项目实战:自己手动搭建pytorch框架完成狗的分类
文章目录
- 任务简介
- 下载数据集
- 加载数据集
-
- 编写自定义数据集类
- 划分训练集与测试集
- 通过DataLoader批量加载数据集
- 神经网络模型
- 训练过程
- 设置超参数开始训练
- 测试
- 整体代码
任务简介
在本项目中,我们从零开始使用pytorch搭建深度学习框架,并训练出模型。我们的任务是完成Kaggle中的一个著名的比赛:狗的品种识别,比赛网址是https://www.kaggle.com/c/dog-breed-identification。在网站上下载的数据集中包含120种狗的种类,我们对其进行学习并测试训练结果。
下载数据集
我们可以登录比赛网址下载官方提供的数据集,如图:
下载需要注册Kaggle账户,为了方便我将数据集传至了百度网盘
链接:https://pan.baidu.com/s/1yZXpcgktcRaRPhbR3h8EyQ
提取码:fc3b
大家可以自己下载
压缩包里有四部分内容:训练集、测试集、标签文件、上传样例

本文中我们要用到的是train、label.csv
train文件夹中包含10222张狗的图片:

label.csv中是它们对应的种类:

加载数据集
为了实现分类,将每个种类对应一个编号,创建一个表格breed_index.xls存放这个对应关系:

表格与train、label.csv放于同一文件夹内
编写自定义数据集类
创建DogBreedData.py文件,写入以下内容:
# -*- coding: utf-8 -*-
from PIL import Image
import torch
from torch.utils.data import Dataset
import os
import pandas as pd
label_csv = pd.read_csv('labels.csv')#存放标签的csv文件
labels = label_csv.set_index('id')#以id为行索引
breed_index = pd.read_excel('breed_index.xls')
breed_index_dict = dict(zip(breed_index['breed'],breed_index['index']))
class DogBreedData(Dataset):
def __init__(self, datadir, transform=None):
self.datadir = datadir#数据集路径
self.img_names = os.listdir(self.datadir)
self.transform = transform#图片转tensor方式
def __len__(self):
return len(self.img_names)
def __getitem__(self, idx):
img_name = self.img_names[idx]#图片名称
path = os.path.join(self.datadir, img_name)
img = Image.open(path)
if self.transform:
m_img = self.transform(img)
label = breed_index_dict[labels['breed'][img_name[:-4]]]
m_label = torch.tensor(label)
return m_img,m_label
自定义数据集类需要继承torch.utils.data.Dataset类,然后重写它的__len__和__getitem__函数。
首先使用pandas库读取labels.csv与breed_index.xls,实现的效果是能够根据图片名称,例如“000bec180eb18c7604dcecc8fe0dba07.jpg”确定出狗的种类,为“boston_bull”,进而得出编号对应为19。由于我们后续会对读取的图片进行转换,如放缩、裁剪、标准化、转换为tensor类型等,这些需要使用torchvision.transforms下的变换,而transforms要求传入的类型为PIL Image类型,因此这里我们使用PIL来读取图像。
该类将每一张图像与其种类编号对应起来
在调用时,使用whole_data = DogBreedData('train', transform=trans)即可(trans的定义见下文)
划分训练集与测试集
我们将全部的10222张图片分为两部分,一部分(0.8)用于训练调整参数,另一部分(0.2)用作测试集,观察训练效果`
train_size = int(0.8*len(whole_data))#训练集图片数
test_size = len(whole_data)-train_size#测试集图片数
train_data,test_data = random_split(whole_data, [train_size,test_size])
random_split是torch.utils.data下的函数,用于划分数据集
生成训练集与测试集如下:
![]()
![]()
通过DataLoader批量加载数据集
我们生成的数据集为单独的一个个样本-标签,而网络的输入需要一批一批的输入样本,一次输入进一batch_size张图像,我们可以通过torch.utils.data下的函数DataLoader来完成此工作
def get_dataloader_workers():
"""使用4个进程来读取数据"""
return 0 if sys.platform.startswith('win') else 4
trans = transforms.Compose([
transforms.Resize((256,256)),#缩放至256x256
transforms.CenterCrop((224,224)),#截取中心224x224部分
transforms.ToTensor(),#转换为tensor数据
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化图像的每个通道
])
train_data_loader = DataLoader(
train_data,
batch_size = 128,
shuffle=True,
num_workers=get_dataloader_workers()
)#训练集
test_data_loader = DataLoader(
test_data,
batch_size = 128,
shuffle=True,
num_workers=get_dataloader_workers()
)#测试集
生成批量数据如下:
![]()
![]()
神经网络模型
本文所使用的这个数据集实际上是著名的ImageNet的数据集子集,因此,我们可以在完整ImageNet数据集上选择预训练的模型,然后使用该模型提取图像特征,以便将其输入到定制的小规模输出网络中。在这里,我们使用预训练的ResNet-34模型,并增加一个输出层,将原来的1000个输出变换为120个输出。由于不重新训练用于特征提取的预训练模型,节省了梯度下降的时间和内存空间。
torchvision.models为我们提供了丰富的预训练模型,例如vgg、resnet等,我们只需要调用其即可
def get_net(device):#定义网络,使用预训练好的resnet34网络,最后自己定义新输出网络为120类
finetune_net = nn.Sequential()
finetune_net.features = models.resnet34(pretrained=True)
# 定义一个新的输出网络,共有120个输出类别
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256),
nn.ReLU(),
nn.Linear(256, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(device)
# 冻结参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
在调用时,若参数pretrained设置为True,则说明使用预训练保存好的参数,否则只调用该网络框架,参数需要自行初始化从头训练。
训练过程
def savelist(L, name):
a = open(name, 'w')
for i in L:
i = str(i)
a.write(i)
a.write('\n')
a.close()
def test_model(model, test_data_loader, loss, device):
model.eval()
with torch.no_grad():
l_sum = 0.0
acc = 0
for j,(imgs,labels) in enumerate(test_data_loader):
imgs = imgs.to(device)
labels = labels.to(device)
output = model(imgs)
l = loss(output.float(), labels.long()).sum()
l_sum += l.item()*labels.size(0)
acc += accuracy_score(labels.to('cpu'), output.argmax(axis=1).to('cpu'))*labels.size(0)
return l_sum/len(test_data),acc/len(test_data)
def train_model(epochs, model, train_data_loader, test_data_loader, loss, optimizer, scheduler, device):
Train_loss = list()
Test_acc = list()
Test_loss = list()
for epoch in range(epochs):
start = time.time()
print('epoch:', epoch)
print('training on', device)
train_loss = 0.0
model.train()#训练模式
for i,(imgs,labels) in enumerate(train_data_loader):
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()#清空梯度
y_pre = model(imgs)
l = loss(y_pre.float(), labels.long()).sum()
train_loss += l.item()*labels.size(0)
l.backward()#反向传播
optimizer.step()#更新参数
scheduler.step()
end = time.time()
test_loss,test_acc = test_model(
model = model,
test_data_loader = test_data_loader,
loss = loss,
device = device
)
print('train_loss:', train_loss/len(train_data))
print('test_loss:', test_loss)
print('test_acc:', test_acc)
print('spend time:',end-start,'s')
print('*'*40)
Train_loss.append(train_loss/len(train_data))
Test_acc.append(test_loss)
Test_loss.append(test_acc)
torch.save(model, 'model.pth')
savelist(Train_loss, 'result/Train_loss1.txt')
savelist(Test_acc, 'result/Test_acc1.txt')
savelist(Test_loss, 'result/Test_loss1.txt')
if torch.cuda.is_available():
torch.cuda.empty_cache()
train_model参数说明:
epochs:训练迭代次数
model:网络模型
train_data_loader/test_data_loader:批量训练/测试数据集
loss:损失函数,这里使用交叉熵损失,见下定义
optimizer:优化器
scheduler:学习率调整算法
device:使用GPU加速计算
test_model函数说明:在训练过程在测试集上评估模型,使用sklearn.metrics下的accuracy_score函数计算分类正确的个数
设置超参数开始训练
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
if __name__ == '__main__':
whole_data = DogBreedData('train', transform=trans)
train_size = int(0.8*len(whole_data))#训练集图片数
test_size = len(whole_data)-train_size#测试集图片数
train_data,test_data = random_split(whole_data, [train_size,test_size])
train_data_loader = DataLoader(
train_data,
batch_size = 128,
shuffle=True,
num_workers=get_dataloader_workers()
)#训练集
test_data_loader = DataLoader(
test_data,
batch_size = 128,
shuffle=True,
num_workers=get_dataloader_workers()
)#测试集
device = try_gpu()#使用GPU
net = get_net(device)#加载网络
model = nn.DataParallel(net).to(device)
loss = nn.CrossEntropyLoss()#交叉熵损失函数
optimizer = torch.optim.SGD((param for param in model.parameters() if param.requires_grad),
lr=1e-3,
momentum=0.9)#优化模型
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.9)
epochs = 15#训练次数
train_model(
epochs = epochs,
model = model,
train_data_loader = train_data_loader,
test_data_loader = test_data_loader,
loss = loss,
optimizer = optimizer,
scheduler = scheduler,
device = device
)
训练过程如图

训练结束得到model.pth模型与三个txt文件,根据其绘制出训练过程曲线图:
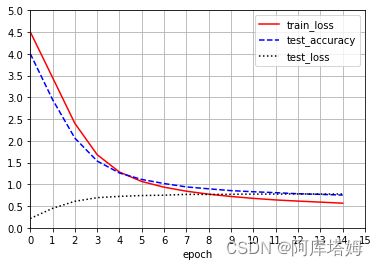
由于模型选择、参数设置、迭代次数等未调于最佳状态,该结果的测试集精确度在0.78左右
测试
将modell.pth与三个txt文件一同放入result文件夹
# -*- coding: utf-8 -*-
import torch
from torchvision import transforms
from PIL import Image
from matplotlib import pyplot as plt
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
device = try_gpu()
trans = transforms.Compose([
transforms.Resize((256,256)),
transforms.CenterCrop((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
net = torch.load('result/model.pth')
img = Image.open('test/00a3edd22dc7859c487a64777fc8d093.jpg')
x = trans(img).reshape((1,3,224,224))
x.to(device)
y = net(x)
print(y.argmax(axis=1).item())
plt.imshow(img)
用test文件夹的第一张进行测试,输出结果:

根据编号对应表格,46号对应german_shepherd德国牧羊犬,可知预测结果正确,由此我们便完成了分类任务
整体代码
整个代码已上传至github:kaggle-dog-identification