【机器学习入门笔记】第八篇-随机森林
使用泰坦尼克数据,用sklearn决策树和随机森林进行预测比对
1.决策树(准确率:0.7811550)
#1)获取数据
import pandas as pd
data = pd.read_csv("titanic.csv")
#2)准备好特征值 目标值
x = data[["pclass","age","sex"]]
y = data["survived"]
#3)数据处理
#缺失值处理
x["age"].fillna(x["age"].mean(),inplace = True)
#特征值-》字典类型(字典抽取特征更方便)
x = x.to_dict(orient="records")
#4)划分数据集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state =22)
#字典特征抽取
from sklearn.feature_extraction import DictVectorizer
transfer =DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
#5).决策树预估器
from sklearn.tree import DecisionTreeClassifier
estimator = DecisionTreeClassifier(criterion="entropy",max_depth=8)
estimator.fit(x_train,y_train)
# 6).模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
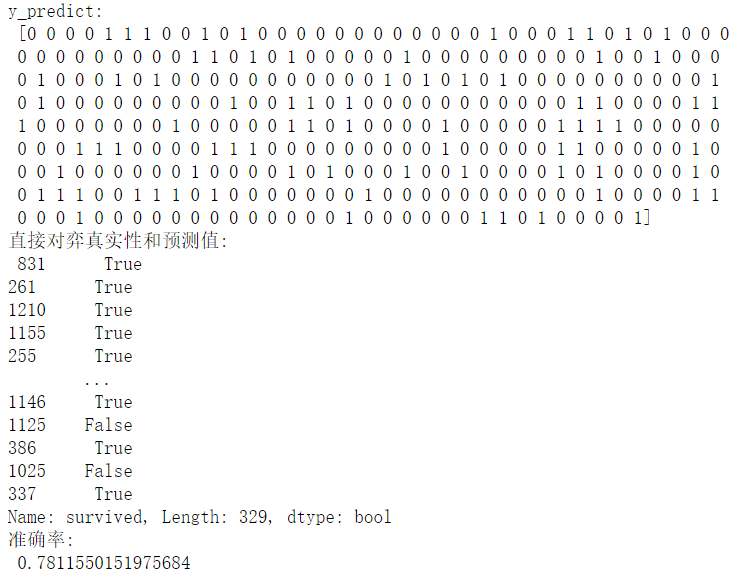
print("y_predict:\n", y_predict)
print("直接对弈真实性和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score);运行结果:
# 决策树的可视化
from sklearn.tree import export_graphviz
import graphviz
dot_data = export_graphviz(estimator,out_file = "titanic_tree.dot",feature_names = transfer.get_feature_names())
2.随机森林(准确率:0.7872340425531915)只多了0.06!!!
什么是集成学习方法?集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
随机?训练集随机 特征随机 bootstrap 随机又放回的抽样
森林?包含多个决策树的分类器。例如,如果你训练了5棵树,其中有4个树是True,1个树的结果是False,那么最终投票结果就是True
#1)获取数据
import pandas as pd
data = pd.read_csv("titanic.csv")
#2)准备好特征值 目标值
x = data[["pclass","age","sex"]]
y = data["survived"]
#3)数据处理
#缺失值处理
x["age"].fillna(x["age"].mean(),inplace = True)
#特征值-》字典类型(字典抽取特征更方便)
x = x.to_dict(orient="records")
#4)划分数据集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state =22)
#字典特征抽取
from sklearn.feature_extraction import DictVectorizer
transfer =DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
estimator = RandomForestClassifier()
##加入网络搜索与交叉验证
param_dict = {"n_estimators":[120,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
estimator = GridSearchCV(estimator,param_grid=param_dict,cv=3)
estimator.fit(x_train, y_train)
# 5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接对弈真实性和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score);
#最佳参数
print("最佳参数:\n",estimator.best_params_)
print("最佳结果:\n",estimator.best_score_)
print("最佳估计器:\n",estimator.best_estimator_)
print("交叉验证结构:\n",estimator.cv_results_)