转换匹配患者记录,看Amazon Lake Formation FindMatches显神通

患者匹配是实现医疗护理互通性的主要障碍之一。不匹配的患者记录和无法检索患者历史信息可能严重阻碍做出正确的临床决定,并导致漏诊或治疗延误。另外,医疗护理提供者经常会花精力去处理患者重复数据的删除,尤其当他们的数据库中的患者记录数量急速增加时。电子健康记录 (EHR) 近年来大幅优化了患者的安全和护理协调,但准确的患者匹配对很多医疗护理组织来说仍然是一项挑战。
重复的患者记录会因为各种原因产生,包括人为生成记录的插入、删除、替换,或转置错误。虽然光学字符辨识 (OCR) 软件会将患者记录数字化,但也可能引入错误。
我们可以采用多种记录匹配算法来解决此问题。它们包括:基本确定性法(如分组和比较相关字段,包括 SSN、姓名或出生日期等)、语音编码系统,以及更高级的使用机器学习 (ML) 的算法。
Amazon Lake Formation 是一项符合 HIPAA 要求的服务,可帮助您在若干简单的步骤内构建安全的数据湖。Lake Formation 还内置 FindMatches,这项 ML 转换功能让您可以在不同的数据集中匹配记录,并且识别与移除重复的记录,但需要较少,甚至完全不需要任何人为干预。
本文将向您介绍如何使用 FindMatches ML 转换在综合生成的数据集里识别匹配的患者记录。要使用 FindMatches,您无需编写代码或了解 ML 的运作方式。如果没有可靠的唯一个人标识符,在数据中查找匹配将变得非常实用,即使其字段不完全匹配。
患者数据集
由于其具有敏感性质,不同国家采用各种法规对患者数据进行管理。此现状导致了用于训练匹配算法的患者数据通常较为缺乏,让模型的开发变得更加复杂。绕开此类挑战的常见办法,即使用综合数据。本文将基于 Open Source Freely Extensible Biomedical Record Linkage Program (FEBRL) 生成患者数据。FEBRL 采用隐马尔可夫模型 (HMM) 为患者记录匹配准备姓名和地址数据。它还允许对导致重复的现实患者数据集进行模拟,这些重复数据可能有以下不匹配类型:
1.空白字段。
2.排版错误,如拼写错误、字符转置或字段调换等。
3.缩写中间名和记录完整中间名。
4.不同格式的邮寄地址。
5.与 OCR 相关的错误。
6.语音错误。
7.无全局唯一患者或个人标识符。每一个医疗护理提供商都可能为相同人员分配一个患者标识符,但它或许并非类似于 SSN 的个人标识符,因此,他们有数据集但没有键。
FEBRL 可以根据可配置的参数生成此类数据集,以改变发生每种错误的可能性,进而涵盖导致重复的各种情形。综合数据集的生成不在本文的讨论范围之内;本文将提供一个预生成的数据集以供您探索之用:
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/aws-blog-lake-formation-ml-transforms/datasets/source/synthetic_patients_source_dataset.csv
简而言之,以下是用于运行 FindMatches 的综合数据集的生成步骤:
1.下载并安装 FEBRL。
2.修改参数以创建数据集,对您的预期进行模拟。如需更多信息,见 FEBRL 数据集生成说明:
https://github.com/J535D165/FEBRL-fork-v0.4.2/tree/master/dsgen
3.清理数据集(此举将为每一条记录确认相同的架构,并移除单引号和家庭角色)。
本文数据集使用的 Amazon 区域为美国东部(弗吉尼亚北部)。
FRBRL 患者数据结构
下表显示 FEBRL 患者数据的结构。此类数据包含 40000 条记录。
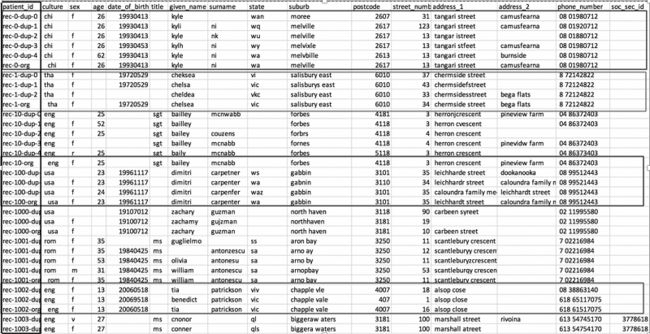
原始记录和重复记录会被分到一组。以特定的格式生成 patient_id:
rec-,后面是 FEBRL 数据生成器工具。
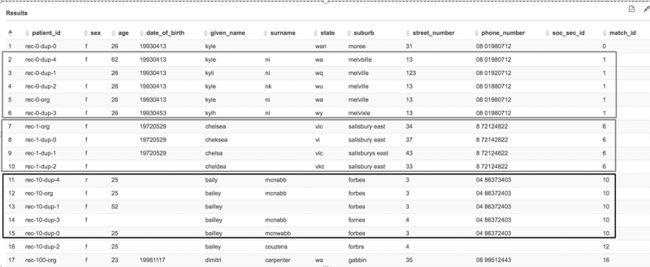
下表是您在努力使用 FindMatches ML 转换所要达成目标的预览。在对数据集进行匹配以后,生成的表将反映输入表的结构和数据,并添加 match_id 列。匹配的记录显示相同的 match_id 值。误报和漏报依然有可能发生,但转换的好处也显而易见。
先决条件
本文的示例综合患者数据集采用美国东部(弗吉尼亚北部)区域,因此本文提到的所有步骤都必须在相同的 Amazon 区域(即 us-east-1)内执行;但如果数据在其他区域,您可以非常轻松地对步骤进行修改。
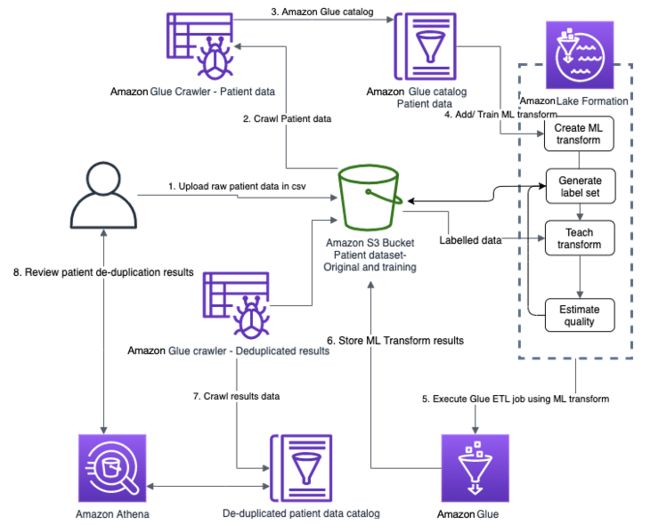
解决方案架构
下图显示了该解决方案的架构。
解决方案概览
在宏观层面上,匹配流程包括以下步骤:
1.在 Amazon S3 存储桶上上传csv格式的原始患者数据集
2.使用 Amazon Glue 爬网程序对上传的患者数据集进行爬网
3.使用 Amazon Glue 数据目录将您的患者数据编入目录,并创建 FindMatches ML 转换。
4.通过 ML 转换或以手动方式创建标签集,然后提供匹配和非匹配记录的标签示例,以便对 FindMatches 进行训练。上传您的标签,并估计预测的质量。按要求添加更多标签集并重复此步骤,以获得所需的查准率、准确率和召回率。
5.创建并执行使用您的 FindMatches 转换的 Amazon Glue ETL 作业。
6.在 Amazon S3 存储桶上存储 FindMatches 转换的结果
7.创建 FindMatches ML 转换结果的 Amazon Glue 数据目录。
8.使用 Amazon Athena 检查转换结果。
将您的数据编入目录,并创建 FindMatches ML 转换
FindMatches 在 Amazon Glue 数据目录内定义的表上运行。使用 Amazon Glue 爬网程序以发现患者数据并将其编入目录。您可以使用为本文生成的 FEBRL 患者数据:
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/aws-blog-lake-formation-ml-transforms/datasets/source/synthetic_patients_source_dataset.csv
下方提供的 Cloudformation 堆栈会在 Amazon 区域- us-east-1(美国东部(弗吉尼亚北部))内创建资源
要在 Amazon Glue 中创建目录和 FindMatches ML 转换,启动以下堆栈:

此堆栈会创建以下资源:
1.存储 ML 转换结果的 Amazon S3 存储桶(可作为启动的一部分进行配置)。您可以在 Amazon CloudFormation 堆栈控制台的输出下方找到存储桶的名称。本文使用名称 S3BucketName

2.允许 Amazon Glue 访问其他服务(包括 S3)的 IAM 角色。
3.Amazon Glue 数据库(可作为启动的一部分进行配置)。
4.内含“公开原始综合患者数据集”的 Amazon Glue 表(可作为启动的一部分进行配置)。
5.Amaozn Glue ML 转换,源作为您的 Amazon Glue 表,准确率设为 1,而精度设为 0.9。
如需更多信息,见使用 Amazon Lake Formation FindMatches 集成数据集并删除重复数据:
https://amazonaws-china.com/blogs/big-data/integrate-and-deduplicate-datasets-using-aws-lake-formation-findmatches/
ML 转换调优
误报匹配的安全风险(即让临床医生误以为关于患者的错误信息是准确的)可能比漏报匹配(即临床医生未能访问关于患者的现有信息)的安全风险更大。(如需更多信息,见 NCBI 网站上的相关研究。) 因此,将召回率 vs.精度滑块移向精度一边可提高置信度,以识别记录是否属于相同的患者,并在最大程度上降低误报匹配的安全风险。
更高的准确率设置有助于提高召回率,但代价是需要更长的运行时间(和成本)对更多记录进行必要的比较。
要针对此特定数据集获取相对更优的结果,启动堆栈已为您创建转换,召回率 vs.精度滑块设为 0.9 并偏向精度一边,低成本 vs.准确率滑块设为准确率。如有必要,您可以在稍后通过选择转换并使用调优菜单调整此类值。
使用标签数据训练 FindMatches
在成功启动堆栈以后,您可以通过提供采用标签集的匹配与非匹配记录对转换进行训练。
创建标签集
您可以自行创建标签集,或允许 Amazon Glue 基于启发式算法生成标签集。
Amazon Glue 会从您的源数据提取记录,并建议可能的匹配记录。生成的标签集文件包含大约 100 个供您操作的数据样本。
本文为您提供可以使用的由 Amazon Glue 生成的标签数据文件,其中的标签列已填充完整的数据。您可以随时使用此文件。
若选择使用本文中提供的预生成标签数据文件,请跳过下方的标签文件生成步骤
要创建训练集,执行以下步骤:
1.在 Amazon Glue 控制台的 ETL、作业和 ML 转换下方,您将可以看到由提供的堆栈为您创建的名为 cfn-findmatches-ml-transform-demo 的 ML 转换。
2.选择 ML 转换 cfn-findmatches-ml-transform-demo ,然后单击操作并选择训练转换。
3.对于使用标签训练转换,选择我没有标签。
4.选择生成标签文件。
5.提供用于存储生成标签文件的 S3 路径。
6.选择下一步。
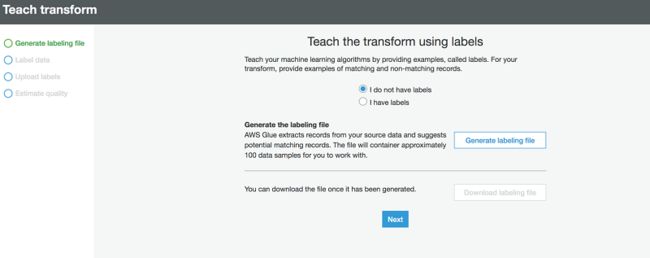
下表显示了生成的标签数据文件,其中的label列为空。
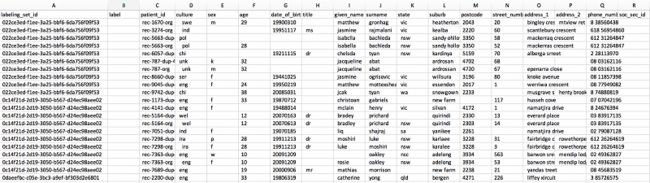
您需要标记与相同值真实匹配的记录,以便填充 label 列。每个标签集都应包含正负匹配示例。
本文为您提供可以使用的标签数据文件,其中的 label 列已填充完整的数据。您可以随时使用此文件。
下表显示的表已完整填充 label 列。
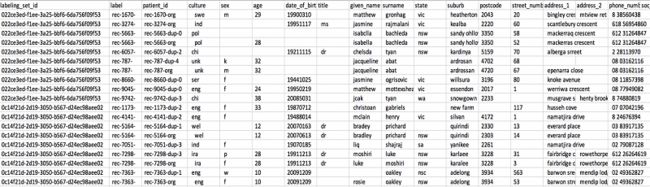
标签文件采用与输入数据一样的架构,以及两个额外的列:labeling_set_id id 和 label。
训练数据集可被分为多个标签集。每个标签集都显示 labeling_set_id 值。此标识方法简化了标签添加流程,让您可以专注于在相同标签集内匹配记录关系,而不用对整个文件进行扫描。对于上述数据集,通过使用正则表达式移除前缀 -org 和 -dup,从 patient_id 提取标签值。但总得来说,您要根据基于属性值应匹配的记录来分配此类标签。
如果为一个标签集内的两个或更多记录指定相同的标签,则您在训练 FindMatches 转换将这些记录视作匹配。而在另一方面,当相同标签集内的两个或更多记录有不同的标签时,FindMatches 会学习不要把这些记录当做匹配。转换在相同标签集而不会跨不同标签集评估记录之间的记录关系。
您应该为数百条记录添加标签以实现适当的匹配质量,而数千条记录则能获得更高的匹配质量。
上传您的标签并检查匹配质量
在您创建标签数据集(需采用 .csv 格式)以后,训练 FindMatches 在什么地方进行查找。请执行以下步骤:
1.在 Amazon Glue 控制台上,选择您在之前创建的转换。
2.选择操作。
3.选择训练转换。
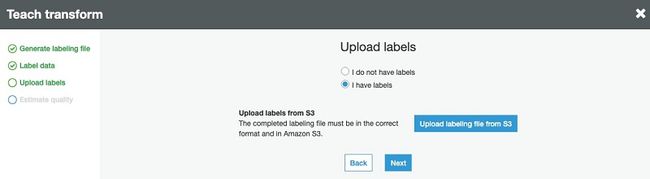
4.对于上传标签,选择我有标签。
5.选择从 S3 上传标签文件。
6.选择下一步。
7.如果您想要使用本博文中提供的标签集,在此处下载标签集:
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/aws-blog-lake-formation-ml-transforms/datasets/training/TrainingDataSet_200Records.csv
8.在由上述已启动的 cloudformation 模板创建的相同 S3 存储桶中,创建一个名为训练集的文件夹。
9.在相同的 S3 存储桶中,上传上述位于训练集的标签集。
10.选择覆盖我的现有标签。您只能使用一个标签集。若反复添加标签,选择附加到我的现有标签选项。
11.选择上传。在上传标签以后,您现在随时可以使用转换。虽然不是硬性要求,但您可以通过检查匹配和非匹配记录来确定转换匹配的质量。
12.选择估计转换质量。转换质量估计将使用您的标签中的 70% 进行学习。在训练完成以后,质量估计将针对剩余的 30% 测试转换学到的识别匹配记录的能力。最后,转换会比较由算法和您的实际标签预测的匹配和非匹配,以便生成质量指标。此过程可能长达数分钟。
您的结果应与以下截图中的情况类似。

将这些指标视作近似值,因为测试只会使用数据的一小部分子集估计匹配的质量。若您对指标感到满意,继续创建并运行记录匹配作业。或者,上传更多标签记录以进一步改善匹配质量。
创建并运行 Amazon Glue ETL 作业
在创建 FindMatches 转换并验证它已学会识别您的数据中的匹配记录以后,您就可以在您的完整数据集中识别匹配。要创建并运行记录匹配作业,执行以下步骤:
1.在 S3 存储桶内创建一个 transformresults 文件夹,该存储桶由 Amazon CloudFormation 模板在您启动堆栈时创建。此文件夹将存储您的 Amazon Glue 作业的 ML 转换的结果。
2.在 Amazon Glue 控制台的作业下方,选择添加作业。
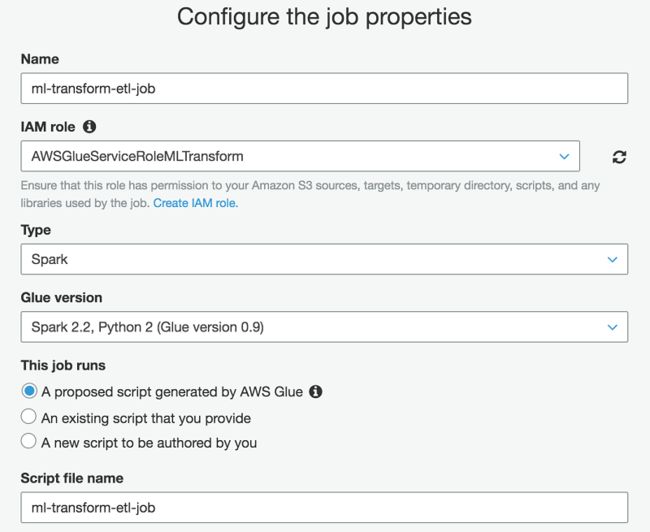
3.在配置作业属性下方的名称中,输入作业的名称。
4.对于 IAM 角色,在下拉菜单中选择您的角色。选择由 Amazon CloudFormation 堆栈创建的名为 AWSGlueServiceRoleMLTransform 的 IAM 角色。如需更多信息,见为 Amazon Glue 创建 IAM 角色:
https://docs.aws.amazon.com/glue/latest/dg/create-an-iam-role.html?icmpid=docs_glue_console
5.选择 Spark 作为类型,Glue 版本为 Spark 2.2,Python 2(Glue 版本 0.9)
6.为作业运行选择 Amazon Glue 生成的建议脚本。
7.在选择一个数据源中,选择转换数据源。本文使用数据源 cfn_table_patient。
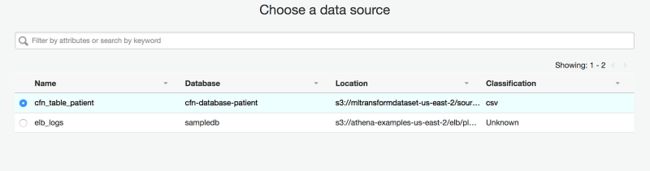
8.在选择转换类型下方,选择查找匹配记录。
9.对于工作线程类型,选择 G.2X。
10.对于工作线程数量,输入 10。您可以根据数据集的大小填写更大数字,以便添加更多工作线程。

11.要检查被识别为重复的记录,不要选择移除重复记录。
12.选择下一步。
13.选择由您创建的转换。
14.选择下一步。
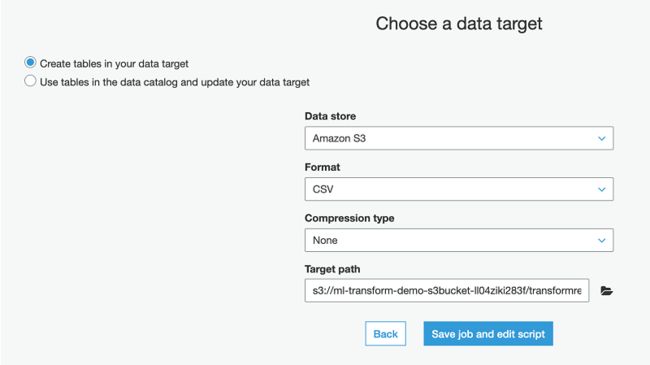
15.对于选择一个数据目标,选择在数据目标中创建表格。
16.对于数据存储,选择 Amazon S3。
17.对于格式,选择 CSV。
18.对于压缩类型,选择无。
19.对于目标路径,选择作业输出的路径。目标路径是由 Amazon CloudFormation 创建的 S3 存储桶,以及您在之前创建的名为transformresults 的文件夹。
20.选择保存作业并编辑脚本。
现已为您的作业生成脚本,并随时可供使用。或者,您也可以进一步对脚本进行自定义,以满足您的具体 ETL 需求。
21.要开始识别此数据集中的匹配,选择如下方屏幕所示运行作业。暂时保留作业参数的默认设置,并在启动作业后关闭此页面。以下截图显示的是由 Amazon Glue 使用 ML 转换而生成的建议 Python Spark 脚本。
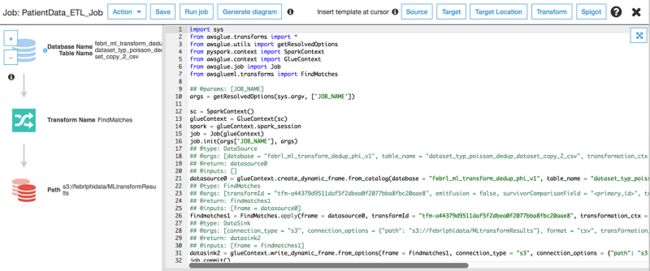
如果执行成功,FindMatches 将显示运行状态为 Succeeded。执行可能需要数分钟才会结束。
FindMatches 会将您的输出数据作为分段 .csv 文件保存于您在作业创建期间指定的目标路径。生成的 .csv 文件反映了输入表的结构和数据,而且内有 match_id 列。匹配的记录显示相同的match_id 值。
创建您的转换结果的数据目录
要查看输出,您可以直接从 S3 存储桶下载分段 .csv 文件并在编辑器中查看,或者您也可以使用 Athena 对存储在 S3 上的数据运行类似 SQL 的查询。要通过 Athena 查看数据,您需要对文件夹以及由您创建的作为 FindMatches ETL 作业输出一部分的分段 .csv 文件进行爬网。
转至 Amazon Glue,使用现有数据库中的 Amazon爬网程序为患者匹配创建一个新表格,此表中有来自您的 FindMatches ETL 作业输出的记录,并且以包含分段 .csv 文件的 S3 存储桶文件夹作为源数据。在本文中,源数据为由 Amazon CloudFormation 堆栈创建的存储桶中的文件夹 transformresults。
要创建爬网程序,执行以下步骤:
1.在 Amazon Glue 控制台的数据目录下方,选择爬网程序。
2.单击添加爬网程序以创建新的爬网程序,对转换结果进行爬网。
3.提供爬网程序的名称,并单击下一步。
4.选择数据存储作为爬网程序源类型,并单击下一步。
5.在添加数据存储部分的选择一个数据存储中,选择 S3。
6.对于爬网数据位置,选择我的账户中的指定路径。
7.在包含路径下方,输入您的路径的名称。它应该是之前由 cloudformation 创建的相同 S3 存储桶,以及由您创建的名为 transformresults 的文件夹。验证文件夹中有已创建的分段 csv 文件。
8.选择下一步。

9.在选择一个 IAM 角色部分,选择选择 IAM 角色。
10.对于 IAM 角色,输入爬网程序的名称。
11.选择下一步。
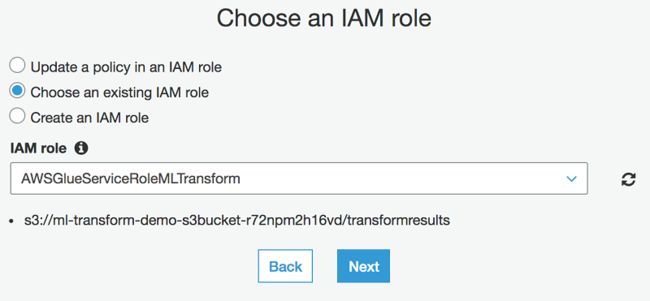
12.对于频率,选择按需运行。
13.配置爬网程序的输出,将数据库设为cfn-database-patient。
14.将添加到表格的前缀的值设为 table_results_。这样做将有助于识别包含转换结果的表。
15.单击结束。
16.选择相同的爬网程序,并单击运行爬网程序。在成功执行爬网程序以后,您应该看到已创建的,而且与您在爬网程序配置期间选择的相应数据库中的爬网程序对应的新表格。
17.在 Amazon Glue 控制台的数据库下方,选择表。
18.选择操作。
19.选择编辑表详细信息。
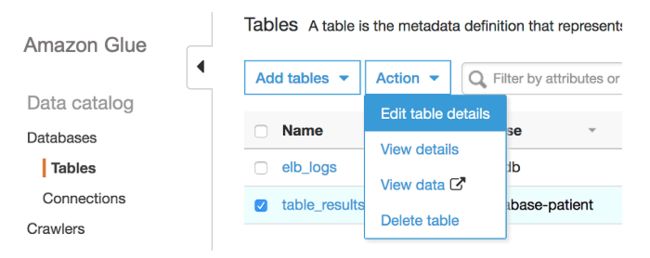
20.在Serde序列化库的下方输入:
org.apache.hadoop.hive.serde2.OpenCSVSerde
21.在 Serde 参数下方,添加键 escapeChar,其值为 \\。
22.添加键 quoteChar,其值为 "(半角双引号)。
23.设置键 field.delim,值为 ,
24.添加键 separatorChar,值为,
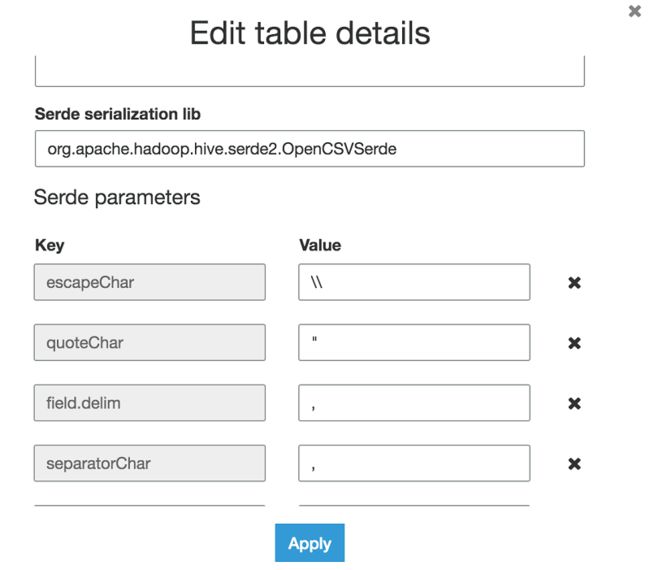
您可以根据基于所拥有数据集的类型的要求设置 Serde 参数。
25.通过将所有列的数据类型设为 String,对表的架构进行编辑。要编辑表的架构,单击表格,然后单击编辑架构按钮。
您还可以根据您的要求,选择按爬网程序保留推断数据类型。为了简单起见,本文将全部都设为 String数据类型,但 match_id 列除外,它被设为 bigint。
使用 Amazon Athena 检查输出
要使用 Amazon Athena 检查输出,执行以下步骤:
1.在数据目录中,选择表。
2.选择由您的爬网程序为结果创建的表的名称。
3.选择操作。
4.选择查看数据。
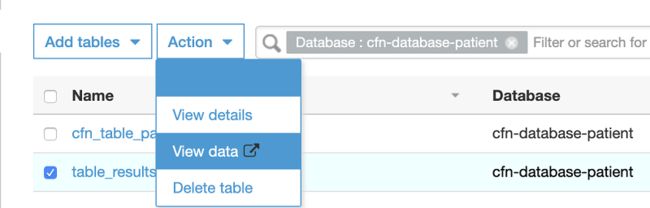
Athena 控制台将会打开。 如果首次运行 Amazon Athena,您可能必须单击开始。在首次运行查询前,您还将需要设置查询结果在 Amazon S3 中的位置。在 Amazon Athena 控制台上单击设置查询结果在 Amazon S3 中的位置,然后设置查询结果的位置。您可以在之前由 cloudformation 创建的相同 Amazon S3 存储桶中创建更多文件夹。请确保 S3 路径以 / 结尾。
5.选择适当的数据库。在本文中,选择 cfn-database-patient。如果未在下拉菜单中看到该数据库,您可能需要刷新数据源。
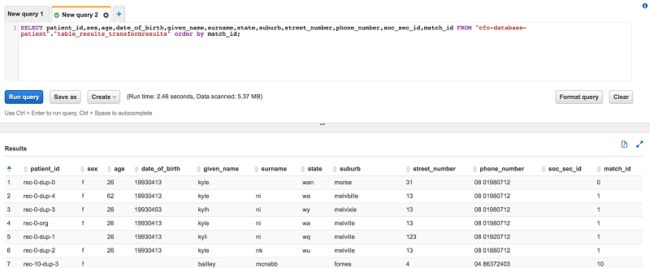
6.选择包含 FindMatches 输出的结果表,而且此表中有患者记录和 match_id 列。在此例中就是 table_results_transformresults。如果您为该结果表选择了不同的名称,需要更改以下查询以反映正确的表名称。
7.选择运行查询,以运行以下查询。
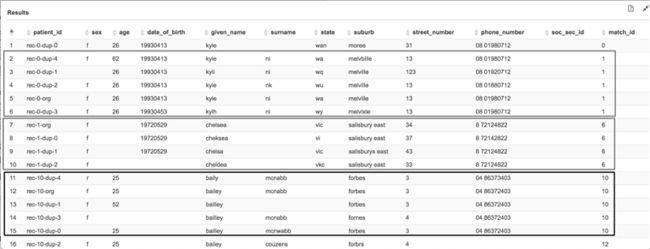
SELECT * FROM "cfn-database-patient"."table_results_transformresults" order by match_id;以下截图显示的是您的输出。
安全注意事项
Amazon Lake Formation 通过为您提供一个中心位置来帮助保护您的数据;无论使用哪项服务进行访问,您都可以在此位置中配置精细数据访问策略
要使用 Lake Formation 集中数据访问策略控制,首先关闭对您在 S3 中存储桶进行直接访问的权限,以便 Lake Formation 管理所有的数据访问。通过 Lake Formation 配置数据保护和访问策略,该 Lake Formation 会在对您的数据湖中的数据进行访问的所有 Amazon 服务中执行此类策略。您可以配置用户和角色,并且定义这些角色可以访问的数据,最低到表和列级别。
Amazon Lake Formation 提供基于简单授予/撤销机制的权限模型。Lake Formation 权限和 IAM 权限结合,对访问存储于数据库的数据和描述该数据的元数据的权限进行控制。如需更多信息,见 Lake Formation 中的元数据和数据的安全及访问权限控制:
https://docs.aws.amazon.com/lake-formation/latest/dg/security-data-access.html
Lake Formation 目前支持 S3 上的服务器端加密(SSE-S3、AES-265)。Lake Formation 还支持您的 VPC 中的私有终端节点,并记录 Amazon CloudTrail 中的所有活动,为您提供网络隔离和可审计性。
Amazon Lake Formation 服务是一项符合 HIPAA 要求的服务。
小结
本文演示了如何使用 Lake Formation FindMatches ML 转换在患者数据库中查找匹配的记录。它让您可以在两个数据集中的记录不采用相同的标识符或包含重复数据时找到匹配。若字段不完全匹配,或属性缺失或损坏,此方法帮助您在数据集行之间查找匹配。
您现在随时可以通过 Lake Formation 开始构建,并对您的数据尝试使用 FindMatches。
参考资料
Amazon Lake Formation:
https://amazonaws-china.com/lake-formation/
Open Source Freely Extensible Biomedical Record
Linkage Program (FEBRL):
https://github.com/J535D165/FEBRL-fork-v0.4.2
Amazon Glue:
https://amazonaws-china.com/glue
Amazon Athena:
http://amazonaws-china.com/athena
Amazon S3:
http://amazonaws-china.com/s3
Amazon CloudFormation:
http://amazonaws-china.com/cloudformation
由 Amazon Glue 生成的标签数据文件:
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/aws-blog-lake-formation-ml-transforms/datasets/training/TrainingDataSet_200Records.csv
预生成标签数据文件:
https://aws-bigdata-blog.s3.amazonaws.com/artifacts/aws-blog-lake-formation-ml-transforms/datasets/training/TrainingDataSet_200Records.csv
标签数据文件:
https://patient-matching-mltransform.s3-us-west-2.amazonaws.com/datasets/training/TrainingDataSet_200Records.csv
Amazon CloudTrail:
http://amazonaws-china.com/cloudtrail
符合 HIPAA 要求:
https://amazonaws-china.com/compliance/hipaa-eligible-services-reference/
本篇作者

Dhawalkumar Patel
亚马逊云科技高级解决方案架构师
他一直就职于从大型企业到中型初创公司等组织,致力于解决与分布式计算和人工智能有关的问题。目前,他正专注于研究机器学习和无服务器技术。

Ujjwal Ratan
亚马逊云科技全球健康医疗与生命科学团队首席机器学习专家解决方案架构师
他的主攻方向是机器学习及深度学习应用,以解决各种现实中的行业问题,例如,医学成像、非结构化临床文本、基因组学、精准医学、临床试验和护理质量优化,等等。他擅长于扩展亚马逊云科技云上的机器学习/深度学习算法,以加快训练和推导。在业余时间,他喜欢欣赏(和弹奏)音乐,以及和家人来一场说走就走的公路旅行。