MySql 数据库基础概念,基本简单操作及数据类型介绍
文章目录
-
- 数据库基础
-
- 为什么需要数据库?
- 创建数据库
- mysql架构
- SQL语句分类
- 编码集
- 修改数据库属性
- 数据库备份
- 表的基本操作
-
- 存在时更新,不存在时插入
- 数据类型
-
- 日期类型
- enum和set
数据库基础
- 以特定的格式保存文件,叫做数据库,这是狭义上的概念
- 提供较为便捷的数据存取服务的软件集合,解决方案的事物,这是广义上的数据库
mysql 的本质是一个进程,client通过网络向目标机的守护进程mysqld(server)发送sql语句,目标机的守护进程执行sql操作,所以mysql是一个应用程序,其运行在操作系统之上
操作mysql内部的数据时,本质上是操作文件内容,操作文件内容需要通过cpu提供的指令。根据冯诺依曼体系,cpu只能与内存进行交互,所以文件必须被加载到内存中
那么mysqld启动时就需要对OS申请一块空间,以执行sql操作,数据库的数据远大于可以使用的空间时,mysql就需要拥有自己的内存管理策略,即数据的换入与换出
所以mysql也需要进行内存管理
为什么需要数据库?
使用文件保存数据即可,为什么需要数据库?
例子:大量的数据,如10000个IP地址,文件和数据库都能存储
问题:需要将这10000个IP中以120开头的IP修改为119,并统计修改的IP个数。
使用文件解决以上问题,需要人为的对数据进行管理
数据库的本质也是文件,其特别之处在于提供了对文件的特定操作,不需要手动管理文件中的数据。即,mysql为用户和磁盘文件之间的一层软件层,能够控制磁盘文件,以减少使用成本
特点:方便,安全,高效
只是用文件的缺点:
- 安全性问题
- 海量数据的存储与处理
- 不方便的数据控制
mysql的存储介质:
- 磁盘为主,内存为辅
连接:
mysql -h IP -P 端口 -u 用户 -p
mysql -h 127.0.0.1 -P 3306 -u root -p
-p表示输入密码
不指明IP与端口,默认都是本地与3306
mysql -u root p
在配置文件中添加port = 端口号,修改mysql服务绑定的端口号,一般建议修改,防止他人恶意攻击。默认端口号为3306
mysql是一个网络服务!是一个关系型数据库,noSql不是关系型数据库,如redis
创建数据库
创建数据库在Linux中是在做什么?
本质是在指定目录下建立一个目录,默认目录是/var/lib/mysql/。甚至可以用mkdir指令直接创建一个目录,此时在mysql中show databases也能看到该目录
通过网络服务将创建指令发送给mysql服务端,服务端接收到指令后解析指令,进行特定的操作
在mysql中,system可以执行系统命令,如system clear
创建数据库
create database 库名
删除数据库
drop databse 库名
该数据库下的文件都会被删除,谨慎操作
mysql大小写不敏感。一般数据库的命令使用大写(但是小写字母更好看懂,所以我都是使用小写)
数据库名字可以用但引号表示`库名`。加了引号,库名就能使用特殊字符
选择数据库,类比cd目录
use 库名
查看当前选择的数据库
select database()
展示
show tables展示表项,show databases展示数据库
建表后添加了两个文件,所以建表的本质是创建文件

通过查询创建语句来了解该数据库的细节信息

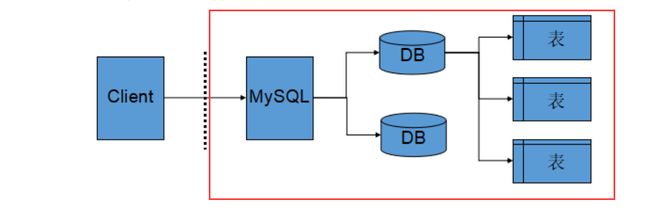
mysql架构
mysql分为三层:
- 连接层:负责客户端的连接,mysql的本质是一个应用层软件,连接层识别请求连接的IP,用来保护数据库。即通过IP地址和同户名密码保护mysql
- 语法分析层:词法语法分析,性能调优,编译级别的性能优化
- 存储引擎层:通过系统调用与磁盘打交道,插件式的存储引擎。该层有多个存储引擎,通过先描述后组织的管理方案,将存储引擎进行抽象管理。需要添加存储引擎时就创建相关结构,不需要某个存储引擎时就释放调该存储结构
站在系统的角度,mysql就是一个应用进程
站在网络的角度,mysql就是应用层协议的一种
除了mysql的客户端,其他的模块基本都是在Linux环境上运行的
SQL语句分类
- DDL(data definition language):数据定义语言,属性操作。用来维护存储数据的结构,create,drop,alter
- DML(data manipulation language):数据操纵语言,内容操作。insert,delete,update
- DQL(data query language):数据查询语言:select
以上是数据库的基本功能,接着是数据库的安全功能(临界资源,网络攻击)
- DQL(data query language):数据查询语言:select
- DCL(Data Control Language):数据控制语言,整个mysql的系统安全与账户管理工作,使mysql在主动和被动的情况下都是可靠的。grant,revoke,commit
存储引擎的查看
show engines

编码集
mysql有两个编码集,一个是编码格式集,一个是校验格式集
存数据要用到编码格式,取数据需要校验格式
通过命令查看字符集/编码集
show variables like 'character_set_%';
show variables like 'collation_database';

有些类似环境变量的查看

show variables like 'character_set_%':编码字符集的查看
show variables like 'collation_database':校验集的查看
这些值都是在conf配置文件中设置好了的
show charset:支持的字符集
show collation:支持的校验集

每个字符集都有对应的校验集,必须匹配
编码集和校验集都是针对表使用的
配置文件不指明这两集合,那么mysql也有默认方案
db.opt文件中保存的就是默认的字符集和校验集

create database 数据库名 charest=gbk collate=utf8_bin:设置字符集为gbk,校验集为utf8_bin
若数据库需要备份到远端其他机器上,则最好指明字符集与校验集,其他情况下不需要指明
创建数据库时,设置编码和校验规则,本质上是影响数据库下的表,所对应的编码和校验规则
创建表时,也能设置编码和校验规则,若不设置则会采用数据库的编码和校验规则
就近原则
查看表的列属性
desc person
查找person表的内容
select * from person
查找person表中含有a字符的数据
select * from person where name='a'
当前连接mysql的用户
show processlist
命令可以忽略大小写,但是命令的参数需要根据数据库的编码要求进行严格的大小写
utf8_general_ci:该校验集需要数据库遵守大小写
bin_db:该校验集不需要数据库遵循大小写
select database();查看当前所在的数据库,相当于pwd
修改数据库属性
修改数据库字符集
alter database 数据库名 charset=gbk
修改只是修改数据库的编码与校验集
mysql不支持修改库名,但可以用shell直接mv修改数据库名,拷贝也是同理,但这是违规的
数据库备份
查询mysqldump工具是否存在
which mysqldump
执行以下命令:
mysqldump -P 3306 -u root -p -B 库名 > db_name.sql
P标识数据库使用的端口号,u表示执行拷贝操作的用户,p表示要输入该用户的密码,B表示要拷贝的数据库名称
将数据库重定向到sql文件中,不重定向的话拷贝的数据将打印到屏幕
mysqldump -P 3306 -u root -p -B 数据库名 表名1 表名2 > db_name.sql,只备份对应的表
以此说明:mysql会保存历史输入的指令,并对指令做优化合并处理

备份有两种方式:备份数据与备份执行语句,
恢复数据库:
source .sql的绝对/相对路径
表的基本操作
建表
create table 表名(属性, 属性);

圆括号后的三个属性,若没有指明则以mysql的默认配置为主,就近原则
若创建的表名已经存在,mysql将抛出错误
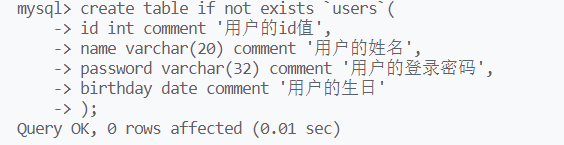
其中comment是一种类似备注的信息,这些信息将被忽略
show create table 表名\G
展示创建表时的语句,\G是mysql的一种扩展语法,不需要加;

不同引擎创建的表的逻辑结构是相同的,但是底层的物理结构却是不同的,体现在文件数量的不同,如InnoDb会创建两个文件,而MyISAM会创建三个文件
.frm:为表的列属性
.ibd:innodb中,存储表数据和索引数据的文件
.MYD:MyISAM中,存储表数据的文件
.MYI:MyISAM中,存储索引数据的文件
故MyISAM为非聚簇索引
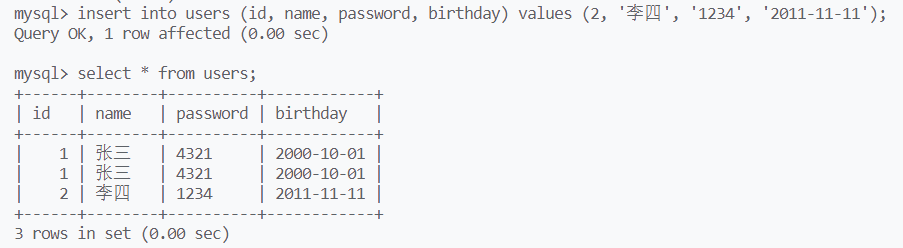
插入数据
insert into 表名 (属性, 属性) values(属性值, 属性值);
添加列属性
alter table 表名 add 属性名 属性类型 after 属性
调整列属性类型
alter table 表名 modify 属性名 要调整的数据类型
删除列属性
删除操作不应该经常使用,无论是表的删除还是库的删除
alter table 表名 drop 要删除的属性名
只剩最后一个属性时,该属性无法删除,只能使用删除表的指令进行删除
表属性的修改
alter table 表名 change 原属性名 新属性名 新属性的类型
其中image_path为原属性名称,path为新属性名称,varchar(128)表示新属性的类型
同样,这也是覆盖式的
表名的修改
alter table 旧表名 rename 新表名
表的删除
drop table 表名
表记录的删除
delete from 表名 where 属性=值
存在时更新,不存在时插入
出现主键/唯一键冲突时,插入已经存在的主键/唯一键会导致失败
在insert语句最后加上on duplicate key update 属性=值, 属性=值,表示若插入失败则更新
0 row affected:表中存在冲突数据,但冲突的数据与update数据一样,没有数据被更新
1 row affected:表中没有冲突数据,数据被插入
2 row affected:表中存在冲突数据,但数据被update更新
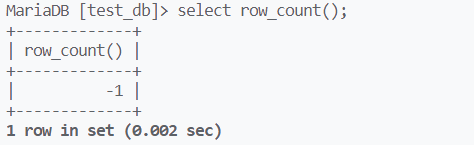
select row_count()可以查看最近一条插入语句的结果,-1表示失败,其他值与上述情况一样
在一般insert语句中,将insert换成replace也能达到同样的效果,推荐使用replace
只要存在唯一键或者主键冲突,产生冲突的记录都将被修改,可能是一条也可能是多条
数据类型
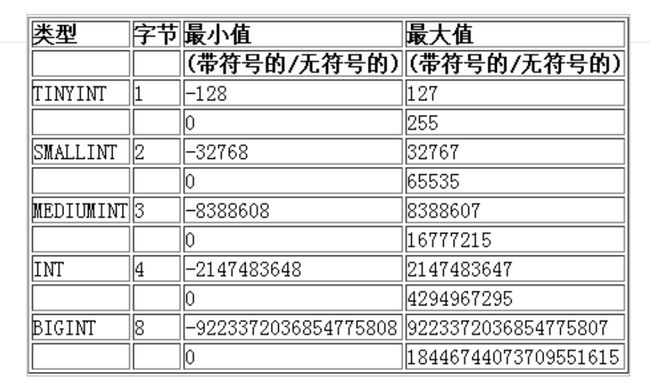
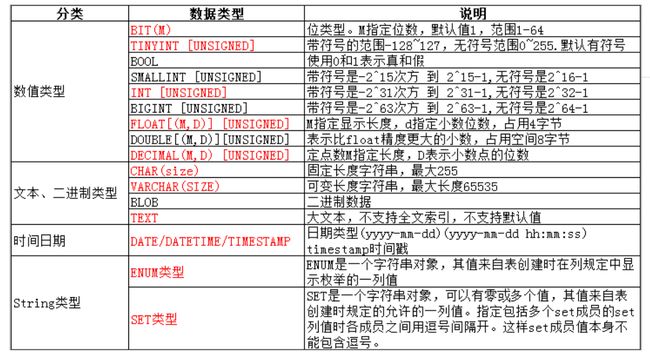 ### 数值范围
### 数值范围
mysql的数据类型除了满足不同的应用场景,还有一个特别重要的点:就是约束
tinyint:类比c语言char类型,一个字节
若插入的数据超出了数据的表达范围,那么mysql将直接报错,因为不允许这样的操作
这就倒逼程序员插入数据时,必须遵守mysql的规范
有些数据类型可以带上unsigned修饰,表示无符号
![]()

bit类型后带上(),表示该数据类型使用几个bit位,bit类型的数据以ASCII码的格式显示


可以用where这样的语句读取bit类型的数据

salary float(M, D),M表示显示长度,数字的总数,d表示小数位数

如:salary float(4,2)表示的范围是(-99.99, 99.99)

插入数据时遵守四舍五入规则

salary float(4,2) unsigned的范围是(0, 99.99),负数不允许存储
decimal(4,2),规则和float一样

decimal存储的数据精度更高,float的精度大约是7位
decimal的m最大为65,默认为10,d最大为30,默认为0
char(L):L表示字符串的长度,最多是255
mysql中的字符与字节不等价
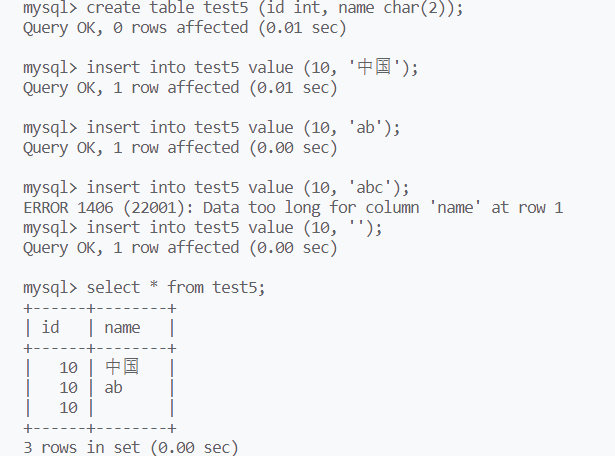
高级语言中的字符表示一个字节,而mysql的长度不是字节的意思,而是字符的意思。一个汉字虽然是一个字符,但是汉字的大小通常不是一个字节。但是在mysql中,长度为2的char可以存储两个汉字
varchar(L)的使用和char一样,其中L表示的是varchar的长度,L和表的编码有密切关系
varchar需要用1~3个字节表示存储的字符串长度,varchar的最多能存储65535字节数据,因此varchar的有效存储字节数为65532
当编码是utf8时,L的最大值为65532/3=21844,因为utf8中一个字符占3个字节。编码是gbk时,L的最大值是65532/2=32766,因为gbk中一个字符占用2个字节
变长指的是在固定长度中变长,相比于char,varchar可以有效的提高磁盘空间的使用
当长度不固定时,尽量使用变长字符串
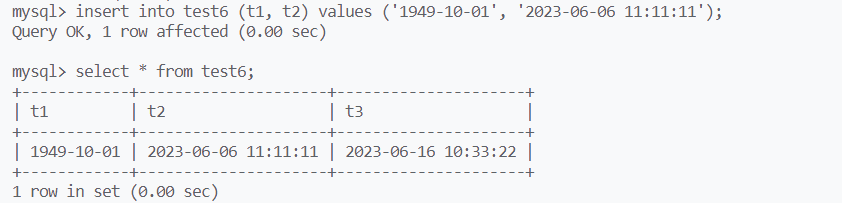
日期类型
date:yyyy-mm-dd,占用三字节
datetime:yyyy-mm-dd HH:ii:ss,占用8字节
timestamp:时间戳,格式和datetime一样,占用4字节
插入表时,无法对时间戳类型进行数据插入,时间戳的数据会在你插入(修改)的一瞬间进行更新
t1,t2,t3分别为data,datetime和timestamp类型的数据

enum和set
enum和set的约束性更强

enum多选一,set多选多
若enum为(‘男’, ‘女’),插入时可以用具体的数据,也可以用1,2,3代替具体的数据…注意从1开始
set是二进制结构的选择,因为是多选多
对于set,用where查询时,只能查询完全相同的set,比如爱好为’唱,跳’,只能查出爱好为’唱,跳’的人,'唱,跳,rap’的人则查不出
此时需要用函数find_in_set(sub, str_list):如果sub在str_list中,则返回其下标,不在返回0
select * from votes where find_in_set('rap', hobby));
select * from votes where find_in_set('rap', hobby) and find_in_set('唱', hobby));
select * from votes where find_in_set('rap', hobby) or find_in_set('唱', hobby));