统一的写法,并将 σ ( z ) \sigma(z) σ(z) 简写为 σ \sigma σ:
p ( y ∣ x ) = σ y ( 1 − σ ) ( 1 − y ) p(y|x)=\sigma^y(1-\sigma)^{(1-y)} p(y∣x)=σy(1−σ)(1−y)
(可以试着带入一下 y=1,y=0 的情况)
Q:这下就可以用这个概率分布来判别了,但是如何优化?(损失函数)
A: 构造损失函数如下:
L ( w , b ) = − log ( p ( y ∣ x ) ) = − y log σ − ( 1 − y ) log ( 1 − σ ) \begin{aligned} L(\bold w,b) &=-\log( p(y|x))\\ & = - y \log \sigma -(1-y)\log (1-\sigma)\\ \end{aligned} L(w,b)=−log(p(y∣x))=−ylogσ−(1−y)log(1−σ)
当真正标签y=1时,最小化损失函数L,相当属于最大化 log σ \log \sigma logσ,也即最大化 σ \sigma σ,也就是最大化 p ( y = 1 ∣ x ) p(y=1|x) p(y=1∣x),这也正是我们想优化的方向,反之,亦然。
对于整个数据集D,我们考虑整体的成本函数,即为:
J ( w , b ) = 1 N ∑ i = 1 N L ( w , b ) = − 1 N ∑ i = 1 N y log σ + ( 1 − y ) log ( 1 − σ ) J(\bold w,b)=\frac{1}{N}\sum^N_{i=1}L(\bold w,b) =-\frac{1}{N}\sum^N_{i=1}{ y \log \sigma +(1-y)\log (1-\sigma)} J(w,b)=N1i=1∑NL(w,b)=−N1i=1∑Nylogσ+(1−y)log(1−σ)
Q:为什么不直接计算平方和作为成本函数?
A:若直接用 J ( w , b ) = 1 N ∑ i = 1 N ( y ( i ) − σ ) 2 J(\bold w,b)=\frac{1}{N}\sum^N_{i=1}{(y^{(i)}-\sigma)^2} J(w,b)=N1∑i=1N(y(i)−σ)2作为成本函数,发现他是一个非凸函数,有很多局部最小值。
而用上述log形式的,是一个凸函数

成本函数的优化
梯度下降:通过一阶导数来寻找下降方向, 迭代求解
∂ J ( w , b ) ∂ w = 1 N ∑ i = 1 N ∂ L ( w , b ) ∂ w = 1 N ∑ i = 1 N ( σ − y ( i ) ) x ( i ) (求导) w k + 1 = w k − α ∂ J ( w , b ) ∂ w (迭代) ∂ J ( w , b ) ∂ b = 1 N ∑ i = 1 N ∂ L ( w , b ) ∂ b = 1 N ∑ i = 1 N ( σ − y ( i ) ) (求导) b k + 1 = b k − α ∂ J ( w , b ) ∂ b (迭代) \begin{aligned} &\frac{\partial \mathcal{J}(\boldsymbol{w}, b)}{\partial \boldsymbol{w}}=\frac{1}{N} \sum_{i=1}^N \frac{\partial \mathcal{L}(\boldsymbol{w}, b)}{\partial \boldsymbol{w}}=\frac{1}{N} \sum_{i=1}^N\left(\sigma-y^{(i)}\right) x^{(i)} (求导)\\ &\boldsymbol{w}^{k+1}=\boldsymbol{w}^k-\alpha \frac{\partial \mathcal{J}(\boldsymbol{w}, b)}{\partial \boldsymbol{w}} (迭代)\\ &\frac{\partial \mathcal{J}(\boldsymbol{w}, b)}{\partial b}=\frac{1}{N} \sum_{i=1}^N \frac{\partial \mathcal{L}(\boldsymbol{w}, b)}{\partial b}=\frac{1}{N} \sum_{i=1}^N\left(\sigma-y^{(i)}\right)(求导) \\ &b^{k+1}=b^k-\alpha \frac{\partial \mathcal{J}(w, b)}{\partial b}(迭代) \end{aligned} ∂w∂J(w,b)=N1i=1∑N∂w∂L(w,b)=N1i=1∑N(σ−y(i))x(i)(求导)wk+1=wk−α∂w∂J(w,b)(迭代)∂b∂J(w,b)=N1i=1∑N∂b∂L(w,b)=N1i=1∑N(σ−y(i))(求导)bk+1=bk−α∂b∂J(w,b)(迭代)
k是迭代次数,α是迭代步长

逻辑回归算法流程
整理一下论及逻辑回归算法的流程步骤:
-
for i=1:N
- 计算 z ( i ) = w T x ( i ) + b z^{(i)}=\bold{w}^T\bold{x}^{(i)}+b z(i)=wTx(i)+b
- 计算 σ = s i g m o i d ( z ( i ) ) \sigma=sigmoid(z^{(i)}) σ=sigmoid(z(i))
- 计算 d w d\bold{w} dw+= ∂ L ∂ w \frac{\partial L}{\partial {\bold{w}}} ∂w∂L, d b db db+= ∂ L ∂ b \frac{\partial L}{\partial {b}} ∂b∂L
-
end
-
分别 计算 损失函数 对 w \bold{w} w,对 b b b的偏导 d w d\bold{w} dw+= 1 N d w \frac{1}{N}d\bold{w} N1dw, d b = d b= db=+= 1 N d b \frac{1}{N}db N1db
-
w \bold{w} w-= − σ d w -\sigma d\bold{w} −σdw; b b b-= − σ d b -\sigma db −σdb ,至此得到模型参数 w \bold{w} w, b b b
-
检验:将待检测数据带入方程 p ( y = 1 ∣ x ) = s i g m o i d ( w T x ( i ) + b ) = σ ( z ) p(y=1|x)=sigmoid(\bold{w}^T\bold{x}^{(i)}+b)=\sigma(z) p(y=1∣x)=sigmoid(wTx(i)+b)=σ(z)中检验,当大于0.5是正样本,否则为负。
感知机
感知机成本函数
首先,给定一个数据集,和上面二分类数据集差不多,只不过标签值取值为{-1,1} (原来是 0,1).
思路一,寻找决策平面 (同上)
使得误分类样本点到超平面距离只和越小越好
1 ∥ w ∥ ∣ w T x ( i ) + b ∣ (回顾高中点到面的距离公式) \frac{1}{\|w\|}\left|\boldsymbol{w}^T \boldsymbol{x}^{(i)}+b\right| (回顾高中点到面的距离公式) ∥w∥1∣ ∣wTx(i)+b∣ ∣(回顾高中点到面的距离公式)
同样由于绝对值符号,其优化比较困难,
可令, − y ( i ) ( x ( i ) + b ) - y^{(i)}(\boldsymbol{x}^{(i)}+b) −y(i)(x(i)+b)作为因子,这样无论是正样本还是负样本,只要是 判错样本 ,其值都大于零
那么成本函数变为:
J ( w , b ) = − 1 ∥ w ∥ ∑ x ( i ) ∈ M y ( i ) ( w T x ( i ) + b ) \mathcal{J}(\boldsymbol{w}, b)=-\frac{1}{\|\boldsymbol{w}\|} \sum_{\boldsymbol{x}^{(i)} \in M} y^{(i)}\left(\boldsymbol{w}^T \boldsymbol{x}^{(i)}+b\right) J(w,b)=−∥w∥1x(i)∈M∑y(i)(wTx(i)+b)
Q:成本函数中忽略 1/||||,对最终的结果是否会有影响呢?
A:没有影响,因为感知机的目标是求一个能够将训练集正样本和负样本完全分开的超平面(第17页),也就是说,最终目标是让所有样本被正确分类,此时总距离为0,而 1/||||为正,其分子为0即可。
J ( w , b ) = − ∑ x ( i ) ∈ M y ( i ) ( w T x ( i ) + b ) \mathcal{J}(\boldsymbol{w}, b)= -\sum_{\boldsymbol{x}^{(i)} \in M} y^{(i)}\left(\boldsymbol{w}^T \boldsymbol{x}^{(i)}+b\right) J(w,b)=−x(i)∈M∑y(i)(wTx(i)+b)
感知机学习算法是误分类驱动的,采用随机梯度下降算法:
∂ J ( w , b ) ∂ w = − ∑ x ( i ) ∈ M y ( i ) x i w ← w + η y ( i ) x ( i ) ∂ J ( w , b ) ∂ b = − ∑ x ( i ) ∈ M y ( i ) b ← b + η y ( i ) \begin{array}{ll} \frac{\partial \mathcal{J}(\boldsymbol{w}, b)}{\partial \boldsymbol{w}}=-\sum_{\boldsymbol{x}^{(i)} \in M} y^{(i)} \boldsymbol{x}_i & \boldsymbol{w} \leftarrow \boldsymbol{w}+\eta y^{(i)} \boldsymbol{x}^{(i)} \\ \frac{\partial \mathcal{J}(\boldsymbol{w}, b)}{\partial b}=-\sum_{\boldsymbol{x}^{(i)} \in M} y^{(i)} & b \leftarrow b+\eta y^{(i)} \end{array} ∂w∂J(w,b)=−∑x(i)∈My(i)xi∂b∂J(w,b)=−∑x(i)∈My(i)w←w+ηy(i)x(i)b←b+ηy(i)
感知机算法流程
输入:训练数据集合D ,学习率 η
输出:感知机模型参数, ,以及感知机模型 = sign( + )
- 选取, 初值;
- 在训练集中随机选取数据 (), () ;
- 如果()(() + ) ≤ 0,更新参数 ← + ()
() , ← + (); - 跳转到第2步,继续学习,直到训练集中没有误分类的点。
对于线性不可分的情形,感知机不再适用
神经网络
对于线性不可分的问题,感知机不再适用,即不是一个超平面就能完全分类的问题,也叫非线性问题。
Q:线性分类器一定无法解决非线性问题吗?
A:非也,对于非线性分类问题,可以通过增加特征的方式来完成非线性的表达。
线性分类: ( x ) = ( 0 + 1 1 + 2 2 ) (\bold x)= (_0 + _1_1 +_2 _2) f(x)=g(w0+w1x1+w2x2)
非线性分类: ( x ) = ( 0 + 1 1 + 2 2 + 3 1 2 + 4 1 2 2 + 5 1 2 2 + ⋯ ) (\bold x) = (_0 + _1_1 +_2 _2 + _3_1_2 +_4 _1^2_2 +_5 _1_2^2 + ⋯ ) f(x)=g(w0+w1x1+w2x2+w3x1x2+w4x12x2+w5x1x22+⋯)
如SVM正是应用了这样的思想
缺点:优化和计算难度极大增加。不知道数据应该是几维时,非常难搞。
为了解决上面非先行问题,采用神经网络的方式
神经元的解释
Q:神经网络是由一层一层神经元构建的,那么每一层究竟在干什么,或者是完成什么事情呢?
A:每层神经元理解: = ( + ),其中是输入向量,是输出向量,是偏移向量,是权重矩阵。
每一层就相当于把输入经过简单的变换得到

y = ( y 1 y 2 y 3 ) x = ( x 1 x 2 x 3 x 4 ) W = ( w 11 w 12 w 13 w 14 w 21 w 22 w 23 w 24 w 31 w 32 w 33 w 34 ) \begin{gathered} \boldsymbol{y}=\left(\begin{array}{l} y_1 \\ y_2 \\ y_3 \end{array}\right) \quad \boldsymbol{x}=\left(\begin{array}{l} x_1 \\ x_2 \\ x_3 \\ x_4 \end{array}\right) \\ \boldsymbol{W}=\left(\begin{array}{llll} w_{11} & w_{12} & w_{13} & w_{14} \\ w_{21} & w_{22} & w_{23} & w_{24} \\ w_{31} & w_{32} & w_{33} & w_{34} \end{array}\right) \end{gathered} y=⎝ ⎛y1y2y3⎠ ⎞x=⎝ ⎛x1x2x3x4⎠ ⎞W=⎝ ⎛w11w21w31w12w22w32w13w23w33w14w24w34⎠ ⎞
神经元数学理解:通过如下5种变换,对输入空间(输入向量的集合)进行操作,完成输入空间->输出空间的变换
- 降维/升维 (如非方阵时)
- 放大/缩小(如数乘单位阵)
- 旋转 (如正交阵)
- 平移(偏移b向量)
- 弯曲(激励函数f实现)
多层神经网络
AlexNet 8层
ResNet >1000
Q:到底应该如何设置隐藏层层数?
A:涉及更深问题,可以看网络结构搜索 (NAS),根据不同任务搜索网络结构?
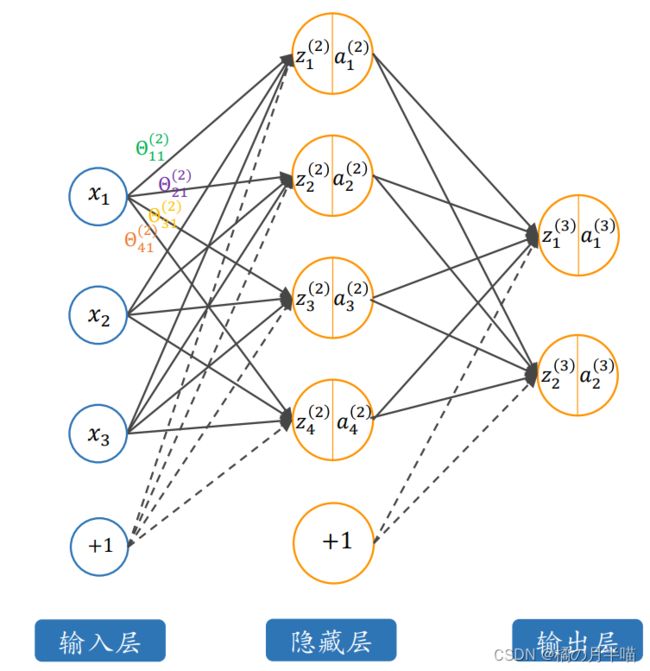
输入层是一个由三个特征组成的特征向量
x = ( x 1 x 2 x 3 ) \boldsymbol{x}=\left(\begin{array}{l} x_1 \\ x_2 \\ x_3 \end{array}\right) x=⎝ ⎛x1x2x3⎠ ⎞
输出层是一个由两个特征作为输出的特征向量
y = ( y 1 y 2 ) \boldsymbol{y}=\left(\begin{array}{l} y_1 \\ y_2 \end{array}\right) y=(y1y2)
前向传播
在多层神经元进行运算时,两个重要的算法步骤就是前向传播和误差的反向传播,反向传播后续章节再讲,下面先介绍一下前向传播。
前向传播简单来说和之前的逻辑回归部分类似
即都是 采用 y = f ( w T x + b ) y=f(\bold{w^Tx}+b) y=f(wTx+b) 的方式进行运算
不同的是
- 逻辑回归中 y y y是一个数,神经网络中," y \bold{y} y"是向量(只是指代,不知具体变量表示,下同)
- 逻辑回归中 w \bold w w是一个向量 ,神经网络中, w \bold{w} w是矩阵,,
- 逻辑回归中 b b b是一个向量 ,神经网络中, b \bold{b} b是矩阵,
- 逻辑回归可以看成是只有一层输入层和一个输出层(且输出层只有一个神经元)的神经网络
定义符号:
n l n_l nl 第 l l l 层的神经元个数,如图 n 1 = 3 n_1=3 n1=3, n 2 = 4 n_2=4 n2=4, n 3 = 2 n_3=2 n3=2\Theta_{i j}^{(l)}$ 从 l − 1 l-1 l−1 层第 j j j 个到 l l l 层第 i i i 个神经元连接的权重
Θ ( l ) \boldsymbol{\Theta}^{(l)} Θ(l) 从 l − 1 l-1 l−1 层到 l l l 层的权重参数组
b i ( l ) b_i^{(l)} bi(l) 从 l − 1 l-1 l−1 层到 l l l 层第 i i i 个神经元连接的偏置
b ( l ) \boldsymbol{b}^{(l)} b(l) 从 l − 1 l-1 l−1 层到 l l l 层的偏置参数组
f ( ⋅ ) f(\cdot) f(⋅) 神经元的激活函数
z i ( l ) z_i^{(l)} zi(l) 第 l l l 层的第 i i i 个神经元的加权和
a i ( l ) a_i^{(l)} ai(l) 第 l l l 层的第 i i i 个神经元的输出 (经过激励函数)
下面具体展开了神经网络第二层所有神经元输出的展开计算形式
z 1 ( 2 ) = Θ 11 ( 2 ) x 1 + Θ 12 ( 2 ) x 2 + Θ 13 ( 2 ) x 3 + b 1 ( 2 ) a 1 ( 2 ) = f ( z 1 ( 2 ) ) = f ( Θ 11 ( 2 ) x 1 + Θ 12 ( 2 ) x 2 + Θ 13 ( 2 ) x 3 + b 1 ( 2 ) ) z 2 ( 2 ) = Θ 21 ( 2 ) x 1 + Θ 22 ( 2 ) x 2 + Θ 23 ( 2 ) x 3 + b 2 ( 2 ) a 2 ( 2 ) = f ( z 2 ( 2 ) ) = f ( Θ 21 ( 2 ) x 1 + Θ 22 ( 2 ) x 2 + Θ 23 ( 2 ) x 3 + b 2 ( 2 ) ) z 3 ( 2 ) = Θ 31 ( 2 ) x 1 + Θ 32 ( 2 ) x 2 + Θ 33 ( 2 ) x 3 + b 3 ( 2 ) a 3 ( 2 ) = f ( z 3 ( 2 ) ) = f ( Θ 31 ( 2 ) x 1 + Θ 32 ( 2 ) x 2 + Θ 33 ( 2 ) x 3 + b 3 ( 2 ) ) z 4 ( 2 ) = Θ 41 ( 2 ) x 1 + Θ 42 ( 2 ) x 2 + Θ 43 ( 2 ) x 3 + b 4 ( 2 ) a 4 ( 2 ) = f ( z 4 ( 2 ) ) = f ( Θ 41 ( 2 ) x 1 + Θ 42 ( 2 ) x 2 + Θ 43 ( 2 ) x 3 + b 4 ( 2 ) ) \begin{aligned} &z_1^{(2)}=\Theta_{11}^{(2)} x_1+\Theta_{12}^{(2)} x_2+\Theta_{13}^{(2)} x_3+b_1^{(2)} \\ &a_1^{(2)}=f\left(z_1^{(2)}\right)=f\left(\Theta_{11}^{(2)} x_1+\Theta_{12}^{(2)} x_2+\Theta_{13}^{(2)} x_3+b_1^{(2)}\right) \\ &z_2^{(2)}=\Theta_{21}^{(2)} x_1+\Theta_{22}^{(2)} x_2+\Theta_{23}^{(2)} x_3+b_2^{(2)} \\ &a_2^{(2)}=f\left(z_2^{(2)}\right)=f\left(\Theta_{21}^{(2)} x_1+\Theta_{22}^{(2)} x_2+\Theta_{23}^{(2)} x_3+b_2^{(2)}\right) \\ &z_3^{(2)}=\Theta_{31}^{(2)} x_1+\Theta_{32}^{(2)} x_2+\Theta_{33}^{(2)} x_3+b_3^{(2)} \\ &a_3^{(2)}=f\left(z_3^{(2)}\right)=f\left(\Theta_{31}^{(2)} x_1+\Theta_{32}^{(2)} x_2+\Theta_{33}^{(2)} x_3+b_3^{(2)}\right) \\ &z_4^{(2)}=\Theta_{41}^{(2)} x_1+\Theta_{42}^{(2)} x_2+\Theta_{43}^{(2)} x_3+b_4^{(2)} \\ &a_4^{(2)}=f\left(z_4^{(2)}\right)=f\left(\Theta_{41}^{(2)} x_1+\Theta_{42}^{(2)} x_2+\Theta_{43}^{(2)} x_3+b_4^{(2)}\right) \end{aligned} z1(2)=Θ11(2)x1+Θ12(2)x2+Θ13(2)x3+b1(2)a1(2)=f(z1(2))=f(Θ11(2)x1+Θ12(2)x2+Θ13(2)x3+b1(2))z2(2)=Θ21(2)x1+Θ22(2)x2+Θ23(2)x3+b2(2)a2(2)=f(z2(2))=f(Θ21(2)x1+Θ22(2)x2+Θ23(2)x3+b2(2))z3(2)=Θ31(2)x1+Θ32(2)x2+Θ33(2)x3+b3(2)a3(2)=f(z3(2))=f(Θ31(2)x1+Θ32(2)x2+Θ33(2)x3+b3(2))z4(2)=Θ41(2)x1+Θ42(2)x2+Θ43(2)x3+b4(2)a4(2)=f(z4(2))=f(Θ41(2)x1+Θ42(2)x2+Θ43(2)x3+b4(2))
神经元前向传播的向量形式
为了方便表达,一般会将上式写为向量形式,
z ( l ) 第 l 层神经元的加权和 R n l a ( l ) 第 l 层神经元输出 (经过激励函数) R n l θ ( l ) 从 l − 1 层到 l 层的权重参数组 R n l × n l − 1 b ( l ) 从 l − 1 层到 l 层的偏置参数组 R n l \begin{array}{llc}\boldsymbol{z}^{(l)} & \text { 第 } l \text { 层神经元的加权和 } & \mathbb{R}^{n_l} \\ \boldsymbol{a}^{(l)} & \text { 第 } l \text { 层神经元输出 (经过激励函数) } & \mathbb{R}^{n_l} \\ \boldsymbol{\theta}^{(l)} & \text { 从 } l-1 \text { 层到 } l \text { 层的权重参数组 } & \mathbb{R}^{n_l \times n_{l-1}} \\ \boldsymbol{b}^{(l)} & \text { 从 } l-1 \text { 层到 } l \text { 层的偏置参数组 } & \mathbb{R}^{n_l}\end{array} z(l)a(l)θ(l)b(l) 第 l 层神经元的加权和 第 l 层神经元输出 (经过激励函数) 从 l−1 层到 l 层的权重参数组 从 l−1 层到 l 层的偏置参数组 RnlRnlRnl×nl−1Rnl
总结: 第 l ( 2 ≤ l ≤ L ) l(2 \leq l \leq L) l(2≤l≤L) 层神经元的状态及激活值 的向量表示形式为
z ( l ) = Θ ( l ) a ( l − 1 ) + b ( l ) a ( l ) = f ( z ( l ) ) a ( 1 ) = x \begin{aligned} \boldsymbol{z}^{(l)}& =\boldsymbol{\Theta}^{(l)} \boldsymbol{a}^{(l-1)}+\boldsymbol{b}^{(l)}\\ \boldsymbol{a}^{(l)}& =f(\boldsymbol{z}^{(l)})\\ \boldsymbol{a}^{(1)}& =\boldsymbol{x} \end{aligned} z(l)a(l)a(1)=Θ(l)a(l−1)+b(l)=f(z(l))=x
z 1 ( 2 ) = Θ 11 ( 2 ) x 1 + Θ 12 ( 2 ) x 2 + Θ 13 ( 2 ) x 3 + b 1 ( 2 ) z 2 ( 2 ) = Θ 21 ( 2 ) x 1 + Θ 22 ( 2 ) x 2 + Θ 23 ( 2 ) x 3 + b 2 ( 2 ) z 3 ( 2 ) = Θ 31 ( 2 ) x 1 + Θ 32 ( 2 ) x 2 + Θ 33 ( 2 ) x 3 + b 3 ( 2 ) z 4 ( 2 ) = Θ 41 ( 2 ) x 1 + Θ 42 ( 2 ) x 2 + Θ 43 ( 2 ) x 3 + b 4 ( 2 ) \begin{aligned} &z_1^{(2)}=\Theta_{11}^{(2)} x_1+\Theta_{12}^{(2)} x_2+\Theta_{13}^{(2)} x_3+b_1^{(2)} \\ &z_2^{(2)}=\Theta_{21}^{(2)} x_1+\Theta_{22}^{(2)} x_2+\Theta_{23}^{(2)} x_3+b_2^{(2)} \\ &z_3^{(2)}=\Theta_{31}^{(2)} x_1+\Theta_{32}^{(2)} x_2+\Theta_{33}^{(2)} x_3+b_3^{(2)} \\ &z_4^{(2)}=\Theta_{41}^{(2)} x_1+\Theta_{42}^{(2)} x_2+\Theta_{43}^{(2)} x_3+b_4^{(2)} \end{aligned} z1(2)=Θ11(2)x1+Θ12(2)x2+Θ13(2)x3+b1(2)z2(2)=Θ21(2)x1+Θ22(2)x2+Θ23(2)x3+b2(2)z3(2)=Θ31(2)x1+Θ32(2)x2+Θ33(2)x3+b3(2)z4(2)=Θ41(2)x1+Θ42(2)x2+Θ43(2)x3+b4(2)
反向传播
前向传播中,我们是假设各种参数已知,实际情况中,需要根据训练误差调整参数。调整的策略本质上依旧是梯度下降算法。
数据集:
{ ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ⋯ , ( x ( i ) , y ( i ) ) , ⋯ , ( x ( N ) , y ( N ) ) } \left\{\left(\boldsymbol{x}^{(1)}, \boldsymbol{y}^{(1)}\right),\left(\boldsymbol{x}^{(2)}, \boldsymbol{y}^{(2)}\right), \cdots,\left(\boldsymbol{x}^{(i)}, \boldsymbol{y}^{(i)}\right), \cdots,\left(\boldsymbol{x}^{(N)}, \boldsymbol{y}^{(N)}\right)\right\} {(x(1),y(1)),(x(2),y(2)),⋯,(x(i),y(i)),⋯,(x(N),y(N))}
第 i i i 个训练样本的输入: x ( i ) = ( x 1 ( i ) , ⋯ , x n 1 ( i ) ) T \boldsymbol{x}^{(i)}=\left(x_1^{(i)}, \cdots, x_{n_1}^{(i)}\right)^T x(i)=(x1(i),⋯,xn1(i))T (输入神经元的个数 n 1 n_1 n1)
第 i i i 个训练样本的输出: y ( i ) = ( y 1 ( i ) , ⋯ , y n L ( i ) ) T \boldsymbol{y}^{(i)}=\left(y_1^{(i)}, \cdots, y_{n_L}^{(i)}\right)^T y(i)=(y1(i),⋯,ynL(i))T(输入神经元的个数 n L n_L nL,一般几分类分体其输出神经元个数就是几)
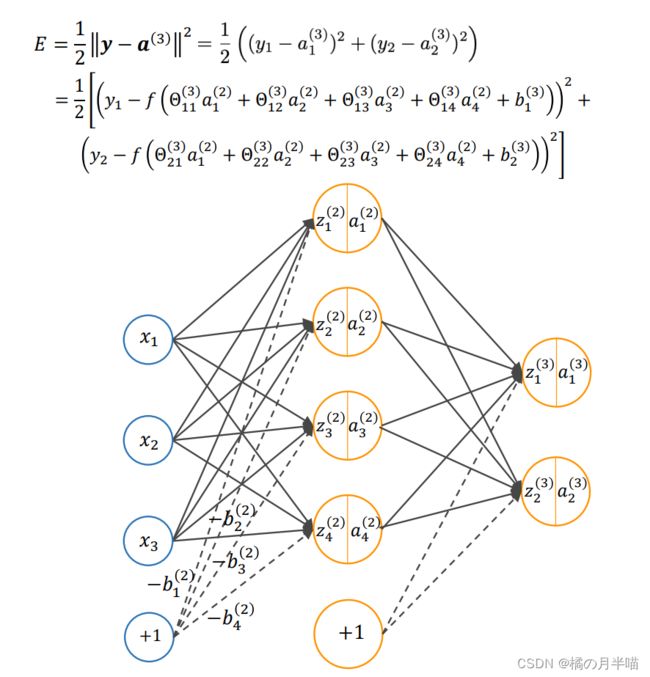
对于第 i i i 个训练数据来说, 其代价函数为:
E = 1 2 ∥ y − a ( L ) ∥ 2 = 1 2 ∑ k = 1 n L ( y k − a k ( L ) ) 2 E=\frac{1}{2}\left\|\boldsymbol{y}-\boldsymbol{a}^{(L)}\right\|^2=\frac{1}{2} \sum_{k=1}^{n_L}\left(y_k-a_k^{(L)}\right)^2 E=21∥ ∥y−a(L)∥ ∥2=21k=1∑nL(yk−ak(L))2
对于所有训练数据, 其平均代价函数为:
E total = 1 N ∑ i = 1 N E E_{\text {total }}=\frac{1}{N} \sum_{i=1}^N E Etotal =N1i=1∑NE
梯度下降
权重求导
梯度下降法(又称为“批量梯度下降法”), Θ ( l ) \boldsymbol{\Theta}^{(l)} Θ(l) 与 b ( l ) \boldsymbol{b}^{(l)} b(l) 的参数更新方式为:
Θ ( l ) = Θ ( l ) − μ ∂ E total ∂ Θ ( l ) = Θ ( l ) − μ N ∑ i = 1 N ∂ E ∂ Θ ( l ) \begin{aligned} \boldsymbol{\Theta}^{(l)} &=\boldsymbol{\Theta}^{(l)}-\mu \frac{\partial E_{\text {total }}}{\partial \boldsymbol{\Theta}^{(l)}} \\ &=\boldsymbol{\Theta}^{(l)}-\frac{\mu}{N} \sum_{i=1}^N \frac{\partial E}{\partial \boldsymbol{\Theta}^{(l)}} \end{aligned} Θ(l)=Θ(l)−μ∂Θ(l)∂Etotal =Θ(l)−Nμi=1∑N∂Θ(l)∂E
b ( l ) = b ( l ) − μ ∂ E total ∂ b ( l ) = b ( l ) − μ N ∑ i = 1 N ∂ E ∂ b ( l ) \begin{aligned} \boldsymbol{b}^{(l)} &=\boldsymbol{b}^{(l)}-\mu \frac{\partial E_{\text {total }}}{\partial \boldsymbol{b}^{(l)}} \\ &=\boldsymbol{b}^{(l)}-\frac{\mu}{N} \sum_{i=1}^N \frac{\partial E}{\partial \boldsymbol{b}^{(l)}} \end{aligned} b(l)=b(l)−μ∂b(l)∂Etotal =b(l)−Nμi=1∑N∂b(l)∂E
(1) Θ ( ) \boldsymbol{ \Theta}^{()} Θ(l) 有可能是向量,也有可能是矩阵,主要取决于神经网络每层神经元的个数; b ( l ) \boldsymbol{b}^{(l)} b(l)是向量。 E E E是常数。
(2) Θ ( ) \boldsymbol{ \Theta}^{()} Θ(l) 与 b ( l ) \boldsymbol{b}^{(l)} b(l)的学习率可以不一样
输出层权重求导
任意一个训练样本,将误差表示(代价函数)在输出层展开

对于输出层其他的权重参数, 同样可得:
δ 1 ( 3 ) = − ( y 1 − a 1 ( 3 ) ) f ′ ( z 1 ( 3 ) ) δ 2 ( 3 ) = − ( y 2 − a 2 ( 3 ) ) f ′ ( z 2 ( 3 ) ) ∂ E ∂ Θ 11 ( 3 ) = δ 1 ( 3 ) a 1 ( 2 ) ∂ E ∂ Θ 21 ( 3 ) = δ 2 ( 3 ) a 1 ( 2 ) ∂ E ∂ Θ 12 ( 3 ) = δ 1 ( 3 ) a 2 ( 2 ) ∂ E ∂ Θ 22 ( 3 ) = δ 2 ( 3 ) a 2 ( 2 ) ∂ E ∂ Θ 13 ( 3 ) = δ 1 ( 3 ) a 3 ( 2 ) ∂ E ∂ Θ 23 ( 3 ) = δ 2 ( 3 ) a 3 ( 2 ) ∂ E ∂ Θ 14 ( 3 ) = δ 1 ( 3 ) a 4 ( 2 ) ∂ E ∂ Θ 24 ( 3 ) = δ 2 ( 3 ) a 4 ( 2 ) \begin{aligned} \delta_1^{(3)}&=-\left(y_1-a_1^{(3)}\right) f^{\prime}\left(z_1^{(3)}\right) \\ \delta_2^{(3)}&=-\left(y_2-a_2^{(3)}\right) f^{\prime}\left(z_2^{(3)}\right) \\ \frac{\partial E}{\partial \Theta_{11}^{(3)}}&=\delta_1^{(3)} a_1^{(2)} \quad \frac{\partial E}{\partial \Theta_{21}^{(3)}}=\delta_2^{(3)} a_1^{(2)} \\ \frac{\partial E}{\partial \Theta_{12}^{(3)}}& =\delta_1^{(3)} a_2^{(2)} \quad\frac{\partial E}{\partial \Theta_{22}^{(3)}}=\delta_2^{(3)} a_2^{(2)} \\ \frac{\partial E}{\partial \Theta_{13}^{(3)}}&=\delta_1^{(3)} a_3^{(2)} \quad \frac{\partial E}{\partial \Theta_{23}^{(3)}}=\delta_2^{(3)} a_3^{(2)} \\ \frac{\partial E}{\partial \Theta_{14}^{(3)}}&=\delta_1^{(3)} a_4^{(2)} \quad \frac{\partial E}{\partial \Theta_{24}^{(3)}}=\delta_2^{(3)} a_4^{(2)} \end{aligned} δ1(3)δ2(3)∂Θ11(3)∂E∂Θ12(3)∂E∂Θ13(3)∂E∂Θ14(3)∂E=−(y1−a1(3))f′(z1(3))=−(y2−a2(3))f′(z2(3))=δ1(3)a1(2)∂Θ21(3)∂E=δ2(3)a1(2)=δ1(3)a2(2)∂Θ22(3)∂E=δ2(3)a2(2)=δ1(3)a3(2)∂Θ23(3)∂E=δ2(3)a3(2)=δ1(3)a4(2)∂Θ24(3)∂E=δ2(3)a4(2)
Q:为什么引入 δ i ( l ) \delta_i^{(l)} δi(l)?
A:简化求导的表达式,通过 δ i ( l + 1 ) \delta_i^{(l+1)} δi(l+1)计算 δ i ( l ) \delta_i^{(l)} δi(l)(体现了误差的反向传播)
推广:
先考虑最后一层(L)
令
δ i ( L ) = − ( y i − a i ( L ) ) f ′ ( z i ( L ) ) ( 1 ≤ i ≤ n L ) ∂ E ∂ Θ i j ( L ) = δ i ( L ) a j ( L − 1 ) \delta_i^{(L)}=-(y_i-a_i^{(L)})f^{'}(z_i^{(L)})\quad (1 \le i \le n_L)\\\frac{\partial E}{\partial \Theta_{ij}^{(L)}}=\delta_i^{(L)} a_j^{(L-1)} δi(L)=−(yi−ai(L))f′(zi(L))(1≤i≤nL)∂Θij(L)∂E=δi(L)aj(L−1)
转化为向量形式:
δ ( L ) = − ( y − a ( L ) ) ⊙ f ′ ( z ( L ) ) ∇ Θ ( L ) E = δ ( L ) ( a ( L − 1 ) ) T \begin{gathered} \boldsymbol{\delta}^{(L)}=-\left(\boldsymbol{y}-\boldsymbol{a}^{(L)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(L)}\right) \\ \nabla_{\Theta^{(L)}} E=\boldsymbol{\delta}^{(L)}\left(\boldsymbol{a}^{(L-1)}\right)^T \end{gathered} δ(L)=−(y−a(L))⊙f′(z(L))∇Θ(L)E=δ(L)(a(L−1))T
其中, ⊙ \odot ⊙ 为 哈达玛积,表示矩阵或者向量对应元素相乘,最终
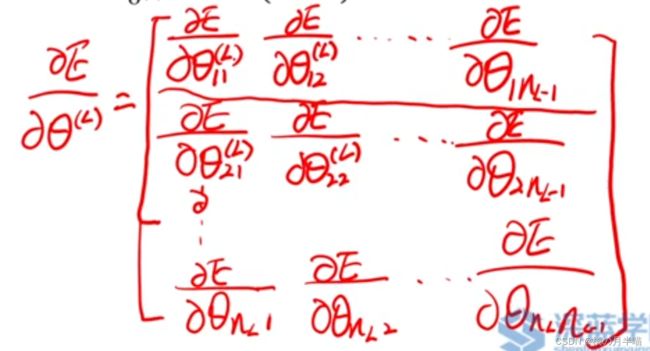
中间层权重求导
如下图,中间层的权重对后续层的影响,以及对最终 代价函数的影响。

根据链式法则,
代价函数对中间l层的权重求导得到,
∂ E ∂ Θ i j ( l ) = ∂ E ∂ z i ( l ) ∂ z i ( l ) ∂ Θ i j ( l ) = δ i ( l ) ∂ z i ( l ) ∂ Θ i j ( l ) = δ i ( l ) a j ( l − 1 ) \begin{aligned} \frac{\partial E}{\partial \Theta_{i j}^{(l)}} &=\frac{\partial E}{\partial z_i^{(l)}} \frac{\partial z_i^{(l)}}{\partial \Theta_{i j}^{(l)}} \\ &=\delta_i^{(l)} \frac{\partial z_i^{(l)}}{\partial \Theta_{i j}^{(l)}} \\ &=\delta_i^{(l)} a_j^{(l-1)} \end{aligned} ∂Θij(l)∂E=∂zi(l)∂E∂Θij(l)∂zi(l)=δi(l)∂Θij(l)∂zi(l)=δi(l)aj(l−1)
其中
δ i ( l ) ≡ ∂ E ∂ z i ( l ) = ∑ j = 1 n l + 1 ∂ E ∂ z j ( l + 1 ) ∂ z j ( l + 1 ) ∂ z i ( l ) = ∑ j = 1 n l + 1 δ j ( l + 1 ) ∂ z j ( l + 1 ) ∂ z i ( l ) = ∑ j = 1 n l + 1 δ j ( l + 1 ) ∂ z j ( l + 1 ) ∂ a i ( l ) ∂ a i ( l ) ∂ z i ( l ) = ∑ j = 1 n l + 1 δ j ( l + 1 ) Θ j i ( l + 1 ) ∂ a i ( l ) ∂ z i ( l ) = ( ∑ j = 1 n l + 1 δ j ( l + 1 ) Θ j i ( l + 1 ) ) f ′ ( z i ( l ) ) \begin{aligned} \delta_i^{(l)} & \equiv \frac{\partial E}{\partial z_i^{(l)}} \\ &=\sum_{j=1}^{n_{l+1}} \frac{\partial E}{\partial z_j^{(l+1)}} \frac{\partial z_j^{(l+1)}}{\partial z_i^{(l)}} \\ &=\sum_{j=1}^{n_{l+1}} \delta_j^{(l+1)} \frac{\partial z_j^{(l+1)}}{\partial z_i^{(l)}}\\ &=\sum_{j=1}^{n_{l+1}} \delta_j^{(l+1)} \frac{\partial z_j^{(l+1)}}{\partial a_i^{(l)}} \frac{\partial a_i^{(l)}}{\partial z_i^{(l)}} \\ &=\sum_{j=1}^{n_{l+1}} \delta_j^{(l+1)} \Theta_{j i}^{(l+1)} \frac{\partial a_i^{(l)}}{\partial z_i^{(l)}} \\ &=\left(\sum_{j=1}^{n_{l+1}} \delta_j^{(l+1)} \Theta_{j i}^{(l+1)}\right) f^{\prime}\left(z_i^{(l)}\right) \end{aligned} δi(l)≡∂zi(l)∂E=j=1∑nl+1∂zj(l+1)∂E∂zi(l)∂zj(l+1)=j=1∑nl+1δj(l+1)∂zi(l)∂zj(l+1)=j=1∑nl+1δj(l+1)∂ai(l)∂zj(l+1)∂zi(l)∂ai(l)=j=1∑nl+1δj(l+1)Θji(l+1)∂zi(l)∂ai(l)=(j=1∑nl+1δj(l+1)Θji(l+1))f′(zi(l))
BP 算法核心公式
BP传播算法的核心公式: 利用 l + 1 l+1 l+1 层的 δ i ( l + 1 ) \delta_i^{(l+1)} δi(l+1) 来 计算 l l l 层的 δ i ( l ) \delta_i^{(l)} δi(l)
δ ( l ) = ( ( θ ( l + 1 ) ) T δ ( l + 1 ) ) ⊙ f ′ ( z ( l ) ) \delta^{(l)}=\left(\left(\boldsymbol{\theta}^{(l+1)}\right)^T \delta^{(l+1)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(l)}\right) δ(l)=((θ(l+1))Tδ(l+1))⊙f′(z(l))
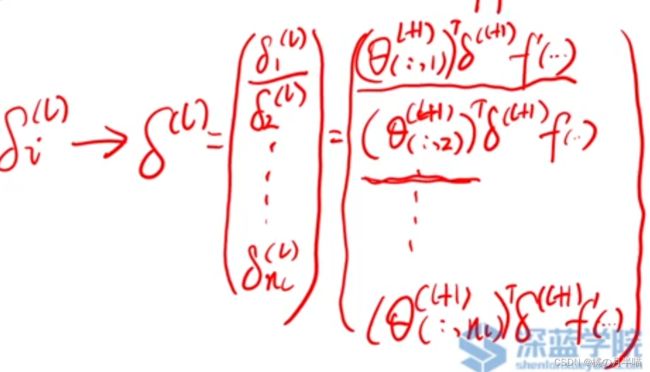
偏置求导
输出层偏执求导:
∂ E ∂ b 1 ( 3 ) = ∂ E ∂ a 1 ( 3 ) ∂ a 1 ( 3 ) ∂ z 1 ( 3 ) ∂ z 1 ( 3 ) b 1 ( 2 ) = δ 1 ( 3 ) ( ∂ E ∂ z 1 ( 3 ) = ∂ E ∂ a 1 ( 3 ) ∂ a 1 ( 3 ) ∂ z 1 ( 3 ) = δ 1 ( 3 ) 看之前推导 ; ∂ z 1 ( 3 ) b 1 ( 2 ) = 1 ) ∂ E ∂ b 2 ( 3 ) = ∂ E ∂ a 2 ( 3 ) ∂ a 2 ( 3 ) ∂ z 2 ( 3 ) ∂ z 2 ( 3 ) b 2 ( 2 ) = δ 2 ( 3 ) \frac{\partial E}{\partial b_1^{(3)}}=\frac{\partial E}{\partial a_1^{(3)}} \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}} \frac{\partial z_1^{(3)}}{b_1^{(2)}}=\delta_1^{(3)}\\ \quad(\frac{\partial E}{\partial z_1^{(3)}}=\frac{\partial E}{\partial a_1^{(3)}} \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}}=\delta_1^{(3)} 看之前推导;\frac{\partial z_1^{(3)}}{b_1^{(2)}}=1)\\ \frac{\partial E}{\partial b_2^{(3)}}=\frac{\partial E}{\partial a_2^{(3)}} \frac{\partial a_2^{(3)}}{\partial z_2^{(3)}} \frac{\partial z_2^{(3)}}{b_2^{(2)}}=\delta_2^{(3)} ∂b1(3)∂E=∂a1(3)∂E∂z1(3)∂a1(3)b1(2)∂z1(3)=δ1(3)(∂z1(3)∂E=∂a1(3)∂E∂z1(3)∂a1(3)=δ1(3)看之前推导;b1(2)∂z1(3)=1)∂b2(3)∂E=∂a2(3)∂E∂z2(3)∂a2(3)b2(2)∂z2(3)=δ2(3)
对隐藏层偏置求偏导数
以下图为例
∂ E ∂ b 1 ( 2 ) = ∂ E ∂ a 1 ( 3 ) ∂ a 1 ( 3 ) ∂ z 1 ( 3 ) ∂ z 1 ( 3 ) ∂ z 1 ( 2 ) z 1 ( 2 ) b 1 ( 2 ) = δ 1 ( 2 ) ∂ E ∂ b 2 ( 2 ) = ∂ E ∂ a 2 ( 3 ) ∂ a 2 ( 3 ) ∂ z 2 ( 3 ) ∂ z 2 ( 3 ) ∂ z 2 ( 2 ) z 2 ( 2 ) b 2 ( 2 ) = δ 2 ( 2 ) ∂ E ∂ b 3 ( 2 ) = ∂ E ∂ a 3 ( 3 ) ∂ a 3 ( 3 ) ∂ z 3 ( 3 ) ∂ z 3 ( 3 ) ∂ z 3 ( 2 ) z 3 ( 2 ) b 3 ( 2 ) = δ 3 ( 2 ) ∂ E ∂ b 4 ( 2 ) = ∂ E ∂ a 4 ( 3 ) ∂ a 4 ( 3 ) ∂ z 4 ( 3 ) ∂ z 4 ( 3 ) ∂ z 4 ( 2 ) z 4 ( 2 ) b 4 ( 2 ) = δ 4 ( 2 ) \frac{\partial E}{\partial b_1^{(2)}}=\frac{\partial E}{\partial a_1^{(3)}} \frac{\partial a_1^{(3)}}{\partial z_1^{(3)}} \frac{\partial z_1^{(3)}}{\partial z_1^{(2)}} \frac{z_1^{(2)}}{b_1^{(2)}}=\delta_1^{(2)}\\ \frac{\partial E}{\partial b_2^{(2)}}=\frac{\partial E}{\partial a_2^{(3)}} \frac{\partial a_2^{(3)}}{\partial z_2^{(3)}} \frac{\partial z_2^{(3)}}{\partial z_2^{(2)}} \frac{z_2^{(2)}}{b_2^{(2)}}=\delta_2^{(2)}\\ \frac{\partial E}{\partial b_3^{(2)}}=\frac{\partial E}{\partial a_3^{(3)}} \frac{\partial a_3^{(3)}}{\partial z_3^{(3)}} \frac{\partial z_3^{(3)}}{\partial z_3^{(2)}} \frac{z_3^{(2)}}{b_3^{(2)}}=\delta_3^{(2)}\\ \frac{\partial E}{\partial b_4^{(2)}}=\frac{\partial E}{\partial a_4^{(3)}} \frac{\partial a_4^{(3)}}{\partial z_4^{(3)}} \frac{\partial z_4^{(3)}}{\partial z_4^{(2)}} \frac{z_4^{(2)}}{b_4^{(2)}}=\delta_4^{(2)} ∂b1(2)∂E=∂a1(3)∂E∂z1(3)∂a1(3)∂z1(2)∂z1(3)b1(2)z1(2)=δ1(2)∂b2(2)∂E=∂a2(3)∂E∂z2(3)∂a2(3)∂z2(2)∂z2(3)b2(2)z2(2)=δ2(2)∂b3(2)∂E=∂a3(3)∂E∂z3(3)∂a3(3)∂z3(2)∂z3(3)b3(2)z3(2)=δ3(2)∂b4(2)∂E=∂a4(3)∂E∂z4(3)∂a4(3)∂z4(2)∂z4(3)b4(2)z4(2)=δ4(2)
梯度下降-偏置更新
可见 输出层和隐藏层的偏置都可以统一写为:
∂ E ∂ b i ( l ) = ∂ E ∂ z i ( l ) ∂ z i ( l ) b i ( l ) = δ i ( l ) \begin{aligned} \frac{\partial E}{\partial b_i^{(l)}} &=\frac{\partial E}{\partial z_i^{(l)}} \frac{\partial z_i^{(l)}}{b_i^{(l)}} \\ &=\delta_i^{(l)} \end{aligned} ∂bi(l)∂E=∂zi(l)∂Ebi(l)∂zi(l)=δi(l)
向量形式为: ∇ b ( l ) E = δ l \nabla_{b^{(l)}} E=\boldsymbol{\delta}^l ∇b(l)E=δl
反向传播整理
反向传播算法的核心公式为:
δ i ( L ) = − ( y i − a i ( L ) ) f ′ ( z i ( L ) ) δ i ( l ) = ( ∑ j = 1 n l + 1 δ j ( l + 1 ) Θ j i ( l + 1 ) ) f ′ ( z i ( i ) ) ∂ E ∂ Θ i j ( l ) = δ i ( l ) a j ( l − 1 ) ∂ E ∂ b i ( l ) = δ i ( l ) \begin{aligned} &\delta_i^{(L)}=-\left(y_i-a_i^{(L)}\right) f^{\prime}\left(z_i^{(L)}\right) \\ &\delta_i^{(l)}=\left(\sum_{j=1}^{n_{l+1}} \delta_j^{(l+1)} \Theta_{j i}^{(l+1)}\right) f^{\prime} (z_i^{(i)})\\ &\frac{\partial E}{\partial \Theta_{i j}^{(l)}}=\delta_i^{(l)} a_j^{(l-1)} \\ &\frac{\partial E}{\partial b_i^{(l)}}=\delta_i^{(l)} \end{aligned} δi(L)=−(yi−ai(L))f′(zi(L))δi(l)=(j=1∑nl+1δj(l+1)Θji(l+1))f′(zi(i))∂Θij(l)∂E=δi(l)aj(l−1)∂bi(l)∂E=δi(l)
向量形式为
δ ( L ) = − ( y − a ( L ) ) ⊙ f ′ ( z ( L ) ) δ ( l ) = ( ( Θ ( l + 1 ) ) ⊤ δ ( l + 1 ) ) ⊙ f ′ ( z ( l ) ) ∇ Θ ( l ) E = δ ( l ) ( a ( l − 1 ) ) ⊤ ∇ b ( l ) E = δ l \begin{aligned} &\boldsymbol{\delta}^{(L)}=-\left(\boldsymbol{y}-\boldsymbol{a}^{(L)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(L)}\right) \\ &\boldsymbol{\delta}^{(l)}=\left(\left(\Theta^{(l+1)}\right)^{\top} \boldsymbol{\delta}^{(l+1)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(l)}\right) \\ &\nabla_{\Theta^{(l)}} E=\boldsymbol{\delta}^{(l)}\left(\boldsymbol{a}^{(l-1)}\right)^{\top} \\ &\nabla_{b_{(l)} } E= \delta^l \end{aligned} δ(L)=−(y−a(L))⊙f′(z(L))δ(l)=((Θ(l+1))⊤δ(l+1))⊙f′(z(l))∇Θ(l)E=δ(l)(a(l−1))⊤∇b(l)E=δl
总结BP算法
输入:数据集D;学习率μ
输出:模型权重、偏置
- 随机初始化模型权重、偏置
- 前向传播
- z ( l ) = Θ ( l ) a ( l − 1 ) + b ( l ) a ( l ) = f ( z ( l ) ) a ( 1 ) = x \begin{aligned} \boldsymbol{z}^{(l)}& =\boldsymbol{\Theta}^{(l)} \boldsymbol{a}^{(l-1)}+\boldsymbol{b}^{(l)}\\ \boldsymbol{a}^{(l)}& =f(\boldsymbol{z}^{(l)})\\ \boldsymbol{a}^{(1)}& =\boldsymbol{x} \end{aligned} z(l)a(l)a(1)=Θ(l)a(l−1)+b(l)=f(z(l))=x
- 计算每一层误差
- δ ( L ) = − ( y − a ( L ) ) ⊙ f ′ ( z ( L ) ) δ ( l ) = ( ( Θ ( l + 1 ) ) ⊤ δ ( l + 1 ) ) ⊙ f ′ ( z ( l ) ) \boldsymbol{\delta}^{(L)}=-\left(\boldsymbol{y}-\boldsymbol{a}^{(L)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(L)}\right) \\ \boldsymbol{\delta}^{(l)}=\left(\left(\Theta^{(l+1)}\right)^{\top} \boldsymbol{\delta}^{(l+1)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(l)}\right) δ(L)=−(y−a(L))⊙f′(z(L))δ(l)=((Θ(l+1))⊤δ(l+1))⊙f′(z(l))
- 求各层权重、偏置的偏导。
- ∇ Θ ( l ) E = δ ( l ) ( a ( l − 1 ) ) T ∇ b ( l ) E = δ l \nabla_{\Theta^{(l)}} E=\boldsymbol{\delta}^{(l)}\left(\boldsymbol{a}^{(l-1)}\right)^{T} \\ \nabla_{b_{(l)} } E= \delta^l ∇Θ(l)E=δ(l)(a(l−1))T∇b(l)E=δl
- 更新参数
- Θ ( l ) = Θ ( l ) − μ ∂ E total ∂ Θ ( l ) = Θ ( l ) − μ N ∑ i = 1 N ∂ E ∂ Θ ( l ) b ( l ) = b ( l ) − μ ∂ E total ∂ b ( l ) = b ( l ) − μ N ∑ i = 1 N ∂ E ∂ b ( l ) \begin{aligned} \boldsymbol{\Theta}^{(l)} &=\boldsymbol{\Theta}^{(l)}-\mu \frac{\partial E_{\text {total }}}{\partial \boldsymbol{\Theta}^{(l)}} \\ &=\boldsymbol{\Theta}^{(l)}-\frac{\mu}{N} \sum_{i=1}^N \frac{\partial E}{\partial \boldsymbol{\Theta}^{(l)}}\\ \boldsymbol{b}^{(l)} &=\boldsymbol{b}^{(l)}-\mu \frac{\partial E_{\text {total }}}{\partial \boldsymbol{b}^{(l)}} \\ &=\boldsymbol{b}^{(l)}-\frac{\mu}{N} \sum_{i=1}^N \frac{\partial E}{\partial \boldsymbol{b}^{(l)}} \end{aligned} Θ(l)b(l)=Θ(l)−μ∂Θ(l)∂Etotal =Θ(l)−Nμi=1∑N∂Θ(l)∂E=b(l)−μ∂b(l)∂Etotal =b(l)−Nμi=1∑N∂b(l)∂E
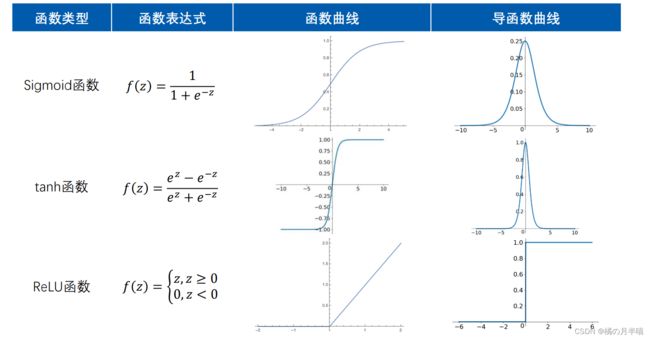
激活函数
的作用:对输入空间进行“弯曲(非线性变换)”,提升神经网络的非线性表达能力
激活函数即为上述神经网络中使用的 f ( z ) f(z) f(z)函数
设计激活函数的原则:
(1)非线性函数,且连续可导;
(2)函数及其导函数易于计算;
(3)导函数的值域以及分布

梯度消失
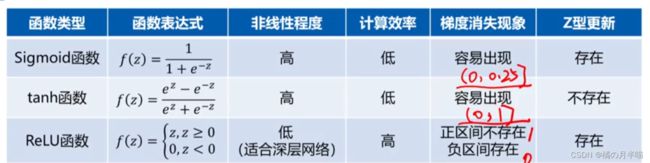
再误差反向传播的过程中,由于梯度越来越小,越靠近输入,更新量越小,导致参数得不到有效更新,训练效率下降。
这与激活函数的值域有一定关系,见下面式子
- δ ( L ) = − ( y − a ( L ) ) ⊙ f ′ ( z ( L ) ) δ ( l ) = ( ( Θ ( l + 1 ) ) ⊤ δ ( l + 1 ) ) ⊙ f ′ ( z ( l ) ) \boldsymbol{\delta}^{(L)}=-\left(\boldsymbol{y}-\boldsymbol{a}^{(L)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(L)}\right) \\ \boldsymbol{\delta}^{(l)}=\left(\left(\Theta^{(l+1)}\right)^{\top} \boldsymbol{\delta}^{(l+1)}\right) \odot f^{\prime}\left(\boldsymbol{z}^{(l)}\right) δ(L)=−(y−a(L))⊙f′(z(L))δ(l)=((Θ(l+1))⊤δ(l+1))⊙f′(z(l))
反向传播中,每一层都要乘以导函数 f ′ f^{'} f′,如果导函数值域过于小,就导致误差传播越传越小。
Z型更新
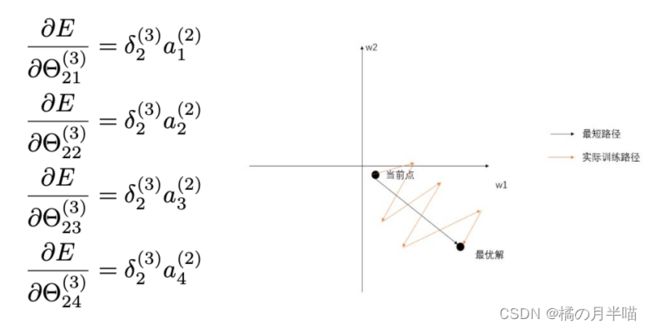
以上式更新方程举例:
由于一层的权重参数导数都共用一个δ,所以更新方向要么都增大(如右图,往第一象限去),要么都减小(往第三象限去),实现不了一个增大一个减小的情况。
目前使用最多的激活函数函数ReLU函数及其改进。