大数据技术之 Flink-CDC
第 1 章 CDC 简介
1.1 什么是 CDC
CDC 是 Change Data Capture(变更数据获取)的简称。在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。CDC 技术的应用场景非常广泛:
数据同步:用于备份,容灾;
数据分发:一个数据源分发给多个下游系统;
数据采集:面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
1.2 CDC 的种类
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
基于查询的 CDC:
离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
不保障实时性,基于离线调度存在天然的延迟。
基于日志的 CDC:
实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
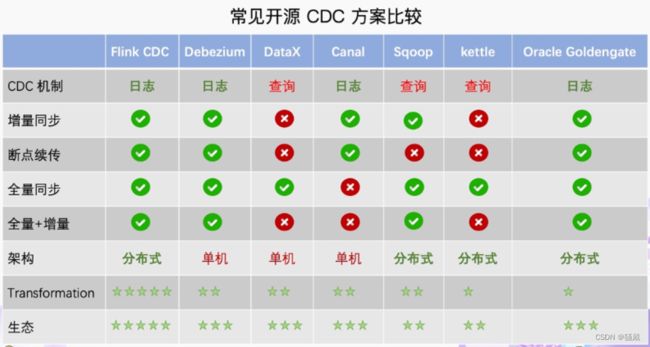
对比增量同步能力,
基于日志的方式,可以很好的做到增量同步;
而基于查询的方式是很难做到增量同步的。
对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:

骚戴理解:
Batch是批处理,Streaming是流处理,批处理就是一次处理大批数据,流处理就是更新一条数据处理一条数据,其实就是全量和增量
是否可以捕获所有数据变化的解释:假如我有一条数据我更新了很多次,比如我把a改成b后再改成c,然后如果是基于查询的CDC那就只能读取到最后一次更新的数据,只能知道c,而b不能知道,但是如果是基于Binlog的CDC的话就可以知道所有的变化
增加数据库压力:Binlog是日志文件,所以基于Binlog的CDC是不增加数据库压力的
1.3 Flink-CDC
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL
等数据库直接读取全量数据和增量变更数据的 source 组件。
ETL 分析中,通过先采集、然后依赖外部 MQ 进行数据投递、在下游消费后进行计算,最后在进行数据存储。整体的数据链路比较长,FlinkCDC 的核心理念在于简化数据链路,底层集成了 Debezium 进行 binlog 的采集、省去了 MQ 部分、最后通过 Flink 进行计算。全链路上都基于 Flink 生态,比较清晰。
1.4 Flink CDC 项目的动机
1. Dynamic Table & ChangeLog Stream
大家都知道 Flink 有两个基础概念:Dynamic Table 和 Changelog Stream。
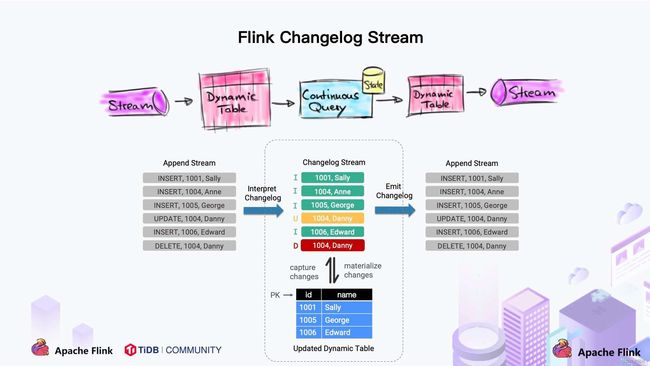
Dynamic Table 就是 Flink SQL 定义的动态表,动态表和流的概念是对等的。参照上图,流可以转换成动态表,动态表也可以转换成流。
在 Flink SQL中,数据在从一个算子流向另外一个算子时都是以 Changelog Stream 的形式,任意时刻的 Changelog Stream 可以翻译为一个表,也可以翻译为一个流。
联想下 MySQL 中的表和 binlog 日志,就会发现:MySQL 数据库的一张表所有的变更都记录在 binlog 日志中,如果一直对表进行更新,binlog 日志流也一直会追加,数据库中的表就相当于 binlog 日志流在某个时刻点物化的结果;日志流就是将表的变更数据持续捕获的结果。这说明 Flink SQL 的 Dynamic Table 是可以非常自然地表示一张不断变化的 MySQL 数据库表。

在此基础上,我们调研了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层采集工具。Debezium 支持全量同步,也支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能。
将 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构进行对比,可以发现两者是非常相似的。
每条 RowData 都有一个元数据 RowKind,包括 4 种类型, 分别是插入 (INSERT)、更新前镜像 (UPDATE_BEFORE)、更新后镜像 (UPDATE_AFTER)、删除 (DELETE),这四种类型和数据库里面的 binlog 概念保持一致。
而 Debezium 的数据结构,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after)。
通过分析两种数据结构,Flink 和 Debezium 两者的底层数据是可以非常方便地对接起来的,大家可以发现 Flink 做 CDC 从技术上是非常合适的。
2. 传统 CDC ETL 分析
我们来看下传统 CDC 的 ETL 分析链路,如下图所示:
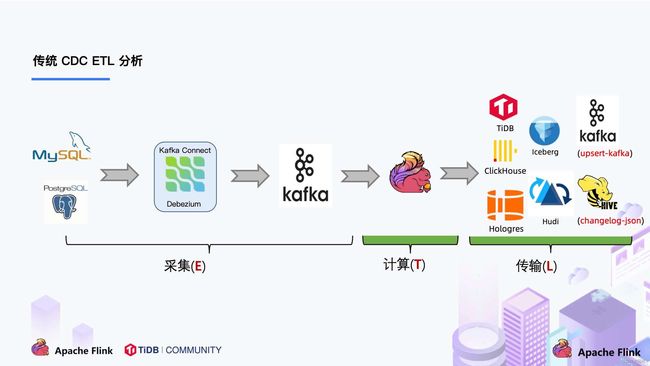
传统的基于 CDC 的 ETL 分析中,数据采集工具是必须的,国外用户常用 Debezium,国内用户常用阿里开源的 Canal,采集工具负责采集数据库的增量数据,一些采集工具也支持同步全量数据。采集到的数据一般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这一部分数据写入到目的端,目的端可以是各种 DB,数据湖,实时数仓和离线数仓。
注意,Flink 提供了 changelog-json format,可以将 changelog 数据写入离线数仓如 Hive / HDFS;对于实时数仓,Flink 支持将 changelog 通过 upsert-kafka connector 直接写入 Kafka。

我们一直在思考是否可以使用 Flink CDC 去替换上图中虚线框内的采集组件和消息队列,从而简化分析链路,降低维护成本。同时更少的组件也意味着数据时效性能够进一步提高。答案是可以的,于是就有了我们基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
在使用了 Flink CDC 之后,除了组件更少,维护更方便外,另一个优势是通过 Flink SQL 极大地降低了用户使用门槛,可以看下面的例子:
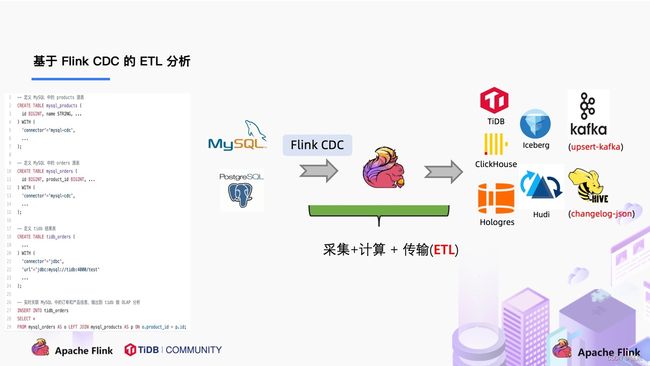
该例子是通过 Flink CDC 去同步数据库数据并写入到 TiDB,用户直接使用 Flink SQL 创建了产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 加工,加工后直接写入到下游数据库。通过一个 Flink SQL 作业就完成了 CDC 的数据分析,加工和同步。
大家会发现这是一个纯 SQL 作业,这意味着只要会 SQL 的 BI,业务线同学都可以完成此类工作。与此同时,用户也可以利用 Flink SQL 提供的丰富语法进行数据清洗、分析、聚合。
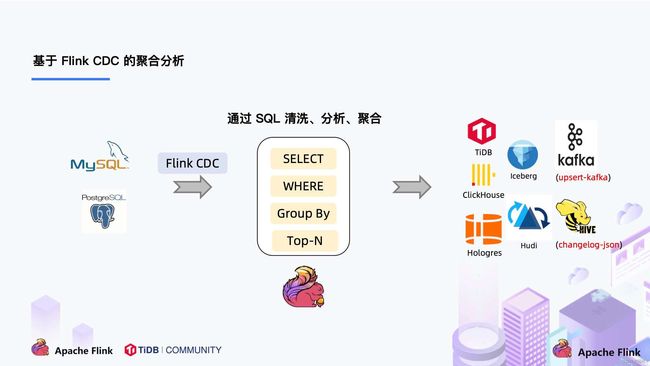
而这些能力,对于现有的 CDC 方案来说,进行数据的清洗,分析和聚合是非常困难的。
此外,利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以非常容易地完成数据打宽,以及各种业务逻辑加工。

1.5 CDC和Debezium的优缺点
Debezium和Flink CDC都是用于实时数据流处理的开源工具,但它们在设计和功能方面有一些差异。
Debezium的优点
实时数据同步:Debezium基于CDC技术,可以实时捕获数据库中的数据变更,并将其同步到目标系统中。
高可靠性:Debezium支持故障转移和容错机制,当出现故障时,可以自动切换到备用节点上。
易于部署和使用:Debezium提供了丰富的文档和示例,使得用户可以快速地部署和使用。
支持多种数据源:Debezium支持多种主流的关系型数据库,如MySQL、PostgreSQL、MongoDB、SQL Server和Oracle等,同时也支持NoSQL数据库和消息队列等数据源。
可扩展性强:Debezium支持水平扩展,可以轻松地处理大规模的数据变更事件。
生态丰富:Debezium有着广泛的社区支持和活跃的生态系统,例如Kafka Connect、Debezium插件等。
Debezium的缺点
高延迟:Debezium使用CDC技术将数据库中的更改转换为Kafka消息。这会导致一些延迟,并可能影响到实时性要求较高的应用。
复杂性:Debezium需要在源数据库和Kafka之间建立连接和配置,这对于不熟悉Kafka和CDC的人来说可能会很困难。
数据格式限制:由于Debezium使用特定的数据格式,因此需要根据需求对其进行修改或扩展。
稳定性:在某些情况下,Debezium可能会因为网络问题或其他原因导致数据丢失或重复传输。因此,需要进行适当的监控和维护来确保稳定性。
存储成本:由于Debezium将所有更改捕获并发送到Kafka主题,因此需要相应的存储空间来存储所有数据。这可能会增加存储成本。
Flink CDC的优点
实时性:Flink CDC 可以实时捕获和处理数据变化,能够及时反映数据源的最新状态。
精确性:Flink CDC 可以准确地捕获每个数据变化,确保数据的完整性和一致性。
可靠性:Flink CDC 提供了高可靠性的数据处理和容错机制,即使系统出现故障或错误,也能保证数据的安全性和正确性。
灵活性:Flink CDC 支持多种数据源和格式,可以轻松地适应不同的业务场景和需求。
高效性:Flink CDC 使用分布式计算技术,能够快速处理大规模的数据量,并支持流式计算和批量计算两种模式。
Flink CDC的缺点
需要对源数据进行修改:Flink CDC需要在源数据库中创建特殊的日志表或触发器来捕获变更,这可能会影响源系统的性能和稳定性,并且需要对源数据进行修改。
无法保证数据完整性:由于CDC是基于日志或触发器等机制进行数据捕获的,因此在高负载和故障情况下可能会导致数据丢失或不一致。
对网络和存储资源的需求较高:Flink CDC需要大量的网络带宽和存储资源来处理大规模的数据流,并确保数据的及时性和正确性。
需要专业知识:Flink CDC需要相当的专业知识和技能才能正确配置和操作,这可能会增加部署和运维的成本和风险。
Flink CDC和Debezium进行对比
Flink CDC和Debezium都是用于实时数据流处理的工具,但它们的重点略有不同。
Flink CDC是Apache Flink的一部分,主要用于从关系型数据库中捕获变更数据并将其转换为实时数据流。它提供了易于使用的API来快速构建基于流的应用程序,并支持在事件时间和处理时间上进行窗口聚合等高级操作。
与之相比,Debezium是一个独立的开源项目,它专门用于捕获数据库的变更事件并将其转换为Kafka消息。Debezium支持多种数据库引擎,并提供了灵活的配置选项来控制事件的生成和传输。
总的来说,如果您正在构建一个需要从关系型数据库中采集数据的大规模实时流处理系统,那么Flink CDC可能是更好的选择。而如果您只需要将数据库变更事件转换为消息传递到其他系统中,那么Debezium可能更适合您的需求。
1.6 Debezium和Flink CDC有哪些的使用场景
Debezium可用于以下场景
数据库迁移:可以使用Debezium将现有数据库的数据迁移到新的系统中。
数据仓库实时同步:可以使用Debezium捕获源数据库中的变更事件,并将其同步到数据仓库中,以便进行实时分析。
事务日志分析:可以使用Debezium分析数据库的事务日志,以便监控和诊断系统性能问题。
微服务架构中的数据共享:可以使用Debezium将不同微服务之间的数据同步,从而实现数据共享。
消息驱动的应用程序:可以使用Debezium将数据变更事件转换为消息,在消息队列中进行处理。
实时数据集成:可以使用Debezium实现不同系统之间的实时数据集成,例如ERP、CRM等系统之间的数据同步。
Flink CDC(Change Data Capture)可用于以下场景
实时数据同步:可以使用Flink CDC将数据库中的变更事件实时同步到目标系统中,以便进行实时分析和处理。
数据仓库实时同步:可以使用Flink CDC将源数据库中的变更事件同步到数据仓库中,以实现实时数据仓库。
事务日志分析:可以使用Flink CDC分析数据库的事务日志,以便监控和诊断系统性能问题。
增量更新:可以使用Flink CDC对已有的数据进行增量更新,而不是全量重新计算,从而提高计算效率。
数据集成:可以使用Flink CDC将不同系统之间的数据进行实时集成,例如ERP、CRM等系统之间的数据同步。
数据库迁移:可以使用Flink CDC将现有数据库的数据迁移到新的系统中,同时保证数据的一致性。
Flink CDC和Debezium进行使用场景的对比
Flink CDC和Debezium都是用于实现数据变更捕获(CDC)的工具,但是它们的使用场景略有不同。
Flink CDC是Apache Flink的一部分,主要用于构建流处理应用程序。它可以从关系型数据库中捕获变更事件,并将这些事件转换为流数据,然后可以对其进行实时计算和分析。因此,Flink CDC适用于需要实时处理和分析数据的场景,如实时业务智能、监控和警报等。
而Debezium则是一个独立的开源项目,用于连接不同类型的数据源(包括关系型数据库、NoSQL数据库等)并捕获变更事件。它可以将这些事件发送到消息队列或事件总线等目标系统中,以便其他系统消费。因此,Debezium适用于需要将数据变更事件与其他系统集成的场景,如微服务架构、事件驱动架构等。
综上所述,Flink CDC适用于需要实时处理和分析数据的场景,而Debezium适用于需要将数据变更事件与其他系统集成的场景。
1.7 Debezium和Flink CDC支持的数据库类型
Debezium 1.8支持以下数据库版本:
MySQL 5.7和8.0
PostgreSQL 9.4到13.x
MongoDB 3.6到4.4
SQL Server 2016、2017和2019
Oracle 11gR2、12cR1、12cR2和19c
请注意,这只是针对Debezium 1.8的支持列表。不同版本的Debezium可能支持不同的数据库版本。
Flink CDC 2.3.x 支持的数据库版本:
Connector |
Database |
Driver |
mongodb-cdc |
MongoDB: 3.6, 4.x, 5.0 |
MongoDB Driver: 4.3.1 |
mysql-cdc |
PolarDB X: 2.0.1 |
JDBC Driver: 8.0.27 |
oceanbase-cdc |
OceanBase EE (MySQL mode): 2.x, 3.x |
JDBC Driver: 5.1.4x |
oracle-cdc |
Oracle: 11, 12, 19 |
Oracle Driver: 19.3.0.0 |
postgres-cdc |
PostgreSQL: 9.6, 10, 11, 12 |
JDBC Driver: 42.2.12 |
sqlserver-cdc |
Sqlserver: 2012, 2014, 2016, 2017, 2019 |
JDBC Driver: 7.2.2.jre8 |
tidb-cdc |
TiDB: 5.1.x, 5.2.x, 5.3.x, 5.4.x, 6.0.0 |
JDBC Driver: 8.0.27 |
db2-cdc |
Db2: 11.5 |
DB2 Driver: 11.5.0.0 |
1.8 FlinkCDC 和Flink的版本对应关系
下表显示了Flink CDC连接器和Flink之间的版本映射:
Flink® CDC Version |
Flink® Version |
1.0.0 |
1.11.* |
1.1.0 |
1.11.* |
1.2.0 |
1.12.* |
1.3.0 |
1.12.* |
1.4.0 |
1.13.* |
2.0.* |
1.13.* |
2.1.* |
1.13.* |
2.2.* |
1.13.*, 1.14.* |
2.3.* |
1.13.*, 1.14.*, 1.15.*, 1.16.0 |
第 2 章 Flink CDC 案例实操
2.1 DataStream 方式的应用
2.1.1 导入依赖
4.0.0
com.atguigu
atguigu-flink-cdc
1.0-SNAPSHOT
1.13.0
org.apache.flink
flink-java
${flink-version}
org.apache.flink
flink-streaming-java_2.12
${flink-version}
org.apache.flink
flink-clients_2.12
${flink-version}
org.apache.hadoop
hadoop-client
3.1.3
mysql
mysql-connector-java
5.1.49
org.apache.flink
flink-table-planner-blink_2.12
${flink-version}
com.ververica
flink-connector-mysql-cdc
2.0.0
com.alibaba
fastjson
1.2.75
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
2.1.2 编写代码
package com.atguigu;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//设置并行度为1
//1.1 开启CK(CK就是Checkpoint)
env.enableCheckpointing(5000);//5s一次断点,可以理解为5s备份一次
env.getCheckpointConfig().setCheckpointTimeout(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//断点的文件存储的位置(在下面2.1.3的第七点创建)
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));
//2.通过FlinkCDC构建SourceFunction
DebeziumSourceFunction sourceFunction = MySqlSource.builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("cdc_test")
.tableList("cdc_test.user_info")
.deserializer(new StringDebeziumDeserializationSchema()) //设置序列化器
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
.tableList("cdc_test.user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的 .databaseList("cdc_test")数据库里的所有表的数据
注意:指定的时候需要使用"db.table"的方式,因为databaseList里面可以写多个库名,不指定数据库的话可能会出现歧义
.startupOptions(StartupOptions.initial())里面的StartupOptions的方法介绍
initial (default): 在第一次启动时对受监控的数据库表执行初始快照,并继续读取最新的binlog。其实就是能获取表中原本存在的数据,在监控后的操作也能获取到
latest-offset: 从不在第一次启动时对受监控的数据库表执行快照,只从binlog的末尾读取,这意味着只具有自连接器启动以来的更改。其实就是不能获取表中原本存在的数据,只能获取在监控后的操作
timestamp: 从不在第一次启动时对被监控的数据库表执行快照,直接从指定的时间戳读取binlog。消费者将从头开始遍历binlog,并忽略时间戳小于指定时间戳的更改事件
specific-offset: 从不在第一次启动时对被监视的数据库表执行快照,直接从指定的偏移量读取binlog。
2.1.3 案例测试
1)打包并上传至 Linux
2)开启 MySQL Binlog 并重启 MySQL
3)启动 Flink 集群
[atguigu@hadoop102 flink-standalone]$ bin/start-cluster.sh
4)启动 HDFS 集群
[atguigu@hadoop102 flink-standalone]$ start-dfs.sh
5)启动程序
[atguigu@hadoop102 flink-standalone]$ bin/flink run -c com.atguigu.FlinkCDC flink-1.0-
SNAPSHOT-jar-with-dependencies.jar
6)在 MySQL 的 gmall-flink.z_user_info 表中添加、修改或者删除数据
7)给当前的 Flink 程序创建 Savepoint
[atguigu@hadoop102 flink-standalone]$ bin/flink savepoint JobId
hdfs://hadoop102:8020/flink/save
8)关闭程序以后从 Savepoint 重启程序
[atguigu@hadoop102 flink-standalone]$ bin/flink run -s hdfs://hadoop102:8020/flink/save/... -c
com.atguigu.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar
2.2 FlinkSQL 方式的应用
2.2.1 代码实现
package com.atguigu;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQLCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//设置并行度为1
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.使用FLINKSQL DDL模式构建CDC 表
tableEnv.executeSql("CREATE TABLE user_info ( " +
" id STRING primary key, " +
" name STRING, " +
" sex STRING " +
") WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'scan.startup.mode' = 'latest-offset', " +
" 'hostname' = 'hadoop102', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = '000000', " +
" 'database-name' = 'cdc_test', " +
" 'table-name' = 'user_info' " +
")");
//3.查询数据并转换为流输出
Table table = tableEnv.sqlQuery("select * from user_info");
DataStream> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
//4.启动
env.execute("FlinkSQLCDC");
}
}
2.3 自定义反序列化器
2.3.1 代码实现
package com.atguigu.func;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserializationSchema implements DebeziumDeserializationSchema {
/**
* {
* "db":"",
* "tableName":"",
* "before":{"id":"1001","name":""...},
* "after":{"id":"1001","name":""...},
* "op":""
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
//创建JSON对象用于封装结果数据
JSONObject result = new JSONObject();
//获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
result.put("db", fields[1]);
result.put("tableName", fields[2]);
//获取before数据
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
//获取列信息
Schema schema = before.schema();
List fieldList = schema.fields();
for (Field field : fieldList) {
beforeJson.put(field.name(), before.get(field));
}
}
result.put("before", beforeJson);
//获取after数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
//获取列信息
Schema schema = after.schema();
List fieldList = schema.fields();
for (Field field : fieldList) {
afterJson.put(field.name(), after.get(field));
}
}
result.put("after", afterJson);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
result.put("op", operation);
//输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
第 3 章 Flink-CDC 2.0
本章图片来源于北京站 Flink Meetup 分享的《详解 Flink-CDC》
3.1 1.x 痛点
FlinkCDC1.0版本的缺点

全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。
不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
3.2 Debezium 锁分析
Flink CDC 底层封装了 Debezium, Debezium 同步一张表分为两个阶段:
全量阶段:查询当前表中所有记录;
增量阶段:从 binlog 消费变更数据。
大部分用户使用的场景都是全量 + 增量同步,加锁是发生在全量阶段,目的是为了确定全量阶段的初始位点,保证增量 + 全量实现一条不多,一条不少,从而保证数据一致性。从下图中我们可以分析全局锁和表锁的一些加锁流程,左边红色线条是锁的生命周期,右边是 MySQL 开启可重复读事务的生命周期。
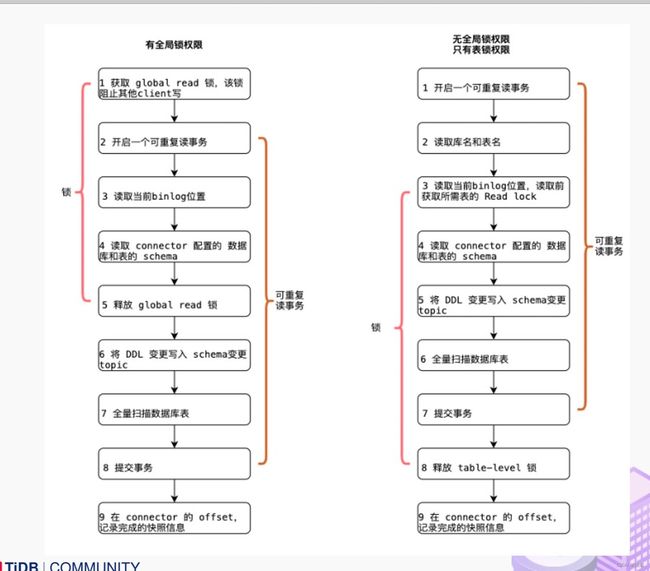
以全局锁为例,首先是获取一个锁,然后再去开启可重复读的事务。这里锁住操作是读取 binlog 的起始位置和当前表的 schema。这样做的目的是保证 binlog 的起始位置和读取到的当前 schema 是可以对应上的,因为表的 schema 是会改变的,比如如删除列或者增加列。在读取这两个信息后,SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成后,会启动 BinlogReader 从读取的 binlog 起始位置开始增量读取,从而保证全量数据 + 增量数据的无缝衔接。
表锁是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户只有表锁。表锁锁的时间会更长。经过上面分析,接下来看看这些锁到底会造成怎样严重的后果:

Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,但存在上述 hang 住数据的风险。
3.3 Flink CDC 2.0 设计 ( 以 MySQL 为例)
通过上面的分析,可以知道 2.0 的设计方案,核心要解决上述的三个问题,即支持无锁、水平扩展、checkpoint。
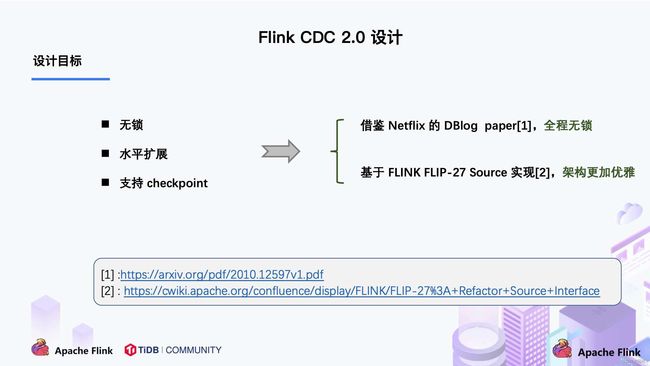
在对于有主键的表做初始化模式,整体的流程主要分为 5 个阶段:
1.Chunk 切分;
2.Chunk 分配;(实现并行读取数据&CheckPoint)
3.Chunk 读取;(实现无锁读取)
4.Chunk 汇报;
5.Chunk 分配。

DBlog 这篇论文里描述的无锁算法如下图所示:
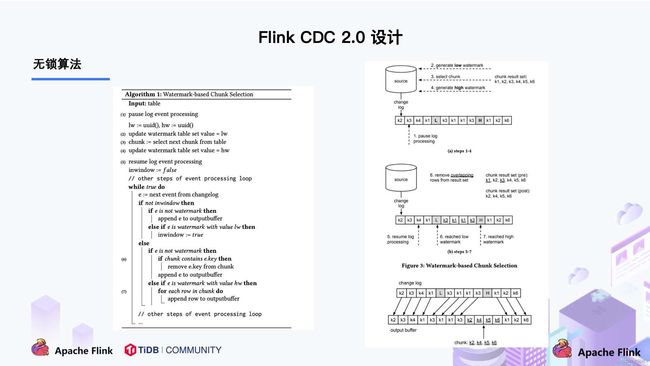
左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。Chunk 的切分如下图所示:
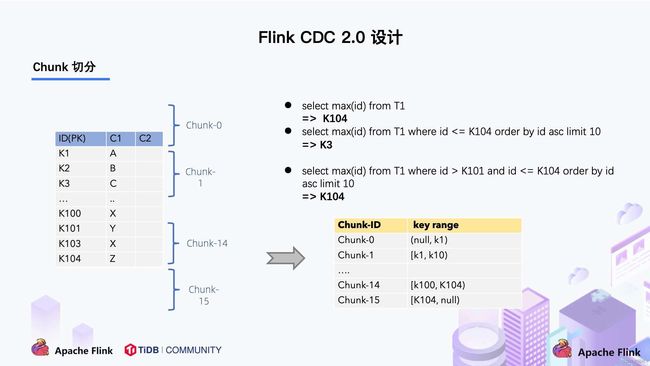
因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
根据 Netflix DBlog 的论文中的无锁算法原理,对于目标表按照主键进行数据分片,设置每个切片的区间为左闭右开或者左开右闭来保证数据的连续性。
Netflix 的 DBLog 论文中 Chunk 读取算法是通过在 DB 维护一张信号表,再通过信号表在 binlog 文件中打点,记录每个 chunk 读取前的 Low Position (低位点) 和读取结束之后 High Position (高位点) ,在低位点和高位点之间去查询该 Chunk 的全量数据。在读取出这一部分 Chunk 的数据之后,再将这 2 个位点之间的 binlog 增量数据合并到 chunk 所属的全量数据,从而得到高位点时刻,该 chunk 对应的全量数据。
Flink CDC 结合自身的情况,在 Chunk 读取算法上做了去信号表的改进,不需要额外维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能,整体的 chunk 读算法描述如下图所示:

比如正在读取 Chunk-1,Chunk 的区间是 [K1, K10],首先直接将该区间内的数据 select 出来并把它存在 buffer 中,在 select 之前记录 binlog 的一个位点 (低位点),select 完成后记录 binlog 的一个位点 (高位点)。然后开始增量部分,消费从低位点到高位点的 binlog。
图中的 - ( k2,100 ) + ( k2,108 ) 记录表示这条数据的值从 100 更新到 108;
第二条记录是删除 k3;
第三条记录是更新 k2 为 119;
第四条记录是 k5 的数据由原来的 77 变更为 100。
观察图片中右下角最终的输出,会发现在消费该 chunk 的 binlog 时,出现的 key 是k2、k3、k5,我们前往 buffer 将这些 key 做标记。
对于 k1、k4、k6、k7 来说,在高位点读取完毕之后,这些记录没有变化过,所以这些数据是可以直接输出的;
对于改变过的数据,则需要将增量的数据合并到全量的数据中,只保留合并后的最终数据。例如,k2 最终的结果是 119 ,那么只需要输出 +(k2,119),而不需要中间发生过改变的数据。
通过这种方式,Chunk 最终的输出就是在高位点是 chunk 中最新的数据。
读取可以分为 5 个阶段
1)SourceReader 读取表数据之前先记录当前的 Binlog 位置信息记为低位点;
2)SourceReader 将自身区间内的数据查询出来并放置在 buffer 中;
3)查询完成之后记录当前的 Binlog 位置信息记为高位点;
4)在增量部分消费从低位点到高位点的 Binlog;
5)根据主键,对 buffer 中的数据进行修正并输出。
通过以上5个阶段可以保证每个Chunk最终的输出就是在高位点时该Chunk中最新的数据,
但是目前只是做到了保证单个 Chunk 中的数据一致性。
上图描述的是单个 Chunk 的一致性读,但是如果有多个表分了很多不同的 Chunk,且这些 Chunk 分发到了不同的 task 中,那么如何分发 Chunk 并保证全局一致性读呢?这个其实就是通过下面的汇总来实现的
通过下图可以看到有 SourceEnumerator 的组件,这个组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 我们能较为方便地做到 chunk 粒度的 checkpoint。

将划分好的 Chunk 分发给多个 SourceReader,每个 SourceReader 读取表中的一部分数据,实现了并行读取的目标。同时在每个 Chunk 读取的时候可以单独做 CheckPoint,某个 Chunk 读取失败只需要单独执行该 Chunk 的任务,而不需要像 1.x 中失败了只能从头读取。若每个 SourceReader 保证了数据一致性,则全表就保证了数据一致性。

当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。

整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:

Flink CDC 是一个完全开源的项目,项目所有设计和源码目前都已贡献到开源社区,Flink CDC 2.0 也已经正式发布,此次的核心改进和提升包括:
提供 MySQL CDC 2.0,核心feature 包括
并发读取,全量数据的读取性能可以水平扩展;
全程无锁,不对线上业务产生锁的风险;
断点续传,支持全量阶段的 checkpoint。
搭建文档网站,提供多版本文档支持,文档支持关键词搜索
笔者用 TPC-DS 数据集中的 customer 表进行了测试,Flink 版本是 1.13.1,customer 表的数据量是 6500 万条,Source 并发为 8,全量读取阶段:
MySQL CDC 2.0 用时 13 分钟;
MySQL CDC 1.4 用时 89 分钟;
读取性能提升 6.8 倍。
3.4 核心原理分析
3.4.1 Binlog Chunk 中开始读取位置源码
MySqlHybridSplitAssigner类的createBinlogSplit方法
private MySqlBinlogSplit createBinlogSplit() {
final List assignedSnapshotSplit =
snapshotSplitAssigner.getAssignedSplits().values().stream()
.sorted(Comparator.comparing(MySqlSplit::splitId))
.collect(Collectors.toList());
Map splitFinishedOffsets =
snapshotSplitAssigner.getSplitFinishedOffsets();
final List finishedSnapshotSplitInfos = new ArrayList<>();
final Map tableSchemas = new HashMap<>();
BinlogOffset minBinlogOffset = BinlogOffset.INITIAL_OFFSET;
for (MySqlSnapshotSplit split : assignedSnapshotSplit) {
// find the min binlog offset
BinlogOffset binlogOffset = splitFinishedOffsets.get(split.splitId());
if (binlogOffset.compareTo(minBinlogOffset) < 0) {
minBinlogOffset = binlogOffset;
}
finishedSnapshotSplitInfos.add(
new FinishedSnapshotSplitInfo(
split.getTableId(),
split.splitId(),
split.getSplitStart(),
split.getSplitEnd(),
binlogOffset));
tableSchemas.putAll(split.getTableSchemas());
}
final MySqlSnapshotSplit lastSnapshotSplit =
assignedSnapshotSplit.get(assignedSnapshotSplit.size() - 1).asSnapshotSplit();
return new MySqlBinlogSplit(
BINLOG_SPLIT_ID,
lastSnapshotSplit.getSplitKeyType(),
minBinlogOffset,
BinlogOffset.NO_STOPPING_OFFSET,
finishedSnapshotSplitInfos,
tableSchemas);
} 3.4.2 读取低位点到高位点之间的 Binlog
BinlogSplitReader类的shouldEmit方法
/**
* Returns the record should emit or not.
*
* The watermark signal algorithm is the binlog split reader only sends the binlog event
that
* belongs to its finished snapshot splits. For each snapshot split, the binlog event is valid
* since the offset is after its high watermark.
*
*
E.g: the data input is :
* snapshot-split-0 info : [0, 1024) highWatermark0
* snapshot-split-1 info : [1024, 2048) highWatermark1
* the data output is:
* only the binlog event belong to [0, 1024) and offset is after highWatermark0
should send,
* only the binlog event belong to [1024, 2048) and offset is after highWatermark1 should
send.
*
*/
private boolean shouldEmit(SourceRecord sourceRecord) {
if (isDataChangeRecord(sourceRecord)) {
TableId tableId = getTableId(sourceRecord);
BinlogOffset position = getBinlogPosition(sourceRecord);
// aligned, all snapshot splits of the table has reached max highWatermark
if (position.isAtOrBefore(maxSplitHighWatermarkMap.get(tableId))) {
return true;
}
Object[] key =
getSplitKey(
currentBinlogSplit.getSplitKeyType(),
sourceRecord,
statefulTaskContext.getSchemaNameAdjuster());
for (FinishedSnapshotSplitInfo splitInfo : finishedSplitsInfo.get(tableId)) {
if (RecordUtils.splitKeyRangeContains(
key, splitInfo.getSplitStart(), splitInfo.getSplitEnd())
&& position.isAtOrBefore(splitInfo.getHighWatermark())) {
return true;
}
}
// not in the monitored splits scope, do not emit
return false;
}
// always send the schema change event and signal event
// we need record them to state of Flink
return true;
}
}3.5 未来规划
关于 CDC 项目的未来规划,我们希望围绕稳定性,进阶 feature 和生态集成三个方面展开。
稳定性
通过社区的方式吸引更多的开发者,公司的开源力量提升 Flink CDC 的成熟度;
支持 Lazy Assigning。Lazy Assigning 的思路是将 chunk 先划分一批,而不是一次性进行全部划分。当前 Source Reader 对数据读取进行分片是一次性全部划分好所有 chunk,例如有 1 万个 chunk,可以先划分 1 千个 chunk,而不是一次性全部划分,在 SourceReader 读取完 1 千 chunk 后再继续划分,节约划分 chunk 的时间。
进阶 Feature
支持 Schema Evolution。这个场景是:当同步数据库的过程中,突然在表中添加了一个字段,并且希望后续同步下游系统的时候能够自动加入这个字段;
支持 Watermark Pushdown 通过 CDC 的 binlog 获取到一些心跳信息,这些心跳的信息可以作为一个 Watermark,通过这个心跳信息可以知道到这个流当前消费的一些进度;
支持 META 数据,分库分表的场景下,有可能需要元数据知道这条数据来源哪个库哪个表,在下游系统入湖入仓可以有更多的灵活操作;
整库同步:用户要同步整个数据库只需一行 SQL 语法即可完成,而不用每张表定义一个 DDL 和 query。
生态集成
集成更多上游数据库,如 Oracle,MS SqlServer。Cloudera 目前正在积极贡献 oracle-cdc connector;
在入湖层面,Hudi 和 Iceberg 写入上有一定的优化空间,例如在高 QPS 入湖的时候,数据分布有比较大的性能影响,这一点可以通过与生态打通和集成继续优化。