算法入门知识
算法学习
CPP-STL
-
vector:就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。-
erase():O(n)复杂度 -
vector.size()是O(1)扩展:
string.length()是O(n)复杂度 -
insert(p,x):在向量p位置处插入元素x,p为指向该位置的迭代器,复杂度是O(n) -
注意:vector和迭代器使用不当会引发内存问题,详解见该资料 。
-
-
queue:- 无法通过迭代器遍历
queue,只能不断pop再push
- 无法通过迭代器遍历
-
string:-
length()为O(n)复杂度 -
append接的是字符串,不是字符char。 -
erase(pos,size_n),从pos位置开始删除指定数量的元素。erase(pos)删除pos后的所有元素。要注意的是删除后字符串长度改变,并且下标提前。 -
find查找字串,成功返回起始下标,否则返回string::npos。 -
push_back(char a) -
include中有:to_string() -
substr(int off,int len)若pos的值超过了string的大小,则抛出异常,若pos + len超过了string大小,则只会拷贝到末尾,也可以substr(off),默认拷贝后面所有字符 -
一般来说用容器存储字符串都是用
string类型,而不是char*,因为string默认好了ascii码的排序方法,如果用char\*的话要自己重新定义比较函数。
-
-
lower_bound()-
template <class ForwardIterator, class T> ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last, const T& val);//原型1 template <class ForwardIterator, class T, class Compare> ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last, const T& val, Compare comp);//原型2,多了一个Compare,就是一个比较器,可以传仿函数对象,也可以传函数指针 -
用于二分查找。
lower_bound()在first和last中的前闭后开区间,进行二分查找。返回从first开始的第一个大于或等于val的元素的地址。如果所有元素都小于val,则返回last的位置。 -
first,last: 迭代器在排序序列的起始位置和终止位置,使用的范围是
[first,last).包括first到last位置中的所有元素。其中first是数组首个元素,last是数组尾元素的下一位
注意,不是所有容器都可以通过该方法返回的地址减去
first得到排序后目标值的序号。一般只有vector,像set容器,我们需要自己写一个树状数组来实现该功能。 -
-
next_permutation(a,a+n)-
产生全排列,当序列存在下一个全排列时返回
true,否则返回false, 要求原序列升序 -
#includeusing namespace std; int a[3] = {1, 2, 3}; int main() { do { cout << a[0] << " " << a[1] << " " << a[2] << endl; } while (next_permutation(a, a + 3)); return 0; } //也支持cmp函数来自定义比较规则 -

-
需要强调的是,
next_permutation()在使用前需要对欲排列数组按升序排序,否则只能找出该序列之后的全排列数。比如,如果数组num初始化为2,3,1,那么输出就变为了:
-
-
priority_queue-
默认大顶堆:
priority_queue。反之,a priority_queue,这样就是小顶堆,不能默认声明。大顶堆先取出最大的元素,用于顺序排序。> c -
对于非内置类型,我们需要自己定义排序方法,通常的方法有:
struct Point { int x, y; friend bool operator<(Point a, Point b) { return a.x < b.x; } }; priority_queue<Point> a; //大顶堆 struct Point { int x, y; friend bool operator<(Point a, Point b) { return a.x > b.x; // 反向定义小于号 } }; priority_queue<Point> a; //小顶堆方法一 struct Point { int x, y; friend bool operator>(Point a, Point b) { return a.x > b.x; } }; priority_queue<Point, vector<Point>, greater<Point> > a; //小根堆方法二
-
-
map- 若
map已经存在某个关键字时,insert操作是不能再插入数据的,但是用数组方式就不同了,它可以覆盖以前该关键字对应的值。所以推荐使用数字下标方式。 find返回迭代器指向当前查找元素的位置否则返回map::end()的位置。- 若某一键值已经存在,Insert不会替代而是失效。
- map使用上有一个问题是,你如果你想查找一个值存不存在需要用.find和.end(或者.count, 新标准下可以用.exists),不能通过[]来判断,且实际上,每次你调用[a],如果你的map里没有键为a的 键对,map里就会出现键为a的键对。这是map的实现原理决定的
- **扩展:**map和set的底层机制就是红黑树,一种自平衡二叉搜索树。
- 若
-
unordered_set与unorderd_map- 功能与set和map一样,但底层实现为哈希表,其建立比较消耗时间,而查询、插入、删除的速度都在常 数级别,可以看成
O(1),但如果出现hash冲突,性能会下降很多,最坏情况下会退化成O(n)unordered_set与unordered_map是无序的,而set和map是有序的 - 一般情况下,
unordered_set和unordered_map性能都很好,但有些题目会故意卡这两个容器,其数据 会造成大量的哈希冲突进而造成TLE! 为了减少不必要的罚时,在比赛中如果O(logn)级别的复杂度够用,就不要使用unordered_map,请只在O(logn)解决不了问题时,再考虑使用。
- 功能与set和map一样,但底层实现为哈希表,其建立比较消耗时间,而查询、插入、删除的速度都在常 数级别,可以看成
-
multimap- 和map容器相比,multimap未提供at()成员方法,也没有重载[ ] 运算符。
- 这意味着,map容器中通过指定键获取指定键值对的方式,将不再适用于
multimap容器。
其实这也很好理解,因为multimap容器中指定的键可能对应多个键值对,而不再是一个。
另外,由于multimap容器可存储多个具有相同键的键值对,因此lower_bound()、upper_bound()、equal_range()以及count()方法经常会用到。
- 这意味着,map容器中通过指定键获取指定键值对的方式,将不再适用于
- 和map容器相比,multimap未提供at()成员方法,也没有重载[ ] 运算符。
-
findInputIterator find (InputIterator first, InputIterator last, const T& val);- 其中,first 和 last 为输入迭代器,[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素。另外,该函数会返回一个输入迭代器,当 find() 函数查找成功时,其指向的是在 [first, last) 区域内查找到的第一个目标元素;如果查找失败,则该迭代器的指向和 last 相同。
-
cin和getline- 从流中提取数据时**
std::cin** 函数从终端输入是跳过前导空白符(空格 tab 回车等 不会出现在终端的符号),即cin从第一个非空白符开始读,直到下一个是空白符或文件结束为止(意思是不吸收该空白符,此时空白符在仍然在缓冲区中,如果下一刻读取一个CHAR字符,需要先处理缓存区中的空白符,一般是用getchar()处理)。 - getline可以读取空格
cin.getline(char *p,int size),p是指针getline(cin,string s)是处理字符串(string类),在#include空间,注意不是string.h。我通常使用这个函数实现读取含空白符的字符串。- 也可以利用该函数读取字符串实现
JAVA中的string.split()的效果,具体我记录在本文第二节。
- 也可以利用该函数读取字符串实现
- 从流中提取数据时**
-
atoi- 头文件
stdlib.h,例子:int num = atoi(str.c_str())。
- 头文件
-
memset函数原型:void *memset(void *s, int c, size_t n);-
通过使用
memset可以快速地对高维数组等进行初始化,但是需要注意其无法任意赋值,因为它是按照字节对内存进行初始化。所以不能用它将int数组出初始化为0和-1之外的其他值(除非该值高字节和低字节相同)。 -
c的实际范围应该在0~255,因为
memset函数只能取c的后八位给所输入范围的每个字节。也就是说无论c多大只有后八位二进制是有效的。当然,不同的机器上int的大小可能不同,所以n最好用sizeof()函数。-
例子:对于
int a[4],memset(a, -1, sizeof(a)) 与 memset(a, 511, sizeof(a))所赋值的结果一样都为-1:因为
-1的二进制码为(11111111 11111111 11111111 11111111)(补码形式。关于负数的补码)511 的二进制码为(00000000 00000000 00000001 11111111);
后八位均为(11111111),所以数组中的每个字节都被赋值为(11111111)
-
-
注意所要赋值的数组的元素类型,因为是对字节赋值,所以对于
char和int数组是不同的。 -
具体用法实例:
-
初始化数组
char str[100]; memset(str,0,100); -
清空结构体类型的变量
typedef struct Stu{ char name[20]; int cno; }Stu; Stu stu1; memset(&stu1, 0 ,sizeof(Stu)); Stu stu2[10]; //数组 memset(stu2, 0, sizeof(Stu)*10); -
为整型数组赋值
memset(a,0,sizeof(a))//赋0 memset(a,-1,sizeof(a))//赋-1 memset(a,0x3f,sizeof(a))//赋int32最大值,0x3f3f3f3f的十进制是1061109567,是10^9级别的,而一般场合下的数据都是小于10^9的,所以它可以作为无穷大使用而不致出现数据大于无穷大的情形。 memset(a,0x8f,sizeof(a))//赋int32最小值0x3f3f3f3f是一个很有用的数值,它是满足以下两个条件的最大整数。
1、整数的两倍不超过 0x7f7f7f7f,即int能表示的最大正整数。
2、整数的每8位(每个字节)都是相同的。
我们在程序设计中经常需要使用 memset(a, val, sizeof a) 初始化一个数组a,该语句把数值 val(0x00~0xFF)填充到数组a 的每个字节上,所以用memset只能赋值出“每8位都相同”的 int。
当需要把一个数组中的数值初始化成正无穷时,为了避免加法算术上溢出或者繁琐的判断,我们经常用 memset(a, 0x3f, sizeof(a)) 给数组赋 0x3f3f3f3f的值来代替。不用0x7f7f7f是为了防止松弛操作。
-
-
与
fill(array.begin(),array.end(),val)的区别:虽然复杂度都是O(n),但是memset更快,但是fill可以赋出特殊值。
-
公用技巧/经验
-
DFS经验
- 行是数组第一维,列是第二维,在定义dx、dy时特别要注意。
- visit数组记得给最初进入的dfs点标志。
- 只有遍历完全后才返回false
-
分离数字技巧:一个数,想从低位得到位数,用取余10。从高位得到位数,用除10。
例如,12345%10 = 5,12345%100 = 45(低位)。12345/10 = 1234,12345/100 = 123(高位)。
-
关于整除的一个技巧: 假如求一个能被k整除最小值min,可以将min = submin / k * k,此时submin也许有更好的途径去求。要注意的是,一般都是有整数要求,此时是 :
m i n = ⌈ s u b m i n / k ⌉ ∗ k min = \lceil submin/k \rceil * k min=⌈submin/k⌉∗k -
关于打表: 有些题会根据题意推出递归式,我们为提前求出所有索引对应的值以及索引边界,或者找出对应规律,叫打表。
-
CPP中代替JAVA.split()函数的技巧
-
利用getchar()吸收无效字符。
-
利用字符串getline和stringstream和cin共同达到目的。
-
例如:
while (getline(cin, tempLine)) { int len = tempLine.length(); for (int i = 0; i < len; i++) { if (tempLine[i] == ':') tempLine[i] = ' '; } stringstream s(tempLine); string temp2 = ""; s >> temp2; //此时就可以得到被:分割的字符,可以先用vector用循环先存储起来 }
-
-
套用现成函数:
void SplitString(const std::string& s, std::vector
-
-
经验*:scanf和cin同时使用会导致部分编译器下的结果出错。最好同时只用一种。
-
经验:多项式极有可能会涉及大数,此时使用Java很好。
-
经验:全局数组能开到4e8 * int,栈能开到518028 * int。c++递归深度最深 20000多次。当超出递归深度时,要么转为非递归循环模式,要么是推出数学表达式使用循环推出。
三 穷竭搜索
- 深度优先搜索更节省空间,二者时间复杂度都是O(M * N)。
四 位运算
-
“<<”:左移运算符,将运算符左边的操作数全部左移指定的位数,移出左边界被屏蔽,右边界用0填充空位,本质上是操作数乘上2n。例如:1 << n = 2 n ,n << 1 = 2 * n。
-
“>>” 大致功能类比左移,需要注意的是填补空位时若原先最高位是1,则填充1,若是0,则填充0。其本质是除上2n ,在c++中是向下取整。
-
按位与:&,例如a&b即a和b的二进制形式中每一位进行一一位与比较。
按与或:|
异或:^
非:~(取反)
常见应用:"i&1"判断i是否位奇数
五 动态规划(Dynamic programming)
- 记忆化搜索与动态规划区别:记忆化搜索只是剪枝的递归,其递归深度依然很深,需要很大的调用栈,内存占用大,而动态规划只是调用一次,递归深度为1。
六 模运算
-
基本运算规则:
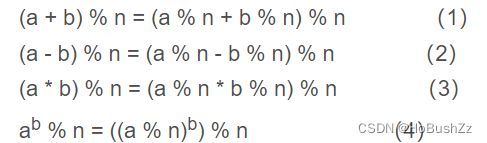
-
降幂运算推导:

-
当
a ⋅ c ≡ b ⋅ c ( m o d m ) a \cdot c \equiv b \cdot c(\mod m) a⋅c≡b⋅c(modm)
求a、b之间的关系:其中涉及一个知识点:(a-b)被m整除,代表a % m == b % m。
a ≡ b ( m o d m / g c d ( m , c ) ) a \equiv b(\mod m/gcd(m,c)) a≡b(modm/gcd(m,c))
-
快速幂:反复平凡法
合数是指在大于1的整数中除了能被1和本身整除外,还能被其他数(0除外)整除的数,素数(质数)与之相反。

代码:
typedef long long ll;
ll mod_pow(ll x, ll n,ll mod)
{
ll res = 1;
while(n > 0)
{
if(n&1) res = res * x % mod;
x = x * x % mod; //将x平方
n >>= 1; //二进制右移
}
return res;
}
七 最大公约数|最小公倍数应用
- 最大公约数用GCD,最小公倍数则是二者之积除以最大公约数。
八数学基础
- 单位圆内接正n边形的面积公式
n / 2 ∗ s i n ( 2 ∗ p i / n ) R 2 n/2 * sin(2*pi/n)R^2 n/2∗sin(2∗pi/n)R2
-
柯西不等式:
-
c++中自己定义pi : define pi 3.1415926
九 CPP应用
-
精度的控制,参考文章:小数点精度的控制——C++ - 知乎 (zhihu.com)
(28条消息) c++ 保留有效数字和小数位_吉大秦少游的博客-CSDN博客_c++ 有效数字
-
仅对数字长度来控制:仅使用setprecision(int num),要注意头文件是iomanip,当整数部分无法显示完全会变成指数形式,同时会有舍入情况。
-
保留n位小数:结合setiosflags(ios::fixed)和setprecision(int num)
double a = 3.141564; cout << setiosflags(ios::fixed) << setprecision(3) << a; // a = 3.141
-
十 JAVA语言应用
- 输出时忽略若浮点数等于整数忽略小数点,可以直接以浮点数和其强转为整数的数值进行比较,相同则直接取整数,即去掉小数点;否则,即不同时,原样输出
- MAP遍历时可以修改值,但不能随意删除或添加
- set<> = m.keyset()是浅复制,若想深拷贝可以,set<> = new set<>(m)。
- cpp的auto,Java的var