Hello, hello everybody! I hope you all are enjoying a nice Labor Day weekend. I personally took Friday off as well to extend my weekend into four days, and I had a lot of great quality time with my daughters these last few days. But you know me, I’m always itching to keep producing in some capacity!
您好,大家好! 希望大家度过一个愉快的劳动节周末。 我也亲自休假,将周末延长为四天,最近几天我和女儿度过了很多美好的时光。 但是您知道我,我总是渴望保持某种生产能力!
Before we get into the post, please be sure to reference my personal GitHub for all the code we’ll get into below. It’s pretty simple, but if you’d like to follow along in a concise Jupyter notebook, then I’d encourage you to check that out. For brevity’s sake, I’m not going to go into what one-hot encoding is in this post and instead encourage you to check out a former post of mine where I go into that more thoroughly.
在我们发表这篇文章之前,请确保参考我个人的GitHub ,以获取下面将要涉及的所有代码。 这很简单,但是如果您想使用简洁的Jupyter笔记本,那么我建议您检查一下。 为了简洁起见,我不会讨论这篇文章中的“热门编码”,而是鼓励您查看我的前一篇文章,在此我将对其进行更彻底的探讨。
Alrighty, so when I first learned about one-hot encoding, I was curiously taught one way that I would argue is the “wrong” thing to do for the data science field. It’s not that it doesn’t work to produce encoded features, but it doesn’t go far enough for applied machine learning. And it feels like I keep seeing this particular method over and over in all the tutorials I’ve come across.
好吧,所以当我第一次学习单编码时,我被好奇地教给我一种方法,我认为这是在数据科学领域要做的“错误”事情。 并不是说它不能产生编码特征,但是对于应用机器学习来说,它还远远不够。 感觉就像我在所遇到的所有教程中一遍又一遍地看到这种特定方法。
That incorrect way? Pandas’ “get_dummies” function.
那不正确的方式? 熊猫的“ get_dummies”功能。
To demonstrate why NOT to use Pandas’ “get_dummies” and why to use the other options I’ll recommend, let’s first quickly setup our project by importing the necessary Python libraries as well as creating a tiny DataFrame with fake animal data. (I’ll explain what we’re importing down below and how to install the second option if you haven’t installed it before.)
为了演示为什么不使用Pandas的“ get_dummies”以及为什么要使用我建议的其他选项,我们首先通过导入必要的Python库以及使用伪造的动物数据创建一个微小的DataFrame来快速设置项目。 (我将在下面解释我们要导入的内容,以及如果您以前没有安装过第二个选项,则如何安装它。)
# Importing the required libraries
import pandas as pd
import joblib
from sklearn import preprocessing
from category_encoders import one_hot# Creating a small DataFrame with fake animal data
animals_df = pd.DataFrame({'animal': ['cat', 'dog', 'bird', 'monkey', 'elephant', 'cat', 'bird']})As you can see, I intentionally duplicated a few values to demonstrate that our encoding will work. With our DataFrame in place, let’s go ahead and see what happens when we use the basic Pandas “get_dummies” function.
如您所见,我特意复制了一些值以证明我们的编码将起作用。 使用我们的DataFrame,让我们继续来看一下使用基本的熊猫“ get_dummies”函数时会发生什么。
# Performing one-hot encoding with Pandas' "get_dummies" function
pandas_dummies = pd.get_dummies(animals_df['animal'])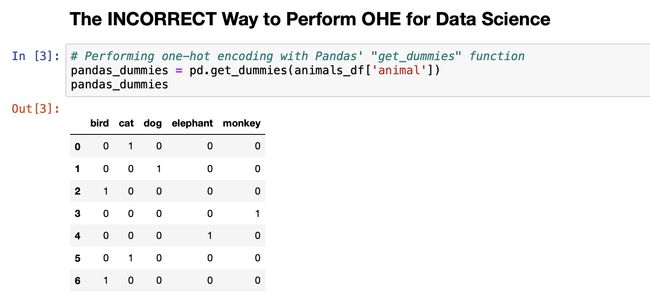
You might be wondering, what’s the problem? Didn’t this do the trick for us? While it did work in this very specific instance, this method does NOT allow for future transformation in an inference pipeline. Just like we export a model or data scaler for inference transformation, there are means to export something to perform consistent one-hot encoding. Unfortunately, Pandas “get_dummies” does not allow for this. (Why this is not taught better in more data science courses is baffling to me!)
您可能想知道,这是什么问题? 这不是对我们有用吗? 虽然在这个特定的实例做工作,这种方法不允许在管道推断未来转型。 就像我们导出模型或数据缩放器以进行推理转换一样,也存在导出某些内容以执行一致的一键编码的方法 。 不幸的是,熊猫“ get_dummies”不允许这样做。 (为什么在更多的数据科学课程中没有更好地教授这一点,这让我感到困惑!)
Fortunately, there are ways to get around this, and I’m about to show you two of them!
幸运的是,有很多方法可以解决这个问题,我将向您展示其中两个!
The first correct way is built right into Scikit-Learn. Just like any of the ML algorithms, there’s a piece of the Scikit-Learn library called OneHotEncoder that allows you to fit your data to an instantiated encoder object and then later transform similar data to appropriately fill all the columns as required.
第一个正确的方法直接内置于Scikit-Learn中。 就像任何ML算法一样,还有一个名为OneHotEncoder的Scikit-Learn库,该库允许您将数据拟合到实例化的编码器对象,然后再转换相似的数据以根据需要适当填充所有列。
But here’s the thing… I’m not wild about Scikit-Learn’s implementation of this. It works and is technically correct, but it’s a tiny bit… kludgy? See for yourself in the code below.
但这就是问题……我对Scikit-Learn对此的实现并不陌生。 它可以正常工作并且在技术上是正确的,但是有点……笨拙? 自己看下面的代码。
# Instantiating the Scikit-Learn OHE object
sklearn_ohe = preprocessing.OneHotEncoder()# Fitting the animals DataFrame to the Scikit-Learn one-hot encoder
sklearn_dummies = sklearn_ohe.fit_transform(animals_df)# Using the output dummies and transformer categories to produce a cleaner looking dataframe
sklearn_dummies_df = pd.DataFrame(data = sklearn_dummies.toarray(),
columns = sklearn_ohe.categories_)# Dumping the transformer to an external pickle file
joblib.dump(sklearn_ohe, 'sklearn_ohe.pkl')
As you can see in the Jupyter screenshot, the direct output of a transformed DataFrame is NOT a DataFrame. It’s actually a sparse matrix of float values. It is indeed possible to produce a DataFrame with that output, but it requires a little extra work. Not impossible, but also not intuitive. The first time I learned this, it took me several hours to wrap my brain around the output. Additionally, it produces float values in the result as opposed to integer values from the original dataset, which isn’t exactly expected behavior. But again, that can be altered, so we can still call this one correct method.
如您在Jupyter屏幕截图中所见,转换后的DataFrame的直接输出不是DataFrame。 实际上,它是一个浮点值的稀疏矩阵。 确实可以用该输出生成一个DataFrame,但是需要一些额外的工作。 并非没有,但也不直观。 第一次学习该知识时,我花了几个小时将自己的大脑包裹在输出上。 此外,它会在结果中产生浮点值,而不是原始数据集中的整数值,这并不是完全预期的行为。 但是,这可以更改,因此我们仍然可以将此方法称为正确方法。
The second correct way to perform one-hot encoding is by using a special Python library called Category Encoders. If you haven’t used it before, all you have to do is a quick pip or conda install. For your convenience, I’ve pasted the respective shell commands to do so down below.
执行单点编码的第二种正确方法是使用一个名为Category Encoders的特殊Python库 。 如果您以前从未使用过它,那么您所要做的就是快速安装pip或conda。 为了方便起见,我在下面粘贴了相应的shell命令。
pip install category_encodersconda install -c conda-forge category_encodersI was actually introduced to this library by some of my fellow data scientists in my day job, and I personally like it a lot better than Scikit-Learn’s implementation. I think it’s pretty evident why in the code below. Here’s the specific documentation about Category Encoder’s version of the OneHotEncoder, too.
我的一些日常数据科学家实际上是将我介绍给该库的,我个人比较喜欢Scikit-Learn的实现。 我认为以下代码中的原因非常明显。 这也是有关类别编码器的OneHotEncoder版本的特定文档 。
# Instantiating the Category Encoders OHE object
ce_ohe = one_hot.OneHotEncoder(use_cat_names = True)# Fitting the animals DataFrame to the Category Encoders one-hot encoder
ce_dummies = ce_ohe.fit_transform(animals_df)# Dumping the transformer to an external pickle file
joblib.dump(ce_ohe, 'ce_ohe.pkl')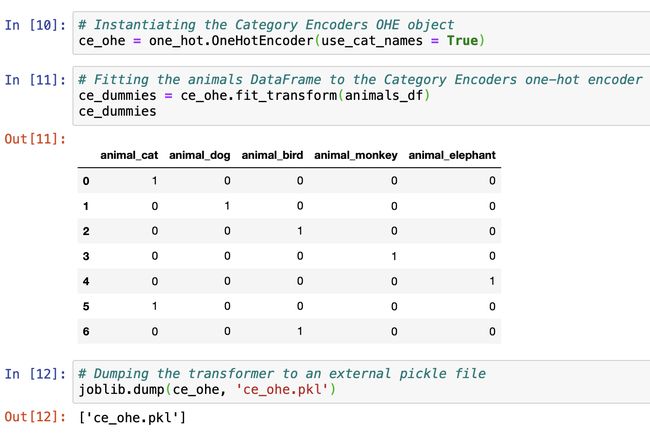
As you can see, the output of fitting the data to the transformer produces a nice, clean DataFrame. Additionally, it appends the original “animal” column name with the value from the column to produce clean column names. Now, I actually think this is a better implementation because when you start one-hot encoding multiple features, it’s nice to know in the output from which feature they were originally sourced!
如您所见,将数据拟合到转换器的输出产生了一个很好的,干净的DataFrame。 此外,它将原始“动物”列名称附加该列中的值以产生干净的列名称。 现在,我实际上认为这是一个更好的实现,因为当您开始对多个功能进行一次热编码时,很高兴在输出中知道它们最初来自哪个功能!
(If there’s *any* downside at all, the dumped pickle file for Scikit-Learn’s implementation is a lot small, but the size is almost negligible. We’re talking bytes versus kilobytes here, which is almost nothing these days, but I feel like I still gotta share that with y’all.)
(如果根本没有任何缺点,则用于Scikit-Learn的实现的转储泡菜文件很小,但大小几乎可以忽略不计。这里我们谈论的是字节还是千字节,这几天几乎没什么用,但是我觉得就像我还是要和大家分享。)
Just to prove these transformers are doing what we want them to do, I re-imported them from their exported pickle files and performed encoding on a new verison of the animals DataFrame. It’s pretty similar to the original one, but I re-ordered the values.
为了证明这些转换器正在执行我们希望它们执行的操作,我从其导出的泡菜文件中重新导入了它们,并对动物DataFrame的新版本进行了编码。 它与原始版本非常相似,但是我重新排列了值。
# Creating a newly ordered animals dataframe
new_animals_df = pd.DataFrame({'animal': ['cat', 'cat', 'dog', 'monkey', 'elephant', 'cat', 'bird', 'dog']})# Importing the exported pickle files
imported_sklearn_ohe = joblib.load('sklearn_ohe.pkl')
imported_ce_ohe = joblib.load('ce_ohe.pkl')# Running the new animals DataFrame through the Scikit-Learn imported transformer
loaded_sklearn_dummies = imported_sklearn_ohe.transform(new_animals_df)
loaded_sklearn_dummies_df = pd.DataFrame(data = loaded_sklearn_dummies.toarray(),
columns = imported_sklearn_ohe.categories_)# Running the new animals DataFrame through the Category Encoders imported transformer
loaded_ce_dummies = imported_ce_ohe.transform(new_animals_df)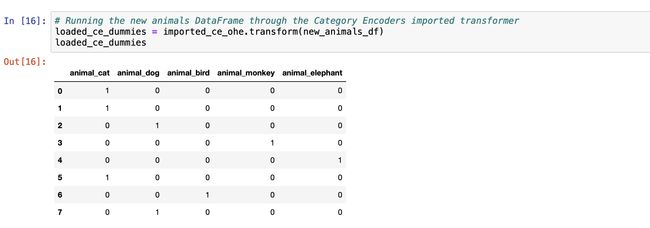
Voila, it works! Each of the outputted transformations share the same characteristics as we first saw when we performed transformation on the original dataset. I didn’t demo it in this post, but there are even baked in features that dictate the proper behavior of what happens when an unknown or null value is passed. Neat!
瞧,行得通! 每个输出的转换都具有与原始数据集上进行转换时所看到的相同的特征。 我没有在这篇文章中进行演示,但是其中甚至包含一些功能,这些功能指示了传递未知或null值时发生的情况的正确行为。 整齐!
And that wraps up another post! As nice as Pandas’ “get_dummies” functionality works, you really shouldn’t be using it for applied ML purposes. It causes a very fault tolerant, kludgy implementation in something like an API, and using either Scikit-Learn’s or Category Encoder’s one-hot encoder is much easier to use, anyway. Hope y’all appreciated this post! Be sure to check out my past tips, and please recommend anything you want to see in future posts! Until then, I’m signing off and wish you a happy Labor Day weekend.
这结束了另一篇文章! 尽管Pandas的“ get_dummies”功能很好用,但您实际上不应该将其用于应用的ML。 它会在API之类的程序中产生非常容错的,模糊的实现,并且无论如何,使用Scikit-Learn或Category Encoder的单热编码器都更容易使用。 希望大家都喜欢这篇文章! 请务必查看我过去的提示,并建议您在以后的帖子中看到的任何内容! 在此之前,我要签字同意并祝您劳动节周末愉快。
翻译自: https://towardsdatascience.com/data-science-tip-005-two-correct-ways-to-perform-one-hot-encoding-7c21e1db7aa2