【论文笔记】RAFT: Recurrent All-Pairs Field Transforms for Optical Flow(ECCV 2020)
关键词:光流估计、端到端训练、迭代优化、GRU
一种新的适用于光流的端到端可训练的模型。独特之处在于它使用大量轻量级、循环更新算子以单一分辨率运行。在各种数据集上实现了最好的精度,强大的跨数据集泛化能力,并且在推断时间、参数总数和训练迭代方面非常有效。
创新点:RAFT以高分辨率保持和更新单个固定的光流场;RAFT的更新算子是循环的、轻量级的,并且共享权重;更新算子由一个卷积GRU组成,在4D多尺度相关体上进行查找。引入了motion feature,而motion feature的计算通过金字塔4D关系矩阵均匀采样得来;引入了GRU概念进行迭代优化。
1. Abstract
背景
光流预测是估计视频帧之间的逐像素运动的任务,指在一帧视频图像中,代表同一目标的像素点到下一帧的移动量,用向量表示。根据光流的亮度恒定假设,同一物体在连续的帧间运动时,像素值不变(一只小鸟不会在运动时突然变成鸭或者飞机)。所以这个运动的过程,就像是光的“流动”过程,简称光流,预测光流的过程,就被称之为光流预测。目前被一些难题所制约,包括快速移动的物体、遮挡、运动模糊和无纹理表面等。经典光流预测算法都存在如上缺点,无论怎么优化,这些缺点都会因为框架的设计而一直存在。
先前方法
根据是否选取图像稀疏点(特征明显,梯度较大),可以将光流预测分为稀疏光流和稠密光流,如下图左和右。

稀疏光流:选取图像稀疏点进行光流估计。稠密光流:使用不同的颜色和亮度表示光流的大小和方向。针对这两种方法,目前有传统预测和基于深度学习的两种经典算法。
1、传统方法:稀疏光流估计算法
求解光流预测算法前,首先要知道孔径问题。比如发廊的旋转灯,灯上的条纹看起来总在往上走(其实没有)。

其中一种传统的Lucas-Kanade算法,求解稀疏光流,选取了一些可逆的像素点估计光流,这些像素点是亮度变化明显(特征明显)的角点,借助可逆相关性质,预测光流方向。
2、深度学习方法:FlowNet
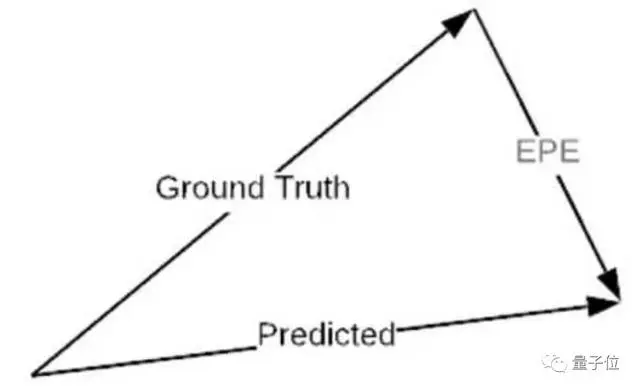
CNN用于光流预测算法的经典例子。在损失设计上,对于每个像素,损失定义为预测的光流值和真实值之间的欧氏距离,称这种误差为EPE,全称End-Point-Error。
光流预测的经典数据集FlyingChairs(飞椅)。为了模拟目标的多种运动方式,飞椅数据集将虚拟的椅子叠加到背景图像中,并将背景图和椅子用不同的仿射变换,得到对应的另一张图。
基于深度学习的经典光流预测算法存在着几个缺点,无论怎么优化,这些缺点都会因为框架自身而一直存在。但在RAFT中,过往的3大缺点都被一一解决了:
1. 先前的框架普遍采用从粗到细的设计,也就是先用低分辨率估算流量,再用高分辨率采样和调整。
相比之下,RAFT以高分辨率维护和更新单个固定的光流场。这种做法带来了如下几个突破:低分辨率导致的预测错误率降低,错过小而快速移动目标的概率降低,以及超过1M参数的训练通常需要的迭代次数降低。
2. 先前的框架包括某种形式上的迭代细化,但不限制迭代之间的权重,这就导致了迭代次数的限制。例如,IRR使用的FlowNetS或PWC-Net作为循环单元,前者受网络大小(参数量38M)限制,只能应用5次迭代,后者受金字塔等级数限制。

相比之下,RAFT的更新运算是周期性、轻量级的:这个框架的更新运算器只有2.7M个参数,可以迭代100多次。
3. 先前框架中的微调模块,通常只采用普通卷积或相关联层。
相比之下,更新运算符是新设计,由卷积GRU组成,该卷积GRU在4D多尺度相关联向量上的表现更加优异。
优势:
- state-of-the-art: 在KITTI上RAFT达到了目前最高的准确率。
- 有很强的泛化性,当只在生成的数据集上训练时RAFT也能有很好的效果。
- 高效,在1080Ti上能够以10帧每秒运行1088×436像素的图像。
2. 相关工作
3. 方法
目标:跳出原先的设计思路,设计一个性能更好、训练更容易并能很好地推广到新场景的新结构,同时实现如下要求:
1.网络输入为图片,输出为图片(端到端网络);
2.光流估计是一个密集的任务,如果我们不对整个图像局部的光流进行约束,网络可能会沿着其他方向去拟合损失函数。尽管损失会降低,但最终的结果可能并不理想。因此,需要同时考虑局部和全局的特征来约束光流估计;
3.虽然光流的信息来自于前后帧间的运动信息,但光流估计也需要一定的纹理信息和上下文信息用于匹配像素点,光流图与原图轮廓也基本一致;
4.网络模块参数量太大,堆叠多个模块会导致网络计算成本太高,因此限制了层数不能太深;
5.延续经典的迭代优化思路。
流程:
- 1.特征提取:通过特征编码器从两个输入图像中提取每个像素的特征,通过上下文编码器从I1中提取特征;
- 2.计算视觉相似度:通过计算所有特征向量对的内积,构造一个4D W×H×W×H相关体,在4D体最后2维上进行多尺度池化,以构建一组多尺度体;
- 3.相关查找:定义查找算子LC,它通过从相关金字塔中索引生成特征图;
- 4.迭代更新:基于GRU的循环更新算子,从相关体中检索值并迭代更新初始化为零的光流场;
- 5.上采样:一个新颖的通过卷积层学习的上采样方式;
- 6.监督:计算伴随权重呈指数增长的预测光流和真实光流之间的l1距离。
RAFT光流计算模型
包含三个部分:
- Feature Encoder:特征编码器,从像素中提取特征。以及仅从I1中提取特征的上下文编码器。
- Correlation Layer:相关层。通过计算所有特征向量对的内积,构造一个4D W×H×W×H相关体。在4D体最后2维上进行多尺度池化,以构建一组多尺度体。建模图像上任意两个点之间的相似度。
- Update Operator:基于门控循环网络GRU的更新算子,用来迭代更新最后生成的光流图。

RAFT结构是由传统的基于优化的方法推动的。特征编码器提取每个像素的特征。相关层计算像素之间的视觉相似性。更新算子模拟迭代优化算法的步骤。但与传统方法不同,特征和运动先验不是人工制作的,而是分别由特征编码器和更新算子学习的。
1.特征提取模块与context提取模块
作用:使用几层卷积层将原图缩小为原来的八分之一,减小后续网络的计算量,同时相当于进行编码操作。
feature encoder:提取输入第一帧、第二帧这两张图像中的特征。用于后续的光流估计。
Context encoder:只提取第一帧图像的上下文信息特征。分辨率都变为输入图像的1/8。对2张图片采用同一个网络进行特征提取。作用是保证估计出的光流图保持与原图相同的上下文信息以及位置对应。
encoder网络结构:
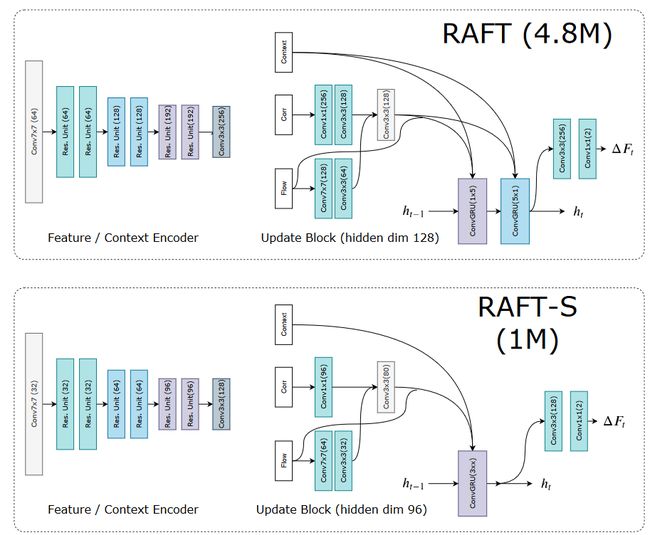
两个encoder具有相同的结构,唯一的区别是特征编码器使用实例归一化,而上下文编码器使用批归一化。
在RAFT-S中,用瓶颈残差单元替换残差单元。更新块使用上下文特征、相关特征和光流特征来更新潜在隐藏状态。更新后的隐藏状态用于预测光流更新。完整模型使用两个卷积GRU更新块,分别带有1x5过滤器和5x1过滤器,而小模型RAFT-S只使用一个3x3的GRU。
2 Correlation Layer模块
通过在所有输入图像对之间构造一个correlation volume(下称为相关性张量)来计算视觉相似性。
作用:将上述的两个编码器输出的结果进行融合。把Feature Encoder对两张图片编码的结果进行相似度的计算。
对两张图两两像素之间进行点积相似度计算,得到一个4D的,大小为H*W*H*W的相似度块C,如下图所示:

视觉相似性计算的是所有特征图对的内积,从而得到一个名为“相关体积”的四维张量,其中包含了关于大小像素位移的关键信息。此处计算的是两个特征图的全局相关性,没有任何固定大小的窗口,可以用下式表示:

其中C为相似度块, gθ是Feature Encoder。I1,I2分别为第一帧图像特征与第二帧图像特征,i,j:第一帧图像特征的高、宽索引。k,l:第二帧图像特征的高、宽索引。h为图像特征的通道维度索引。
将四维张量的后两维使用大小分别为 1 , 2 , 4 , 8的核进行池化,形成相关金字塔。利用相关金字塔建立多尺度图像相似性特征,使突变运动更为明显,也同时提供了关于大位移和小位移的信息。
(由于光流找到前两帧之间相似度最大的像素,并进行对应,该相似度并不仅仅是像素值的相似,也是描述子的相似,所以可以看做两张图提取出的特征相似,即Feature Encoder输出的编码结果中寻找相似的位置进行对应。所以作者使用了最简单的点积相似度衡量。)
相似度金字塔:用于关注到不同尺度的相似度。作者使用了四层金字塔,即通过Pool的方式将上述得到的相似度块分别缩小。体Ck的维度为H×W×H/2k×W/2k。这组体提供了关于大位移和小位移的信息;但是,通过保持前2个维度(I1的维度),可以保持高分辨率信息,同时保证微小运动和剧烈运动同时被观测到。
相关查询(Correlation Lookup):
定义一个查询算子LC ,通过从相关金字塔中索引来生成特征图。
对于已经估计到的光流 (f1,f2),可以将图像I1中的每个像素点(u,v)映射到I2中的对应点 x' = (u+f1(u),v+f2(v)),然后定义 x' 周围的局部网格:
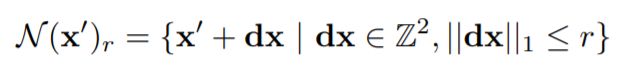
即,x’ 周围,半径小于r的坐标集合。使用局部邻域 N(x′)r 从相关张量中索引,得到特征。由于 N(x′)r 是一组实数的网格,所以这里使用双线性采样。
在金字塔的所有层级上执行查询。如对于在 k 层的volume Ck ,使用网络 N(x′)r 来索引。每层使用索引的网格半径 r 不变,因此层级越低,感受野越大。比如对于最低的层级 k=4 ,若半径为 4,则在原始图像上对应256个像素。 然后,每个级别的值被拼接成一个单一的特征图。
高效计算高分辨率图像
所有图像对的相关性的计算复杂度为 O(N^2) ,其中N是像素的数量。且相关张量只需要计算一次,并且在迭代的过程中保持不变。但是也存在一种计算复杂度仅为 O(NM) 的方法,该方法利用内积和平均池化的线性性质来加速。考虑到第m层的cost volume ![]() ,和特征图 g(1)=gθ(I1),g(2)=gθ(I2) :
,和特征图 g(1)=gθ(I1),g(2)=gθ(I2) :
这是在 2m×2m 网格内的相关响应的均值。这意味着 ![]() 值可以这样被计算: 特征向量 gθ(I1)和 通过 2m×2m 卷积核池化后的特征 gθ(I2) 的内积。
值可以这样被计算: 特征向量 gθ(I1)和 通过 2m×2m 卷积核池化后的特征 gθ(I2) 的内积。
在实现中,不预先计算相关,而是预先计算池化后的图像特征图。在每次迭代中,根据需要计算每个相关值——只在查找时计算。因此仅需要O(NM)的复杂度。
根据经验,预计算所有图像对很容易实现,而不是一个瓶颈,因为在gpu上高度优化的矩阵例程,即使对于1088x1920的视频,它也只需要总推理时间的17%。请注意,如果预计算计算瓶颈的话,则采用上面说的这种 O(NM)的方法。
3. 迭代更新
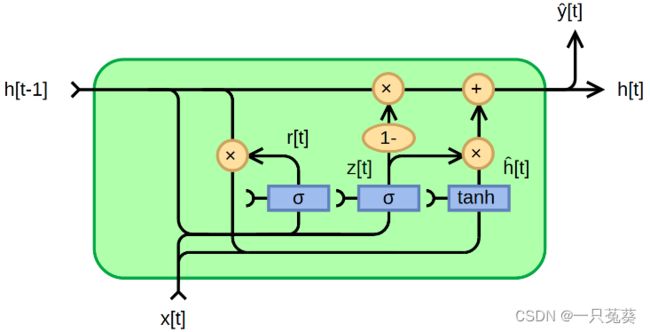
使用一个门控循环单元(GRU)序列,来结合之前获取的所有数据。
更新算子从初始起点f0=0开始,估计了一系列光流估计{ f1,…,fN }。每次迭代,它都会产生一个更新方向Δf,并应用于当前估计:fk+1=Δf+fk+1。
更新算子将光流、相关和潜在隐藏状态作为输入,并输出更新Δf和更新后的隐藏状态。我们设计更新算子结构的目的是模仿优化算法的步骤。因此,我们使用绑定权重并使用有界激活来促进收敛到一个固定点。我们训练更新算子来执行更新,使得序列收敛到一个固定点fk→f*。
初始化 :默认情况下,将所有的光流场初始化为0。当应用于视频任务时,可以使用 warm-start 初始化,前一对帧的光流被向前投影到下一对帧,然后使用最近邻插值填充遮挡间隙。
输入:给定当前光流估计fk,使用该光流从相关金字塔中检索相关特征。接着相关特征被2个卷积层处理。 此外,对光流应用2个卷积层来生成光流特征。最后,从context网络直接注入输入。最后的输入特征图是将相关特征、光流、context特征连接在一起。
更新:更新算子的核心组成部分是一个基于GRU单元的门控激活单元,其中将全连接层替换为卷积:

其中 xt 是前面定义的光流、相关特征、context特征的拼接。论文还实验了一个可分离的ConvGRU单元,其中用两个GRU替换3×3卷积: 一个用1×5卷积,一个用5×1卷积,以便在不显著增加模型大小的情况下增加感受野。
光流预测:将GRU输出的隐藏状态经过两个卷积层来预测光流的更新 Δ f \Delta \bold{f} Δf 。输出的光流的分辨率是输入图像的1/8。 在训练和评估过程中,对预测的光流场进行上采样,以匹配ground-truth的分辨率。
上采样:该模块中利用卷积操作学习上采样权值,使当前1/8分辨率下的光流上采样到与输入图像同尺寸,具体形式如下图所示,其中w1-w9为利用卷积操作学习到的权重。也就是说,上采样之后的光流结果中每一像素点的值都与其周围的9个像素点有关。最后,输出每一次迭代过程生成的全分辨率光流结果,用于损失函数计算,更新模型中的参数。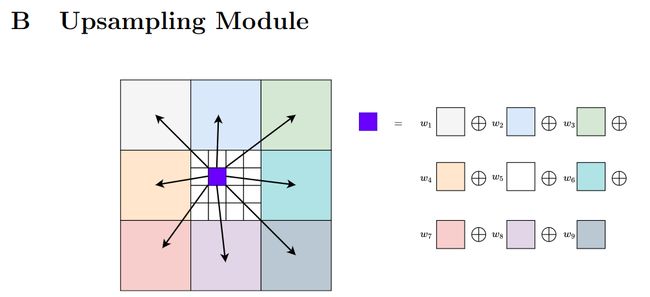
结果:上采样模块提高了运动边界附近的精度,并且还让RAFT恢复小型快速移动物体的光流,例如图中所示的鸟类。

监督:在整个预测序列{ f1,…,fN }上,使用预测的光流和ground-truth光流之间的 L1 距离监督学习网络,使用指数增加的权重。给定gt光流,损失定义为: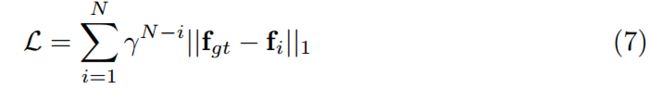
RAFT模型中总共进行12次优化迭代,也就是说会产生12个全分辨率下的光流结果。迭代次数越多,光流计算精度越精确。RAFT模型采用的是监督算法,具体步骤可以表示为:通过求取12次 光流迭代过程中的 光流计算结果 与 光流真实值的L1范数,并且迭代的次数越多,对应L1范数结果的权值也就越大(说明该结果对整个损失函数的影响越大),其中,N=12。
总结一下,RAFT的框架流程分为三步:对每个像素提取特征,计算所有像素对的相关性,高效迭代更新光流场。
4. 实验
在Sintel和KITTI上评估RAFT。
在FlyingChairs和FlyingThing上预训练,然后在数据集上进行特定微调。我们的方法在Sintel(clean和final pass)和KITTI上都取得了最好的性能。此外,在DAVIS数据集的1080p视频上测试以证明可以扩展到更高分辨率的视频中。
实现细节:RAFT在PyTorch中实现。所有模块都使用随机权重从头开始初始化。使用AdamW优化器并将梯度限制在[−1; 1]。对于每次更新Δf + fk,只通过Δf分支反向传播梯度,通过fk分支将梯度归零。
训练计划:使用两个2080Ti GPU训练RAFT。在FlyingThings上进行100k次迭代预训练,批量大小为12,然后在FlyingThings3D上迭代训练100k次,批量大小为6。对RAFT在Sintel上再微调100k,数据集结合了来自Sintel、KITTI-2015和 HD1K的数据,这类似于MaskFlowNet和PWC-Net+的做法。最后,使用在Sintel上微调后模型的权重,在KITTI-2015上进行了额外的50k次迭代微调。
Sintel
使用FlyingChairs→FlyingThings计划训练我们的模型,然后在Sintel数据集进行评估,使用拆分的训练数据作为验证集。结果如表1和图3所示,我们根据用于训练的数据拆分结果。C+T表示模型在FlyingChairs(C)和FlyingThings(T)上进行训练,而+ft表示模型在Sintel数据上进行了微调。与PWC-Net+和MaskFlowNet一样,在微调时我们使用包含来自KITTI和HD1K的数据。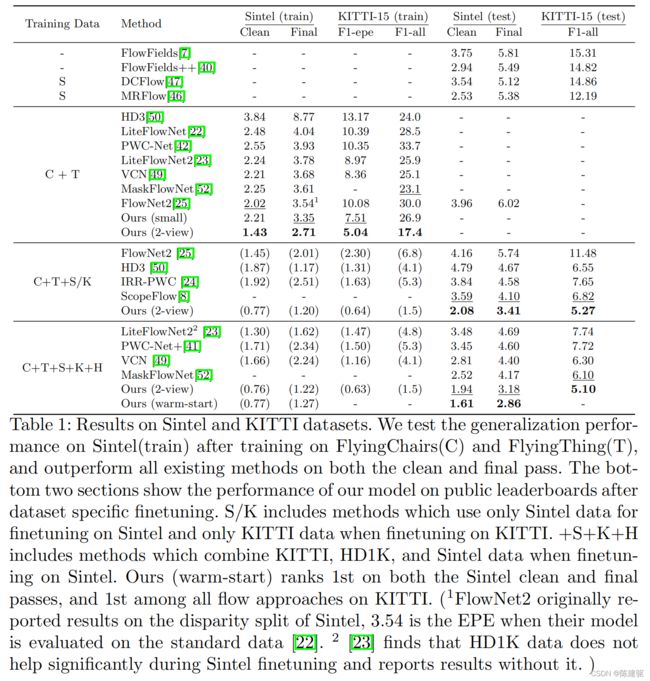
表1:Sintel和KITTI数据集的结果。在FlyingChairs(C)和FlyingThing(T)进行训练后,在Sintel(train)上测试了泛化性能,在clean和final pass上都优于现有所有的方法。底部两部分显示了我们的模型在数据集特定微调后在公共排行榜上的性能。S/K包括在Sintel上进行微调时仅使用Sintel数据和在KITTI上进行微调时仅使用KITTI数据的方法。+S+K+H包括在Sintel进行微调时结合了KITTI、HD1K和Sintel的数据的方法。我们的(warm-start)在Sintel的clean和final pass中均排名第一,在KITTI的所有光流方法中排名第一。

图3:在Sintel测试集上的光流预测。
使用C+T进行训练时,我们的方法优于所有现有方法。在Sintel(train) clean pass上实现了1.43的平均EPE(端点误差),比FlowNet2的误差低29%。
泛化性更好的原因之一是我们的网络结构。通过将光流限制为一系列相同更新步骤的产物,让网络学习一个更新算子,该算子模仿一阶下降算法的更新。这限制了搜索空间,降低了过拟合的风险,并实现了更快的训练和更好的泛化性。
KITTI
在Sintel(test)集上进行评估时,我们在结合了KITTI、HD1K数据和训练集中clean pass和final pass组合上进行微调。我们的方法在Sintel clean和final pass中均排名第一,并且在clean pass上比之前的所有工作高0.9像素(36%),在最终pass中高出1.2像素(30%)。我们评估我们模型的两个版本,Ours(two-frame)使用零初始化,而Ours(warp-start)通过向前投影的前一帧光流估计来初始化光流。由于我们的方法以单一分辨率运行,我们可以初始化光流估计以利用过去帧的运动平滑,这是使用粗糙到精细的模型不容易做到的。

还在KITTI上评估了RAFT,并在表1和图4中提供了结果。首先通过在Chairs(C)和FlyingThings(T) 训练后的模型在KITTI-15(train)划分集上验证来评估跨数据集的泛化性。我们的方法明显优于先前的工作,将EPE(端点误差)从8.36降低到5.04,这表明我们网络的基底结构有助于泛化性。在KITTI排行榜上在所有光流方法中我们的方法排名第一。
4.2. KITTI
在KITTI上评估了RAFT,并在表1和图4中提供了结果。我们首先通过在Chairs(C)和FlyingThings(T) 训练后的模型在KITTI-15(train)划分集上验证来评估跨数据集的泛化性。我们的方法明显优于先前的工作,将EPE(端点误差)从8.36降低到5.04,这表明我们网络的基底结构有助于泛化性。在KITTI排行榜上在所有光流方法中我们的方法排名第一。
消融实验
进行了一组消融实验来说明每个组成部分的相对重要性。所有消融版本都在FlyingChairs(C) + FlyingThings(T)上进行训练。
更新算子的结构:使用基于GRU单元的门控激活单元。我们使用一组具有ReLU激活的3个卷积层替换卷积GRU。通过使用GRU块我们获得了更好的性能,这可能是因为门控激活使一系列的光流估计更容易收敛。
权重绑定:默认情况下,在更新算子的所有实例中绑定权重。测试了另一个版本,其中每个更新算子分别学习权重。当权重绑定时精度会更好,并且参数总数明显降低。
上下文:通过训练没有上下文网络的模型来测试上下文的重要性。在没有上下文的情况下,我们仍然取得了不错的结果,优于在Sintel和KITTI上现有的所有工作。但是上下文很有帮助。将图像特征直接添加进更新算子可能在运动边界内能更好地聚合空间信息。
特征尺度:默认情况下,以单一分辨率提取特征。我们还尝试通过在每个尺度上分别构建相关体来提取多个分辨率的特征。单分辨率特征简化了网络结构,即使在大位移下也可以进行细粒度的匹配。
查找半径:在查找操作中查找半径指定使用的网格的尺寸。当使用半径为0时,在单个点检索相关体。令人惊讶的是,当半径为0时,我们仍然可以粗略估计光流,这意味着网络正在学习使用0阶信息。然而,随着半径的增加,我们看到了更好的结果。
相关池化:我们以单一分辨率输出特征,然后执行池化以生成多尺度体。在此,我们测试了移除池化时的影响。有池化的结果会更好,因为同时获得了大位移和小位移。
相关范围:我们还尝试仅为每个像素周围的局部邻域构建相关体,而不是所有对相关。我们尝试了32像素、64像素和128像素的范围。总体而言,当使用所有对时,我们得到了最好的结果,尽管128px的范围足以在Sintel上表现很好,因为大多数位移都在这个范围内。也就是说,all-pairs仍然是更合适的,因为它排除了指定范围的需要。实现起来也更方便:它可以使用矩阵乘法计算,从而让我们的方法在PyTorch中可以完全实现。
改进特征:我们通过在所有像素对之间构建相关体来计算视觉相似性。在这个实验中,我们尝试用形变层替换相关体,形变层使用当前的光流估计将特征从I2形变到I1,然后估计残差位移。与之前在Sintel上的工作相比虽然形变仍然具有竞争力,但相关的表现要好得多,尤其是在KITTI上。
上采样:RAFT以1/8分辨率输出光流场。我们比较了双线性上采样与我们学习的上采样模块。上采样模块产生更好的结果,尤其是在运动边界附近。
推断更新:在推断期间应用任意数量的更新。在表2中,我们提供了选定更新次数的数值结果,并测试了200次的极端情况,以表明我们的方法没有发散。我们的方法快速收敛,在3次更新后超过了PWC-Net,在6次更新后超过了FlowNet2,随着更多的更新效果继续提高。

实验结果:
最好的精度:在KITTI上,RAFT实现了5.10% 的F1-all误差,比已公布的最佳结果(6.10%)减少了16%的误差。在Sintel(final pass)上,RAFT获得了2.855 像素的EPE误差,比已公布的最佳结果(4.098像素)减少了30%的误差。
强泛化性:仅在合成数据上训练时,在KITTI上RAFT取得了5.04像素的端点误差,与在相同数据上训练的之前的最佳深度网络(8.36像素)相比,误差减少了40%。
高效率:在1080Ti GPU上RAFT以每秒10帧的速度处理1088×436视频。它训练的迭代次数比其他结构少10倍。具有1/5参数的较小版本的RAFT以每秒20帧的速度运行,然而在Sintel上仍然优于以前所有的方法。
效果

在Sintel测试集上的效果展示,最左边是真值,最右边是RAFT预测的光流效果,中间的VCN和IRR-PWC是此前效果较好的几种光流预测框架。
较于中间两个框架的预测效果,RAFT的预测不仅边界更清晰,而且运动的大小和方向准确(看颜色)。
此外,在KITTI数据集上的预测效果也非常不错。图左的几辆小车被清楚地预测了出来,而图右中,驾驶方向不同的车辆也能用不同的颜色(红、蓝)区分标记。

不仅小视频,在1080p的高分辨率视频(DAVIS数据集)中,光流预测的效果也非常不错。

有意思的是,在训练参数(下图横轴)几乎没有明显增加的情况下,RAFT在一系列光流预测框架中,EPE误差(下图纵轴)做到了最小。
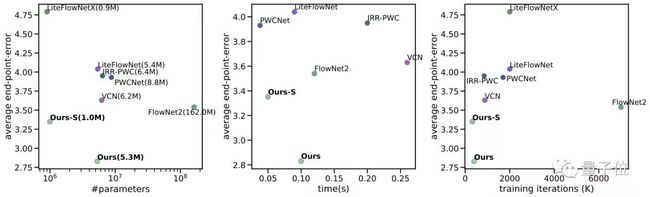
图 5:比较参数总数、推断时间和训练迭代与精度的图表。
由上图可见,团队同时推出了5.3M参数量和1.0M轻量级的两个框架,EPE误差效果均非常好。从效果来看,在KITTI数据集上,RAFT的F1-all误差是 5.10%,相比此前的最优结果(6.10%)减少了16%;在Sintel数据集上,RAFT只有2.855像素的端点误差(End-Point-Error),相比先前的最佳结果(4.098 像素)减少了30%。
5. 结论
提出了RAFT—一种新的适用于光流的端到端可训练的模型。RAFT的独特之处在于它使用大量轻量级、循环更新算子以单一分辨率运行。我们的方法在各种数据集上实现了最好的精度,强大的跨数据集泛化能力,并且在推断时间、参数总数和训练迭代方面非常有效。
6. 代码
主代码
class RAFT(nn.Module):
def __init__(self, args):
super(RAFT, self).__init__()
self.args = args
self.flow_init: torch.Tensor = torch.Tensor()
if args.small:
self.hidden_dim = hdim = 96
self.context_dim = cdim = 64
args.corr_levels = 4
args.corr_radius = 3
else:
self.hidden_dim = hdim = 128
self.context_dim = cdim = 128
args.corr_levels = 4
args.corr_radius = 4
if 'dropout' not in self.args:
self.args.dropout = 0
if 'alternate_corr' not in self.args:
self.args.alternate_corr = False
# feature network, context network, and update block
if args.small:
self.fnet = SmallEncoder(output_dim=128, norm_fn='instance', dropout=args.dropout)
self.cnet = SmallEncoder(output_dim=hdim+cdim, norm_fn='none', dropout=args.dropout)
self.update_block = SmallUpdateBlock(self.args, hidden_dim=hdim)
else:
self.fnet = BasicEncoder(output_dim=256, norm_fn='instance', dropout=args.dropout)
self.cnet = BasicEncoder(output_dim=hdim+cdim, norm_fn='batch', dropout=args.dropout)
self.update_block = BasicUpdateBlock(self.args, hidden_dim=hdim)
def freeze_bn(self):
for m in self.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
def initialize_flow(self, img:torch.Tensor):
""" Flow is represented as difference between two coordinate grids flow = coords1 - coords0"""
N, C, H, W = img.shape
coords0 = coords_grid(N, H//8, W//8, device=img.device)
coords1 = coords_grid(N, H//8, W//8, device=img.device)
# optical flow computed as difference: flow = coords1 - coords0
return coords0, coords1
def upsample_flow(self, flow:torch.Tensor, mask:torch.Tensor):
""" Upsample flow field [H/8, W/8, 2] -> [H, W, 2] using convex combination """
N, _, H, W = flow.shape
mask = mask.view(N, 1, 9, 8, 8, H, W)
mask = torch.softmax(mask, dim=2)
up_flow = F.unfold(8 * flow, [3,3], padding=1)
up_flow = up_flow.view(N, 2, 9, 1, 1, H, W)
up_flow = torch.sum(mask * up_flow, dim=2)
up_flow = up_flow.permute(0, 1, 4, 2, 5, 3)
return up_flow.reshape(N, 2, 8*H, 8*W)
def forward(self, image1:torch.Tensor, image2:torch.Tensor,iters:int=12, upsample:bool=True, test_mode:bool=False)\
->typing.List[torch.Tensor]:
""" Estimate optical flow between pair of frames """
image1 = 2 * (image1 / 255.0) - 1.0
image2 = 2 * (image2 / 255.0) - 1.0
image1 = image1.contiguous()
image2 = image2.contiguous()
hdim = self.hidden_dim
cdim = self.context_dim
# run the feature network
with autocast(enabled=True):
fmap1, fmap2 = self.fnet([image1, image2],True)
fmap1 = fmap1.float()
fmap2 = fmap2.float()
# if self.args.alternate_corr:
# corr_fn = AlternateCorrBlock(fmap1, fmap2, radius=self.args.corr_radius)
# else:
# corr_fn = CorrBlock(fmap1, fmap2, radius=self.args.corr_radius)
corr_fn = CorrBlock(fmap1, fmap2, radius=4)
# run the context network
with autocast(enabled=True):
cnet = self.cnet([image1],False)[0]
net, inp = torch.split(cnet, [hdim, cdim], dim=1)
net = torch.tanh(net)
inp = torch.relu(inp)
coords0, coords1 = self.initialize_flow(image1)
if self.flow_init == torch.Size([]):
coords1 = coords1 + self.flow_init
flow_predictions = []
for itr in range(iters):
coords1 = coords1.detach()
corr = corr_fn(coords1) # index correlation volume
flow = coords1 - coords0
with autocast(enabled=True):
#print("net.shape",net.shape)
#print("inp.shape",inp.shape)
#print("corr.shape",corr.shape)
#print("flow.shape",flow.shape)
net, up_mask, delta_flow = self.update_block(net, inp, corr, flow)
# F(t+1) = F(t) + \Delta(t)
coords1 = coords1 + delta_flow
# upsample predictions
if up_mask is None:
flow_up = upflow8(coords1 - coords0)
else:
flow_up = self.upsample_flow(coords1 - coords0, up_mask)
self.flow_init = coords1 - coords0
flow_predictions.append(flow_up)
#if test_mode:
# return coords1 - coords0, flow_up
return flow_predictions
特征提取网络
class BasicEncoder(nn.Module):
def __init__(self, output_dim: int = 128, norm_fn: str = 'batch', dropout: float = 0.0):
super(BasicEncoder, self).__init__()
self.norm_fn = norm_fn
if self.norm_fn == 'group':
self.norm1 = nn.GroupNorm(num_groups=8, num_channels=64)
elif self.norm_fn == 'batch':
self.norm1 = nn.BatchNorm2d(64)
elif self.norm_fn == 'instance':
self.norm1 = nn.InstanceNorm2d(64)
elif self.norm_fn == 'none':
self.norm1 = nn.Sequential()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.relu1 = nn.ReLU(inplace=True)
self.in_planes = 64
self.layer1 = self._make_layer(64, stride=1)
self.layer2 = self._make_layer(96, stride=2)
self.layer3 = self._make_layer(128, stride=2)
# output convolution
self.conv2 = nn.Conv2d(128, output_dim, kernel_size=1)
self.dropout = None
if dropout > 0:
self.dropout = nn.Dropout2d(p=dropout)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.InstanceNorm2d, nn.GroupNorm)):
if m.weight is not None:
nn.init.constant_(m.weight, 1)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def _make_layer(self, dim: int, stride=1):
layer1 = ResidualBlock(self.in_planes, dim, self.norm_fn, stride=stride)
layer2 = ResidualBlock(dim, dim, self.norm_fn, stride=1)
layers = (layer1, layer2)
self.in_planes = dim
return nn.Sequential(*layers)
def forward(self, x_list: typing.List[torch.Tensor], isFnet: bool) \
-> typing.List[torch.Tensor]:
# if input is list, combine batch dimension
x = x_list[0]
batch_dim = 0
if isFnet:
batch_dim = x_list[0].shape[0]
x = torch.cat(x_list, dim=0)
x = self.conv1(x)
x = self.norm1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.conv2(x)
if self.training and self.dropout is not None:
x = self.dropout(x)
if isFnet:
return torch.split(x, [batch_dim, batch_dim], dim=0)
else:
return [x]
构造张量
class CorrBlock:
def __init__(self, fmap1:torch.Tensor, fmap2:torch.Tensor, num_levels:int=4, radius:int=4):
self.num_levels = num_levels
self.radius = radius
self.corr_pyramid = []
# all pairs correlation
corr = CorrBlock.corr(fmap1, fmap2)
batch, h1, w1, dim, h2, w2 = corr.shape
corr = corr.reshape(batch*h1*w1, dim, h2, w2)
self.corr_pyramid.append(corr)
for i in range(self.num_levels-1):
corr = F.avg_pool2d(corr, 2, stride=2)
self.corr_pyramid.append(corr)
def __call__(self, coords:torch.Tensor):
r = self.radius
coords = coords.permute(0, 2, 3, 1)
batch, h1, w1, _ = coords.shape
#print(coords.shape)
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i]
dx = torch.linspace(-r, r, 2*r+1, device=coords.device)
dy = torch.linspace(-r, r, 2*r+1, device=coords.device)
delta = torch.stack(torch.meshgrid(dy, dx), dim=-1)
centroid_lvl = coords.reshape(batch*h1*w1, 1, 1, 2) / 2**i
delta_lvl = delta.view(1, 2*r+1, 2*r+1, 2)
coords_lvl = centroid_lvl + delta_lvl
corr = bilinear_sampler(corr, coords_lvl)[0]
corr = corr.view(batch, h1, w1, -1)
out_pyramid.append(corr)
out = torch.cat(out_pyramid, dim=-1)
return out.permute(0, 3, 1, 2).contiguous().float()
@staticmethod
def corr(fmap1:torch.Tensor, fmap2:torch.Tensor):
batch, dim, ht, wd = fmap1.shape
fmap1 = fmap1.view(batch, dim, ht*wd)
fmap2 = fmap2.view(batch, dim, ht*wd)
corr = torch.matmul(fmap1.transpose(1,2), fmap2)
corr = corr.view(batch, ht, wd, 1, ht, wd)
return corr / torch.sqrt(torch.tensor(dim).float())
光流初始化
def coords_grid(batch:int, ht:int, wd:int, device:torch.device)->torch.Tensor:
coords = torch.meshgrid(torch.arange(ht, device=device), torch.arange(wd, device=device))
coords = stack([coords[1],coords[0]], dim=0).float()
return coords[None].repeat(batch, 1, 1, 1)
def initialize_flow(self, img:torch.Tensor):
""" Flow is represented as difference between two coordinate grids flow = coords1 - coords0"""
N, C, H, W = img.shape
coords0 = coords_grid(N, H//8, W//8, device=img.device)
coords1 = coords_grid(N, H//8, W//8, device=img.device)
更新
class BasicUpdateBlock(nn.Module):
def __init__(self, args, hidden_dim:int=128, input_dim:int=128):
super(BasicUpdateBlock, self).__init__()
self.args = args
self.encoder = BasicMotionEncoder(args)
self.gru = SepConvGRU(hidden_dim=hidden_dim, input_dim=128+hidden_dim)
self.flow_head = FlowHead(hidden_dim, hidden_dim=256)
self.mask = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 64*9, 1, padding=0))
def forward(self, net:torch.Tensor, inp:torch.Tensor, corr:torch.Tensor, flow:torch.Tensor, upsample:bool=True):
motion_features = self.encoder(flow, corr)
inp = torch.cat([inp, motion_features], dim=1)
net = self.gru(net, inp)
delta_flow = self.flow_head(net)
# scale mask to balence gradients
mask = .25 * self.mask(net)
return net, mask, delta_flow
参考
【论文简述及翻译】RAFT: Recurrent All-Pairs Field Transforms for Optical Flow(ECCV 2020)_raft光流论文-CSDN博客
【精选】光流估计算法RAFT的论文和代码阅读_raft光流-CSDN博客
(论文解读)RAFT: Recurrent All-Pairs Field Transforms for Optical Flow_CyrilSterling的博客-CSDN博客
ECCV 2020最佳论文讲了啥?作者为ImageNet一作、李飞飞高徒邓嘉 - 知乎