联邦元学习
联邦学习算法
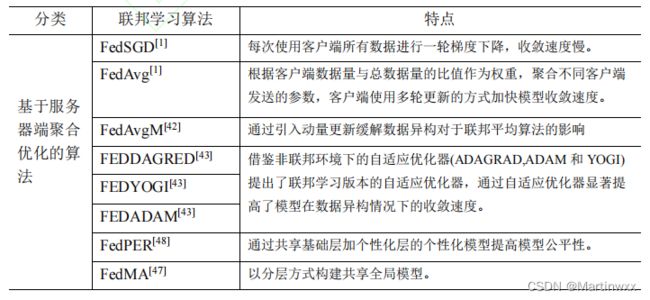
基于服务器端聚合方法优化的算法和基于客户端优化的算法。
(一)优化模型聚合的方法(基于服务器端聚合优化的算法)
- 文献[48]提出了一种基于迭代模型平均的深层网络联合学习方法,对于不平衡和非独立同分布是稳健的。
[48] ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers[J]. arXiv preprint arXiv:1912.00818, 2019
- 联邦平均算法(FedAvg)[1]
客户端数据量相对于全体数据占比作为权重 - FedSGD[1]
使用客户端所有数据进行一轮梯度下降的方式 - FedAvgM[42]
引入动量的方法
[42] HSU T M H, QI H, BROWN M. Measuring the effects of non-identical data distribution for federated visual classification[J]. arXiv preprint arXiv:1909.06335, 2019.
- 联邦学习版本的自适应优化器
FEDADAGRAD[43],FEDYOGI[43],FEDADAM[43]
非联邦环境下的自适应优化器(ADAGRAD[44],ADAM[45]和YOGI[46])
[43] REDDI S, CHARLES Z, ZAHEER M, et al. Adaptive federated optimization[J]. arXiv preprint arXiv:2003.00295, 2020.
[44] DUCHI J, HAZAN E, SINGER Y. Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of machine learning research, 2011, 12(7).
[45] KINGMA D P, BA J. Adam: A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
[46] ZAHEER M, REDDI S, SACHAN D, et al. Adaptive methods for nonconvex optimization[J]. Advances in neural information processing systems, 2018, 31.
文献[47][48]提出两种分层聚合的方式
- FedPER[48]
共享基础层加个性化层的个性化联邦学习模型
其中基础层由不同客户端共同训练,个性化层由本地数据训练,
[47] WANG H, YUROCHKIN M, SUN Y, et al. Federated learning with matched averaging[J]. arXiv preprint arXiv:2002.06440, 2020.
[48] ARIVAZHAGAN M G, AGGARWAL V, SINGH A K, et al. Federated learning with personalization layers[J]. arXiv preprint arXiv:1912.00818, 2019
- 联邦匹配平均算法 FedMA[47]
以分层方式构建共享全局模型
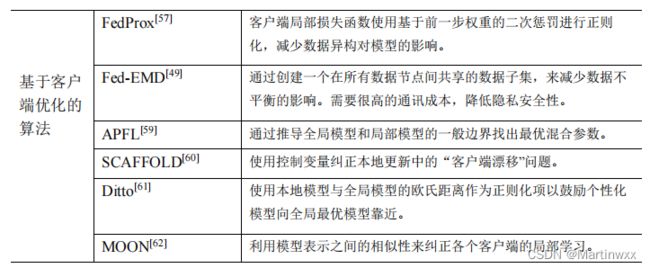
(二)优化本地模型的更新过程(基于客户端优化的算法)
- FedProx[57]
在文献[57]中,作者进一步扩展联邦平均算法(FedAvg),提出了一种新的算法 FedProx[57],它规定客户有局部损失函数,进一步使用基于前一步权重的二次惩罚进行正则化,在 数据异构 的环境中显示出对于联邦平均算法的进步性
[57] LI T, SAHU A K, ZAHEER M, et al. Federated ptimization in heterogeneous networks[J]. Proceedings of Machine Learning and Systems, 2020, 2: 429-450.
- Fed-EMD[49]
创建一个在所有数据节点间共享的数据子集,来减少数据不平衡的影响。通讯成本高。
[49] ZHAO Y, LI M, LAI L, et al. Federated learning with non-iid data[J]. arXiv preprint arXiv:1806.00582, 2018.
- APFL[59]
通过推导全局模型和局部模型的一般边界找出最优混合参数
[59] DENG Y, KAMANI M M, MAHDAVI M. Adaptive ersonalized federated learning[J]. arXiv preprint arXiv:2003.13461, 2020.
-
联邦平均算法
受数据不平衡影响大,不同客户端本地更新的同时无法了解其他客户端的更新信息,数据异构导致更新方向漂移
利用正则化可以约束本地模型更新方向 -
SCAFFOLD[60]
控制变量(方差减少)来纠正本地更新中的“客户端漂移问题”
利用客户间的相似性,降低通信成本
[60] KARIMIREDDY S P, KALE S, MOHRI M, et al. SCAFFOLD: Stochastic Controlled Averaging for On-Device Federated Learning[J]. 2019.
- Ditto[61]
在不同客户端损失函数中引入正则化项,通过正则化项前系数控制模型在个性化和鲁棒性间的权衡
本地模型与全局模型的欧氏距离作为正则化项以鼓励个性化模型向全局最优模型靠近
[61] LI T, HU S, BEIRAMI A, et al. Ditto: Fair and robust federated learning through personalization[C]//International Conference on Machine Learning. PMLR, 2021: 6357-6368.
- MOON[62]
利用模型表示之间的相似性来纠正各个客户端的局部学习
用全局模型与本地模型表示间的对比损失作为正则化项约束本地模型的更新
[62] LI Q, HE B, SONG D. Model-contrastive federated learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 10713-10722
元学习
(一)定义
元学习往往以小样本学习和对任务的快速适应作为切入点
训练集:不同任务T(支持集S+查询集Q)
支持集S上参数优化:得到对应任务T train的中间参数模型
查询集Q:使用模型 计算损失函数L
最小化不同任务T train上损失函数值 训练一个基础模型
测试集:通过任务T val的支持集数据进行几步梯度下降 得到新模型
利用T val中的查询集Q测试模型表现
(二)元学习分类
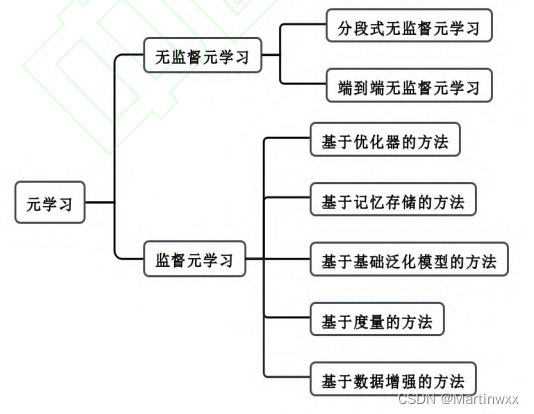
1.无监督元学习方法
常采用一种显示的方式自动构建数据集,通过构建虚标签的方式,将无监督学习转换为监督学习
①分阶段训练算法 CACTUs[6]
在无标签训练数据上使用无监督训练方法学习一个特征表示器,通过聚类的方式在无标签数据上进行聚类划分,并生成伪标签
[6] HSU K, LEVINE S, FINN C. Unsupervised learning via meta-learning[J]. arXiv preprint arXiv:1810.02334, 2018
②端到端的自监督算法 UMTRA[7]
数据增强的方式为每个图片生成一个增强数据并将原数据作为支撑集,增强图片作为查询集,从而构建 N-way-1-shot 任务
[7] KHODADADEH S, BOLONI L, SHAH M. Unsupervised meta-learning for few-shot image classification[J]. Advances in neural information processing systems, 2019, 32.
2.监督元学习方法
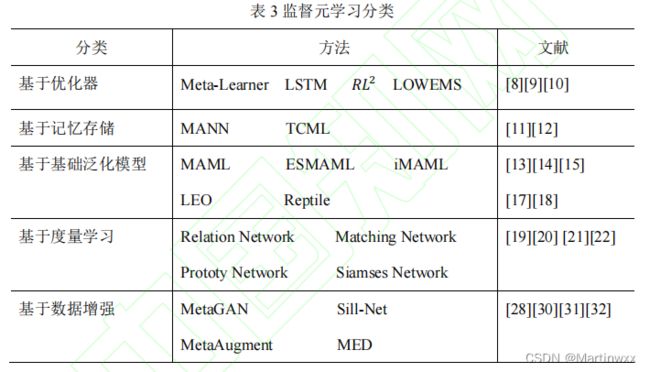
基于优化器的方法
基于记忆存储的方法
基于基础泛化模型的方法
基于度量学习的方法
基于数据增强的方法
(1)基于优化器的方法
旨在通过学习一个更好的优化器加快学习过程。
文献[8]中提出使用一个 LSTM 的元学习者来学习一个更新规则,一种新的类似于但不同于梯度下降的优化算法
在[9]中2利用一个慢速调整的强化学习去训练一个快速调整的强化学习
文献[10]中提出了一种加快神经网络训练速度的方法 LOWEMS[10]以实现快速的学习,为梯度下降算法训练
一个学习器以加快梯度下降算法的收敛速度
[8] RAVI S, LAROCHELLE H. Optimization as a model for few-shot learning[J]. 2016.
[9] DUAN Y, SCHULMAN J, CHEN X, et al. Rl $^ 2$: Fast reinforcement learning via slow reinforcement learning[J]. arXiv preprint arXiv:1611.02779, 2016.
[10] ANDRYCHOWICZ M, DENIL M, GOMEZ S, et al. Learning to learn by gradient descent by gradient descent[J]. Advances in neural information processing systems, 2016, 29
(2)基于记忆存储的方法
先验知识对于后续任务具有重要作用,合理利用先验知识可以帮助模型快速适应新的任务
文献[11]提出了一种带有记忆增强神经网络的元学习算法 MANN
外部存储器保存样本特征,元学习改进单元读取和写入方式,错位匹配以避免训练过程中记住样本位置。
由于权重更新缓慢,实现了网络长期记忆,外部存储实现短期记忆,最终实现元学习快速训练。
在[12]中,引入时间卷积网络访问之前的特征信息提出了一种元学习模型TCML,
在某个固定的时间内使用更加灵活的计算。通过时间卷积网络和注意力机制的集合,网络可以更加准确的在先前的信息中进行选择
[11] SANTORO A, BARTUNOV S, BOTVINICK M, et al. Meta-learning with memory-augmented neural networks[C]//International conference on machine learning. PMLR, 2016: 1842-1850.
[12] MISHRA N, ROHANINEJAD M, CHEN X, et al. A simple neural attentive meta-learner[J]. arXiv preprint arXiv:1707.03141, 2017
(3)基于基础泛化模型的方法
旨在于学习一个可以快速适应新任务的基础模型,当面对新任务时,仅仅通过简单的几步梯度下降就能获得快速适应新任务的模型。
(数学太多)
(4)基于度量学习的方法
旨在获得一个强大的特征提取器,通过在特征空间中度量不同样本间的距离进行分类。
文献[19]设计了一个 Meta-Critic 网络,该网络由核心价值网络(Meta Value Network),任务行为编码器(Task-Actor Encoder)组成。
用任务编码通过匹配网络来驱动对目标网络的监督,而不是合成其权重。
匹配网络[20]通过对比数据间的相似度来判断数据类别。
原型网络[21]将每个数据进行提取特征,并使用每个类别的特征均值作为该类别的原型。通过判断样本特征到不同类别的原型的距离来判断样本的类别。
匹配网络[20],原型网络[21],孪生网络[22],都是通过计算特征向量间的距离来判断样本类别。
***关系网络[23]***提出使用神经网络来计算样本间的匹配程度。
首先对查询集与支持集中的样本进行特征提取,然后进行拼接,将拼接后的特征输入神经网络计算出关系得分。
[19] SUNG F, ZHANG L, XIANG T, et al. Learning to learn: Meta-critic networks for sample efficient learning[J]. arXiv preprint arXiv:1706.09529, 2017.
[20] VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning[J]. Advances in neural information processing systems, 2016, 29.
[21] SNELL J, SWERSKY K, ZEMEL R. Prototypical networks for few-shot learning[J]. Advances in neural information processing systems, 2017, 30.
[22] KOCH G, ZEMEL R, SALAKHUTDINOV R. Siamese neural networks for one-shot image recognition[C]//ICML deep learning workshop. 2015, 2: 0.
[23] SANTORO A, RAPOSO D, BARRETT D G, et al. A simple neural network module for relational reasoning[J]. Advances in neural information processing systems, 2017, 30.
(5)基于数据增强的方法
元学习在解决小样本分类问题时,面临的最大挑战来源于训练数据的不足,通过不同的数据增强方式[24][25][26][27] [28],扩展训练数据集成为一种选择。
新的神经网络 Sill-Net[28]
针对图片可以分离光照特征,并通过在特征空间使用该网络分离光线的影响来增强训练样本。
[28] ZHANG H, CAO Z, YAN Z, et al. Sill-net: Feature augmentation with separated illuminationrepresentation[J]. arXiv preprint arXiv:2102.03539, 2021.
文献[29]提出了一个统一的元数据增强框架并在此框架下解释了现有的增强策略。
[29] RAJENDRAN J, IRPAN A, JANG E. Meta-learning requires meta-augmentation[J]. Advances in Neural Information Processing Systems, 2020, 33: 5705-5715.
数据增强策略 MetaAugment[30]
通过将样本数据增强策略作为样本重加权问题来学习一个具有样本感知能力的数据增强策略,捕捉样本间的不同性来评估不同样本增强策略的有效性
[30] ZHOU F, LI J, XIE C, et al. Metaaugment: Sample-aware data augmentation policy learning[J]. arXiv preprint arXiv:2012.12076, 2020.
MetaGAN【31】
为少镜头学习提出了一个简单通用的框架,其引入了一个以任务为条件的对抗生成器,其目标是生成与从特定任务中采集的真实数据无法区分的样本
[31] ZHANG R, CHE T, Ghahramani Z, et al. Metagan: An adversarial approach to few-shot learning[J]. Advances in neural information processing systems, 2018, 31.
数据增强元学习 MEDA【32】
结合小样本文本分类问题,该框架引入一个球生成器用于生成新的数据样本。首先通过生成器计算支持集样本的最小球形状封闭边界,然后在边界内合成新的数据样本。
[32] SUN P, OUYANG Y, ZHANG W, et al. MEDA: Meta-Learning with Data Augmentation for Few-Shot Text Classification[J].
联邦元学习
联邦元学习定义
在联邦学习中,通过元学习算法,为每个客户端训练个性化的模型,降低模型在不同客户端上表现的差异,提高模型公平性,就称为联邦元学习算法
联邦元学习分类
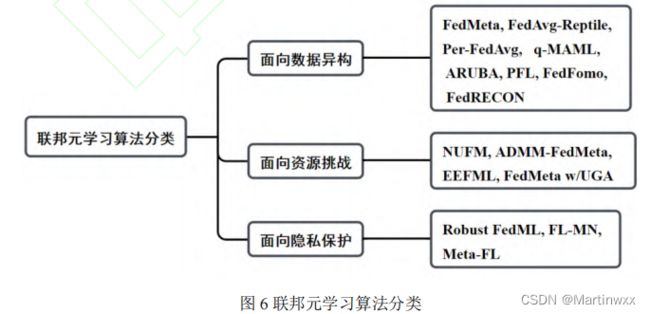
(1)如何通过联邦元学习为不同用户提供个性化模型,解决联邦学习中数据异构问题
(2)如何利用联邦元学习进行合理资源分配,提高联邦学习的通信效率,加快收敛速度
(3)如何利用元学习算法增强联邦学习面对恶意攻击的鲁棒性,保护数据隐私
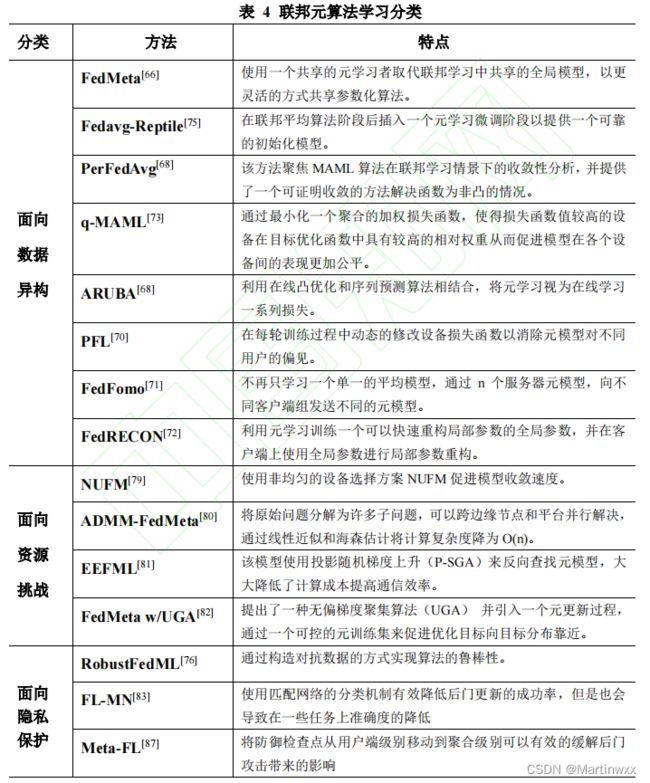
一、面向 数据异构 的联邦元学习
1. FedMeta 算法[66]
将客户端视为任务,目标为训练一个初始化良好的模型而不是全局最优。
使用一个共享元学习者(meta-learner)取代联邦学习中共享的全局模型,参数初始化和更新都在中心服务器。
每个节点设置一个支持集,参数集,每个节点支持集上用meta-learner知道训练模型,查询集上验证。
[66] CHEN F, LUO M, DONG Z, et al. Federated meta-learning with fast convergence and efficient communication[J]. arXiv preprint arXiv:1802.07876, 2018.
2. Fedavg-Reptile[75]
将元学习作为一个微调阶段放置在联邦学习之后
其中 Reptile[17]是模型不可知算法的一种变体,其简化了 MAML的二阶求导过程。
①选择动量随机梯度下降算法(Momentum SGD)作为服务器优化器,FedAvg 可以提供个性化模型;
②通过减少本地学习率和训练轮次可以加快收敛;
③在联邦平均算法阶段后插入一个元学习微调阶段,提供一个可靠的初始化模型
该方案分为训练和微调两个阶段:
联邦平均算法:服务器优化器
切换到Reptile(K)[17]算法:作为服务器优化器微调初始模型得到个性化初始模型,并保持稳定
最后:使用相同的客户端优化器进行个性化优化。
[75] Y. JIANG, J. KONEČNÝ, K. RUSH, AND S. KANNAN, "Improving federated learning personalization via model agnostic meta learning," arXiv preprint arXiv:1909.12488, 2019.
[17] NICHOL A, ACHIAM J, SCHULMAN J. On first-order meta-learning algorithms[J]. arXiv preprint arXiv:1803.02999, 2018.
3. Per-FedAvg[68]
每轮训练随机选择一部分用户,发送当前模型,用户根据自身的损失函数通过随机梯度下降更新参数,并返回服务器。服务器计算均值并更新模型。
该模型是模型不可知元学习(MAML)的一种。
[68] FALLAH A, MOKHTARI A, OZDAGLAR A. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach[J]. Advances in Neural Information Processing Systems, 2020, 33: 3557-3568.
4. q-MAML[73]
通过衡量准确度差异(accuracy parity)来表示公平性。
文献[73]引入good-intent fairness, 确保模型对任何设备的适应都不会以牺牲其他设备为代价。仅优化性能最差组,仅在小型网络测试。
文献[74]提出了 q-FFL(q-Fair Federated Learning),最小化一个聚合的加权损失函数,使得损失函数值较高的设备在目标优化函数中具有较高的相对权重从而促进模型在各个设备间的表现更加公平。
将 q-FFL 与流行的元学习算法 MAML 相结合,在不同任务上表现更加公平的新算法 q-MAML。使用q-FFL中的目标函数和权重更新全局参数。
[73] ZAFAR M B, VALERA I, GOMEZ RODRIGUEZ M, et al. Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment[C]//Proceedings of the 26th international conference on world wide web. 2017: 1171-1180.
[74] LI T, SANJABI M, BEIRAMI A, et al. Fair resource allocation in federated learning[J]. arXiv preprint arXiv:1905.10497, 2019.
5. ARUBA[68]
文献[68]利用在线凸优化(Online Convex Optimization)和序列预测算法相结合,提出新的理论框架 ARUBA,该算法将元学习视为在线学习一系列损失。
学习一个在线镜像下降的 Mahalanobis-Norm 正则化项来确定参数空间中那些方向需要更新。其提供了一个动态调整学习率方法。是一种简单的无需步长调整的方法
[68] FALLAH A, MOKHTARI A, OZDAGLAR A. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach[J]. Advances in Neural Information Processing Systems, 2020, 33: 3557-3568.
6. PFL[70]
文献[70]中提出利用梯度矫正方法为每个边缘设备定制个性化模型。
将每个客户端与不同的任务关联,在不同的任务上学习一个元模型,每轮训练中动态修改设备损失函数,消除元模型对不同用户的偏见。
[70] ZHANG M, SAPRA K, FIDLER S, et al. Personalized federated learning with first order model optimization[J]. arXiv preprint arXiv:2012.08565, 2020.
7. FedFomo[71]
根据客户端间的模型联系,计算客户端之间的影响,得到最佳模型组合,通过n个服务器元模型,向客户端发送不同元模型。
[71] ACAR D A E, ZHAO Y, ZHU R, et al. Debiasing Model Updates for Improving Personalized Federated Training[C]//International Conference on Machine Learning. PMLR, 2021: 21-31.
8. FedRECON[72]
模型无关的局部联邦重构算法(FedRECON)
模型参数划分为全局参数和本地参数。本地参数不离开客户端,利用元学习训练一个可以快速重构局部参数的全局参数,在客户端用全局参数进行局部参数重构。
(疑问:此情况本地参数干啥用?)
[72] SINGHAL K, SIDAHMED H, GARRETT Z, et al. Federated reconstruction: Partially local federated learning[J]. Advances in Neural Information Processing Systems, 2021, 34
二、面向 资源挑战 的联邦元学习
1. NUFM 算法
文献[79]提出了一种非均匀的联邦元学习设备选择方
案 NUFM 来促进模型收敛速度,并提出了一种资源分配策略 URAL
[79] YUE S, REN J, XIN J, et al. Efficient Federated Meta-Learning over Multi-Access Wireless Networks[J]. arXiv preprint arXiv:2108.06453, 2021.
2. ADMM-FedMeta
文献[80]将先前任务的有价值的知识被提取为正则化项,
其中 ADMM 提供了一种自然的机制,将原始问题分解为许多子问题,可以跨边缘节点和平台并行解决
采用了一种非精确化 ADMM 方法的变体,通过线性近似和海森估计将计算复杂度降为 O(n)
[80] YUE S, REN J, XIN J, et al. Efficient Federated Meta-Learning over Multi-Access Wireless Networks[J]. IEEE Journal on Selected Areas in Communications, 2022.
3. EEFML
MAML有良好收敛性和快速适应新任务的性能,当需要计算二阶导数进行反向传播,计算成本高,有梯度消失的可能。
一阶近视优化算法(FOMAML, Reptile)无需计算二阶导数,但忽略元模型对任务模型的影响。
[81]中提出EEFML,使用***投影随机梯度上升(P-SGA)***来反向查找元模型,元模型双层循环中,内部更新可以由一个简单封闭的表达式解决,SGD步骤和投影步骤,使内部循环不需要计算二阶导数(海森矩阵)
[81] ELGABLI A, ISSAID C B, BEDI A S, et al. Energy-Efficient and Federated Meta-Learning via Projected Stochastic Gradient Ascent[J]. arXiv preprint arXiv:2105.14772, 2021.
4. FedMeta w/UGA
传统FL两个偏差:客户端多步骤更新,导致模型聚合有梯度偏差;随机选择客户端,导致每轮优化与真正目标不一致。
在[82]提出了一种无偏梯度聚集算法(UGA),用保持追踪梯度下降和梯度评估策略来减少本地更新造成的梯度偏差。并引入一个元更新过程,通过一个可控的元训练集来促进优化目标向目标分布靠近。
[82] YAO X, HUANG T, ZHANG R X, et al. Federated learning with unbiased gradient aggregation and controllable meta updating[J]. arXiv preprint arXiv:1910.08234, 2019.
三、面向 隐私保护 的联邦元学习
1. Robust FedML 算法[76]
针对:有限计算资源+有限本地数据+对抗性攻击
一个建立在分布式鲁棒优化上的联邦元学习框架 Robust FedML
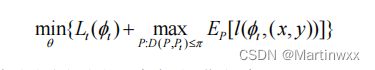
D是概率分布空间上的距离度量,采用 Wasserstein 距离。
对抗式数据生成过程:在迭代过程中,每个边缘节点使用梯度上升构造对抗数据样本,并加入对抗数据集中。每个节点先使用训练数据集更新θ,后使用测试数据集和敌对数据集本地更新θ,本地更新完成后传递参数个中心服务器。
通过构造对抗数据的方式实现算法的鲁棒性。
[76] LIN S, YANG G, ZHANG J. A collaborative learning framework via federated meta-learning[C]//2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2020: 289-299.
2. Federated Learning with Matching Network(FL-MN)[83]
针对:后门攻击,客户端发送恶意数据生成的模型参数。
使用匹配网络的分类机制,根据输入样本特征与支持集中样本特征的距离进行分类。
匹配网络:基于度量的元学习方法,需要进一步提升准确度
[83] CHEN C L, GOLUBCHIK L, PAOLIERI M. Backdoor attacks on federated meta-learning[J]. arXiv preprint arXiv:2006.07026, 2020
3. Meta-FL[87]
针对:后门攻击
旨在不检查各客户端的情况下防御后门攻击。
思想:将防御检查点从用户端级别移动到聚合级别
将不同客户端进行分组,将传统FL聚合从一个阶段全局聚合变为两个阶段的多层次聚合。客户端分组,组内安全聚合:SecAgg[88],每组获得一个组内全局模型,SecAgg确保服务器聚合客户端提交的更新而不知具体值,通过组间聚合全局模型进行安全检查。
虽然有泄露组内全局模型信息风险,但信息和单个用户无关。
[87] ARAMOON O, CHEN P Y, QU G, et al. Meta Federated Learning[J]. arXiv preprint arXiv:2102.05561, 2021.
[88] BONAWITZ K, IVANOV V, KREUTER B, et al. Practical secure aggregation for privacy-preserving machine learning[C]//proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017: 1175-1191.
在隐私保护方面,利用基于度量的元学习算法增强元学习面对恶意攻击时的鲁棒性[83]是一个引人注目的方向,但是向服务器发送度量模型参数,可能会产生用户敏感信息的泄露。
[83] CHEN C L, GOLUBCHIK L, PAOLIERI M. Backdoor attacks on federated meta-learning[J]. arXiv preprint arXiv:2006.07026, 2020.