聊聊Android线程优化这件事
一、背景
在日常开发APP的过程中,难免需要使用第二方库和第三方库来帮助开发者快速实现一些功能,提高开发效率。但是,这些库也可能会给线程带来一定的压力,主要表现在以下几个方面:
- 线程数量增多:一些库可能会在后台启动一些线程来执行任务,这样会增加系统中线程的数量,从而导致系统资源的浪费。
- 线程竞争:一些库可能会在同一时间启动多个线程来执行任务,这样会导致线程之间的竞争,从而影响程序的执行效率。
- 线程阻塞:一些库可能会在执行任务时阻塞主线程,从而导致程序的卡顿和响应速度变慢。
二、整体思路
为了解决使用第二方库和第三方库代理的线程问题,我选择用下面的思路来进行线程优化:
- 线程检测,评估优化空间。
- 线程统计,收集优化范围。
- 线程和线程池优化,线程数收敛。
- 线程栈裁剪,减少线程内存。
三、具体方案
1. 线程检测
最常见的几种获取线程信息的方式如下

为了有完整的线程统计,而且能实时了解运行过程中线程数的变化,那我们就选择了读取伪文件系统里面线程信息的方式。
/**
* 获取所有线程信息
*/
private fun getThreadInfoList(): List? {
//获取伪文件所有的线程信息文件
val file = File("/proc/self/task")
...
//遍历task文件目录下
for (threadDir in listFile) {
//读取每个目录下的status文件获取单个线程信息
val statusFile = File(threadDir, "status")
if (statusFile.exists()) {
val threadInfo = ThreadInfo()
try {
BufferedReader(InputStreamReader(FileInputStream(statusFile))).use { reader ->
var line: String
hitFlag = 0
while (reader.readLine().also { line = it } != null) {
if (hitFlag > 2) {
break
}
//解析线程名
if (line.startsWith("Name")) {
val name =
line.substring("Name".length + 1).trim { it <= ' ' }
threadInfo.name = name
hitFlag++
continue
}
//解析线程Pid
if (line.startsWith("Pid")) {
val pid =
line.substring("Pid".length + 1).trim { it <= ' ' }
threadInfo.id = pid
hitFlag++
continue
}
//解析线程状态
if (line.startsWith("State")) {
...
threadInfo.status = state
hitFlag++
}
}
}
} catch (e: Exception) {
Log.e(LOG_TAG, e.toString())
}
threadInfoList.add(threadInfo)
}
}
return threadInfoList
}
最后只需要在APP启动后就开启轮询任务:1,获取伪文件。2,写入数据库。3,更新视图展示。

统计了运行时创建的线程、可用的线程、正在运行的线程。
理想的情况就是可用的线程数应该和正在运行的线程数尽量接近,实际发现差异巨大,所以优化的空间还是蛮值得期待的。
2. 线程统计

了解创建线程和线程池的字节码

如何扫描到创建的线程和线程池
通过插桩的方式,来查找创建线程池和线程的类名,并把这些类名统一输出到一份txt文档。插桩的框架,我选择的是ASM,因为使用ASM进行插桩具有高效性、灵活性、易用性、兼容性和社区活跃等优点,是一种比较优秀的字节码操作框架,对于提高应用程序的性能和可维护性具有重要意义。
那么通过ASM是如何扫描到的呢?
要扫描到创建线程池的类名,你需要使用ASM的访问者模式(Visitor Pattern)来遍历字节码中的方法和指令。在遍历过程中,当遇到创建线程的指令(如:new java/util/concurrent/ThreadPoolExecutor)时,就可以获取到创建线程的类名。
import org.objectweb.asm.*;
public class ThreadPoolDetectorClassVisitor extends ClassVisitor {
public ThreadPoolDetectorClassVisitor(int api, ClassVisitor classVisitor) {
super(api, classVisitor);
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor mv = cv.visitMethod(access, name, desc, signature, exceptions);
return new ThreadPoolDetectorMethodVisitor(api, mv);
}
class ThreadPoolDetectorMethodVisitor extends MethodVisitor {
public ThreadPoolDetectorMethodVisitor(int api, MethodVisitor methodVisitor) {
super(api, methodVisitor);
methodVisitor);
}
@Override
public void visitMethodInsn(int opcode, String owner, String name, String desc, boolean itf)) {
if (opcode == Opcodes.INVOKESTATIC && owner.startsWith("java/util/concurrent/Executors")) {
System.out.println("Detected creation of new ThreadPool!");
}
super.visitMethodInsn(opcode, owner, name, desc desc, itf);
}
}
}
-
统计和分类扫描到的创建线程和线程池的类名
- 扫描到的结果

- 结果进行分类
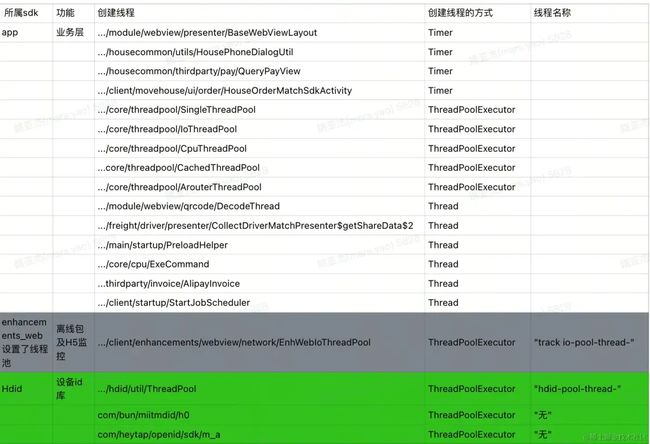
- 结果的用处
- 了解项目现状。
- 对后续优化可以设置白名单。
- 可以对线上设置的线程进行降级处理。
3. 线程和线程池优化

3.1 线程优化
- 对于APP业务层和自研SDK,我们检查是否真的需要直接new thread,能否用线程池代替,如果必须创建单个线程,那我们创建的时候必须加上线程名,方便排查线程问题。
- 对于三方SDK,那就可以通过插桩来重命名(名称必须少于16个字符),方便尽快知道该线程是来自哪个SDK。
3.2 线程池优化
- 对于APP业务层,我们需要提供常用线程池,例如I/O、CPU、Single、Cache等等线程池,避免开发各自创建重复的线程池。
- 对于自研SDK,我们尽量让架构组的开发同学提供可以设置自定义线程池的能力,方便我们代理到我们APP业务层的线程池。
- 对于三方SDK,首先了解有没有提供设置我们自定义线程池的接口,有的话,那就直接设置我们APP业务层的线程池。如果没有这种能力,那我们就进行插桩来进行线程池收敛。在进行三方SDK插桩代理的时候,需要注意三点:
- 设置白名单,进行逐步代理。
- 针对不同的SDK,要区分是本地任务还是网络任务,这样能明确是代理到I/O线程池还是CPU线程池。
- 设置降级开关,方便线上有问题时,及时对单个SDK进行降级处理。
3.2.1 行业方案
(1)反射收敛,但是使用反射来收敛线程池的确有一些潜在的弊端:
- 性能开销:反射在执行时需要进行一系列的检查和解析,这会比直接的Java方法方法调用带来更大的性能开销。
- 安全问题:反射可以访问所有的字段和方法,包括私有有的和受保护的,这可能会破坏对象的封装性,导致安全问题。
- 代码复杂性:使用反射的代码通常比直接的Java代码更复杂,更难理解和维护。
因此,虽然反射是一种强大的工具,但在使用时需要谨慎,尽量避免不必要的使用。
(2)代理收敛,但是使用代理设计模式来收敛线程池也有一些潜在的弊端:
- 增加复杂性:代理方式会引入额外的类和对象,这会增加系统的复杂性。对于简单的问题,使用代理可能会显得过于复杂。
- 代码可读性:由于代理方式涉及到额外的抽象层,这可能会对代码的可读性产生一定的影响。
- 调试困难:由于代理模式的存在,错误可能会被掩盖或者难以定位,这可能会使得调试变得更加困难。
因此,虽然代理模式是一种强大的设计模式,但在使用时也需要考虑到这些潜在的问题。
(3)协程收敛,但是使用协程收敛线程池也有一些局限性和潜在的弊端:
- 需要依赖Kotlin协程库:使用Kotlin协程需要依赖Kotlin协程库,如果应用程序中没有使用Kotlin语言,那么需要额外引入Kotlin库,增加了应用程序的体积。
- 协程的执行时间不能过长:Kotlin协程的执行时间不能过长,否则会影响其他协程的执行。因此,在使用Kotlin协程进行线程收敛时,需要合理控制协程的执行时间。
- 可能会导致内存泄漏:如果协程没有正确地取消,可能会导致内存泄漏。因此,在使用Kotlin协程时,需要注意正确地取消协程。
因此,虽然Kotlin协程可以通过使用协程调度器来实现线程收敛,但是也存在一些弊端,需要开发者根据具体情况来选择是否使用。
(4)插桩收敛,虽然插桩也有一些不足之处:
- 可能影响程序行为:如果插桩代码改变了程序的状态或者影响了线程的线程的调度,那么它可能会改变程序的行为。
- 可能引入错误:如果插桩代码桩代码本身存在错误,那么它可能会引入新的错误到程序中。
但是这些缺点在线程池收敛的时候还是可控的,相比于上面的反射收敛、代理收敛和协程收敛来说,还有许多优点:
- 直接性:插桩直接在代码中插入额外的逻辑,不需要通过代理或反射射间接地操作对象,这使得插桩更直接,更易于理解和控制。
- 灵活活性:插桩可以在任何位置插入代码,,这提供了很大的灵活性。而代理和反射通常只能操作公开的接口和方法。
- 无需修改原始代码:插桩通常常不需要常不需要修改原始的线程池代码,这使得它可以在不影响原始代码的情况下收集信息。
- 颗粒度控制:可以对某个方法或某段代码进行线程收敛,而不是整个应用程序。
综上所述,我就选择了更加通用、灵活、精确的方式来收敛二方和三方的线程池—插桩代理。
3.2.2 代码设计图

3.2.3 代码流程图

暂时无法在飞书文档外展示此内容
3.2.4 代码实施
- 创建NewThreadTrackerPlugin,在插件里主要是获取到需要进行代理的线程池白名单以及注册ThreadTrackerTransform。
class NewThreadTrackerPlugin implements Plugin {
@Override
void apply(Project project) {
System.out.println("ThreadTracker:start ThreadTrackerPlugin")
project.getRootProject().getSubprojects().each { subProject ->
PluginUtils.addProjectName(subProject.name)
PluginUtils.projectPathList.add(subProject.projectDir.toString())
}
org.gradle.api.plugins.ExtraPropertiesExtension ext = project.getRootProject().getExtensions().getExtraProperties()
//通过配置来设置是否需要输出所有创建线程池的txt文件,文件名为"thread_tracker_XXX.txt"
if (ext.has("scanProject")) {
boolean scan = ext.get("scanProject")
PluginUtils.setScanProject(scan)
System.out.println("ThreadTracker:需要扫描项目吗?" + scan)
}
//通过配置来获取需要进行插桩代理的白名单
if(ext.has("whiteList")){
List list = ext.get("whiteList")
PluginUtils.addWhiteList(list)
}else {
System.out.println("ThreadTracker:请创建thread_tracker.gradle文件,设置whiteList白名单")
}
//注册ThreadTrackerTransform。
//Gradle Transform 是 Android 官方提供给开发者在项目构建阶段,即由 .class 到 .dex 转换期间修改 .class 文件的一套 API。目前比较经典的应用是字节码插桩、代码注入技术。
AppExtension appExtension = (AppExtension) project.getProperties().get("android")
appExtension.registerTransform(new ThreadTrackerTransform(), Collections.EMPTY_LIST)
}
}
- 创建 ThreadTrackerTransform,重写ThreadTrackerTransform的transform方法,在该方法里面来遍历文件目录下和Jar包中的class文件,并让ClassReader接受的是我们自定义的ThreadTrackerClassVisitor。
/**
* transform 方法来处理中间转换过程,主要逻辑在该方法中实现。我们可以在 transform 方法中,实现对字节码的修改、处理等操作。
* @param transformInvocation
*/
@Override
void transform(@NonNull TransformInvocation transformInvocation) {
...
//对于一个.class文件进行Class Transformation操作,整体思路是这样的:
// ClassReader --> ClassVisitor(1) --> ... --> ClassVisitor(N) --> ClassWriter
ClassReader classReader = new ClassReader(file.bytes)
ClassWriter classWriter = new ClassWriter(classReader, ClassWriter.COMPUTE_MAXS)
ClassVisitor cv = new ThreadTrackerClassVisitor(classWriter, null)
classReader.accept(cv, EXPAND_FRAMES)
byte[] code = classWriter.toByteArray()
FileOutputStream fos = new FileOutputStream(
file.parentFile.absolutePath + File.separator + name)
fos.write(code)
fos.close()
...
}
- 创建ThreadTrackerClassVisitor,重写visitMethod来返回自定义的MethodVisitor,通过这个对象来访问方法的详细信息。
在visitMethod方法方法中,我们可以插入自己的代码,以修改或替换原有的方法声明声明。例如,我们可以改变方法的访问权限、改变方法的参数、改变方法的返回值,甚至可以完全替换原有的方法声明。
@Override
public MethodVisitor visitMethod(int access0, String name0, String desc0, String signature0, String[] exceptions) {
MethodVisitor mv = cv.visitMethod(access0, name0, desc0, signature0, exceptions);
if (filterClass(className)) {
return mv;
}
return new ProxyThreadPoolMethodVisitor(ASM6, mv, className);
}
/**
*。 过滤掉不需要插桩的类,比如这个插桩代码模块、自定义的线程池等等
**/
private boolean filterClass(String className) {
return className.contains("com/lalamove/threadtracker/") || className.contains("com/lalamove/plugins/thread") || className.contains("com/tencent/tinker/loader") || className.contains("com/lalamove/huolala/client/asm/HllPrivacyManager");
}
- 创建ProxyThreadPoolMethodVisitor,并重写它的visitMethodInsn方法来真实插桩自己的线程池。
在visitMethodInsn方法中,我们可以插入自己的代码,以修改或替换原有的方法调用。
@Override
public void visitMethodInsn(int opcode, String owner, String name, String descriptor, boolean isInterface) {
//如果配置中是需要扫描App,则把创建线程池的类名全部都写在"thread_tracker_XXX.txt"里面,供开发者统计、分类、设置白名单和降级处理
if (PluginUtils.getScanProject()) {
if (owner.equals(O_ThreadPoolExecutor) && name.equalsIgnoreCase("")) {
PluginUtils.writeClassNameToFile("创建ThreadPoolExecutor的类:" + className);
}
}
//如果配置中是需要插桩代理线程池,则把原本的类 "java/util/concurrent/ThreadPoolExecutor"换成了我们自定义的类"com/lalamove/threadtracker/proxy/BaseProxyThreadPoolExecutor"
//mClassProxy只是一个总开关,是否开启代理;具体某个类是否需要代理,在创建线程池的具体地方会根据类名来判断
if (mClassProxy) {
if (owner.equals(O_ThreadPoolExecutor) && name.equalsIgnoreCase("")) {
if ("(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;)V".equalsIgnoreCase(descriptor)) {
mv.visitLdcInsn(className);
mv.visitMethodInsn(opcode, O_BaseProxyThreadPoolExecutor, name, "(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/lang/String;)V", false);
} else if ("(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/util/concurrent/ThreadFactory;)V".equalsIgnoreCase(descriptor)) {
mv.visitLdcInsn(className);
mv.visitMethodInsn(opcode, O_BaseProxyThreadPoolExecutor, name, "(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/util/concurrent/ThreadFactory;Ljava/lang/String;)V", false);
} else if ("(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/util/concurrent/RejectedExecutionHandler;)V".equalsIgnoreCase(descriptor)) {
mv.visitLdcInsn(className);
mv.visitMethodInsn(opcode, O_BaseProxyThreadPoolExecutor, name, "(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/util/concurrent/RejectedExecutionHandler;Ljava/lang/String;)V", false);
} else if ("(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/util/concurrent/ThreadFactory;Ljava/util/concurrent/RejectedExecutionHandler;)V".equalsIgnoreCase(descriptor)) {
mv.visitLdcInsn(className);
mv.visitMethodInsn(opcode, O_BaseProxyThreadPoolExecutor, name, "(IIJLjava/util/concurrent/TimeUnit;Ljava/util/concurrent/BlockingQueue;Ljava/util/concurrent/ThreadFactory;Ljava/util/concurrent/RejectedExecutionHandler;Ljava/lang/String;)V", false);
} else {
mv.visitMethodInsn(opcode, O_BaseProxyThreadPoolExecutor, name, descriptor, false);
}
return;
}
}
super.visitMethodInsn(opcode, owner, name, descriptor, isInterface);
}
上述使用到的一些常量定义如下,也引入到了我们自己自定义的线程池。
class ClassConstant {
//Java里面创建线程池的类名
static final String O_ThreadPoolExecutor = "java/util/concurrent/ThreadPoolExecutor";
//自定义创建线程池的类名
static final String O_BaseProxyThreadPoolExecutor = "com/lalamove/threadtracker/proxy/BaseProxyThreadPoolExecutor";
}
- 创建BaseProxyThreadPoolExecutor,重写了创建线程池的所有构造方法,也通过传入的类名判断了该类里面的线程池是否需要代理,以及代理的是的CPU密集型线程池还是IO密集型线程池。
package com.lalamove.threadtracker.proxy
import android.util.Log
import com.lalamove.threadtracker.TrackerUtils
import java.util.concurrent.*
/**
* ThreadPoolExecutor代理类
*/
open class BaseProxyThreadPoolExecutor : ThreadPoolExecutor {
var mProxy = true
//App层自定义的IO线程池
private var threadPoolExecutor: ThreadPoolExecutor =
TrackerUtils.getProxyNetThreadPool()
constructor(
corePoolSize: Int,
maximumPoolSize: Int,
keepAliveTime: Long,
unit: TimeUnit?,
workQueue: BlockingQueue?,
className: String?,
) : super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue) {
init(corePoolSize,
maximumPoolSize,
keepAliveTime, className)
}
private fun init(
corePoolSize: Int,
maximumPoolSize: Int,
keepAliveTime: Long,
className: String?,
) {
//判断className下创建的线程池是否要被插桩代理
if (className != null) {
mProxy = TrackerUtils.isProxy(className)
}
//单线程暂不代理
if (corePoolSize == 1 || (corePoolSize == 0 && maximumPoolSize == 1)) {
mProxy = false
}
if (!mProxy) {
return
}
//设置核心线程超时允许销毁
if (keepAliveTime <= 0) {
setKeepAliveTime(10L, TimeUnit.MILLISECONDS)
}
allowCoreThreadTimeOut(true)
//设置className的线程池被代理为CPU线程池
if (className != null && TrackerUtils.proxyCpuClass(className)) {
threadPoolExecutor = TrackerUtils.getProxyCpuThreadPool()
}
}
...
override fun submit(task: Runnable): Future<*> {
return if (mProxy) threadPoolExecutor.submit(task) else super.submit(task)
}
override fun execute(command: Runnable) {
if (mProxy) threadPoolExecutor.execute(command) else super.execute(command)
}
//注意:不能关闭,否则影响其他被代理的线程池
override fun shutdown() {
if (!mProxy) {
super.shutdown()
}
}
//注意:不能关闭,否则影响其他被代理的线程池
override fun shutdownNow(): MutableList {
val list = if (mProxy) mutableListOf() else super.shutdownNow()
return list
}
}
3.2.5 实施代理
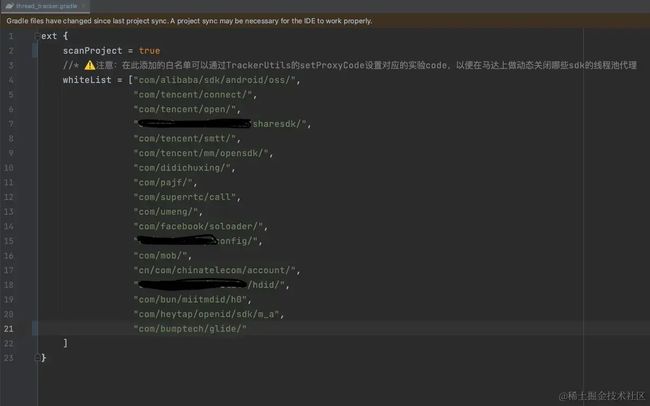
- 在工程最外层创建thread_tracker.gradle,里面可以设置需要代理的线程池白名单。
- 通过打印日志就能看出白名单里面的线程池是否被代理成功。

- 设置降级开关
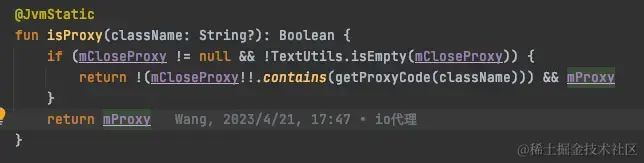
(1)设置每个SDK里面细分类名对应的code

(2)在配置系统上设置需要关闭SDK,设置上面对应的code码即可。

(3)在APP初始化的时候尽可能早的获取配置系统上的code字符串

(4)在进行代理的时候,会匹配code字符串,来决定具体的线程池是否进行代理。
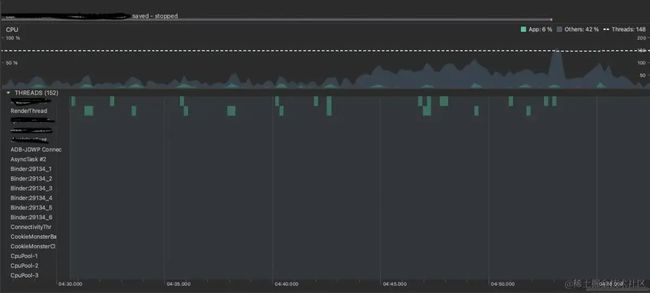
3.2.6 代理后的收益
- 累计减少了大约40条线程的开销

4. 线程栈裁剪
4.1 裁剪方式
创建线程的时候,线程默认的栈空间大小为 1M 左右,经过测试大部分情况下线程内执行的逻辑并不需要这么大的空间,因此线程栈空间减小,可以对内存这块有明显的优化。

接下来我们来看下函数FixStackSize源码,是怎么设置线程栈默认为1M的?
static size_t FixStackSize(size_t stack_size) {
//参数是java层中thread 的stack_size默认0
if (stack_size == 0) {
stack_size = Runtime::Current()->GetDefaultStackSize();
}
// 默认栈大小是 1M
stack_size += 1 * MB;
//...
if (Runtime::Current()->ExplicitStackOverflowChecks()) {
stack_size += GetStackOverflowReservedBytes(kRuntimeISA);
} else {
8k+8K
stack_size += Thread::kStackOverflowImplicitCheckSize +
GetStackOverflowReservedBytes(kRuntimeISA);
}
//...
return stack_size;
}
发现函数的源码实现就是通过 stack_size += 1 * MB 来设置 stack_size 的: 如果我们传入的 stack_size 为 0 时,默认大小就是 1 M ; 如果我们传入的 stack_size 为 -512KB 时,stack_size 就会变成 512KB(1M - 512KB)。 那我们是不是只用带有 stack_size 入参的构造函数去创建线程,并且设置 stack_size 为 -512KB 就行了呢? 应用中创建线程的地方太多很难一一修改,前面我们已经将应用中的线程部分收敛到自定义的线程池中去了,所以只需要修改自定义线程池中创建的线程方式即可。在我们自定义的 ThreadFactory 中,创建 stack_size 为 - 512 KB 的线程,这么一个简单的操作就能减少线程所占用的虚拟内存。
package com.lalamove.threadtracker.proxy
import java.util.concurrent.ThreadFactory
import java.util.concurrent.atomic.AtomicInteger
open class ProxyThreadFactory : ThreadFactory {
override fun newThread(runnable: Runnable): Thread {
val mAtomicInteger = AtomicInteger(1)
return Thread(null, runnable, "Thread-" + mAtomicInteger.getAndIncrement(), -512 * 1024)
}
}
需要注意是线程栈大小的设置需要根据具体的应用场景来进行调整。 如果线程栈大小设置得过小,可能会导致栈溢出等问题; 如果设置得过大,可能会浪费过多的内存资源。 因此,在进行线程栈大小设置时,我这边会设置一个动态的裁剪值,即使有线上问题,我们也可以进行适当的调整,以保证程序的正常运行。
4.2 裁剪后的收益
- 通过火山引擎的APP性能分析平台对比发现,内存平均值减少了20M

- 通过Profiler实测,发现和火山引擎检测结果相近
| 方式 | Total(单位:M) | Java(单位:M) | Native(单位:M) | Graphics(单位:M) | Stack(单位:M) | Code(单位:M) | Others(单位:M) |
|---|---|---|---|---|---|---|---|
| 关闭代理 | 492.4 | 61.1 | 181.6 | 57.9 | 0.2 | 144.7 | 46.9 |
| 开启代理 | 464.3 | 58.2 | 158.6 | 64.5 | 0.1 | 139 | 43.8 |
![]()

四、收益和踩坑
1. 收益
- 优化之前,线程数为197条;优化之后,线程数为152条;线程数减少了大约40条
- 优化之前,内存使用了470.93M;优化之后,内存使用了450.24M;内存减少了大约20M
- 优化之前,系统CPU使用率为34.83%;优化之后,系统CPU使用率为31.51%;系统CPU使用率降低了3%

- APP使用的流畅性:优化之前,每秒刷新23.36帧;优化之后,每秒刷新36.3帧;帧率平均每秒增加了13帧。

综上所述:通过插桩代理线程池进行收敛,能有效减少线程数(减少了40条),从而减少内存的使用(减少了20M)、降低CPU使用率(降低了3%)、使得APP使用的流畅性更高(每秒平均多刷新13帧),符合优化预期。
2. 踩坑
- 网络任务线程和本地任务线程要分开,避免网络不好的时候网络任务堵塞了本地任务
- 要相互依赖的线程池需要分开代理或者某些不代理,避免出现因为任务排队和互相依赖导致类似“死锁”现象
- 核心线程数等于1的不要代理,因为不仅优化效果有限,还可能把占用1个线程变成占用多个线程,从而导致部分任务会常驻,占用核心线程
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的核心笔记(还该底层逻辑):https://qr18.cn/FVlo89
性能优化核心笔记:https://qr18.cn/FVlo89
启动优化

内存优化

UI优化
网络优化

Bitmap优化与图片压缩优化:https://qr18.cn/FVlo89

多线程并发优化与数据传输效率优化
体积包优化
《Android 性能监控框架》:https://qr18.cn/FVlo89

《Android Framework学习手册》:https://qr18.cn/AQpN4J
- 开机Init 进程
- 开机启动 Zygote 进程
- 开机启动 SystemServer 进程
- Binder 驱动
- AMS 的启动过程
- PMS 的启动过程
- Launcher 的启动过程
- Android 四大组件
- Android 系统服务 - Input 事件的分发过程
- Android 底层渲染 - 屏幕刷新机制源码分析
- Android 源码分析实战
