k8s的grafana的dashboard指标分析
1. Cluster SLO and Error budget
1.1 Cluster control plane SLO
avg(
avg_over_time((sum without ()(kube_pod_container_status_ready{namespace="kube-system",pod=~".*.dashboard.*|.*.dns.*|kube.*|.*.calico.*|.*.flannel.*|.*.etcd.*"})
/
count without ()(kube_pod_container_status_ready{namespace="kube-system",pod=~".*.dashboard.*|.*.dns.*|kube.*|.*.calico.*|.*.flannel.*|.*.etcd.*"}))[$duration:5m])
)
k8s集群要达到的服务质量目标(SLO)SLO 关注时间
99% 的可用性意味着什么?它不是 1% 的错误率 (失败的 http 响应的百分比),而是在一个预定义的时间段内可用服务的时间百分比。
1.2 Cluster control plane error budget remaining
(( avg(avg_over_time((sum without ()(kube_pod_container_status_ready{namespace="kube-system",pod=~".*.dashboard.*|.*.dns.*|kube.*|.*.calico.*|.*.flannel.*|.*.etcd.*"})
/
count without ()(kube_pod_container_status_ready{namespace="kube-system",pod=~".*.dashboard.*|.*.dns.*|kube.*|.*.calico.*|.*.flannel.*|.*.etcd.*"}))[$duration:5m])
)) - 0.98999999999999999 )
*
avg((time() - timestamp(up{job="apiserver",namespace="default",service="kubernetes"} offset $duration))) 
群集控制平面错误预算剩余
1.3 Promtheus monitoring SLO
avg(
avg_over_time((sum without ()(kube_pod_status_ready{namespace="monitoring",pod="prometheus-prometheus-operator-prometheus-0",condition="true"})
/
count without ()(kube_pod_status_ready{namespace="monitoring",pod="prometheus-prometheus-operator-prometheus-0"}))[$duration:5m])
) 
2. Overall cluster status

Burstable: pod中只要有一个容器的requests和limits的设置不相同,该pod的QoS即为Burstable。举例如下:
Container bar没有指定resources
containers:
name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
requests:
cpu: 10m
memory: 1Gi
name: bar
Burstable 举例2:pod中只要有一个容器没有对cpu或者memory中的request和limits都没有明确指定。
containers:
name: foo
resources:
limits:
memory: 1Gi
name: bar
resources:
limits:
cpu: 100m
Burstable 举例3:Container foo没有设置limits,而bar requests与 limits均未设置。
containers:
name: foo
resources:
requests:
cpu: 10m
memory: 1Gi
name: bar
Best-Effort:如果对于全部的resources来说requests与limits均未设置,该pod的QoS即为Best-Effort。举例如下:
containers:
name: foo
resources:
name: bar
resources:

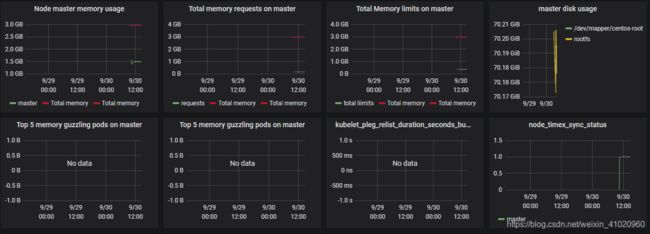
3.master Node details

 4. Namespace monitoring details
4. Namespace monitoring details




5. API Server

