性能优化:JIT即时编译与AOT提前编译
优质博文:IT-BLOG-CN
一、简介
JIT与AOT的区别: 两种不同的编译方式,主要区别在于是否处于运行时进行编译。
JIT:Just-in-time动态(即时)编译,边运行边编译:在程序运行时,根据算法计算出热点代码,然后进行JIT实时编译,这种方式吞吐量高,有运行时性能加成,可以跑得更快,并可以做到动态生成代码等,但是相对启动速度较慢,并需要一定时间和调用频率才能触发JIT的分层机制。JIT缺点就是编译需要占用运行时资源,会导致进程卡顿。
AOT:Ahead Of Time指运行前编译,预先编译:AOT编译能直接将源代码转化为机器码,内存占用低,启动速度快。无需runtime运行,直接将runtime静态链接至最终的程序中,但无运行时性能加成,不能根据程序运行情况做进一步的优化,AOT缺点就是在程序运行前编译会使程序安装的时间增加。
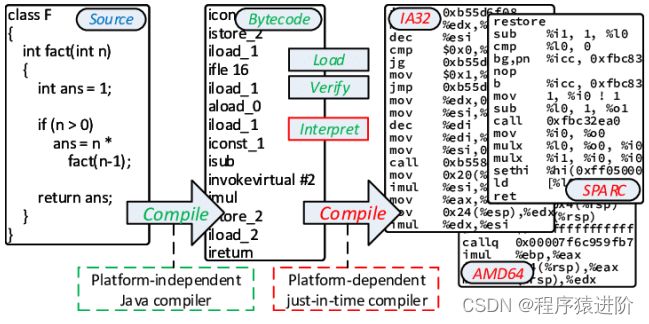
JIT即时编译指的是在程序的运行过程中,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。而AOT编译指的则是,在程序运行之前,便将字节码转换为机器码的过程。
.java -> .class -> (使用jaotc编译工具) -> .so(程序函数库,即编译好的可以供其他程序使用的代码和数据)
二、JIT
在HotSpot虚拟机中,内置了两种JIT,分别为C1编译器和C2编译器,这两个编译器的编译过程是不一样的。
【1】C1编译器:C1编译器是一个简单快速的编译器,主要的关注点在于局部性的优化,适用于执行时间较短或对启动性能有要求的程序,也称为Client Compiler。
【2】C2编译器:C2编译器是为长期运行的服务器端应用程序做性能调优的编译器,适用于执行时间较长或对峰值性能有要求的程序,也称为Server Compiler,例如,服务器上长期运行的Java应用对稳定运行就有一定的要求。JDK 6开始定义服务器级别的机器是至少有两个CPU和2GB的物理内存,才开启C2;
【3】分层编译: 在Java8中,默认开启分层编译,在1.8之前,分层编译默认是关闭的。在Java7之前,需要根据程序的特性来选择对应的JIT,虚拟机默认采用解释器和其中一个编译器配合工作。
分层编译将JVM的执行状态分为了5个层次:
【1】第 0 层:程序解释执行,默认开启性能监控功能Profiling,如果不开启,可触发第二层编译;
【2】第 1 层:可称为C1编译,将字节码编译为本地代码,进行简单、可靠的优化,不开启Profiling;
【3】第 2 层:也称为C1编译,开启Profiling,仅执行带方法调用次数和循环回边执行次数profiling的C1编译;
【4】第 3 层:也称为C1编译,执行所有带Profiling的C1编译;
【5】第 4 层:可称为C2编译,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
mixed mode代表是默认的混合编译模式,除了这种模式外,我们还可以使用-Xint参数强制虚拟机运行于只有解释器的编译模式下,这时JIT完全不介入工作;也可以使用参数-Xcomp强制虚拟机运行于只有JIT的编译模式下。如下:

如果只想开启C2,可以关闭分层编译-XX:-TieredCompilation,如果只想用C1,可以在打开分层编译的同时,使用参数:-XX:TieredStopAtLevel=1
C1、C2和C1+C2,分别对应client、server和分层编译。C1编译速度快,优化方式比较保守;C2编译速度慢,优化方式比较激进。C1+C2在开始阶段采用C1编译,当代码运行到一定热度之后采用G2重新编译。
参数-XX:ReservedCodeCacheSize = N(其中N是为特定编译器提供的默认值)主要设置热点代码缓存codecache的大小。如果缓存不够,则JIT无法继续编译,并且会去优化,比如编译执行改为解释执行,由此,性能会降低。同时,可以通过java -XX:+PrintCodeCache查看codecache的使用情况:
C:/Users/Administrator> java -XX:+PrintCodeCache
CodeCache: size=245760Kb used=1165Kb max_used=1165Kb free=244594Kb
bounds [0x000000010be1b000, 0x000000010c08b000, 0x00000011ae1b000]
total_blobs=293 nmethods=48 adapters=159
compilation: enable
相关参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
| -XX:InitialCodeCacheSize | 2555904(240M) | 默认的CodeCache区域大小,单位为字节 |
| -XX:ReservedCodeCacheSize | 251658240(240M) | CodeCache区域的最大值,单位为字节 |
| -XX:CodeCacheExpansionSize | 65536(64K) | CodeCache每次扩展大小,单位为字节 |
| -XX:ExitOnFullCodeCache | false | 当CodeCache区域满了的时候是否退出JVM |
| -XX:UseCodeCacheFlushing | false | 是否在关闭JIT编译前清除CodeCache |
| -XX:MinCodeCacheFlushingInterval | 30 | 刷新CodeCache的最小时间间隔 ,单位为秒 |
| -XX:CodeCacheMinimumFreeSpace | 512000 | 当CodeCache区域的剩余空间小于参数指定的值时停止JIT编译。剩余的空间不会再用来存放方法的本地代码, 可以存放本地方法适配器代码 |
| -XX:CompileThreshold | 10000 | 指定方法在在被JIT编译前被调用的次数 |
| -XX:OnStackReplacePercentage | 140 | 该值为用于计算是否触发OSR(OnStackReplace)编译的阈值 |
如何判断热点代码
【1】基于采样的热点探测: 主要是虚拟机会周期性的检查各个线程的栈顶,若某个或某些方法经常出现在栈顶,那这个方法就是“热点方法”。优点是实现简单。缺点是很难精确一个方法的热度,容易受到线程阻塞或外界因素的影响。
【2】基于计数器的热点探测(典型应用-Hotspot): 主要就是虚拟机给每一个方法甚至代码块建立了一个计数器,统计方法的执行次数,超过一定的阀值则标记为此方法为热点方法。Hotspot使用的基于计数器的热点探测方法。然后使用了两类计数器:方法调用计数器和回边计数器。当方法计数器和回边计数器之和超过方法计数器阈值时,就会触发JIT编译器。
【3】方法调用计数器: 方法调用计数器用于统计方法被调用的次数,默认阈值在C1模式下是1500次,在C2模式在是10000次,可通过-XX: CompileThreshold来设定;而在分层编译的情况下-XX: CompileThreshold指定的阈值将失效,此时将会根据当前待编译的方法数以及编译线程数来动态调整。
【4】回边计数器: 回边计数器用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”Back Edge,该值用于计算是否触发C1编译的阈值,在不开启分层编译的情况下,C1默认为13995,C2默认为10700,可通过-XX: OnStackReplacePercentage=N来设置;而在分层编译的情况下,-XX: OnStackReplacePercentage指定的阈值同样会失效,此时将根据当前待编译的方法数以及编译线程数来动态调整。
回边计数器阈值计算规则:
1、C1模式下:CompileThreshold*OnStackReplacePercentage/100;即:方法调用计数器阈值*OSR比率/100;
2、C2模式下:(CompileThreshold)*(OnStackReplacePercentage-InterpreterProfilePercentage)/100;即:方法调用计数器阈值*(OSR比率 - 解释器监控比率)/100;
JIT优化
JIT编译运用了一些经典的编译优化技术来实现代码的优化:主要有两种:方法内联和逃逸分析。
【1】方法内联: 方法内联的优化行为就是把目标方法的代码复制到发起调用的方法之中,避免发生真实的方法调用。方法内联不仅可以消除调用本身带来的性能开销,还可以进一步触发更多的优化。
private int add1(int s1, int s2, int s3, int s4) {
return add2(s1+s2) + add2(s3+s4);
}
private int add2(int s1, int s2) {
return s1+s2;
}
// 方法内联后的代码
private int add(int s1, int s2, int s3, int s4) {
return s1+s2+s3+s4;
}
提高方法内联的策略:调整参数;写小方法;使用static、final关键字,不用出现方法继承,没有额外的类型检查,就可能发生内联;
【2】锁消除: 如果是在单线程环境下,JIT编译会对这个对象的方法锁进行锁消除,jdk1.8默认开启。例如:
//-XX:-EliminateLocks 先关闭锁消除, 再打开, 执行此段代码100万次查看差别很大
public static String getString(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
【3】标量替换: 逃逸分析证明一个对象不会被外部访问,如果这个对象可以被拆分的话,当程序真正执行的时候可能不创建这个对象,可以直接创建它的成员变量来代替,前提要开启逃逸分析(jdk1.8默认开启逃逸分析-XX:+DoEscapeAnalysis; -XX:+EliminateAllocations开启标量替换jdk1.8默认开启)。
public void foo() {
Person info = new Person ();
info.name = "queen";
info.age= 18;
}
//逃逸分析后,代码会被优化(标量替换)为:
public void foo() {
String name= "queen";
int age= 18;
}
三、AOT
优点: Java虚拟机加载已经预编译成二进制库,可以直接执行。不必等待及时编译器的预热,减少Java应用给人带来“第一次运行慢” 的不良体验。在程序运行前编译,可以避免在运行时的编译性能消耗和内存消耗。可以在程序运行初期就达到最高性能,程序启动速度快。运行产物只有机器码,打包体积小。
缺点: 由于是静态提前编译,不能根据硬件情况或程序运行情况择优选择机器指令序列,理论峰值性能不如JIT,没有动态能力,同一份产物不能跨平台运行。第一种即时编译JIT是默认模式,Java Hotspot虚拟机使用它在运行时将字节码转换为机器码。后者提前编译AOT由新颖的GraalVM编译器支持,并允许在构建时将字节码直接静态编译为机器码。
现在正处于云原生,降本增效的时代,Java相比于Go、Rust等其他编程语言非常大的弊端就是启动编译和启动进程非常慢,这对于根据实时计算资源,弹性扩缩容的云原生技术相冲突,Spring6借助AOT技术在运行时内存占用低,启动速度快,逐渐的来满足Java在云原生时代的需求,对于大规模使用Java应用的商业公司可以考虑尽早调研使用JDK17,通过云原生技术为公司实现降本增效。
Graalvm
Spring6支持的AOT技术,底层通过GraalVM支持,Spring也对GraalVM本机映像提供了一流的支持。GraalVM是一种高性能JDK,旨在加速用Java和其他JVM语言编写的应用程序的执行,同时还为JavaScript、Python和许多其他流行语言提供运行时。GraalVM提供两种运行 Java应用程序的方法:在HotSpot JVM上使用Graal即时JIT编译器或作为提前AOT编译的本机可执行文件。GraalVM的多语言能力使得在单个应用程序中混合多种编程语言成为可能,同时消除了外部调用成本。GraalVM向HotSpot Java虚拟机添加了一个用Java编写的高级即时JIT优化编译器。
GraalVM具有以下特性:
【1】一种高级优化编译器,它生成更快、更精简的代码,需要更少的计算资源;
【2】AOT本机图像编译提前将Java应用程序编译为本机二进制文件,立即启动,无需预热即可实现最高性能;
【3】Polyglot编程在单个应用程序中利用流行语言的最佳功能和库,无需额外开销;
【4】高级工具在Java和多种语言中调试、监视、分析和优化资源消耗;
Native Image
目前业界除了这种在JVM中进行AOT的方案,还有另外一种实现Java AOT的思路,那就是直接摒弃JVM,和C/C++一样通过编译器直接将代码编译成机器代码,然后运行。这无疑是一种直接颠覆Java语言设计的思路,那就是GraalVM Native Image。它通过C语言实现了一个超微缩的运行时组件Substrate VM,基本实现了JVM的各种特性,但足够轻量、可以被轻松内嵌,这就让Java语言和工程摆脱JVM的限制,能够真正意义上实现和C/C++一样的AOT编译。这一方案在经过长时间的优化和积累后,已经拥有非常不错的效果,基本上成为Oracle官方首推的Java AOT解决方案。
Native Image是一项创新技术,可将Java代码编译成独立的本机可执行文件或本机共享库。在构建本机可执行文件期间处理的Java字节码包括所有应用程序类、依赖项、第三方依赖库和任何所需的JDK类。生成的自包含本机可执行文件特定于不需要JVM的每个单独的操作系统和机器体系结构。
Native Image 构建过程
下载GraalVM 并配置环境变量:将JAVA_HOME修改为graalvm的位置,并将Path修改为graalvm的bin位置。
变量名:JAVA_HOME
变量值:D:\graalvm-ce-java17-22.3.0
检查是否安装成功
C:/Users/Administrator>java -version
openjdk version "17.0.5" 2023-10-32
OpenJDK Runtime Environment GraalVM CE 22.3.0 (build 17.0.5+8-jvmci-22.3-b08)
OpenJDK 64-Bit Server VM GraalVM CE 22.3.0 (build 17.0.5+8-jvmci-22.3-b08, mixed mode, sharing)
通过gu install native-image安装native-image插件,并通过gu list检查版本
C:/Users/Administrator>gu install native-image
......
C:/Users/Administrator>gu list
......
native-image 22.3.0 Native Image Early adopter
对比: 通过javac xx.java和native-image xx构建文件,其中包含了SVM和JDK各种库后的大小,虽然相比C/C++的二进制文件来说体积偏大,但是对比完整JVM来说,可以说是已经是非常小了。
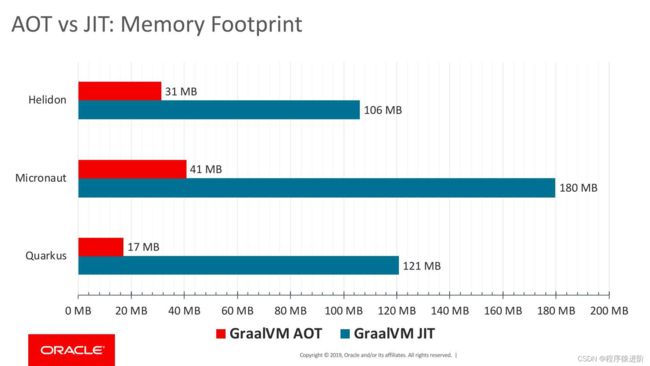
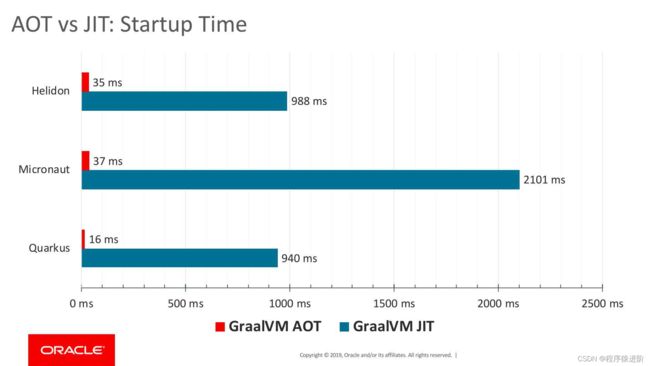
相比于使用JVM运行,Native Image的速度要快上不少,cpu占用也更低一些,从官方提供的各类实验数据也可以看出Native Image对于启动速度和内存占用带来的提升是非常显著的: