『网络篇』之手把手实现强缓存与协商缓存
文章目录
- 一、文章内容
- 二、文章介绍
- 三、浏览器缓存
- 四、缓存相关头信息
-
- HTTP1.0相关响应头
- HTTP1.1相关响应头
- 五、浏览器缓存之强缓存
- 六、浏览器缓存之协商缓存
- 七、手把手之实现强缓存
-
- 1. 搭建服务器环境
-
- 静态资源文件内容
- 2. 处理请求数据
- 3. 设置强缓存
- 4. 强缓存效果
- 八、手把手之实现协商缓存
-
- 1. 获取文件上一次修改的时间
- 2. 配置协商缓存
- 3. 协商缓存效果
- 九、知识小补充:
- 十、总结
一、文章内容
- 浏览器缓存概念
- 与缓存有关的请求头
- 强制缓存与协商缓存的概念
- nodejs实现强缓存与协商缓存
二、文章介绍
本文为网络篇系列中的第一篇文章,主要介绍的是浏览器根据服务器返回数据的响应头做出的一系列处理,以及强缓存和协商缓存是如何进行判断是否使用缓存数据,最后将手把手实现nodejs实现强缓存以及协商缓存案例。
三、浏览器缓存
进入正题,那么浏览器的缓存是什么?实际上浏览器会将请求并返回的WEB资源(静态资源),如HTML页面、JS文件、图片、CSS文件等复制成一个副本储存在浏览器的缓存中,当使用缓存策略或得到服务器返回304缓存重定向时,会从浏览器缓存中获取这个副本文件。
那么浏览器是如何判断请求的资源是否可以使用缓存呢,在计算机世界里当然不能自我判断。真正让浏览器做出判断的是服务器返回的响应头,是否使用浏览器的缓存文件会由服务器来告知。
四、缓存相关头信息
那么与缓存相关的有哪些头信息呢?我们可以将其分为两个阶段:HTTP1.0与HTTP1.1
HTTP1.0相关响应头
在HTTP1.0中有这么两个响应头:Pragma、Expires
- Pragma
Pragma响应头是控制浏览器是缓存文件以及是否使用缓存文件的响应头,它对应了两个常用值:no-cache、no-store。其中的no-cache并非是使浏览器不缓存文件,而是缓存文件却不使用缓存的副本,强制浏览器向服务器获取资源。而no-store才是强制浏览器不缓存也不使用缓存的副本文件。 - Expires
Expires是使浏览器使用缓存,且Expires的值为一个GMT时间对象(必须为时间对象)来告诉浏览器缓存的时间,如果时间没有超过缓存的时间,则不需要向服务器发送请求,直接使用缓存文件。
HTTP1.1相关响应头
在HTTP1.1中则有一个字段替代了Pragma与Expires,那便是Cache-Control,这里要提一下HTTP的协议是向下兼容的,即当HTTP1.0与1.1的字段同时存在时优先使用1.1,但1.1失效之后会使用1.0的字段。因此,在设置缓存相关的响应头时,最好是将HTTP1.1与1.0都写上。
- Cache-Control
Cache-Control包括了HTTP1.0中的两个字段,通过Cache-Control:no-cache可以达成Pragma:no-cache的效果,而设置缓存则有了一定的变化。是使用Cache-Control:max-age=10的形式来设置缓存时间,max-age所对应的时间单位是秒。
上述所说的三个响应头是用来设置强缓存的响应头,但是强缓存会存在一定的缺陷,也就是根文件无法被缓存,为了解决这个问题,有了新的响应头和请求头来实现协商缓存(对比缓存),便是请求头中的If-Modified-Since对应响应头中的Last-Modified以及请求头中的If-None-Match对应响应头中的Etag,具体的含义我们在讲到协商缓存时再展开。
五、浏览器缓存之强缓存
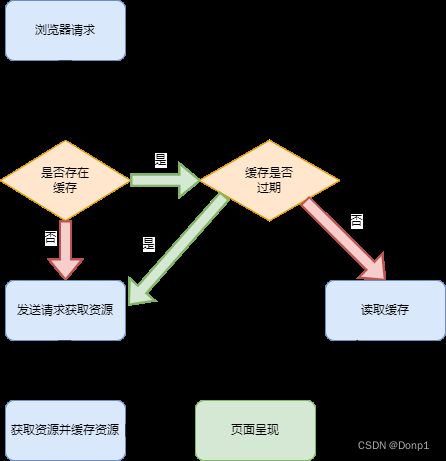
强缓存流程图
不太熟练的流程图画的有点抽象,不过还是能够理解的。我多嘴复述一遍,首先由浏览器判断本地是否存在待请求资源的缓存,若不存在则向服务器发送资源获取请求。若存在则判断文件的缓存时间是否过期,若过期同样向服务器发送请求,若不过期则从缓存中获取资源并在页面呈现。
那么浏览器如何知道文件的缓存时间?就是通过上一次获取资源时服务器返回的响应头中是否携带了Cache-Control、Expires、Pragma等相关响应头,根据响应头中携带的策略、时间对文件进行缓存。
但强缓存的问题便是,每次向服务器返回根文件时,服务器没法判断浏览器是否存在缓存,因此每次服务器在得到请求时都会返回一份新的根文件。这便是强缓存无法缓存根文件的原因。
六、浏览器缓存之协商缓存
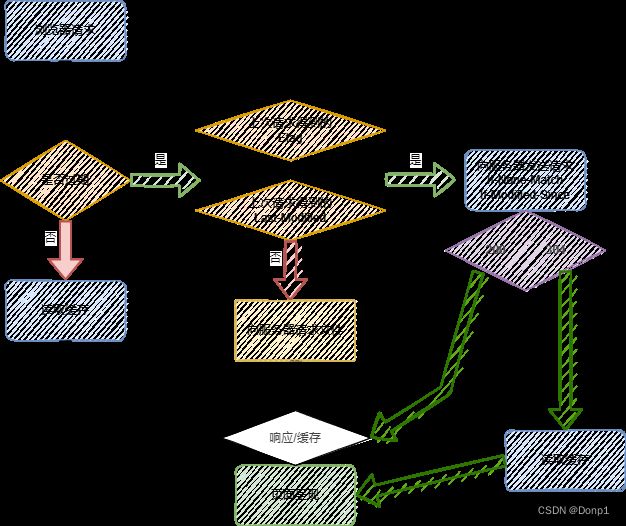
协商缓存流程图
为了解决强缓存无法缓存根文件的问题,协商缓存出现了。协商缓存又名对比缓存,是因为服务器通过对比浏览器发送请求头中的If-None-Match、If-Modified-Since两个字段与本地的文件信息进行比对,当两者相同时意为文件并没有发生过修改,浏览器将返回状态码304来使浏览器使用缓存中的数据,当其中任何一项与服务器数据信息不一致时,便是文件被修改过了,浏览器返回状态码200并将最新的文件携带着Etag、Last-Modified响应头返回给浏览器。
我们来解惑一下这四个神奇的字段代表着什么,Etag指的是文件的唯一标识,一般我们可以使用md5加密文件部分的内容来得到这个唯一标识,MD5算法只要加密的内容是一样的,那么得到的结果便是一致的,但只要输入内容有一点点的改变,最后得到的结果就会有翻天覆地的改变(雪崩效应)。而浏览器发送请求头中的If-None-Match便是上一次从浏览器响应头中获取到的Etag。
而Last-Modified便是文件最后修改的时间,浏览器将其保存并在下一次发送请求时携带在If-Modified-Since请求头发送给服务器,由服务器进行时间对比。
注意:在对比时应该先对比唯一标识Etag的一致性再对比最后修改时间。
七、手把手之实现强缓存
1. 搭建服务器环境
首先创建目录结构如下:在public文件夹下创建三个静态资源文件

静态资源文件内容

这里就展示HTML页面的内容,至于CSS与JS的部分大家可以自行填写测试,这并不是重点。当浏览器得到HTML资源发现其含有其他的资源文件时会再次发送HTTP请求向资源对应服务器获取资源数据。
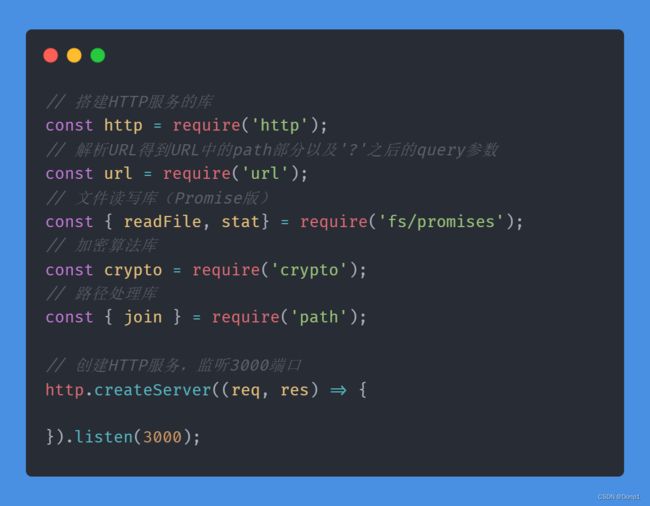
因为是使用nodejs直接进行编程,只需要保证电脑上安装了nodejs就可以直接进行代码编写,以下便是搭建nodejs服务的基本代码框架,以及后续将会使用到的功能库。
2. 处理请求数据
与express不同,nodejs并没有对请求对象进行功能性封装,不过我们仍然可以在require对象中得到HTTP请求相关的数据,如:请求头、请求方式、请求地址、HTTP版本号等信息。这里我们关注的便是根据请求地址来得到对应的资源文件。

3. 设置强缓存

设置强缓存的关键便是在读取文件之后给响应头设置的两个请求头Expires与Cache-Control,那么设置完之后会是什么效果呢?
4. 强缓存效果

我们访问页面可以看到CSS样式已经生效、当然JS的文件也会执行,这并不是关键,让我们看看服务端的控制台日志:

我们可以看到在这一次请求中,浏览器向服务端发送了4条HTTP请求分别获取图上对应的数据,但只要我们在10s之内多次刷新我们的页面,我们可以得到如下结果:

我们可以清楚的看到,除了根文件之外的所有文件都没有再向服务器获取了,这是因为我们设置的强缓存生效了。但是我们同时也能看到一个问题:根文件永远没有办法得到缓存。为了验证是因为缓存生效才不向服务器发送请求,我们看一下从缓存中得到的文件请求:
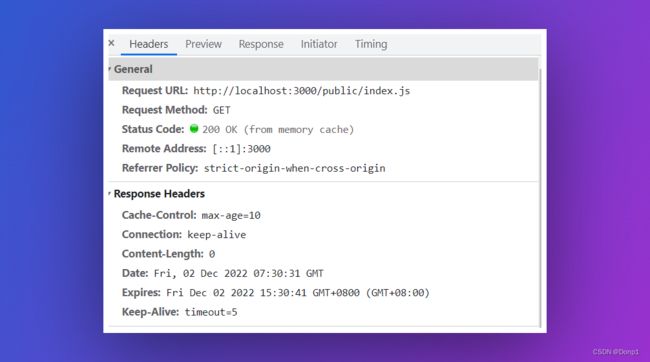
我们可以看到Response Headers中的Expires、Cache-Control是存在的,同时StatusMessage为from memory cache,因为我使用的是Chrome的最新版,他会自动的在GMT时间上+8小时转为东八区时间,因此Expires对应的时间是准确的时间。
八、手把手之实现协商缓存
那么为了解决根文件无法被浏览器缓存的问题,让我们来着手协商缓存吧。协商缓存的请求处理与强缓存一致,因此这里就直接从协商缓存处理讲起:
1. 获取文件上一次修改的时间
首先看一下使用fs中的stat得到的文件状态数据,获取上一次修改的时间属性mtime就在其中

在图中我们可以看到三个时间状态,分别是ctime、atime、mtime:
- ctime(change time) 是最后一次修改文件属性的时间
- atime(access time) 是最后一次访问文件的时间即最后一次阅读时间
- mtime(modify time) 指的是最后一次文件被修改的时间
2. 配置协商缓存
因此我们根据请求头中的If-Modifed-Match与文件的mtime时间进行比较,但两者的时间是精确到秒的,如果在一秒内有多次的变更是无法监测到的,因此我们还需要利用文件的内容来作为唯一的标识,也就是Etag。

3. 协商缓存效果

从响应头中没有看到Etag与Last-Modifed,以及从请求头中看到的If-None-Match与If-Modified-Since再加上304的状态码,我们可以清楚的了解到,当前的根文件也得到了浏览器的缓存。这就是协商缓存的全部内容,大家可以跟着代码尝试着构建出对应的缓存。
九、知识小补充:
express中配置协商缓存就相对简单的多了,因为express就是一个集成性非常好的框架,只需要对express静态资源获取时配置一些属性即可开启协商/强缓存:

十、总结
这一篇文章可以说是从早写到晚,这种又臭又长的文章其实并不怎么会讨人喜欢,而且可能笔者也没有将缓存、手把手实现讲的清楚。但作为技术人,我认为文章只是总结自己所学的知识,看看自己能否逻辑清晰的将所学知识点分享出来,也是自己技术掌握的一个考核吧。
希望大家一起加油!我是Donp1,下次见~❄️
仓库地址:Gitee仓库