python解析pdf得到每个字符的坐标
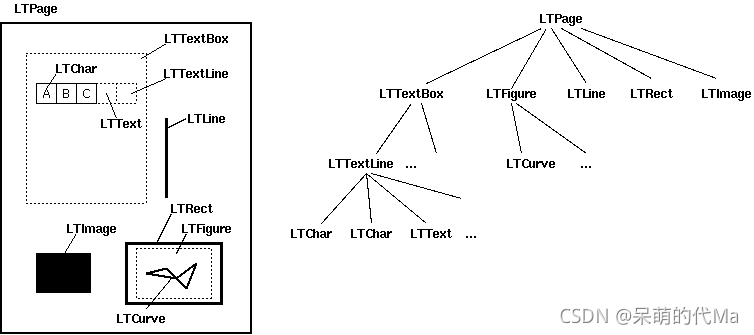
结构图如下:
只要一直循环,就可以从Box -> Line -> Char
使用.bbox属性就可以得到坐标,一共有4个值,分别表示:
- x0:从页面左侧到框左边缘的距离
- y0:从页面底部到框的下边缘的距离
- x1:从页面左侧到方框右边缘的距离
- y1:从页面底部到框的上边缘的距离
示例
import requests
import io
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTText, LTChar, LTAnno
def parse_char_layout(layout):
"""解析页面内容,一个字母一个字母的解析"""
# bbox:
# x0:从页面左侧到框左边缘的距离。
# y0:从页面底部到框的下边缘的距离。
# x1:从页面左侧到方框右边缘的距离。
# y1:从页面底部到框的上边缘的距离
for textbox in layout:
if isinstance(textbox, LTText):
for line in textbox:
for char in line:
# If the char is a line-break or an empty space, the word is complete
if isinstance(char, LTAnno) or char.get_text() == ' ':
pass
elif isinstance(char, LTChar):
print("坐标 x:", char.bbox[0], "y:", char.bbox[3], " ||| ", char.get_text())
if __name__ == '__main__':
req = requests.get("http://www.africau.edu/images/default/sample.pdf")
fp = io.BytesIO(req.content)
# fp = open('../../ocr_pdf/0a0c3b458b66d5e525551ec5b40df1c6.pdf', 'rb')
parser = PDFParser(fp) # 用文件对象来创建一个pdf文档分析器
doc: PDFDocument = PDFDocument(parser) # 创建pdf文档
rsrcmgr = PDFResourceManager() # 创建PDF,资源管理器,来共享资源
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释其对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page内容
# doc.get_pages() 获取page列表
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 处理文档对象中每一页的内容
# doc.get_pages() 获取page列表
# 循环遍历列表,每次处理一个page的内容
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for page in PDFPage.create_pages(doc):
print('================ 新页面 ================')
interpreter.process_page(page)
layout = device.get_result()
parse_char_layout(layout) # 解析字母