集成学习入门与实战
文章目录
- 1. 什么是集成学习
- 2.基本思想
- 3.集成学习解决的问题
- 4.相关算法
-
- 4.1 Boosting
-
- 4.1.1 AdaBoost算法思想
- 4.1.2 AdaBoost算法流程
- 4.1.3 示例
- 4.2 提升树(Boosting Tree)
- 4.3 梯度提升树(GBDT)
- 4.4 Bagging与随机森林
- 5. 偏差-方差分解的角度分析Boosting和Bagging
1. 什么是集成学习
集成学习(ensemble learning)是现在非常火爆的机器学习方法。它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。也就是我们常说的“博采众长”。集成学习可以用于分问题集成回归问题集成,特征选取集成,异常点检测集成等等,可以说所有的机器学习领域都可以看到集成学习的身影。
集成学习思维导图图下所示:
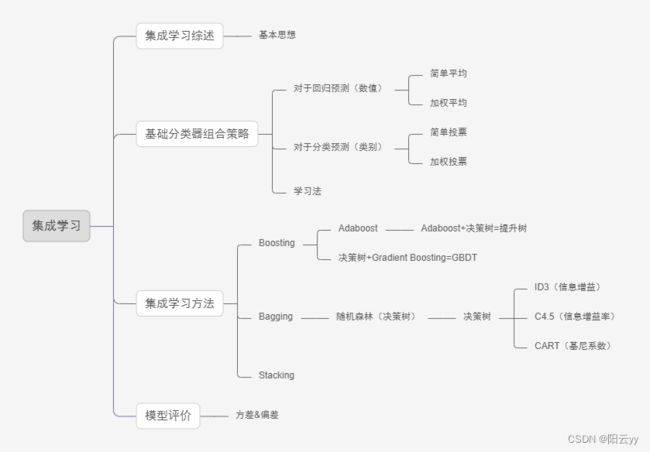
2.基本思想
对于训练集数据,我们通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众长的目的。集成学习有两个主要的问题需要解决:
- 如何得到若干个个体学习器;
- 如何选择一种结合策略,将这些个体学习器集合成一个强学习器
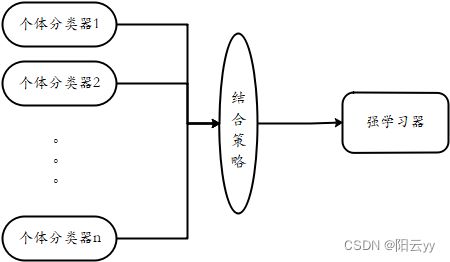
集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。
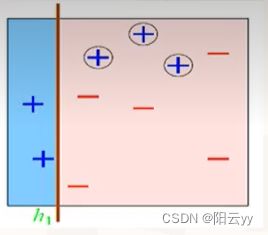
通过图例进行简单的分析集成学习过程:
- 原始数据

- 个体学习器
不同学习器所选择分割线不同,最终的结果也具有差异性
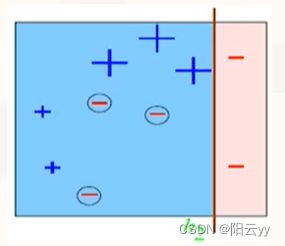
- 将多个单学习器进行组合
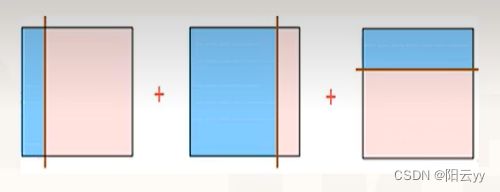
- 如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决,组合后得到的结果为理想划分界限。

对多个分类器的分类结果进行某种组合来决定最终的分类,以取得比单个分类器更好的性能。
在概率近似正确(PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它。
- 如果正确率很高,那么就称这个概念是强可学习(stronglylearnable)的。
- 如果正确率不高,仅仅比随即猜测略好,那么就称这个概念是弱可学习(weakly learnable)的。
后来证明强可学习与弱可学习是等价的
3.集成学习解决的问题
如上图所示,我们结合多种策略,使得分类效果较好,但是我们如何进行策略具有如下几个问题:
- 弱分类器之间是怎样的关系?
- 组合时,如何选择学习器?
- 怎样组合弱分类器?
问题一:弱分类器之间是怎样的关系?

个体学习器有两种选择:
- 第一种就是所有的个体学习器都是一个种类的或者说是同质的。比如都是决策树个体学习器或者都是神经网络个体学习器
- 第二种是所有的个体学习器不全是一个种类的或者说是导质的。比如我们有一个分类问题对训练集采用支持向量机个体学习器,逻辑回归个体学习器和朴素贝叶斯个体学习器来学习再通过某种结合策略来确定最终的分类强学习器
目前而言,同质个体学习器应用最广泛,一般我们常说的集成学习的方法都是指的同质个体学习器。而同质个体学习器使用最多的模型是CART决策树和神经网络。
同质个体学习器按照个体学习器之间是否存在依赖关系可以分为两类:
- 第一是个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成,代表算法是boosting系列算法。
- 第二个是个体学习器之间不存在强依赖关系,一系列个体学习器可以并行生成,代表算法是bagging和随机森林(RandomForest)系列算法。
问题二:组合时,如何选择学习器?
考虑准确性和多样性
- 准确性指的是个体学习器不能太差,要有一定的准确度;
- 多样性则是个体学习器之间的输出要具有差异性
考虑一个简单的例子:在二分类任务中,假定三个分类器在三个测试样本上的表现如图所示,其中 \sqrt{ } 表示分类正确, × \times × 表示分类错误,集成学习的结果通过投票法产生, 即 “少数服从多数” 。在图(a) 中,每个分类器都只有 66.6 % 66.6 \% 66.6% 的精度,但集成学习却达到了 100 % 100 \% 100%;在图 (b)中,三个分类器没有差别,集成之后性能没有提高;在图©中,每个分类器的精度都只有 33.3 % 33.3 \% 33.3%,集成学习的结果变得更糟。这个简单的例子显示出:要获得好的集成,个体学习器应 “好而不同” ,即个体学习器要有一定的 “准确性”,即学习器不能太坏,并且要有 “多样性”,即学习器间具有差异。

问题三:怎样组合弱分类器?
常见的组合策略:
- 平均法
- 投票法
- 学习法
(1) 平均法对于数值类的回归预测问题
思想:对于若干个弱学习器的输出进行平均得到最终的预测输出。
- 简单平均法 H ( x ) = 1 T ∑ i = 1 T h i ( x ) \quad H(x)=\frac{1}{T} \sum_{i=1}^T h_i(x) H(x)=T1∑i=1Thi(x)
- 加权平均法 H ( x ) = ∑ i = 1 T w i h i ( x ) \quad H(x)=\sum_{i=1}^T w_i h_i(x) H(x)=∑i=1Twihi(x)
其中 w i w_i wi 是个体学习器 h i h_i hi的权重,通常有 w i ≥ 0 , ∑ i = 1 T w i = 1 w_i \geq 0, \sum_{i=1}^T w_i=1 wi≥0,∑i=1Twi=1
(2)投票法对于分类问题的预测
思想:多个基本分类器都进行分类预测,然后根据分类结果用某种投票的原则进行投票表决,按照投票原则使用不同投票法。
一票否决、一致表决、少数服少多数
阈值表决:首先统计出把实例 x x x划分为 C i C_i Ci和不划分为 C i C_i Ci的分类器数目分别是多少,然后当这两者比例超过某个阈值的时候把 x x x划分到 C i C_i Ci。
(3)学习法(代表方法是Stacking)
之前的方法都是对弱学习器的结果做平均或者投票,相对比较简单,但是可能学习误差较大。
思想:不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,分为2层。
第一层是用不同的算法形成T个弱分类器,同时产生一个与原数据集大小相同的新数据集,利用这个新数据集和一个新算法构成第二层的分类器。
主要学习方法:
根据个体学习器的生成方式,目前的集成学习方法大致可分为两类:
- Boosting:个体学习器间存在强依赖关系,必须串行生成的序列化方法;
串行:下一个分类器只在前一个分类器预测不够准的实例上进行训练或检验。 - Bagging:个体学习器间不存在强依赖关系,可同时生成的并行化方法;
并行:所有的弱分类器都给出各自的预测结果,通过组合把这些预测结果转化为最终结果。
4.相关算法
4.1 Boosting
Boosting是一簇可将弱学习器提升为强学习器的算法。其工作机制为:先从初始训练集训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使得先前的基学习器做错的训练样本在后续收到更多的关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到实现指定的值T,或整个集成结果达到退出条件,然后将这些学习器进行加权结合。
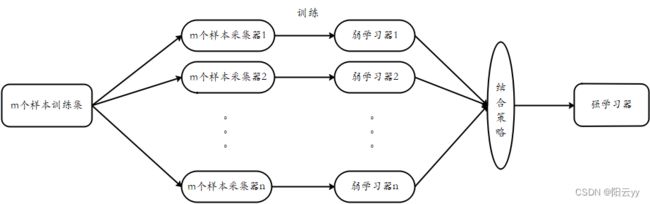
4.1.1 AdaBoost算法思想
Adaboost 算法采用调整样本权重的方式来对样本分布进行调整,即提高前一轮个体学习器错误分类的样本的权重,而降低那些正确分类的样本的权重,这样就能使得错误分类的样本可以受到更多的关注,从而在下一轮中可以正确分类,使得分类问题被一系列的弱分类器“分而治之”。对于组合方式,AdaBoost采用加权多数表决的方法,具体地,加大分类误差率小的若分类器的权值,减小分类误差率大的若分类器的权值,从而调整他们在表决中的作用。
4.1.2 AdaBoost算法流程
输入: 训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) , … ( x n , y n ) } T=\left\{\left(x_1, y_1\right),\left(x_2, y_2\right),\left(x_3, y_3\right), \ldots\left(x_n, y_n\right)\right\} T={(x1,y1),(x2,y2),(x3,y3),…(xn,yn)} ,其中 x i ∈ X ⊆ R n , y i ∈ Y = { − 1 , + 1 } x_i \in X \subseteq {R}^n, y_i \in Y=\{-1,+1\} xi∈X⊆Rn,yi∈Y={−1,+1} , Y = { − 1 , + 1 } Y=\{-1, \left.+1\right\} Y={−1,+1} 是弱分类算法。
输出: 最终分类器 G m ( x ) G_m(x) Gm(x)
初始化: 假定第一次训练时,样本均匀分布权值一样。
D 1 = ( w 11 , w 12 , w 13 … … w 1 n ) D_1=\left(w_{11}, w_{12}, w_{13} \ldots \ldots w_{1 n}\right) D1=(w11,w12,w13……w1n)
其中 w 1 i = 1 n , i = 1 , 2 , 3 … n w_{1 i}=\frac{1}{n}, i=1,2,3 \ldots n w1i=n1,i=1,2,3…n
循环: m = 1 , 2 , 3 … M m=1,2,3 \ldots \mathrm{M} m=1,2,3…M
(a)使用具有权值分布 D m D_m Dm 的训练数据集学习,得到基本分类器 G m G_m Gm (选取让误差率最低的阈值来设计基本分类器):
G m ( x ) : χ → { − 1 , + 1 } G_m(x): \chi \rightarrow\{-1,+1\} Gm(x):χ→{−1,+1}
(b)计算 G m ( x ) G_m(x) Gm(x) 在训练集上的分类误差率 e m e_m em
e m = P ( G m ( x i ) ≠ y i ) = ∑ i = 1 n w m i I ( G m ( x i ) ≠ y i ) e_m=P\left(G_m\left(x_i\right) \neq y_i\right)=\sum_{i=1}^n w_{m i} I\left(G_m\left(x_i\right) \neq y_i\right) em=P(Gm(xi)=yi)=i=1∑nwmiI(Gm(xi)=yi)
I ( G m ( x i ) ≠ y i ) I\left(G_m\left(x_i\right) \neq y_i\right) I(Gm(xi)=yi) : 当 G m ( x i ) G_m\left(x_i\right) Gm(xi) 与 y i y_i yi 相等时,函数取值为 0 ;当 G m ( x i ) G_m\left(x_i\right) Gm(xi) 与 y i y_i yi 不相等时,取值为 1 ;
由上述式子可知, G m ( x ) G_m(x) Gm(x) 在训练数据集上的误差率 e m e_m em 就是被 G m ( x ) G_m(x) Gm(x) 误分类样本的权值之和。
(c)计算 G m ( x ) G_m(x) Gm(x) 的系数 α m , α m \alpha_m , \alpha_m αm,αm 表示 G m ( x ) G_m(x) Gm(x) 在最终分类器中的重要程度:
α m = 1 2 ln 1 − e m e m \alpha_m=\frac{1}{2} \ln \frac{1-e_m}{e_m} αm=21lnem1−em
【注】显然 e m < = 1 / 2 e_m<=1 / 2 em<=1/2 时, α m > = 0 \alpha_m>=0 αm>=0 ,且 α m \alpha_m αm 随着 e m e_m em 的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大
此时分类器为: f m ( x ) = α m G m ( x ) f_m(x)=\alpha_m G_m(x) fm(x)=αmGm(x)
(d)更新训练数据集的权值分布,用于下一轮迭代。
D m + 1 = ( w m + 1 , 1 , w m + 1 , 2 , w m + 1 , 3 , … w m + 1 , n ) w m + 1 , i = w m i Z m exp ( − y i α m G m ( x i ) ) , i = 1 , 2 , 3 , … n \begin{gathered} D_{m+1}=\left(w_{m+1,1}, w_{m+1,2}, w_{m+1,3}, \ldots w_{m+1, n}\right) \\ w_{m+1, i}=\frac{w_{m i}}{Z_m} \exp \left(-y_i \alpha_m G_m\left(x_i\right)\right), i=1,2,3, \ldots n \end{gathered} Dm+1=(wm+1,1,wm+1,2,wm+1,3,…wm+1,n)wm+1,i=Zmwmiexp(−yiαmGm(xi)),i=1,2,3,…n
其中 Z m Z_m Zm 是规范化因子,使得 D m + 1 D_{m+1} Dm+1 成为一个概率分布。
Z m = ∑ i = 1 n w m i e ( − y i α m G m ( x i ) ) Z_m=\sum_{i=1}^n w_{m i} e^{\left(-y_i \alpha_m G_m\left(x_i\right)\right)} Zm=i=1∑nwmie(−yiαmGm(xi))
循环结束条件:
e m e_m em 小于某个阈值 (一般是 0.5 ) \left.0.5\right) 0.5) ,或是达到最大迭代次数。
AdaBoost 方法中使用的分类器可能很弱 (比如出现很大错误率),但只要它的分类效果比随机好一点 (比如两类问题分类错吴率略小于 0.5 0.5 0.5 ),就能够改善最终得到的模型。
组合分类器:
f ( x ) = ∑ m = 1 M α m G m ( x ) f(x)=\sum_{m=1}^M \alpha_m G_m(x) f(x)=m=1∑MαmGm(x)
最终分类器( Y { + 1 , − 1 } Y\{+1,-1\} Y{+1,−1}):
G m ( x ) = sign ( f ( x ) ) = sign ( ∑ i = 1 M α m G m ( x ) ) G_m(x)=\operatorname{sign}(f(x))=\operatorname{sign}\left(\sum_{i=1}^M \alpha_m G_m(x)\right) Gm(x)=sign(f(x))=sign(i=1∑MαmGm(x))
其中:
∑ i = 1 N u m i = 1 \sum _ { i = 1 } ^ { N } u _ { m i } = 1 i=1∑Numi=1
w m + 1 , i = { w m i Z m e − α m , G m ( x i ) = y i w m i Z m e α m , G m ( x i ) ≠ y i w_{m+1,i}= \left\{ \begin{matrix} \frac{w_{mi}}{Z_{m}}e^{- \alpha _{m}}, \quad G_{m}(x_{i})=y_{i}\\ \frac{w_{mi}}{Z_{m}}e^{\alpha _{m}}, \quad G_{m}(x_{i})\neq y_{i}\\ \end{matrix} \right. wm+1,i={Zmwmie−αm,Gm(xi)=yiZmwmieαm,Gm(xi)=yi
4.1.3 示例
假定给出下列训练样本

初始化: w 1 i = 1 n = 0.1 , n = 10 w _ { 1 i } = \frac { 1 } { n } = 0.1 , n = 10 w1i=n1=0.1,n=10(样本个数)
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值 | w 1 i w_{1i} w1i | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
阈值猜测:观察数据,可以发现数据分为两类:-1和1,其中数据“0,1,2”对应“1”类,数据“3,4,5”对应“-1”类,数据“6,7,8”对应“1”类,数据“9”对应“"1”类。抛开单个的数据“9”,可以找到对应的数据分界点(即可能的阈值),比如:2.5、5.5、8.5(一般0.5的往上加,也可以是其他数)。然后计算每个点的误差率,选最小的那个作为阈值。
但在实际操作中,可以每个数据点都做为阈值,然后就算误差率,保留误差率最小的那个值。若误差率有大于0.5的就取反(分类换一下,若大于取1,取反后就小于取1),再计算误差率。
迭代过程 1 : m = 1 1: m=1 1:m=1
- 确定阈值的取值及误差率
- 当阈值取 2.5 2.5 2.5 时,误差率为 0.3 0.3 0.3 。即 x < 2.5 x<2.5 x<2.5 时取 1 , x > 2.5 1 , x>2.5 1,x>2.5 时取 − 1 -1 −1 ,则数据6、7、8分错,误差率为 0.3 0.3 0.3 (简单理解: 10 个里面 3 个错的,真正误差率计算看下面的表格 )
- 当阈值取 5.5 5.5 5.5 时,误差率最低为 0.4 0.4 0.4 。即 x < 5.5 x<5.5 x<5.5 时取 1 , x > 5.5 1 , x>5.5 1,x>5.5 时取 − 1 -1 −1 ,则数据3、4、5、6、7、8分错,错误率为 0.6 > 0.5 0.6>0.5 0.6>0.5 ,故反过来,令 x > 5.5 x>5.5 x>5.5 取 1 , x < 5.5 x<5.5 x<5.5 时取 − 1 -1 −1 , 则数据0、1、2、9分错,误差率为 0.4 0.4 0.4
- 当阈值取 8.5 8.5 8.5 时,误差率为 0.3 0.3 0.3 。即 x < 8.5 x<8.5 x<8.5 时取 1 , x > 8.5 1, x>8.5 1,x>8.5 时取 − 1 -1 −1 ,则数据3、4、5分错,错误率为 0.3 0.3 0.3
由上面可知,阈值取 2.5 2.5 2.5 或8.5时,误差率一样,所以可以任选一个作为基本分类器。这里选2.5为例。
G 1 ( x ) = { 1 , x < 2.5 − 1 , x > 2.5 G_1(x)= \begin{cases}1, & x<2.5 \\ -1, & x>2.5\end{cases} G1(x)={1,−1,x<2.5x>2.5
计算误差率:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 分类器结果 | G 1 ( x ) G_1(x) G1(x) | 1 | 1 | 1 | -1 | -1 | -1 | -1 |
-1 |
-1 |
-1 |
| 分类结果 | 对 | 对 | 对 | 对 | 对 | 对 | 错 | `错 | 错 | 对 |
从上可得 G 1 ( x ) G_1(x) G1(x)在训练数据集上的误差率(被分错类的样本的权值之和):
e 1 = P ( G 1 ( x i ) ≠ y i ) = ∑ G 1 ( x i ) ≠ y i w 1 i = 0.1 + 0.1 + 0.1 = 0.3 e_{1}=P(G_{1}(x_{i})\neq y_{i})= \sum _{G_{1}(x_{i})\neq y_{i}}w_{1i}=0.1+0.1+0.1=0.3 e1=P(G1(xi)=yi)=G1(xi)=yi∑w1i=0.1+0.1+0.1=0.3
-
计算 G 1 ( x ) G_1(x) G1(x) 的系数:
α 1 = 1 2 ln 1 − e 1 e 1 = 1 2 ln 1 − 0.3 0.3 ≈ 0.42365 \alpha_1=\frac{1}{2} \ln \frac{1-e_1}{e_1}=\frac{1}{2} \ln \frac{1-0.3}{0.3} \approx 0.42365 α1=21lne11−e1=21ln0.31−0.3≈0.42365
这个 α 1 \alpha_1 α1 代表 G 1 ( x ) G_1(x) G1(x) 在最终的分类函数中所占的比重约为 0.42365 0.42365 0.42365 -
分类函数
f 1 ( x ) = α 1 G 1 ( x ) = 0.42365 G 1 ( x ) f_1(x)=\alpha_1 G_1(x)=0.42365 G_1(x) f1(x)=α1G1(x)=0.42365G1(x) -
更新权值分布:
Z 1 = ∑ i = 1 n w 1 i exp ( − y i α 1 G 1 ( x i ) ) = ∑ i = 1 3 0.1 × exp ( − [ 1 × 0.4263 × 1 ] ) + ∑ i = 4 4 − 6 , 10 0.1 × exp ( − [ ( − 1 ) × 0.4263 × ( − 1 ) ] ) + ∑ i = 7 9 0.1 × exp ( − [ 1 × 0.4263 × ( − 1 ) ] ) ≈ 0.3928 + 0.4582 + 0.0655 = 0.9165 w 2 i = w 1 i Z 1 exp ( − y i α 1 G 1 ( x i ) ) = { 0.1 0.9165 exp ( − [ 1 × 0.4236 × 1 ] ) , i = 1 , 2 , 3 0.1 0.9165 exp ( − [ ( − 1 ) × 0.4236 × ( − 1 ) ] ) , i = 4 , 5 , 6 , 10 0.1 0.9165 exp ( − [ 1 × 0.4236 × ( − 1 ) ] ) , i = 7 , 8 , 9 ≈ { 0.07143 i = 1 , 2 , 3 0.07143 i = 4 , 5 , 6 , 10 0.16666 i = 7 , 8 , 9 \begin{aligned} Z_1=& \sum_{i=1}^n w_{1 i} \exp \left(-y_i \alpha_1 G_1\left(x_i\right)\right) \\ =& \sum_{i=1}^3 0.1 \times \exp (-[1 \times 0.4263 \times 1]) \\ &+\sum_{i=4}^{4-6,10} 0.1 \times \exp (-[(-1) \times 0.4263 \times(-1)]) \\ &+\sum_{i=7}^9 0.1 \times \exp (-[1 \times 0.4263 \times(-1)]) \\ \approx & 0.3928+0.4582+0.0655 = 0.9165\\ &w_{2 i}= \frac{w_{1 i}}{Z_1} \exp \left(-y_i \alpha_1 G_1\left(x_i\right)\right)= \begin{cases}\frac{0.1}{0.9165} \exp (-[1 \times 0.4236 \times 1]), & i=1,2,3 \\ \frac{0.1}{0.9165} \exp (-[(-1) \times 0.4236 \times(-1)]), & i=4,5,6,10 \\ \frac{0.1}{0.9165} \exp (-[1 \times 0.4236 \times(-1)]), & i=7,8,9 \\ \end{cases} \\ \approx& \begin{cases}0.07143 \quad i=1,2,3 \\ 0.07143 \quad i=4,5,6,10 \\ 0.16666 \quad i=7,8,9\end{cases} \end{aligned} Z1==≈≈i=1∑nw1iexp(−yiα1G1(xi))i=1∑30.1×exp(−[1×0.4263×1])+i=4∑4−6,100.1×exp(−[(−1)×0.4263×(−1)])+i=7∑90.1×exp(−[1×0.4263×(−1)])0.3928+0.4582+0.0655=0.9165w2i=Z1w1iexp(−yiα1G1(xi))=⎩ ⎨ ⎧0.91650.1exp(−[1×0.4236×1]),0.91650.1exp(−[(−1)×0.4236×(−1)]),0.91650.1exp(−[1×0.4236×(−1)]),i=1,2,3i=4,5,6,10i=7,8,9⎩ ⎨ ⎧0.07143i=1,2,30.07143i=4,5,6,100.16666i=7,8,9
权值更新表:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值1 | w 1 i w_{1i} w1i | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 更新权值2 | w 2 i w_{2i} w2i | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
由上面可以看出,因为数据“6,7,8”被 G 1 ( x ) G_1(x) G1(x)分错了,所以它们的权值由初始的0.1增大到了0.16666;其他的数据由于被分对了,所以权值由0.1减小到0.07143。
迭代过程2: m = 2 m=2 m=2
- 确定阈值的取值及误差率
- 当阈值取2.5时,误差率为 0.49998 0.49998 0.49998 。即 x < 2.5 x<2.5 x<2.5 时取 1 , x > 2.5 1 , x>2.5 1,x>2.5 时取 − 1 -1 −1 ,则数据6、7、8分错,误差率为 0.1666 6 ⋆ 3 0.16666^{\star} 3 0.16666⋆3 (取过,不列入考虑范围)
- 当阈值取 5.5 5.5 5.5 时,误差率最低为 0.28572 0.28572 0.28572 。即 x < 5.5 x<5.5 x<5.5 时取 1 , x > 5.5 1 , x>5.5 1,x>5.5 时取 − 1 -1 −1 ,则数据3、4、5、6、7、8分错,错误率为 0.0714 3 ∗ 3 + 0.1666 6 ⋆ 3 = 0.71427 > 0.5 0.07143^* 3+0.16666^{\star} 3=0.71427>0.5 0.07143∗3+0.16666⋆3=0.71427>0.5 ,故反过来,令 x > 5.5 x>5.5 x>5.5 取 1 , x < 5.5 1 , x<5.5 1,x<5.5 时取 − 1 -1 −1 ,则数据0、1、2、9分错,误差率为 0.0714 3 ⋆ 4 = 0.28572 0.07143^{\star} 4=0.28572 0.07143⋆4=0.28572
- 当阈值取8.5时,误差率为 0.21429 0.21429 0.21429 。即 x < 8.5 x<8.5 x<8.5 时取 1 , x > 8.5 x>8.5 x>8.5 时取 − 1 -1 −1 ,则数据3、4、 5 、9分错,错吴率为 0.0714 3 ∗ 3 = 0.21429 0.07143^* 3=0.21429 0.07143∗3=0.21429
由上面可知,阈值取 8.5 8.5 8.5 时,误差率最小,所以:
G 2 ( x ) = { 1 , x < 8.5 − 1 , x > 8.5 G_2(x)= \begin{cases}1, & x<8.5 \\ -1, & x>8.5\end{cases} G2(x)={1,−1,x<8.5x>8.5
计算误差率:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值2 | w 2 i w_{2i} w2i | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
| 分类器结果 | G 2 ( x ) G_2(x) G2(x) | 1 | 1 | 1 | 1 |
1 |
1 |
1 | 1 | 1 | -1 |
| 分类结果 | 对 | 对 | 对 | 错 | 错 | 错 | 对 | 对 | 对 | 对 |
从上可得 G 2 ( x ) G_2(x) G2(x) 在训练数据集上的误差率(被分错类的样本的权值之和):
e 2 = P ( G 2 ( x i ) ≠ y i ) = ∑ G 2 ( x i ) ≠ y i w 2 i = 0.07143 + 0.07143 + 0.07143 = 0.21429 e_2=P\left(G_2\left(x_i\right) \neq y_i\right)=\sum_{G_2\left(x_i\right) \neq y_i} w_{2 i}=0.07143+0.07143+0.07143=0.21429 e2=P(G2(xi)=yi)=G2(xi)=yi∑w2i=0.07143+0.07143+0.07143=0.21429
- 计算 G 2 ( x ) G_2(x) G2(x) 的系数:
α 2 = 1 2 ln 1 − e 2 e 2 = 1 2 ln 1 − 0.21429 0.21429 ≈ 0.64963 \alpha_2=\frac{1}{2} \ln \frac{1-e_2}{e_2}=\frac{1}{2} \ln \frac{1-0.21429}{0.21429} \approx 0.64963 α2=21lne21−e2=21ln0.214291−0.21429≈0.64963
这个 α 2 \alpha_2 α2 代表 G 2 ( x ) G_2(x) G2(x) 在最终的分类函数中所占的比重约为 0.649263 0.649263 0.649263 - 分类函数
f 2 ( x ) = α 2 G 2 ( x ) = 0.64963 G 2 ( x ) f_2(x)=\alpha_2 G_2(x)=0.64963 G_2(x) f2(x)=α2G2(x)=0.64963G2(x) - 更新权值分布:
Z 2 = ∑ i = 1 n w 2 i exp ( − y i α 2 G 2 ( x i ) ) = ∑ i = 1 3 0.07143 × exp ( − [ 1 × 0.64963 × 1 ] ) + ∑ i = 4 6 0.07143 × exp ( − [ ( − 1 ) × 0.64963 × 1 ] ) + ∑ i = 7 9 0.16666 × exp ( − [ 1 × 0.64963 × 1 ] ) + ∑ i = 10 10 0.07143 × exp ( − [ ( − 1 ) × 0.64963 × ( − 1 ) ] ) ≈ 0.11191 + 0.41033 + 0.26111 + 0.03730 = 0.82065 \begin{aligned} Z_2=& \sum_{i=1}^n w_{2 i} \exp \left(-y_i \alpha_2 G_2\left(x_i\right)\right) \\ =& \sum_{i=1}^3 0.07143 \times \exp (-[1 \times 0.64963 \times 1]) \\ &+\sum_{i=4}^6 0.07143 \times \exp (-[(-1) \times 0.64963 \times 1]) \\ &+\sum_{i=7}^9 0.16666 \times \exp (-[1 \times 0.64963 \times 1]) \\ &+\sum_{i=10}^{10} 0.07143 \times \exp (-[(-1) \times 0.64963 \times(-1)]) \\ \approx & 0.11191+0.41033+0.26111+0.03730 \\ =& 0.82065 \end{aligned} Z2==≈=i=1∑nw2iexp(−yiα2G2(xi))i=1∑30.07143×exp(−[1×0.64963×1])+i=4∑60.07143×exp(−[(−1)×0.64963×1])+i=7∑90.16666×exp(−[1×0.64963×1])+i=10∑100.07143×exp(−[(−1)×0.64963×(−1)])0.11191+0.41033+0.26111+0.037300.82065
w 3 i = w 2 i Z 2 exp ( − y i α 2 G 2 ( x ) ) = { 0.07143 0.82065 exp ( − [ 1 × 0.64963 × 1 ] ) ≈ 0.04546 , i = 1 , 2 , 3 0.07143 0.82065 exp ( − [ ( − 1 ) × 0.64963 × 1 ] ) ≈ 0.16667 , i = 4 , 5 , 6 0.16666 0.82065 exp ( − [ 1 × 0.64963 × 1 ] ) ≈ 0.10606 , i = 7 , 8 , 9 0.07143 0.82065 exp ( − [ ( − 1 ) × 0.64963 × ( − 1 ) ] ) ≈ 0.04546 , i = 10 \begin{aligned} w_{3 i}&= \frac{w_{2 i}}{Z_2} \exp \left(-y_i \alpha_2 G_2(x)\right) \\ &= \begin{cases}\frac{0.07143}{0.82065} \exp (-[1 \times 0.64963 \times 1]) \approx 0.04546, & i=1,2,3 \\ \frac{0.07143}{0.82065} \exp (-[(-1) \times 0.64963 \times 1]) \approx 0.16667, & i=4,5,6 \\ \frac{0.16666}{0.82065} \exp (-[1 \times 0.64963 \times 1]) \approx 0.10606, & i=7,8,9 \\ \frac{0.07143}{0.82065} \exp (-[(-1) \times 0.64963 \times(-1)]) \approx 0.04546, & i=10\end{cases} \end{aligned} w3i=Z2w2iexp(−yiα2G2(x))=⎩ ⎨ ⎧0.820650.07143exp(−[1×0.64963×1])≈0.04546,0.820650.07143exp(−[(−1)×0.64963×1])≈0.16667,0.820650.16666exp(−[1×0.64963×1])≈0.10606,0.820650.07143exp(−[(−1)×0.64963×(−1)])≈0.04546,i=1,2,3i=4,5,6i=7,8,9i=10
权值更新表:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值1 | w 1 i w_{1i} w1i | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 更新权值2 | w 2 i w_{2i} w2i | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
| 更新权值3 | w 3 i w_{3i} w3i | 0.04546 | 0.04546 | 0.04546 | 0.16667 | 0.16667 | 0.16667 | 0.10606 | 0.10606 | 0.10606 | 0.04546 |
迭代过程 3 : m = 3 3: m=3 3:m=3
- 确定阈值的取值及误差率
- 当阈值取 2.5 2.5 2.5 时,误差率为 0.31818 0.31818 0.31818 。 即 x < 2.5 x<2.5 x<2.5 时取 1 , x > 2.5 1 , x>2.5 1,x>2.5 时取 − 1 -1 −1 ,则数据6、7、 8分错,误差率为 0.1060 6 ∗ 3 = 0.31818 0.10606^* 3=0.31818 0.10606∗3=0.31818 (取过,不列入考虑范围)
- 当阈值取 5.5 5.5 5.5 时,误差率最低为 0.18184 0.18184 0.18184 。即 x < 5.5 x<5.5 x<5.5 时取 1 , x > 5.5 x>5.5 x>5.5 时取 − 1 -1 −1 ,则数据3、4、5、6、7、8分错,错娱率为 0.16667 ∗ 3 + 0.1060 6 ∗ 3 = 0.81819 > 0.5 0.16667 * 3+0.10606^* 3=0.81819>0.5 0.16667∗3+0.10606∗3=0.81819>0.5 ,故反过 来,令 x > 5.5 x>5.5 x>5.5 取 1 , x < 5.5 1 , x<5.5 1,x<5.5 时取 − 1 -1 −1 ,则数据 0 、 1 、 2 、 9 0 、 1 、 2 、 9 0、1、2、9 分错,误差率为 0.0454 6 ∗ 4 = 0.18184 0.04546^* 4=0.18184 0.04546∗4=0.18184
- 当阈值取8.5时,误差率为 0.13638 0.13638 0.13638 。即 x < 8.5 x<8.5 x<8.5 时取 1 , x > 8.5 1 , x>8.5 1,x>8.5 时取 − 1 -1 −1 ,则数据3、4、5分错,铂误率为 0.0454 6 ∗ 3 = 0.13638 0.04546^* 3=0.13638 0.04546∗3=0.13638 (取过,不列入考虑范围)
由上面可知,阈值取8.5时,误差率最小,但 8.5 8.5 8.5 取过了,所以取 5.5 5.5 5.5 :
G 3 ( x ) = { − 1 , x < 5.5 1 , x > 5.5 G_3(x)= \begin{cases}-1, & x<5.5 \\ 1, & x>5.5\end{cases} G3(x)={−1,1,x<5.5x>5.5
计算误差率:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 权值3 | w 3 i w_{3i} w3i | 0.04546 | 0.04546 | 0.04546 | 0.16667 | 0.16667 | 0.16667 | 0.10606 | 0.10606 | 0.10606 | 0.04546 |
| 分类器结果 | G 3 ( x ) G_3(x) G3(x) | -1 |
-1 |
-1 |
-1 | -1 | -1 | 1 | 1 | 1 | 1 |
| 分类结果 | 错 | 错 | 错 | 对 | 对 | 对 | 对 | 对 | 对 | 错 |
从上可得 G 3 ( x ) G_3(x) G3(x) 在训练数据集上的误差率(被分错类的样本的权值之和):
e 3 = P ( G 3 ( x i ) ≠ y i ) = ∑ G 3 ( x i ) ≠ y i w 3 i = 0.04546 + 0.04546 + 0.04546 + 04546 = 0.18184 e_3=P\left(G_3\left(x_i\right) \neq y_i\right)=\sum_{G_3\left(x_i\right) \neq y_i} w_{3 i}=0.04546+0.04546+0.04546+04546=0.18184 e3=P(G3(xi)=yi)=G3(xi)=yi∑w3i=0.04546+0.04546+0.04546+04546=0.18184
- 计算 G 3 ( x ) G_3(x) G3(x) 的系数:
α 3 = 1 2 ln 1 − e 3 e 3 = 1 2 ln 1 − 0.18188 0.18184 ≈ 0.75197 \alpha_3=\frac{1}{2} \ln \frac{1-e_3}{e_3}=\frac{1}{2} \ln \frac{1-0.18188}{0.18184} \approx 0.75197 α3=21lne31−e3=21ln0.181841−0.18188≈0.75197
这个 α 3 \alpha_3 α3 代表 G 3 ( x ) G_3(x) G3(x) 在最终的分类函数中所占的比重约为 0.75197 0.75197 0.75197 - 分类函数
f 3 ( x ) = α 3 G 3 ( x ) = 0.75197 G 3 ( x ) f_3(x)=\alpha_3 G_3(x)=0.75197 G_3(x) f3(x)=α3G3(x)=0.75197G3(x) - 更新权值分布:
Z 3 = ∑ i = 1 n w 3 i exp ( − y i α 3 G 3 ( x i ) ) = ∑ i = 1 3 0.04546 × exp ( − [ 1 × 0.75197 × ( − 1 ) ] ) + ∑ i = 4 6 0.16667 × exp ( − [ ( − 1 ) × 0.75197 × ( − 1 ) ] ) + ∑ i = 7 9 0.10606 × exp ( − [ 1 × 0.75197 × 1 ] ) + ∑ i = 10 10 0.04546 × exp ( − [ ( − 1 ) × 0.75197 × 1 ] ) ≈ 0.28929 + 0.23572 + 0.15000 + 0.09643 = 0.77144 \begin{aligned} Z_3&=\sum_{i=1}^n w_{3 i} \exp \left(-y_i \alpha_3 G_3\left(x_i\right)\right) = \sum_{i=1}^3 0.04546 \times \exp (-[1 \times 0.75197 \times(-1)]) \\ &+\sum_{i=4}^6 0.16667 \times \exp (-[(-1) \times 0.75197 \times(-1)]) \\ &+\sum_{i=7}^9 0.10606 \times \exp (-[1 \times 0.75197 \times 1]) \\ &+\sum_{i=10}^{10} 0.04546 \times \exp (-[(-1) \times 0.75197 \times 1]) \\ &\approx 0.28929+0.23572+0.15000+0.09643\\ &=0.77144 \end{aligned} Z3=i=1∑nw3iexp(−yiα3G3(xi))=i=1∑30.04546×exp(−[1×0.75197×(−1)])+i=4∑60.16667×exp(−[(−1)×0.75197×(−1)])+i=7∑90.10606×exp(−[1×0.75197×1])+i=10∑100.04546×exp(−[(−1)×0.75197×1])≈0.28929+0.23572+0.15000+0.09643=0.77144
w 4 i = w 3 i Z 3 exp ( − y i α 3 G 3 ( x ) ) = { 0.04546 0.77144 exp ( − [ 1 × 0.75197 × ( − 1 ) ] ) ≈ 0.12500 , i = 1 , 2 , 3 0.16667 0.77144 exp ( − [ ( − 1 ) × 0.75197 × ( − 1 ) ] ) ≈ 0.10185 , i = 4 , 5 , 6 0.10606 0.77144 exp ( − [ 1 × 0.75197 × 1 ] ) ≈ 0.06481 , i = 7 , 8 , 9 0.04546 0.77144 exp ( − [ ( − 1 ) × 0.75197 × 1 ] ) ≈ 0.12500 , i = 10 w_{4 i}=\frac{w_{3 i}}{Z_3} \exp \left(-y_i \alpha_3 G_3(x)\right)= \begin{cases}\frac{0.04546}{0.77144} \exp (-[1 \times 0.75197 \times(-1)]) \approx 0.12500, & i=1,2,3 \\ \frac{0.16667}{0.77144} \exp (-[(-1) \times 0.75197 \times(-1)]) \approx 0.10185, & i=4,5,6 \\ \frac{0.10606}{0.77144} \exp (-[1 \times 0.75197 \times 1]) \approx 0.06481, & i=7,8,9 \\ \frac{0.04546}{0.77144} \exp (-[(-1) \times 0.75197 \times 1]) \approx 0.12500, & i=10\end{cases} w4i=Z3w3iexp(−yiα3G3(x))=⎩ ⎨ ⎧0.771440.04546exp(−[1×0.75197×(−1)])≈0.12500,0.771440.16667exp(−[(−1)×0.75197×(−1)])≈0.10185,0.771440.10606exp(−[1×0.75197×1])≈0.06481,0.771440.04546exp(−[(−1)×0.75197×1])≈0.12500,i=1,2,3i=4,5,6i=7,8,9i=10
权值更新表
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值1 | w 1 i w_{1i} w1i | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 更新权值2 | w 2 i w_{2i} w2i | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
| 更新权值3 | w 3 i w_{3i} w3i | 0.04546 | 0.04546 | 0.04546 | 0.16667 | 0.16667 | 0.16667 | 0.10606 | 0.10606 | 0.10606 | 0.04546 |
| 更新权值4 | w 4 i w_{4i} w4i | 0.125 | 0.125 | 0.125 | 0.10185 | 0.10185 | 0.10185 | 0.06481 | 0.06481 | 0.06481 | 0.125 |
迭代过程4:m=4
此时观察数据,每次迭代被分错的数据都已经重新分配过权值,按其他参考资料来说,此时的误差率为0,所以迭代可以到此结束。
最终分类器:
G m ( x ) = s i g n ( 0.42365 G 1 ( x ) + 0.64963 G 2 ( x ) + 0.75197 G 3 ( x ) ) G_m(x)=sign(0.42365G_1(x)+0.64963G_2(x)+0.75197G_3(x)) Gm(x)=sign(0.42365G1(x)+0.64963G2(x)+0.75197G3(x))
4.2 提升树(Boosting Tree)
xxx后续更新
4.3 梯度提升树(GBDT)
xxx单独更新
4.4 Bagging与随机森林
xxx单独更新
5. 偏差-方差分解的角度分析Boosting和Bagging
偏差(bias):述的是预测值的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
方差(variance):描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散:如下图右列所示。
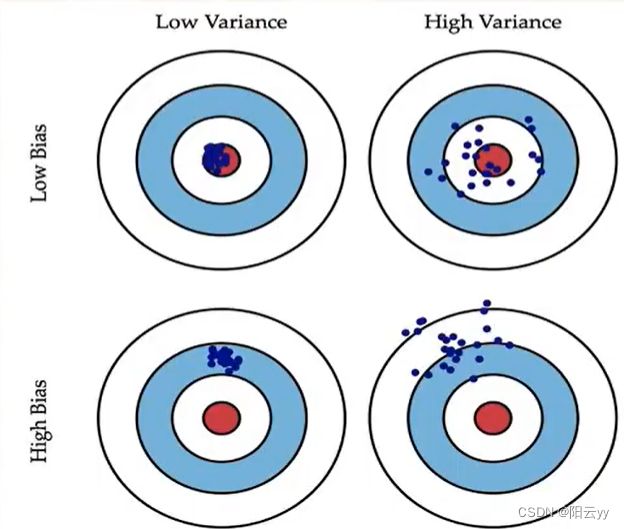
- Boosting主要关注降低偏差
偏差刻画了学习算法本身的拟合能力
Boosting思想,对判断错误的样本不停的加大权重,为了更好地拟合当前数据,所以降低了偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成。Boosting是把许多弱的分类器组合成一个强的分类器。 - Bagging主要是降低方差
度量了同样大小的数据集的变动所导致的学习性能的变化。刻画了数据扰动所造成的影响。
Bagging思想,随机选择部分样本来训练处理不同的模型,再综合来减小防方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更明显。Bagging是对许多强(甚至过强)的分类器求平均。