大数据面试
转自:https://blog.csdn.net/qq_44868502/article/details/103202702 山岭巨人杨尚桑
大数据面试
分享给大家一篇很好的面试题
- ConcurrentHashMap 是怎么实现的?
答:concurrent 包中线程安全的哈希表,采用分段锁,可以理解为把一个大的 Map 拆分成 N 个小的 HashTable,根据 key.hashCode() 来决定把 key 放到哪个 HashTabl 中。在 ConcurrentHashMap 中,就是把 Map 分成了 N 个 Segment,put 和 get 的时候,都是现根据 key.hashCode() 算出放到哪个 Segment 中。
- sparksql 和 sparkstreaming 哪个比较熟
答:都还行,SparkSql 的 DataFrame 或者 DataSet 和 SparkStreaming 的 DStream 都是基于SparkCore 的,最终都会转化为 Sparktask 执行。我们可以交流一下本质的东西 SparkCore,而SparkCore 的核心又是 RDD。
- 说一下 sparkshuffle
答:Spark 的 shuffle 也是一处理问题的思想:分而治之。shuffle 一般称为洗牌,一般会有Shuffle。
Write 阶段 和 Shuffle
Read 阶段。在 Spark 中实现 Shuffle 的方式有两种,一种是 HashShuffle,一种是 SortShuffle。shuffle 的性能是影响 spark 应用程序性能的关键。shuffle 发生在 stage 之间,stage 中用的 pipline 的计算模式。
- Spark Shuffle 的调优点:
1:Shuffle 的选择 2:缓冲区的大小 3:拉去的数据量的大小 4:间隔时间重试次数。
- 缓存这块熟悉吗,介绍缓存级别
答:Spark 的缓存机制是 Spark 优化的一个重要点,它将需要重复使用或者共用的 RDD 缓存在内存中,可以提高 Spark 的性能。Spark 的底层源码中使用 StorageLevel 来表示缓存机制,其中包括:使用内存,使用磁盘,使用序列化,使用堆外内存。在他的半生对象中基于这几种方式提供了一些实现:不使用缓存,Memory_Only,Disk_only,offHeap 分别都有相应的序列化,副本,组合的实现提供选择。持久化的级别 StorageLevel 可以自定义,但是一般不自定义。如何选择 RDD 的缓存级别的本质是在内存的利用率和 CPU 的利用率之间的权衡。一般默认选择的是 Memory_only, 其次是 Memery_only_Ser, 再次是 Memory_only_and_Dis 至于怎么选择你得自己权衡。
- 说一下 cache 和 checkpoint 的区别
答:要知道区别,首先要知道实现的原理和使用的场景 catche 的就是将共用的或者重复使用的 RDD 按照持久化的级别进行缓存 checkpoint 的是将业务场景非常长的逻辑计算的中间结果缓存到 HDFS 上,它的实现原理是:
首先找到 stage 最后的 finalRDD,然后按照 RDD 的依赖关系进行回溯,找到使用了 checkPoint 的 RDD 然后标记这个使用了 checkPoint 的 RDD 重新的启动一个线程来将 checkPoint 之前的 RDD 缓存到 HDFS 上面最后将 RDD 的依赖关系从 checkPoint 的位置切断知道了实现的原理和使用场景后我们就很容易的知道了 catch 和 checkpoint 的区别了。
- spark 运行模式 local local[] local[*] 分别是什么
答:该模式被称为 Local[N] 模式,是用单机的多个线程来模拟 Spark 分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题其中N代表可以使用 N 个线程,每个线程拥有一个 core 。如果不指定 N,则默认是1个线程(该线程有1个 core )。如果是 local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine: 在本地运行Spark,与您的机器上的逻辑内核一样多的工作线程。
- Spark 怎么设置垃圾回收机制 ?
答:Spark 中各个角色的JVM参数设置:http://blog.csdn.net/wuxb2000/article/details/52870198 1)Driver 的 JVM 参数: GC 方式,如果是 yarn-client 模式,默认读取的是 spark-class 文件中的 JAVAOPTS;如果是 yarn-cluster 模式,则读取的是 spark-default.conf 文件中的 spark.driver.extraJavaOptions 对应的参数值。 (2)Executor 的 JVM 参数: GC 方式,两种模式都是读取的是 spark-default.conf 文件中的spark.executor.extraJavaOptions 对应的 JVM 参数值。
- 一台节点上以 root 用户执行一个 spark 程序,以其他非 root 用户也同时在执行一个 spark 程序,这时以 spark 用户登录,这个节点上,使用 Jps 会看到哪些线程?
答:单独的用户只能看自己的进程
- hive 怎么解决数据倾斜的问题?
参考博客:https://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842860.html 本质:使 map 的输出数据更均匀的分布到 reduce 中去,是我们的最终目标
- 数据倾斜的原因:
key 分布不均匀 业务数据本身的欠缺性 建表设计方法不对 有些 SQL 难免会有一下数据倾斜不可避免 表现的形式: 任务完成进度卡死在99%,或者进度完成度在100%但是查看任务监控,发现还是有少量(1个或几个)reduce 子任务未完成。因为其处理的数据量和其他 reduce 差异过大。单一reduce 的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
解决方案: 参数调整: hive.map.aggr=true: Map 端部分聚合,相当于 Combiner hive.groupby.skewindata=true: 有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。 2:参数调节: 如何 Join: 关于驱动表的选取,选用 join key 分布最均匀的表作为驱动表 做好列裁剪和 filter 操作,以达到两表做 join 的时候,数据量相对变小的效果 大小表 Join: 使用 map join 让小的维度表(1000条以下的记录条数) 先进内存。在 map 端完成 reduce. 大表 Join 大表: 把空值的 key 变成一个字符串加上随机数,把倾斜的数据分到不同的 reduce 上,由于 null值关联不上,处理后并不影响最终结果 count distinct 大量相同特殊值 count distinct 时,将值为空的情况单独处理,如果是计算 count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行 group by,可以先将值为空的记录单独处理,再和其他计算结果进行 union。 group by 维度过小: 采用 sum() group by 的方式来替换 count(distinct) 完成计算。 特殊情况特殊处理: 在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后 union 回去。 如果确认业务需要这样倾斜的逻辑,考虑以下的优化方案: 总结: 1、对于 join,在判断小表不大于1 G 的情况下,使用 map join 2、对于 group by 或 distinct,设定 hive.groupby.skewindata=true 3、尽量使用上述的 SQL 语句调节进行优化
- 如果链表的实现方式中 hash 的值有冲突的话,怎么解决?如果解决以后怎么解决再链表的常数次的查询?
答案:使用链表来存储重复的 hash 值,如何对链表进行常数次的查找,需要将链表+随机数再 hash
- HDFS 的读写流程细节?HDFS 中的 fsimage 里面存储的是什么信息?副本的存放策略?
答:这个大家最好回家准备一个详细的流程图然后根据自己的图讲给面试官看
- HDFS 的机架感知?
答:根据副本的存放策略,HDFS 是如何知道多个不同 node 是否在同一个机架上呢 ?在namenode 启动时如果 net.topology.script.file.name 配置的参数不为空,表示已经动机架感知,当 datanode 注册时和 heartbeat 时,会把 datanode 的 ip 作为参数传入,返回信息为此datanode 的机架信息。如果没有参数配置,datanode 统一为默认的机架 /default-rack
- 如果 Client 节点就在 HDFS 中的一台 DataNode 节点上,副本的数据又是如何存储的?
答案:存放在当前的 DN 上,其他的和副本的存放的策略一样,第二个副本存放在和第一个副本不同的机架上的节点上,第三个副本存放在同第二个副本相同的机架的不同的节点上
- Spark 的提交方式?
答案:不管是提交到 yarn 上面还是提交到 standalone 上都分为 Client 的方式提交和 Cluster 的方式提交
- 项目的模型训练和项目的准确度是多少?
答:一般在项目的初期准确度一般在百分之85左右就可以了,这个精准度还要根据业务的不断调整去不断的调节
- 项目组多少人?怎么分工的?薪水多少?项目中你负责那一块?
答:这一块大家可以根据要面试的公司规模来提前准备几十人几百人分组都可以,但是薪水一定不要说滴,如果你是10k的工资去面试30k的岗位人家首先会对你产生怀疑的。
- 手写冒泡排序和二分查找?
这个建议大家在去面试之前一定要牢牢的记住怎么写,起码要自己能加拿大的写一个小的demo,这样才能在面试官面前书写流畅。
- 如何将一个标题等在一千万数据中进行进行 Top10 的推荐?
答案:标题向量化,数据清洗和降维,计算相似度,推荐
- kafka 用到了什么
答:消息持久化,消息批量发送,消息有效期,负载均衡方面都可以说,同步异步的问题,但是一定要挑自己熟悉的说
- hadoop 支持三种调度器
答:先进先出的调度器:最早的 hadoop 采用的是 FIFO(默认-先进先出的)调度器调度用户提交的作业。作业按照提交的顺序被调度,作业必须等待轮询到自己才能运行。 但是考虑到公平在多用户之间分配资源,设置了作业的优先级功能,但是不支持抢占式的。
公平调度器:公平调度器的目标是让每一个用户公平的共享集群能力,充分的利用闲置的任务槽,采用“让用户公平的共享集群”的方式分配资源。作业放在作业池之中,每个用户拥有自己的作业池。提交的作业越多并不会因此获得更多的资源,公平调度器支持抢占式的机制,一个作业池中若没有公平的共享资源,则会将多余的资源空出来。
容量调度器:集群中很多的队列组成的,这些队列具有一定的层次结构,每个队列都有一定的容量。每个队列的内部支持 FIIFO 方式。本质上容量调度器允许用户或则组织模拟出一个使用 FIFO 调度策略的独立 MApReduce 集群
- 编写 mapreduce 的方式:
java 编写-常用 Hadoop Streaming:使用 unix 标准的输入和输出流作为 hadooop 和应用程序之间的接口,支持像Ruby,python 等不同的编程语言编写 map 和 reduce Hadoop Pipes 是 hadoop 提供的 C++ 的接口的名称
- hive 保存元数据的方式有三种:
1:自带的内存数据库 Derby 方式保存,只支持单个会话,挺小,不常用
2:本地 mysql :常用本地调用 3:Remote 远程 mysql 方式:远程调用
- hadoop 二级排序:
hadoop 默认的是对 key 进行排序,如果想要再对 value 进行排序,那么就要使用:二级排序 二级排序的方式: 1:将 reduce 接收到的 value-list 的值缓存,然后做 reduce 内排序,再写出,这样排序速度快一些,由于value-list 的数据可能很庞大,可能会造成内存的溢出 2:将值的一部分或则整个部分加入 key ,生成一个合并的可以。生成组合 key 的过程很简单。我们需要先分析一下,在排序时需要把值的哪些部分考虑在内,然后,把它们加进 key 里去。随后,再修改 key 类的 compareTo 方法或是 Comparator 类,确保排序的时候使用这个组合而成的 key。
- 内部表&外部表
hive 的内部表和外部表的區別是 hive 的内部表是由 hive 自己管理的,外部表只是管理元数据,当删除数据的时候,内部表会连数据和元数据全部删除,而外部表则只会删除元数据,数据依然存放在 hdfs 中。外部表相对来说更加的安全一些,数据的组织也更加的灵活一些,方便共享源数据
下面来点数据结构方面的题转换一下思路 手写数据结构和算法:比较重要,基础中的基础
-
冒泡排序
private static void bubbleSort(int [] array){
int temp=0;
for(int i=0;i
array[j]=array[j+1];
array[j+1]=temp;
}}}} -
二分查找
public static int binarySearch(int srcArray,int des){
int low=0;
int height=srcArray.length-1;
while(low<=height){
int middle=(low+height)/2;
if(des==srcArray[middle]){
return middle;
}else if(des
}else{
low=middle+1;
}
}
return -1;
} -
递归的方式实现:
public static int binarySearch(int[] dataset;int data,int beginIndex,int endIndex){ int midIndex=(beginIndex+endIndex)/2;
if(data
return -1;
}
if(data
return binarySearch(dataset,data,midIndex+1,endIndex); }else{
return midIndex;
}
} -
单链表反转
class ListNode { int val; ListNode next;
ListNode(int x) {
val = x;
} }
public static ListNode reverseList(ListNode head){
ListNode prev=null;
while(head != null){
ListNode temp=head.next;
head.next=prev;
prev =head;
head =temp;
}
return prev;
} -
插入排序:
初始时假设第一个记录自成一个有序序列,其余记录为无序序列。接着从第二个记录开始,按照记录的大小依次将当前处理的记录插入到其之前的有序序列中,直至最后一个记录插入到有序序列中为止
public static void insertSort(int[] a){
int temp;
for(int i=1;i0;j--){
if(a[j-1]>a[j]){
temp=a[j-1]
a[j-1]=a[j]
a[j]=temp
}
}
}
}
- 选择排序:
把最小或者最大的选择出来 对于给定的一组记录,经过第一轮比较后得到最小的记录,然后将该记录与第一个记录的位置进行交换;接着对不包括第一个记录以外的其他记录进行第二轮比较,得到最小的记录并与第二个记录进行位置交换;重复该过程,直到进行比较的记录只有一个时为止。
public static void selectSort(int[] a){
if (a == null || a.length <= 0) {
return;
}
for(int i=0;i
数据结构在面试方面基本上就是这些内容,下面继续给大家展示一下有关 hive/hbase 方面的面试题
- 你认为用 Java、streaming、pipe 方式开发 map/reduce , 各有哪些优点
就用过 java 和 hiveQL。 Java 写 mapreduce 可以实现许多复杂的逻辑思维,但是一旦对于简单的需求来说太过于繁琐。
HiveQL 基本的针对对象是 hive 上的表,但是一旦遇到很复杂的逻辑的话就去实很难去实现。对于语句书写方面来说还是很简单的。
- hive 有哪些方式保存元数据,各有哪些优点
三种:自带内嵌数据库 derby,挺小,不常用,最致命的是只能用于单节点。
- 请简述 hadoop 怎样实现二级排序(对 key 和 value 双排序)
第一种方法是,Reducer 将给定 key 的所有值都缓存起来,然后对它们在 Reduce 内部做一个内排序。但是,由于 Reducer 需要缓存给定 key 的所有值,数据量多的话可能会导致内存不足。
第二种方法是,将值的一部分或整个值键入到原始 key 中,重新组合成一个新的 key 。这两种方法各有各的特点,第一种方法编写简单,但是需要较小的并发度,数据量大的话可能会造成内存耗尽卡死的状态。 第二种方法则是将排序的任务交给 MapReduce 框架进行 shuffle,更符合 Hadoop/Reduce 的设计思想。
- 请简述 mapreduce 中的 combine 和 partition 的作用
答:combiner 是发生在 map 的最后一个阶段,其原理也是一个小型的 reducer,主要作用是减少输出到 reduce 的数据量,提高网络传输瓶颈,提高 reducer 的执行效率。 partition 的主要作用将 map 阶段产生的所有 k,v 对分配给不同的 reducer task 处理,可以将 reduce 阶段的处理负载进行分摊。
- hive 内部表和外部表的区别
Hive 向内部表导入数据时,会将数据移动到数据仓库指向的路径;若是外部表,用户在建表的时候就要确定表的位置 在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。 这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
- Hbase 的 rowKey 怎么创建比较好?
答:rowkey 的设计一定要有规则并且有序,常用的一些 rowkey 一定要连续连续,并且 rowkey的设计规则最好加入以后要查询的规则在里面方便日后校对查询。
- 列族的创建:
根据业务的特点对数据进行归类。
- 用 mapreduce 怎么处理数据倾斜问题
本质:让各个分区的数据均匀分布,并且根据自己的业务特点设置合适的 partition 策略,具体的设置方法可以上网查询一下,这里就不过多的介绍了。如果事先不知道业务数据的分布规律,只能利用随机抽样之后生成 partition 策略后再做处理
- hadoop 框架怎么来优化
答:可以从很多方面来进行:比如 hdfs,mapreduce,yarn 的 job 调度,hbase,hive 可以优化的有太多地方了,具体要在哪里优化只能看你数据的特点了,根据真实场景来判断。
- hbase 内部机制是什么
答:Hbase 是一个能适应联机业务的数据库系统 物理存储:hbase 的持久化数据是存放在 hdfs 上 存储管理:一个表是划分为很多 region 的,这些 region 分布式地存放在很多 regionserver 上
版本管理:hbase 中的数据更新本质上是不断追加新的版本,通过 compact 操作来做版本间的文件合并 Region 的 split 集群管理:zookeeper + hmaster(职责) + hregionserver(职责)
- 我们在开发分布式计算 job 的时候,是否可以去掉 reduce 阶段
答:可以,如果不涉及到有关数据的计算的话还是可以省才去 mapreduce 阶段的
- hadoop 中常用的数据压缩算法
答:Lzo,Gzip,Default,Snapyy 如果要是对数据进行压缩的话最好将数据转化一下:quenceFile 或者 Parquet File(spark)
- mapreduce 的作业调度模式
答: 公平调度器:为每个任务分配资源的方法,按照作业的优先级高低,再按照到达时间的先后选择被执行的作业
- hive 底层与数据库交互原理
答:Hive 的查询功能是由 hdfs 和 mapreduce 结合起来实现的,对于大规模数据查询还是不建议在 hive 中,因为过大数据量会造成查询十分缓慢。 Hive 与 mysql 的关系:只是借用 mysql 来存储 hive 中的表的元数据信息,称为 metastore
- 现场出问题测试 mapreduce 掌握情况和 hive 的 ql 语言掌握情况
答:这个就要看大家的功底了,现场问题我也想不出来。
- datanode 在什么情况下不会备份数据
答:在客户端上传文件时指定文件副本数量为1,但是基本我们做大数据都是设置副本的数量是,这个还要根据自己公司的情况而定。
- combine 合并出现在哪个过程
答:shuffle 过程中具体来说,combine 之不过是一个特殊的 reduce 而已,并且发生在本地,累加 map 里面 key 的值然后发给 reduce 处理
- hdfs 的体系结构
答:集群架构:
namenode datanode secondarynamenode journalnode zkfc 这个是简单的基本架构,在文章末尾我会找一下架构图形提供给大家参考。
- flush 的过程
答:flush 是在内存的基础上进行的,首先写入文件的时候,会先将文件写到内存中,当内存写满的时候,一次性的将文件全部都写到硬盘中去保存,并清空缓存中的文件,
- 什么是队列
答:就是一种简单的调度策略,先来先进,先进先出
- Spark 都有什么算子?
答案:map,reducebykey,filter,mapPartition,flatmap,cogroup,foreach,first,take, join, sortBy,distinct,等等
- List 与 set 的区别
答:List 和 Set 都是接口。他们各自有自己的实现类,有无顺序的实现类,也有有顺序的实现类。 最大的不同就是 List 是可以重复的。而Set是不能重复的。 List 适合经常追加数据,插入,删除数据。但随即取数效率比较低。 Set 适合经常地随即储存,插入,删除。但是在遍历时效率比较低。
- 数据的三范式
答: 第一范式()无重复的列 第二范式(2NF)属性完全依赖于主键 [消除部分子函数依赖] 第三范式(3NF)属性不依赖于其它非主属性 [消除传递依赖]
- 三个 datanode 中当有一个 datanode 出现错误时会怎样?
答:Namenode 会第一时间通过心跳发现 datanode 下线,并且通过副本策略将这个 datanode 上的block 快重新发送分配到集群中并且重新复制一份保持每个 block 块的副本数量不变。在此同事运维团队一定要第一时间被通知到处理这个问题,尽快维修上线
- sqoop 在导入数据到 mysql 中,如何不重复导入数据,如果存在数据问题,sqoop 如何处理?
答:FAILED java.util.NoSuchElementException 此错误的原因为 sqoop 解析文件的字段与 MySql 数据库的表的字段对应不上造成的。因此需要在执行的时候给 sqoop 增加参数,告诉 sqoop 文件的分隔符,使它能够正确的解析文件字段。 hive 默认的字段分隔符为 ‘\001’
- MapReduce 优化经验
答:1.设置合理的 map 和 reduce 的个数。合理设置块的大小,要注意一个任务对应一个 map 2避免数据倾斜,合理分配数据对应的 key,尽量对 sql 进行优化 3 combine 函数 4 对数据进行压缩处理,必要的时候对数据进行拆分。 5小文件处理优化:事先合并成大文件,combineTextInputformat,在 hdfs 上用 mapreduce 将小文件合并成 SequenceFile 大文件(key: 文件名,value:文件内容),并且要定期在非工作时间做一次大合并,但是要提前估算好工作量,因为大合并期间所有任务是没办法执行的。 6参数优化,具体什么参数比较多大家可以自行百度。
- 请列举出曾经修改过的 /etc/ 下面的文件,并说明修改要解决什么问题?
答:/etc/profile 这个文件,主要是用来配置环境变量。让 hadoop 命令可以在任意目录下面执行。但是每个开发人员都有自己的目录设置习惯,这个需要根据自己的习惯具体来回答。 /ect/sudoers /etc/hosts /etc/sysconfig/network /etc/inittab
-
请描述一下开发过程中如何对上面的程序进行性能分析,对性能分析进行优化的过程。
-
现有 1 亿个整数均匀分布,如果要得到前 1K 个最大的数,求最优的算法。
参见《海量数据算法面试大全》
- mapreduce 的大致流程
答:主要分为八个步骤
对文件进行切片,提前想好块的大小如何分配
启动相应数量的 maptask 进程
调用 FileInputFormat 中的 RecordReader,读一行数据并封装为 k1v1
调用自定义的 map 函数,并将 k1v1 传给 map,一个任务对应一个 map
收集 map 的输出,进行分区和排序,这块要注意优化。
reduce task 任务启动,并从 map 端拉取数据
reduce task 调用自定义的 reduce 函数进行处理
调用 outputformat 的 recordwriter 将结果数据输出
- 搭建 hadoop 集群 , master 和 slaves 都运行哪些服务
答:master 是主节点,slaves 是从节点
- hadoop 运行原理
答:hadoop 的主要由两部分组成,HDFS 和 mapreduce,HDFS 就是把数据进行分块存储。 Mapreduce 的原理就是使用 JobTracker 和 TaskTracke r来进行作业的执行。Map 就是将任务展开,reduce 是汇总处理后的结果。简单的来说就是提交一个 jar 包,这个时候需要 mapreduce 来处理。
- HDFS 存储机制
答:HDFS 主要是一个分布式的文件存储系统,由 namenode 来接收用户的操作请求,然后根据文件大小,以及定义的 block 块的大小,将大的文件切分成多个 block 块来进行保存,这里存在的优化问题点比较多,前期处理不好可能会造成后期的数据倾斜比较严重。
- 举一个例子说明 mapreduce 是怎么运行的。
自带的实例 Wordcount,但是最好是自己准备一个写熟了的例子。
- 如何确认 hadoop 集群的健康状况
答:有完善的集群监控体系(ganglia,nagios) Hdfs dfsadmin –report Hdfs haadmin –getServiceState nn1
选择题(此部分来源于网络筛选)
- 下面哪个程序负责 HDFS 数据存储。 答案 C
a) NameNode b) Jobtracker c) Datanode d) secondaryNameNode e) tasktracker
- HDfS 中的 block 默认保存几份? 答案 A
a) 3 份 b)2 份 c) 1 份 d) 不确定
- 下列哪个程序通常与 NameNode 在一个节点启动?
a) SecondaryNameNode b) DataNode c) TaskTracker d) Jobtracker e) zkfc
- Hadoop 作者 答案 D
a) Martin Fowler b) Kent Beck c) Doug cutting
- HDFS 默认 Block Size 答案 B
a) 32MB b) 64MB c) 128MB
- 下列哪项通常是集群的最主要瓶颈 答案 D
a) CPU b)网络 c)磁盘 d)内存
- 关于 SecondaryNameNode 哪项是正确的? 答案 C
a) 它是 NameNode 的热备
b) 它对内存没有要求 c) 它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间 d) SecondaryNameNode 应与 NameNode 部署到一个节点
- 配置机架感知[M3] 的下面哪项正确 答案 ABC
a) 如果一个机架出问题,不会影响数据读写 b) 写入数据的时候会写到不同机架的 DataNode 中 c) MapReduce 会根据机架获取离自己比较近的网络数据
- Client 端上传文件的时候下列哪项正确 答案 BC
a) 数据经过 NameNode 传递给 DataNode b) Client 端将文件切分为 Block,依次上传 c) Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作
- 下列哪个是 Hadoop 运行的模式 答案 ABC
a )单机版 b) 伪分布式 c) 分布式
- Cloudera 提供哪几种安装 CDH 的方法 答案 ABCD
a )Cloudera manager b) Tar ball c) Yum d) Rpm
判断题(此部分来源于网络筛选):
-
Ganglia 不仅可以进行监控,也可以进行告警。( X )
-
Block Size 是不可以修改的。( X )
-
Nagios 不可以监控 Hadoop 集群,因为它不提供 Hadoop 支持。( X )
-
如果 NameNode 意外终止, SecondaryNameNode 会接替它使集群继续工作。( X )
-
Cloudera CDH 是需要付费使用的。( X )
-
Hadoop 是 Java 开发的,所以 MapReduce 只支持 Java 语言编写。( X )
-
Hadoop 支持数据的随机读写。(X )
-
NameNode 负责管理 metadata, client 端每次读写请求,它都会从磁盘中读取或则 会写入 metadata 信息并反馈 client 端。(X )
-
NameNode 本地磁盘保存了 Block 的位置信息。(X )
-
DataNode 通过长连接与 NameNode 保持通信。( X )
-
Hadoop 自身具有严格的权限管理和安全措施保障集群正常运行。(X )
-
Slave节点要存储数据,所以它的磁盘越大越好。(X )
-
hadoop dfsadmin –report 命令用于检测 HDFS 损坏块。( X)
-
Hadoop 默认调度器策略为 FIFO( 正确)
-
集群内每个节点都应该配 RAID,这样避免单磁盘损坏,影响整个节点运行。(X )
-
因为 HDFS 有多个副本,所以 NameNode 是不存在单点问题的。(X )
-
每个 map 槽(进程)就是一个线程。(X )
-
Mapreduce 的 input split 就是一个 block。(X )
-
NameNode的默认 Web UI 端口是 50030,它通过 jetty 启动的 Web 服务。(X )
-
Hadoop 环境变量中的 HADOOP_HEAPSIZE 用于设置所有 Hadoop 守护线程的内存。它默认是200 GB。( X )
-
DataNode 首次加入 cluster 的时候,如果 log中报告不兼容文件版本,那需要 NameNode执行“Hadoop namenode -format ”操作格式化磁盘。(X )
-
面试面试官问了你们每天有多少数据,用了多少台机器
答: 一般根据你写的项目,每天产生的数据量规划,假如一天数据量100G 一般集群 规划是年数据量的3倍还要多一点这样算下来大概需要60台左右的机器才能保障运行。
- 每天运行多久
答:一般一个作业10分钟到-几个小时不等 一般一个作业也就几十分钟。。运行几天的很少
- 有多少个 MR
答:30-50个左右 一般公司很多个作业。。 你可以说你们部门的,其他你不清楚就别说,,相应你简历上写的项目,很多模板都有作业。。细化一下 比如推荐的作业,统计汇总的作业,用户定位的作业
- 遇到 bug 怎么解决,上线之后的 bug 怎么解决
答:一般在测试阶段就那部分线上数据测试过了。。 如果在线上还有问题一般 kill 掉作业。。当然可以做 mapreduce 里面设计日志输出到单独文件,, 根据 hadoop 异常日志出什么问题了。。当然 hadoop 每台都会有日志,当然 hadoop 自己的日子很庞大,可以采用 chukwa(大概看看干什么的就行,就是收集方便查看 hadoop 本身的日志)处理然后分析作业代码。
- 有没有关心过运行时候的状态
答:mapreduce 运行状态,hadoop 有监控页面,当然也可以自己写监控程序,mapreduce 有作业监听方法,可以获取进度。
- 每台机器的负载
答:采用 ganglia,nagios,zabbix 监控工具监控机器磁盘,内存,cpu 你只需要回答采用这些弄得 具体运维部弄得。当然你研究过会更好
- 宽窄依赖?
答:除了父 RDD 和子 RDD 一对多外,其他的都是窄依赖
- spark on yarn 和 mapreduce 中 yarn 有什么区别?
答:没有什么区别,yarn 就是一种任务调度框架
- spark 运行的 job 在哪里可以看到?
答: 一般是在 WEBUI 上 查看,如果问具体怎么配置的可以推到运维人员身上
- 用 scala 写一个 wordcount ?
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val lines = List("hello java hello python","hello scala","hello scala hello java hello scala")
// 切块
val words = lines.flatMap(_.split(" "))
// 生成pair
val tuples = words.map((_,1))
// k,v分组
val grouped = tuples.groupBy(_._1)
val sumed = grouped.mapValues(_.size)
// 排序
val sorted = sumed.toList.sortBy(_._2)
// 降序
val result = sorted.reverse
println(result)
}
}
- 对 scala 的了解 有用过 play framework 框架吗
答:是一个纯java框架,可以进行快速开发,开发周期较短,并且能够快速建立一个java web所需要的所有内容。
- scala 中的隐式函数的关键字?
答:implicit
- val x=y=1 结果是什么?
答:会报错
- 编译好的 scala 程序,运行的时候还需要 scala 环境吗?
答:不需要
- 画下项目的架构图介绍下项目?介绍下你做的哪些方面?
答:这个大家最好提前自己画一画,这样每一步对应的数据流程都是你自己最熟悉的,这样才显的最真实,特别是没有从事过大数据行业的人难免会心里发虚。我在文章的最上部简单的画了一下架构图,大家可以照着参考一下。
- 介绍下 kafka 容错性
kafka 不像集群最少需要三台机器,假如有三个 kafka,如果坏了两个,那么剩下的一个就是主 leader,并且依然正常运行,这就是kafka 的容错性
- zookeeper 原子广播协议
这个协议的英文名字是 ZooKeeper Atomic Broadcast,这个协议的主要作用是保证大数据分布的一致性,通过主备方式保证副本的一致性。
- hbase 优化 rowkey 设计
答:rowkey 的作用一般是用来检索数据用的无非有几种方式,按照某个固定的键值对进行检索,或者在一定范围内进行扫描,因为rowkey 是按照字典序存储的,所以在设计 rowkey 的时候要充分的利用这一点,把经常要查询的数据设计在一起,并且可以加上时间戳也是一个办法。
- 内部表外部表的区别 hdfs 数据导入到 hive 的语法
答:首先我们来讲一下建表时的不同,在创建内部表的时候,数据的指向会指向数仓的路径,但是在创建外部表的时候,仅仅只是记录数据的一个路径,数据不会像数仓移动,数据的位置不会改变。 我们再讨论删除表的不同,那就是在删除内部表的同时,元数据和数据都会被一起删除,而在删除外部表的时候只删除元数据并不会删除数据,相比之下外部表还是比较灵活的。 至于从 hdfs 导入 hive 的语法我举个例子:load data inpath ‘/’ into table test;
- spark 提交任务的流程
在这里我找了一个网图,相信看图来的更加直接一些。
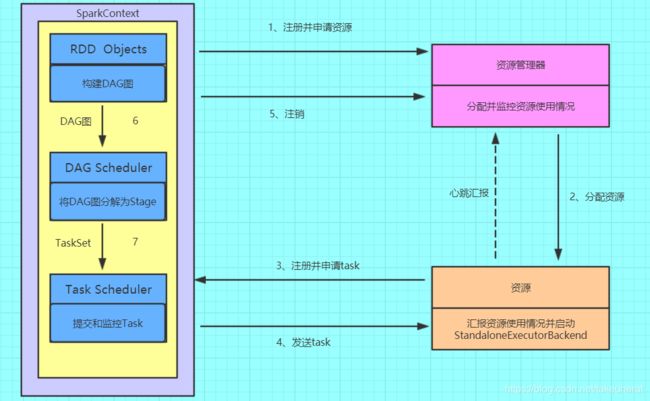
- cache 和 persist 的区别
答:cache 只有一个缓存级别可以设置,但是 persist 可以设置多个级别的缓存级别。
123.reduceBykey 和 groupByKey哪个快?
当然是 reduceBykey 比较快,在到 reduce 端之前会对要传输的结果进行一个本地的 merge,这样到达 reduce端的数据就会大幅度的减少,而 groupbykey 会对每一个过来的 RDD 进行一个序列化,并且这个过程是发生在 reduce 端进行执行的,所以会造成一旦数据量过大的时候会造成内存溢出等麻烦,所以建议还是尽量少用比较好。
- 随便写一个算法
答:在这里我就说一下一般会用到哪些算法,至于每个算法的 demo 大家可以自行百度一下,常用的有推荐算法(CB,CF),分类算法(SVM,NB),聚类算法(层次聚类,K-means),回归算法。
- 工厂模式
答:工厂模式一般分为三种: 简单工厂模式、工厂方法模式、抽象工厂模式
- hive on spark 了解过吗?
答:说实话 hive on spark 跟 hive 没有多大的关系,只不过 hive 一直在用MR这样在数据量庞大的时候就造成速度过慢的情况,这个时候就要将逻辑转换成 RDD 模式,这样在集群中跑的话速度明显就上来了,只不过就是继续延续了hive的标准而已。
- udf 和 uda f写过吗?有什么区别?有一个场景,用 udf 实现一个字段自增怎么弄?
答:这块涉水比较深,建议大家对答案简单掠过就好,UDF 是自定义函数,一般是一进一出,而 UDFA 是自定义聚合函数,多进一出。 这个字段自增我就找了一个模板让大家借鉴一下,最好在面试之前自己准备一下。 import org.apache.hadoop.hive.ql.exec.Description; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.hive.ql.udf.UDFType; import org.apache.hadoop.io.LongWritable; /* * UDF RowSequence */ @Description(name = “autosequence”, value = “FUNC_() - Returns a generated row sequence number starting from 1”) @UDFType(deterministic = false) public class RowSequence extends UDF { private LongWritable result = new LongWritable(); public RowSequence(){ result.set(0); } public LongWritable evaluate(){ result.set(result.get() + 1); return result; } }
- kafka 数据落地磁盘有哪些好处?
答:1、缓存由 linux 本身进行维护 2、磁盘的顺序读写速度完胜内存读写速度 3、避免占用内存过大的情况 4、不惧怕系统冷启动
- storm 的容错机制
在这里我找了一个架构图大家先直面的看一下

在非 nimbus 服务器有节点故障时,nimbus 会将这些 task 任务分配出去,比如 worker 挂掉时会快速失败,并且能保障消息完整性的实现机制。
- 怎么优化 shffle
答:hashshufflemanager 可以开启 consolidate 机制、bypass 运行机制、或者修改一些参数如下 spark.shuffle.file.buffer spark.reducer.maxSizeInFlight spark.shuffle.io.maxRetries spark.shuffle.io.retryWait spark.shuffle.memoryFraction spark.shuffle.manager spark.shuffle.sort.bypassMergeThreshold spark.shuffle.consolidateFiles
- rdd 怎么转 dataFrame
答:可以通过反射的方式来推断元数据,因为 RDD 本身是没有元数据的,通过反射就可以了解这些元数据并且进一步转换成 dtaframe
- OOM 的原因?
答:首先可以分析一下这个是栈溢出还是堆溢出,然后再根据溢出类型进一步分析是什么原因。
- 问我 spark、jdk、scala 的版本
JDK:1.8 SPARK:2.2.0 SCALA:2.11.8 HADOOP:2.6.5
134.zookeeper 脑裂
答:脑裂就是在当只有两台 cluster 的时候,会选择一个作为 master 但是如果这两台机器存在通信问题的话就会产生两个 master,这就是脑裂。zookeeper 一般会采用 quorums 的方式,只有当集群超过半数的时候才会投票选举出一个 master 来保障集群的可用性。
- 多线程有几种创建方式?
1、runnable 创建 threa 线程 2、callable 创建线程 3、thread 创建线程 4、exctor 创建线程池
- 代码怎么确定二叉树的高度?
答:可以用后序遍历二叉树,层次遍历二叉树,递归遍历二叉树
- 为什么选择 kafka kafka 为什么快
答:因为kafka是落地磁盘,顺序读取磁盘的速度要远高于内存读取。
- spark 和 storm 的区别?
答:storm是对大量的小型数据块进行处理,并且是动态数据 spark一般是对大量数据进行进行全集处理,并且侧重传输数据的过程
- persist 和 checkpoint 的区别
答:persits一般是将数据持久化到磁盘上但是一旦进程被停掉的话,在磁盘上的数据也会同时被清空 而checkpoint 是将 RDD 持久化到 HDFS 上的,如果不手动删除的话是一直存在的。
- spark 和 mapreduce 的对比
答:MR 一般处理大量数据的时候一般会存在高延迟,浪费时间,对于一些有时间要求的业务就很不适合。但是如果用 spark 处理的话就非常快了,特别是对于实时动态处理的过程。
下面我会针对人事简历方面的问题总结一下我的想法
- 对于项目问题如何写简历
答:千万不要写一堆配置信息,人家以为你是搞运维的,并且最好写一些公司的大数据项目,之前的一些java项目就不要往上写了,并且一定要写技术细节,业务场景,业务模块,一定要写自己最熟悉的。
- 为什么要从上家公司离职?
答:千万不要说:上家公司外包太累、加班太多、领导不好,可以从技术发展的角度去谈
- 面试完,面试官问你有什么还需要问我的问题
答:尽量请教一些技术问题,最好在面试前就针对公司的业务介绍准备一些问题,切记千万不要问录用不录用的问题,对于期望的薪资如果技术回答的不错可以适当的多要一点,一般三年工作经验的都在 16K 以上。
- 面试和复习问题
答:面试后回家应该立马写总结,今天问了哪些问题,哪些没有回答好,哪些问题都没听过,对应自己的简历进行修改更新。写简历就要把自己当成面试官。
- 专业技能要有侧重点
答:对于自己熟悉的技能要有自己的侧重点,比如 spark 很熟,着重写spark的着重点,写上简历的一定要会,否则面试官可能认为你在欺骗他。
- 是否有自己的博客,个人的技术栈
答:一定要写这一项,这一项说明你热爱技术,善于学习总结,乐于分享,并且利用自己的业余时间投入到自己的事业当中。
- 专业技能,至少写的有层次感
答:分块写:比如 1) 按层次写 2) 比如hadoop 3) 实时计算 4) 机器学习 5) 编程语言等等
- 简历
答:写清楚工作经历 每个时间段,在哪个公司工作,什么职位 项目名称: 写为 XXX公司XXX系统或平台(必须带上公司名称) 项目架构:写清楚使用到那些技术 比如 flume+kafka+hadoop+hbase+mapreduce+spark等等 总体人数:10人 项目描述:根据项目解决问题,一共有哪些功能写,功能不一定要写你都做过,因为这里只是描述 责任描述: 你负责的模块,写大的功能,不要写实现细节 解决问题:描述这个问题即可,怎么解决,面试的时候去说 项目最好设计 以 storm spark mahout 相关
- 自己的优缺点
答:这个问题很不好回答,最好的回答就是不要回答,谈谈自己的兴趣爱好逐渐转移到技术点位上
- 为什么来北京发展
答:这个问题就是面试官想确定你的工作态度是否稳定,也可以谈谈要在北京定居,以后就在北京发展的事。
下面我们最后来说一下异地灾备的问题
现在大多数的公司的数据存储都是在本地而不是异地,这样在数据和业务上就存在很大的风险,一旦本地发生火灾或者重大人员事故真实想哭都不知道怎么哭,所以在经济条件允许的条件下还是要做异地备份。但是条件不允许怎么办,我们可以对办公区进行数据分离,将简单的备份文件传输到不同业务区的(除主存储)的备份机房。这个过程重中之重的就是数据的保密性,安全性,并且敏感数据最好进行数据脱敏,对于数据一定要加密存储,一定小心不要弄丢密码。