cs224n学习笔记9-问答系统
目录
Question Answering 问答系统
Question Answering 问答
Reading Comprehension 阅读理解
Stanford question answering dataset(SQuAD) 斯坦福问答数据集
神经网络模型
BiDAF: the Bidirectional Attention Flow model (2017)
用于阅读理解的BERT模型
比较BiDAF和BERT模型
预训练模型SpanBERT
瓶颈
Open-domain question answering 开放域问答
Question Answering 问答系统
Question Answering 问答
目的:自动回答人类自然语言的问题
分类:信息源类型(一段文本、网络文档、知识库、表格、图像、视频、音频)
问题类型(事实与非事实、开放域与封闭域、简单与复杂)
回答类型(一个单词、一个片段、一个段落、一个列表、是/否)
Protosynthex (1964):最早的问答系统,基于对文本的依存分析,为问题匹配回答
IBM Waston 问答系统 (2011年):包含大量nlp模块

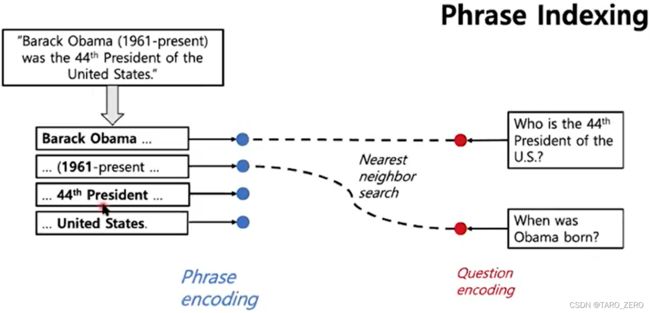
深度学习时代:几乎所有最先进的问答系统都建立在端到端训练和预训练语言模型(例如BERT)之上,例如下图所示的开放检索问答(ORQA)系统

超越文本QA问题
基于知识的QA:基于巨大的知识库

视觉问答

Reading Comprehension 阅读理解
理解一段文本并回答关于其内容的问题
意义:阅读理解具有大量实际应用需求;是评估计算机系统对人类语言理解程度的重要测试平台;许多其他 NLP 任务可以转为阅读理解问题
Stanford question answering dataset(SQuAD) 斯坦福问答数据集
包含![]() 组带注释的
组带注释的![]() 三元组,其中文章来自英文维基百科,回答都是截取自文章中的片段,内容如下
三元组,其中文章来自英文维基百科,回答都是截取自文章中的片段,内容如下

评估指标:exact match(0或1)和 F1,测试时会有三个最佳回答,然后我们分别和预测回答进行匹配,最后取三个回答EM和F1得分的平均值
神经网络模型
任务描述:输入文本和问题的单词序列,输出回答片段截取自文本中的开始和结束位置

模型可分为基于LSTM和基于BERT两类,前者是2016~2018年的研究思路,至2019年后该领域的研究方向转为后者

注意到QA任务思路与机器翻译任务中seq2seq模型类似,同样都是使用注意力机制处理两个单词序列之间的关系,前者需要再加上两个分类器来输出答案的起止位置
BiDAF: the Bidirectional Attention Flow model (2017)
编码器:字符嵌入(字符级CNN模型)+词嵌入(预训练的词嵌入GloVe模型)+上下文嵌入(单词序列的BiLSTM模型)

注意力机制:定义Context2Query(为每个文本单词匹配最相关的问题中词汇)和Query2Context(为每个问题中的单词匹配最相关的文本词汇)两种注意力机制

先对每一对分别在文本和问题中的单词建立相似性

然后分别计算Context2Query和Query2Context注意力


最后输出所有向量的拼接

解码器:建模层(两层BiLSTM)+输出层(softmax分类器)
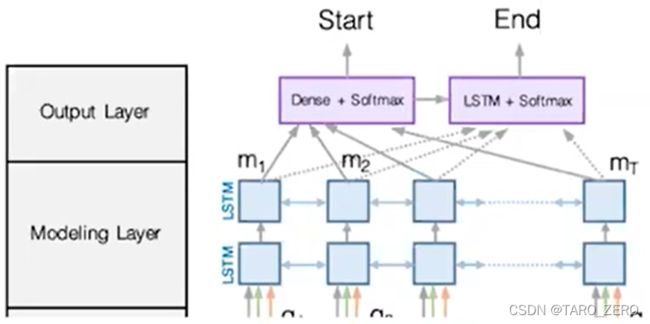
损失函数

模型效果:在SQuAD上F1达到77.3
用于阅读理解的BERT模型
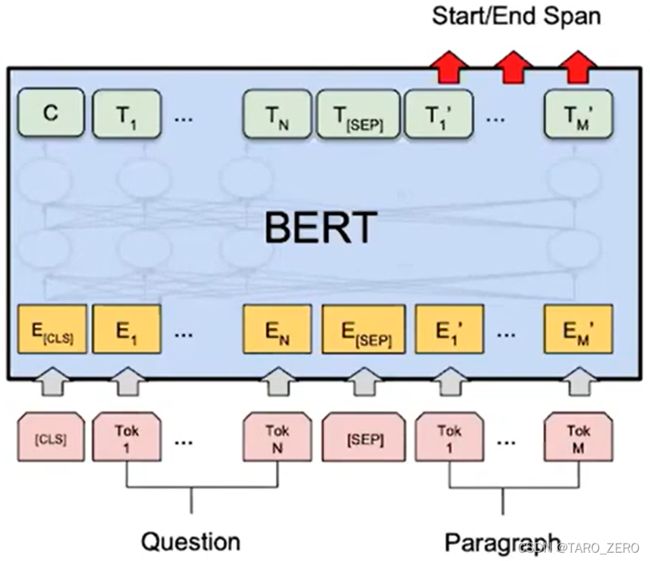

模型效果:在SQuAD上F1达到90以上,效果极佳
比较BiDAF和BERT模型
BERT模型有更多的参数(110M或330M),BiDAF包含大约2.5M的参数
BiDAF建立在多个双向LSTM之上,BERT建立在Transformer之上(无循环架构且易于并行)
BERT是预训练的,BiDAF仅建立在GloVe之上(所有其余参数都从监督数据集中学习)
预训练模型SpanBERT

改进思路:将随机掩盖15%单词改为掩盖连续的单词序列;使用被掩盖的序列的两端来预测中间的所有词汇
瓶颈
仅在受限的精准数据集上表现良好:易受无关文本干扰;无法掌握比较级、词性、反义词、共指、主被动等概念的理解
Open-domain question answering 开放域问答
没有给定的文本范围,基于大量的数据集回答任意问题
Retriever-reader framework 检索器-阅读器框架
问题描述为给定大量文档 和问题
和问题 ,输出答案
,输出答案

该模型先选出量级较小的文档集,再从中找出答案
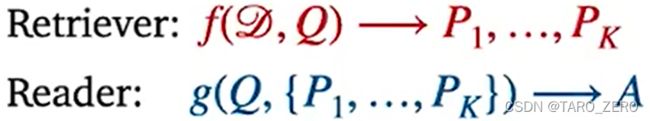
Large language models 大型语言模型

DensePhrases: 仅检索器,无阅读器