【MYSQL】索引
文章目录
- 索引
- Mysql与磁盘交互的基本单位
- 共识
- 索引理解
- 页目录
- 目录页
- 聚簇索引与非聚簇索引
- 索引操作
- 创建主键索引
- 唯一索引的创建
- 查询索引
- 删除索引
- 以多列的索引结构(复合索引)
- 全文索引
索引
//给column列添加索引
alter table table_name index(column);
Mysql与磁盘交互的基本单位
show global status like 'innodb_page_size';
page=16384 (bit) = 16 (kb)
共识
- Mysql中的数据文件,是以page(16kb)为单位保存在磁盘的
- CURD 操作全部要经过计算
- 一旦进行计算,数据要加载到内存,CPU负责运算
- 在特定时间内,MySQL表中的数据,磁盘中有,内存中也有,操作完内存数据后,再刷新到磁盘
- 因此,MySQL服务器 在内存中运行的时候,在服务器内部就申请了Buffer Pool的大内存空间,用来各种缓存,以及和磁盘数据进行IO交互
- 提高效率,一定要尽可能减少系统和磁盘IO的次数
索引理解
向一个具有主键的表中,乱序插入数据,数据会自动排序,这是为什么?
mysql内部一定需要并page存在大量page,也就是说,mysql必须将多个同时存在的page管理起来。
因此,page不仅仅是一个内存块,page内部也必须写入对应的管理信息。
page的存在其实是计算机预存储的一种机制,局部性原理的一种体现。
页目录
给页加入目录,可以极大地提高搜索效率,这是一种以空间换时间的做法

目录页
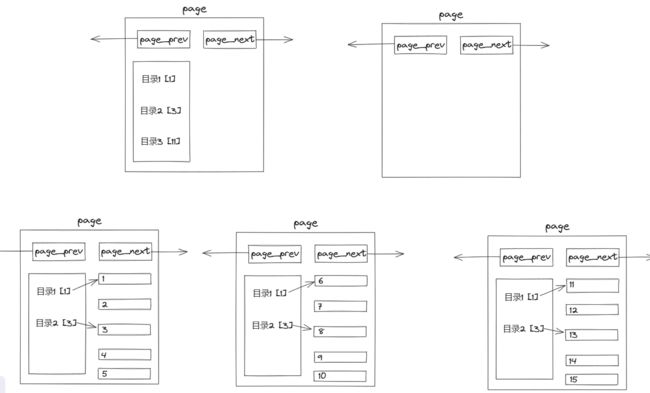
1、叶子节点保存数据,非叶子节点只有目录
因为不存数据,可以存更多目录项,管理更多page,因此这是一棵 “ 矮胖 ” 的多叉树
2、叶子节点全部用链表级联
a、B+树的叶子是级联的
b、我们希望进行范围查找
为什么不使用其他数据结构?
链表?线性遍历
二叉搜索树?退化为线性遍历
AVL和红黑树?很好,但没B+树好
Hash?范围查找不太好
B树?page里存了数据,树会变得较瘦较高,且叶子节点不相连,范围查找就要多次遍历B树
聚簇索引与非聚簇索引
将目录和数据放在一起的索引叫聚簇索引,不在一起(地址)则是非聚簇索引。
在innodb里,创建的一张表生了两个文件frm和ibd文件
在myisam里,有三张表,MYD和MYI分别是数据和索引
所以innodb是聚簇索引,而myisam是非聚簇索引。
在innodb存储结构中,非主键索引(辅助索引)的叶子节点里没有数据,只记录主键的key值,因为如果存数据就会导致特别大。
回表查询:
首先检索辅助索引获得主键,然后用主键去主键索引里获得记录,这个过程叫做回表查询
索引操作
创建主键索引
alter table table_name add primary key(id);
唯一索引的创建
alter table table_name add unique(id);
查询索引
//1
show keys from table_name;
//2
show index from table_name;
删除索引
alter table table_name drop primary key;
alter table table_name drop index index_name;
drop index index_name on table_name(column);
以多列的索引结构(复合索引)
alter table table_name add index(name,email);
索引覆盖:
(name,email) email不是主键,但高频查找email,就可以构建符合索引,返回索引的值,这被称为索引覆盖。
复合索引具有最左匹配原则。
全文索引
要求存储引擎必须是MyisAM中采用,且只支持英文,若要支持中文,可以使用sphinx的中文版(coreseek)
FULLTEXT(column1,column2);
select * from article where match(title,body) against('database');