大数据Kafka入门
follow:b站尚硅谷kafka教程&以及相关文档、博客
Kafka是一个分布式基于发布/订阅模式的消息队列,Message Queue,用于大数据实时处理领域。Spark和Kafka是高度相关的。
一、Kafka是采用消息队列的异步处理。消息队列优点:
1.解耦,只需有确保接口约束,可以单独的扩展两边的处理过程
2.可恢复性,系统的某一部分损坏不会影响整个系统
3.缓冲,解决生产大于消费的的速度,(解决速度不一致问题)
4.灵活性,峰值处理能力,可以动态的调整处理的硬件支持,减少浪费。
二、消息队列的两种模式
1.点对点模式
消费者主动从生产者拉去数据。
2.发布/订阅模式 同一个消息可以被不同的消费者不同享有。有两种模式:消费者拉取,生产者推送
生产者推送:生产者发送消息到队列Topic(公众号),topic推送给consumer。每个consumer的处理能力不一样,但是生产者接收推送速度不一致、但是topic推送速度是根据生产者决定的(一般快)。消费者处理能力不足(崩了)、资源浪费(消费者快)
消费者拉取:Kafka是消费者拉取数据模式:消费者一直访问topic是否有新消息(缺点:资源浪费),生产者不管这个,有生产就放到topic里面。
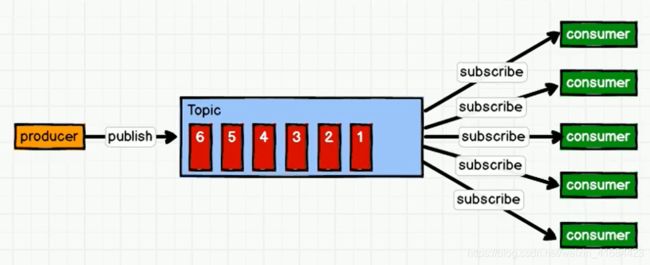
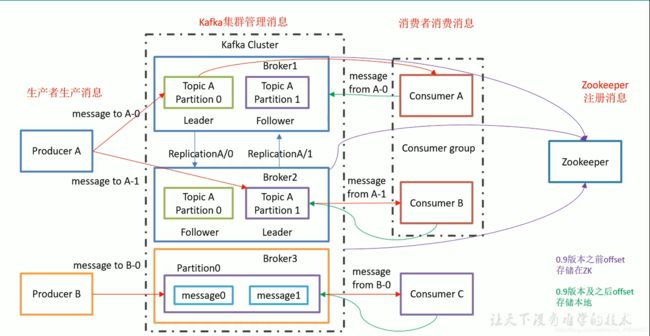
三、Kafka架构
生产者生产消息->Kafka集群管理消息->消费者消费消息
前提:启动kafka集群。
Broker是服务器,如图kafka有三台服务器。Broker中有不同的主题Topic,对消息进行分类。主题中带有分区partition用于分区实现提高并发度提高负载均衡(吞吐量)。leader和follower,生产者消费者只连接到leader,follower仅仅作为备份。
消费者有消费者组的概念。一个分区的数据同时只能被一个消费者组里面的某一个消费者消费。不同组内的消费者可以同时消费。消费者组内消费者数如果大于分区数就没有意义了。
kafka集群和消费者(存储消费的位置信息)都会在Zookeeper中存储一些信息。注意:不同的版本在ZK里面存储的信息不一样。0.9之前消费者offerset存储在ZK,0.9以及以后存储在Kafka本地(磁盘)。防止消费者频繁访问ZK。
四、kafka安装&命令行操作
官网:http://kafka.apache.org/
致谢:https://blog.csdn.net/hxtog/article/details/113706182
1.wget下载:
wget https://downloads.apache.org/kafka/2.7.0/kafka_2.12-2.7.0.tgzLinux chgrp 命令:Linux chgrp(英文全拼:change group)命令用于变更文件或目录的所属群组
chgrp [-cfhRv][--help][--version][所属群组][文件或目录...] 或 chgrp [-cfhRv][--help][--reference=<参考文件或目录>][--version][文件或目录...]Linux chown 命令Linux chown(英文全拼:change owner)命令用于设置文件所有者和文件关联组的命令。
chown [-cfhvR] [--help] [--version] user[:group] file...2.启动、关闭、测试、删除top命令
启动zookeeper
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
关闭zookeeper
./bin/zookeeper-server-stop.sh -daemon ./config/zookeeper.properties
启动kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
./bin/kafka-server-start.sh ./config/server.properties
关闭kafka
./bin/kafka-server-stop.sh ./config/server.properties
测试创建topic
./bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic test
查看topic
./bin/kafka-topics.sh --list --zookeeper master:2181
生产者发送
./bin/kafka-console-producer.sh --broker-list master:9092 --topic test
消费者接收
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning
describe topic
./bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test
删除topic
./bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test
第一次启动卡夫卡需要在Kafka目录下mkdir logs文件夹
致谢:https://blog.csdn.net/hxtog/article/details/113706182
分区数可以大于机器数但是不能副本数不能大于机器数!
Kafka数据在/tmp/kafa*里面,日志在Kafka文件夹里面的logs里面
测试卡夫卡的时候报的Error:
Error while executing topic command : Replication factor: 1 larger than available brokers: 0.
[2021-04-08 23:03:26,383] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 1 larger than available brokers: 0.
(kafka.admin.TopicCommand$)
解决:没有启动Kafka,有可能是这个文件夹设置的所属用户或者组设置的不对。
五、配置文件修改
server.properties
broker.id:分发的时候需要改成每台机器唯一的数字
log.dirs :kafka暂存数据的目录
log.retention.hours:数据存储的时间
zookeeper.connect:修改成hadoop的端口号!
群起脚本:todo

chmod 777 x.sh