方法试用:基于强化学习提高EEG分类准确率的特征选择方法(完整代码)
2023/4/19 -4/21 脑机接口学习内容一览:
这一篇文章主要建立在前文脑机接口随机森林判断睡眠类型与EEG前沿方法探索的基础上,尝试运用强化学习的方法来提高识别睡眠阶段的准确率,对前段时间强化学习的学习成果做一个总结。
一、强化学习类详解
这一部分主要详细讲述代码中强化学习类的部分,关于强化学习的相关知识可从视频吴恩达机器学习中获取。
def __init__(self, n_states, n_actions, learning_rate=0.1, discount_factor=0.9, explore_rate=0.1):
# 初始化Q表 (S, A)
self.Q = np.zeros((n_states, n_actions))
"""
学习率:
用于控制每次更新Q值时,新的Q值和旧的Q值之间的权重。
学习率越大,新的Q值对最终的Q值的影响就越大,模型的学习速度也就越快;
学习率越小,模型学习的速度就越慢。
因此,选择合适的学习率可以保证模型在训练过程中快速收敛到最优策略。
"""
self.learning_rate = learning_rate
"""
折扣因子:
用于控制未来奖励的衰减。在计算Q值时,折扣因子乘以下一个状态的最大Q值,然后加上当前状态的奖励值。
折扣因子越大,未来奖励的影响就越大,模型更加注重长期的回报。
折扣因子越小,未来奖励的影响就越小,模型更加注重即时的回报。
"""
self.discount_factor = discount_factor
"""
探索率
用于控制模型在训练过程中的“探索-利用”策略。
在训练初期,模型需要探索更多的状态空间,以寻找最优策略;
随着模型的训练,模型逐渐转向利用已有的知识。探索率越高,模型越倾向于探索新的状态,而不是利用已有的知识;
探索率越低,模型越倾向于利用已有的知识,而不是探索新的状态。
因此,选择合适的探索率可以使模型在训练过程中平衡探索和利用的策略,从而快速收敛到最优策略。
"""
self.explore_rate = explore_rate这是类的初始化函数,在这里主要获取了状态和动作的数量以及学习率、折扣因子和探索率这三个超参数。也许在这个部分你会疑惑状态和动作分别对应什么东西,但其实在对强化学习有了一点基础的了解之后就能明白,state代表现在所选取的特征序列,action则是下一个选取的单个特征。Q表的样例如下表所示,假设我们要处理0-4一共五个特征,中间一大片的空格子代表当前的state采用相应action所能得到的reward。你可能对state为何要这么排列存在疑惑,但是下文的代码会有解答。
| action\state | (0) | (1) | (0, 1) | (2) | (0, 2) | (1, 2) | ... |
| 0 | |||||||
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 |
# 选择动作
def choose_action(self, state):
# 生成一个0-1范围内的随机数
if np.random.uniform(0, 1) < self.explore_rate:
# 探索 随机选取特征
action = np.random.choice(range(self.Q.shape[1]))
else:
# 利用 选择已经选取过的、取得reward高的特征
action = np.argmax(self.Q[state, :])
return actionchoose_action函数,顾名思义是用来进行动作选择的explore_rate一般取一个比较低的值,避免不能充分利用之前的经验。
# 更新Q表
def update(self, state, action, reward, next_state):
# 当前state到action的值
q_predict = self.Q[state, action]
# 折扣因子乘以 下一个 状态的最大Q值,然后加上当前状态的奖励值
q_target = reward + self.discount_factor * np.max(self.Q[next_state, :])
self.Q[state, action] += self.learning_rate * (q_target - q_predict)该函数是Q-learning算法的核心部分,用于更新Q表中某个状态下某个动作的值。具体解释如下:
- `state`:当前状态
- `action`:当前状态下智能体选择的动作
- `reward`:智能体执行动作后得到的奖励值
- `next_state`:执行动作后智能体进入的下一个状态
首先,从Q表中获取当前状态下选择某个动作的预测值`q_predict`,即Q表中(state, action)的值。这个预测值是根据之前的学习和经验积累得到的,它代表了智能体在当前状态下执行选择某个动作的预期回报。
然后,计算目标值`q_target`,它是智能体在当前状态下选择某个动作后,预期在接下来的所有状态中得到的最大回报。具体来说,它是当前状态下的奖励值reward加上下一个状态的最大Q值(discount_factor是一个衰减系数,它控制着未来回报的重要性,使得智能体更加关注近期的奖励)。
接下来,使用差分学习的方法,将`q_target`与`q_predict`的差异乘以学习率`learning_rate`来更新Q表中相应的值。学习率控制着更新的速度,它越大则更新的幅度就越大,但可能会导致算法不稳定,它越小则更新的幅度就越小,算法越稳定。更新后的值代表了智能体在当前状态下选择某个动作的实际回报,它将被用于下一次选择动作和更新Q表。
总的来说,该函数的目标是通过不断地更新Q表中的值,使得智能体能够学习到在不同状态下选择不同动作的最优策略,从而实现智能决策。
二、特征选择类详解
# 特征选择器
class FeatureSelector:
def __init__(self, data, labels, n_features, n_episodes=1000):
self.data = data # 特征数据
self.labels = labels # 标签数据
self.n_features = n_features # 提供的特征数量
self.n_episodes = n_episodes # 训练的轮数
# 获取当前特征序列代表的状态
def get_state(self, selected_features):
"""
这个函数的意义是将已选择的特征子集转换为一个状态值,用于Q值表中的状态索引;
在实现中,它将每个特征看作二进制位上的一个数字,将已选择的特征子集转换为一个二进制数,再将其转换为十进制表示的状态值;
例如,如果已选择的特征子集为[0, 2, 3],则转换后的状态值为2^0 + 2^2 + 2^3 = 1 + 4 + 8 = 13,很显然状态值不会重复;
这个状态值将用于更新Q值表中对应状态的Q值。
"""
state_sum = 0
for i in selected_features:
state_sum += 2**i
return state_sum
# 获取奖励
def get_reward(self, selected_features):
# 分割训练集和测试集,比值为7:3,根据传入特征序列选取特征
X_train, X_test, y_train, y_test = train_test_split(self.data[:, selected_features], self.labels, test_size=0.3, random_state=0)
# 构建决策树
clf = DecisionTreeClassifier(random_state=0)
# 使用决策树训练数据
clf.fit(X_train, y_train)
# 打印测试集准确率
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy on test set: {:.2f}%".format(accuracy * 100))
"""
返回错误样本数的比例作为奖励:
可以让智能体在学习的过程中更加关注于错误分类的样本,也就是那些准确率低的样本;
这样做的目的是让智能体更加聚焦于那些难以分类的样本,并尝试找到更好的分类方法,以提高整体的分类准确率。
"""
return 1 - clf.score(X_test, y_test)
# 特征选择
def select_features(self):
n_states = 2**self.n_features # 获取特征组合数量
n_actions = self.n_features # 获取行动数量、
# 根据以上信息生成Q表
q_learning = QLearning(n_states, n_actions)
for i in range(self.n_episodes):
# 清空特征选择序列
selected_features = []
# 获取特征序列编号
state = self.get_state(selected_features)
# 当选取的特征长度小于总特征序列长度时循环
while len(selected_features) < self.n_features:
# 下一步动作为选取特征的下标
action = q_learning.choose_action(state)
# 若该特征尚未被选取
if action not in selected_features:
selected_features.append(action)
# 选取采取动作后进入的下一个状态
next_state = self.get_state(selected_features)
# 更新新特征序列的奖励
reward = self.get_reward(selected_features)
q_learning.update(state, action, reward, next_state)
state = next_state
return selected_features该类是一个特征选择器,它通过给定的特征数据和标签数据,使用Q-learning算法从中选择最佳的特征子集。它的构造函数接受四个参数:特征数据、标签数据、提供的特征数量和训练的轮数。其中,特征数据是一个二维数组,每行代表一个样本,每列代表一个特征;标签数据是一个一维数组,代表每个样本的类别标签;提供的特征数量表示要从中选择多少个特征;训练的轮数表示要进行多少次特征选择训练。
该类有三个主要的方法:get_state、get_reward和select_features。
其中,get_state方法将已选择的特征子集转换为一个状态值,用于Q值表中的状态索引(这个函数的注释就反映了上文中表格里state排列顺序的意义);
get_reward方法用于计算已选择特征子集在测试集上的分类准确率,返回错误样本数的比例作为奖励(为什么返回错误样本的比例作为reward?这一点看上去比较反直觉);
select_features方法是特征选择的主要方法,它使用Q-learning算法对所有特征进行选择,并返回最佳的特征子集。在select_features方法中,首先初始化Q值表,然后在每一轮训练中,循环选取特征直到选择的特征数量达到提供的特征数量,每次选择特征时更新Q值表,直到训练轮数达到指定值,最终返回最佳的特征子集。
三、完整代码
(一)enforcement.py
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
# Q-Learning算法
class QLearning:
def __init__(self, n_states, n_actions, learning_rate=0.1, discount_factor=0.9, explore_rate=0.1):
# 初始化Q表 (S, A)
self.Q = np.zeros((n_states, n_actions))
"""
学习率:
用于控制每次更新Q值时,新的Q值和旧的Q值之间的权重。
学习率越大,新的Q值对最终的Q值的影响就越大,模型的学习速度也就越快;
学习率越小,模型学习的速度就越慢。
因此,选择合适的学习率可以保证模型在训练过程中快速收敛到最优策略。
"""
self.learning_rate = learning_rate
"""
折扣因子:
用于控制未来奖励的衰减。在计算Q值时,折扣因子乘以下一个状态的最大Q值,然后加上当前状态的奖励值。
折扣因子越大,未来奖励的影响就越大,模型更加注重长期的回报。
折扣因子越小,未来奖励的影响就越小,模型更加注重即时的回报。
"""
self.discount_factor = discount_factor
"""
探索率
用于控制模型在训练过程中的“探索-利用”策略。
在训练初期,模型需要探索更多的状态空间,以寻找最优策略;
随着模型的训练,模型逐渐转向利用已有的知识。探索率越高,模型越倾向于探索新的状态,而不是利用已有的知识;
探索率越低,模型越倾向于利用已有的知识,而不是探索新的状态。
因此,选择合适的探索率可以使模型在训练过程中平衡探索和利用的策略,从而快速收敛到最优策略。
"""
self.explore_rate = explore_rate
# 选择动作
def choose_action(self, state):
# 生成一个0-1范围内的随机数
if np.random.uniform(0, 1) < self.explore_rate:
# 探索 随机选取特征
action = np.random.choice(range(self.Q.shape[1]))
else:
# 利用 选择已经选取过的、取得reward高的特征
action = np.argmax(self.Q[state, :])
return action
# 更新Q表
def update(self, state, action, reward, next_state):
# 当前state到action的值
q_predict = self.Q[state, action]
# 折扣因子乘以 下一个 状态的最大Q值,然后加上当前状态的奖励值
q_target = reward + self.discount_factor * np.max(self.Q[next_state, :])
self.Q[state, action] += self.learning_rate * (q_target - q_predict)
# 特征选择器
class FeatureSelector:
def __init__(self, data, labels, n_features, n_episodes=1000):
self.data = data # 特征数据
self.labels = labels # 标签数据
self.n_features = n_features # 提供的特征数量
self.n_episodes = n_episodes # 训练的轮数
# 获取当前特征序列代表的状态
def get_state(self, selected_features):
"""
这个函数的意义是将已选择的特征子集转换为一个状态值,用于Q值表中的状态索引;
在实现中,它将每个特征看作二进制位上的一个数字,将已选择的特征子集转换为一个二进制数,再将其转换为十进制表示的状态值;
例如,如果已选择的特征子集为[0, 2, 3],则转换后的状态值为2^0 + 2^2 + 2^3 = 1 + 4 + 8 = 13,很显然状态值不会重复;
这个状态值将用于更新Q值表中对应状态的Q值。
"""
state_sum = 0
for i in selected_features:
state_sum += 2**i
return state_sum
# 获取奖励
def get_reward(self, selected_features, episodes):
# 分割训练集和测试集,比值为7:3,根据传入特征序列选取特征
X_train, X_test, y_train, y_test = train_test_split(self.data[:, selected_features], self.labels, test_size=0.3,
random_state=0)
# 构建决策树
clf = RandomForestClassifier(n_estimators=200, random_state=20)
# 使用决策树训练数据
clf.fit(X_train, y_train)
# 打印测试集准确率
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
if episodes % 10 == 0:
print("Accuracy on test set: {:.2f}%".format(accuracy * 100))
"""
返回错误样本数的比例作为奖励:
可以让智能体在学习的过程中更加关注于错误分类的样本,也就是那些准确率低的样本;
这样做的目的是让智能体更加聚焦于那些难以分类的样本,并尝试找到更好的分类方法,以提高整体的分类准确率。
"""
return 1 - clf.score(X_test, y_test)
# 特征选择
def select_features(self):
n_states = 2**self.n_features # 获取特征组合数量
n_actions = self.n_features # 获取行动数量、
# 根据以上信息生成Q表
q_learning = QLearning(n_states, n_actions)
for i in range(self.n_episodes):
# 清空特征选择序列
selected_features = []
# 获取特征序列编号
state = self.get_state(selected_features)
# 当选取的特征长度小于总特征序列长度时循环
while len(selected_features) < self.n_features:
# 下一步动作为选取特征的下标
action = q_learning.choose_action(state)
# 若该特征尚未被选取
if action not in selected_features:
selected_features.append(action)
# 选取采取动作后进入的下一个状态
next_state = self.get_state(selected_features)
# 更新新特征序列的奖励
reward = self.get_reward(selected_features, i)
q_learning.update(state, action, reward, next_state)
state = next_state
return selected_features(二)main.py
import numpy as np
import matplotlib.pyplot as plt
import mne
from mne.datasets.sleep_physionet.age import fetch_data
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import FunctionTransformer
import enforcement
"""
可以通过
mne.datasets.sleep_physionet.age.fetch_data(subjects,recording,path)
来获取PhysioNet多导睡眠图数据集文件。
返回一个list
subjects:表示想要使用哪些受试者对象,可供选择的受试者对象范围为0-19。
recording:表示夜间记录的编号(索引),有效值为:[1]、[2]或[1、2]。
path:PhysioNet数据的存放地址,如果没有给定,则加载默认存放数据的地址;
如果默认存放数据集的地址不存在数据,则从网络中下载相关数据。
"""
# 选择两个受试者实验对象ALICE, BOB(该名字并非实验中的真实名,这里是为了方便才临时取的名字)
# 将0,1赋值给两个名称变量
ALICE, BOB = 0, 1
# 加载ALICE, BOB的实验数据文件,返回本地数据的路径列表
[alice_files, bob_files] = fetch_data(subjects=[ALICE, BOB], recording=[1], path='data')
# 通道名称映射
mapping = {'EOG horizontal': 'eog',
'Resp oro-nasal': 'misc',
'EMG submental': 'misc',
'Temp rectal': 'misc',
'Event marker': 'misc'}
# 读取ALICE的edf文件,和其对应的注释文件
raw_train = mne.io.read_raw_edf(alice_files[0])
annot_train = mne.read_annotations(alice_files[1])
raw_train.plot()
# 设定注释且不在裁剪时发出警报
raw_train.set_annotations(annot_train, emit_warning=False)
raw_train.set_channel_types(mapping)
# 绘制空0s开始,时间窗口长度为40s的连续通道数据波形图
'''
raw_train.plot(duration=40, scalings='auto')
plt.show()
'''
"""
睡眠表示与事件映射
"""
annotation_desc_2_event_id = {'Sleep stage W': 1,
'Sleep stage 1': 2,
'Sleep stage 2': 3,
'Sleep stage 3': 4,
'Sleep stage 4': 4,
'Sleep stage R': 5}
print(raw_train)
events_train, _ = mne.events_from_annotations(
raw_train, event_id=annotation_desc_2_event_id, chunk_duration=30.)
# 创建一个新的event_id以统一 阶段3和4
event_id = {'Sleep stage W': 1,
'Sleep stage 1': 2,
'Sleep stage 2': 3,
'Sleep stage 3/4': 4,
'Sleep stage R': 5}
# 绘制事件数据
mne.viz.plot_events(events_train, event_id=event_id)
# 保留颜色代码以便进一步绘制
stage_colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
tmax = 30. - 1. / raw_train.info['sfreq'] # tmax in included
print('this is sfreq here')
print(raw_train.info['sfreq'])
"""
所创建的是时间从tmin=0开始,到tmax为止的epochs
"""
epochs_train = mne.Epochs(raw=raw_train, events=events_train,
event_id=event_id, tmin=0., tmax=tmax, baseline=None, preload=True)
print('this is times here')
print(len(epochs_train))
'''
加载Bob的数据作为测试数据,与前面内容类同
'''
raw_test = mne.io.read_raw_edf(bob_files[0])
annot_test = mne.read_annotations(bob_files[1])
raw_test.set_annotations(annot_test, emit_warning=False)
raw_test.set_channel_types(mapping)
events_test, _ = mne.events_from_annotations(
raw_test, event_id=annotation_desc_2_event_id, chunk_duration=30.)
epochs_test = mne.Epochs(raw=raw_test, events=events_test, event_id=event_id,
tmin=0., tmax=tmax, baseline=None)
# print(epochs_test)
'''
特征工程:基于特定频带中的相对功率来创建EEG特征,以捕获数据中睡眠阶段之间的差异
'''
# 创建一个1*2的画窗(包括两个坐标系ax1,ax2)
fig, (ax1, ax2) = plt.subplots(ncols=2)
# iterate over the subjects
# 将event_id的key值(可迭代)进行排序形成一个stages列表用于遍历,sorted对所有可迭代数据进行排序
stages = sorted(event_id.keys())
for ax, title, epochs in zip([ax1, ax2],
['Alice', 'Bob'],
[epochs_train, epochs_test]):
for stage, color in zip(stages, stage_colors):
epochs[stage].plot_psd(area_mode=None, color=color, ax=ax,
fmin=0.1, fmax=20., show=False,
average=True, spatial_colors=False)
ax.set(title=title, xlabel='Frequency (Hz)')
ax2.set(ylabel='uV^2/hz (dB)')
ax2.legend(ax2.lines[2::3], stages)
plt.tight_layout()
plt.show()
'''
设计scikit-learn转换器
'''
def eeg_power_band(epochs):
"""脑电相对功率带特征提取
该函数接受一个""mne.Epochs"对象,
并基于与scikit-learn兼容的特定频带中的相对功率创建EEG特征。
Parameters
----------
epochs : Epochs
The data.
Returns
-------
X : numpy array of shape [n_samples, 5]
Transformed data.
"""
# 特定频带
FREQ_BANDS = {"delta": [0.5, 4.5],
"theta": [4.5, 8.5],
"alpha": [8.5, 11.5],
"sigma": [11.5, 15.5],
"beta": [15.5, 30]}
# psds, freqs = psd_welch(epochs, picks='eeg', fmin=0.5, fmax=30.)
spectrum = epochs.compute_psd(method='welch', picks='eeg', fmin=0.5, fmax=30.)
psds = spectrum.get_data()
print("this is psds")
print(psds.shape)
print(psds)
freqs = spectrum.freqs
print("this is freqs")
print(freqs.shape)
print(freqs)
# 归一化 PSDs
psds /= np.sum(psds, axis=-1, keepdims=True)
X = []
for fmin, fmax in FREQ_BANDS.values():
psds_band = psds[:, :, (freqs >= fmin) & (freqs < fmax)].mean(axis=-1)
print("this is psds_band")
print(psds_band.shape)
print(psds_band)
X.append(psds_band.reshape(len(psds), -1))
print('this is X')
# print(X.shape)
k = np.concatenate(X, axis=1)
print(k.shape)
return np.concatenate(X, axis=1)
# 特征数量
data = eeg_power_band(epochs_train)
test_data = eeg_power_band(epochs_test)
y_train = epochs_train.events[:, 2]
y_test = epochs_test.events[:, 2]
n_features = data.shape[1]
# 特征选择
feature_selector = enforcement.FeatureSelector(data, y_train, n_features)
selected_features = feature_selector.select_features()
# 输出选择的特征 Selected features: [6, 0, 3, 7, 8, 5, 2, 9, 4, 1]
print('Selected features:', selected_features)
X_test = test_data[:, selected_features]
# 构建决策树
clf = RandomForestClassifier(n_estimators=200, random_state=20)
# 使用决策树训练数据
clf.fit(data[:, selected_features], y_train)
# 打印测试集准确率
y_pred = clf.predict(X_test)
# 评估准确率
acc = accuracy_score(y_test, y_pred)
print("Accuracy score: {}".format(acc))
print(classification_report(y_test, y_pred, target_names=event_id.keys()))tip.以上代码是从测试验证的代码临时改的,末尾可能会有点错误。代码运行时间较长,想快点可以修改 enforcement.py 中的epidodes参数。
四、结果展示与思考
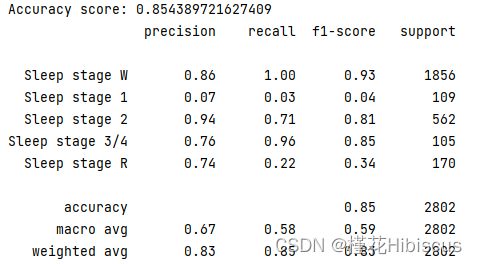 图1 强化学习选取特征后测试集的准确率
图1 强化学习选取特征后测试集的准确率
 图2 全部特征用于训练和预测后测试集的准确率
图2 全部特征用于训练和预测后测试集的准确率
实验获取的最终结果如上图所示。让一开始看到结果的我以及读者可能有点绷不住的是,强化学习在特征选取方面的应用似乎让人看不到其优越性,准确率不增反降。然而不完全是这样,接下来我们会对这个结果展开分析,剖析强化学习在特征选取方面的优点和缺点:
(一)优势
准确率方面:看起来本次实验中强化学习的准确率与选取全部特征的准确率基本相等,并且选取的特征就是已有的全部特征(在特征选取部分我们最终就是会选取所有特征,只不过有个先后问题)。事实上当前数据集可能已经经过一部分的预处理操作,也就是数据集的质量较好。这说明强化学习所得到的特征选取结果在一定意义上可能是可靠的,之后还需要进行进一步确定。
除此之外,根据强化学习按顺序选取最优解的特性(这里不知道怎么讲好,只能说在现存的特征集合上如果加入一个特征,该特征应该是剩余所有特征中加入特征集合对正确率最有利的一个),在此我们将所选取特征的末尾部分一步步拿走,用以证明强化学习所选取的特征集合在一定程度上反映了特征集合子集的重要性。
证明过程如下,第一部分图为从最后一个特征开始从后往前拿走特征,第二部分为从第一个开始从前往后拿走特征。若假设准确,则试验1所得准确率应先上升再下降,试验2所得准确率基本一直下降。
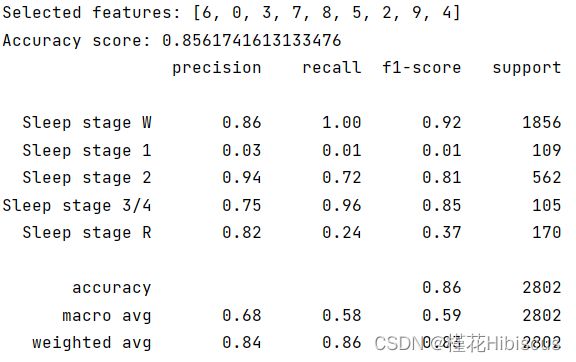



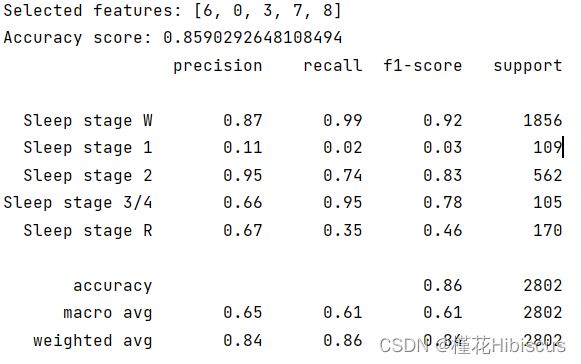
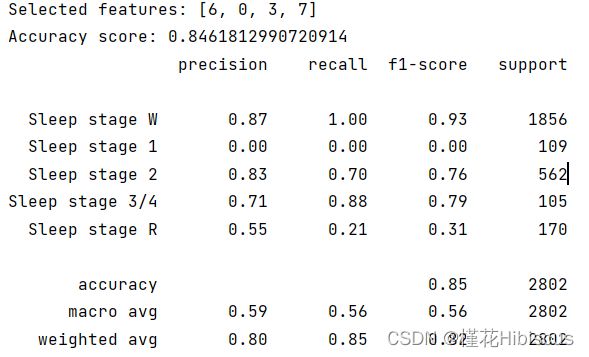


以上为试验1部分。








以上为试验2部分。
我们可以看到试验的结果基本符合预期,但细想试验步骤还是有很多不合理的地方,要证明该假设还需要进一步验证。在询问chatgpt后得到以下结果(因为国内相关资料较少):
Q:使用强化学习进行特征选择的意义
A:强化学习可以帮助我们在特征选择中找到最优的特征组合,从而提高模型的准确性和效率。与传统的特征选择方法相比,强化学习不仅考虑了各个特征之间的相互作用,还可以动态地调整特征组合以适应不同的数据集和任务要求。此外,强化学习还可以自动化地进行特征选择,减少了人工干预的成本和误差,提高了实验效率和可重复性。因此,使用强化学习进行特征选择具有很大的意义。
这可以进一步说明假设的可信度。
(二)存在问题
时间复杂度:在本次实验中强化学习训练的时间粗略计算在30到40分钟左右,既然我的目的是得到最优的特征组合,那么我为何不直接使用穷举呢?这可能还会快一点。当然这个问题也可能是因为episodes设置过大。
接下来是gpt环节:
Q:使用强化学习进行特征选择的问题
A:1. 状态空间的复杂性:特征选择问题中的状态空间通常非常庞大,可能会导致强化学习算法的计算复杂度过高,甚至无法收敛。
2. 动作空间的限制:特征选择问题中的动作空间通常受到特征数量和特征类型的限制,可能会限制强化学习算法的搜索能力。
3. 奖励函数的设计:特征选择问题中的奖励函数设计可能比较复杂,需要考虑到模型的准确性、效率、泛化能力等多个因素,可能会影响到强化学习算法的性能。
4. 数据集的质量:特征选择问题的结果很大程度上取决于数据集的质量,如果数据集不够完备、不够准确,甚至存在噪声和缺失值,可能会影响到强化学习算法的效果。 因此,在使用强化学习进行特征选择时,需要综合考虑这些问题,选择合适的算法和参数设置,以获得最佳的特征选择结果。
关于动作空间的限制问题我深以为然。在普通的强化学习任务中,实体的动作空间基本是不受限制的,但是在特征选择任务中就不是这样。这么说可能有点抽象,我们举个例子:在马里奥这个游戏中,不管人物处在哪个位置,左右键和起跳键始终可以按下,而特征选择中的“马里奥”,在按下一个键之后就不能再重复“按下”(即选择)该按键了,这就表明,除非特征之间的排列顺序对预测的结果会有所影响,否则强化学习的优势相对于其他方法并不是很大。
学艺不精,接下来争取多看一些相关方面的资料和论文,进一步解答我的疑问。