MySQL 窗口函数
文章目录
- 1 MySQL 窗口函数有哪些?
- 2 SQL表和数据
- 3 LAG() 函数
-
- 3.1 LAG()函数的参数
- 3.2 代码示例
- 4 LEAD() 函数
-
- 4.1 LEAD()函数的参数
- 4.2 代码示例
1 MySQL 窗口函数有哪些?
- LAG() 函数
- LEAD() 函数
2 SQL表和数据
t_log 表结构
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| num | varchar |
+-------------+---------+
测试数据
+----+-----+
| id | num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| 5 | 2 |
| 6 | 1 |
| 7 | 2 |
| 8 | 2 |
+----+-----+
3 LAG() 函数
LAG()函数从同一结果集中的当前行访问上一行的数据。 允许您回顾多行并从当前行访问行的数据
3.1 LAG()函数的参数
LAG(<expression>[,offset[, default_value]]) OVER (
PARTITION BY expr,...
ORDER BY expr [ASC|DESC],...
)
expression
LAG()函数返回expression当前行之前的行的值,其值为offset 其分区或结果集中的行数
offset
offset是从当前行返回的行数,以获取值。offset必须是零或文字正整数。如果offset为零,则LAG()函数计算expression当前行的值。如果未指定offset,则LAG()默认情况下函数使用一个
default_value
如果没有前一行,则LAG()函数返回default_value。例如,如果offset为2,则第一行的返回值为default_value。如果省略default_value,则默认LAG()返回函数 NULL
PARTITION BY 子句
PARTITION BY子句将结果集中的行划分LAG()为应用函数的分区。如果省略PARTITION BY子句,LAG()函数会将整个结果集视为单个分区。
ORDER BY 子句
ORDER BY子句指定在LAG()应用函数之前每个分区中的行的顺序。 LAG()函数可用于计算当前行和上一行之间的差异
3.2 代码示例
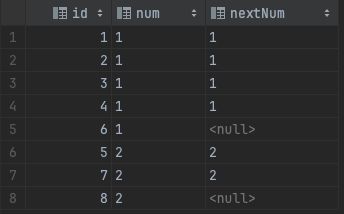
- 通过 id 进行排序, 查询当前行的 num 和 前一行的 num
select
id,
lag(num, 1) over (order by id) as preNum,
num
from t_log
查询结果
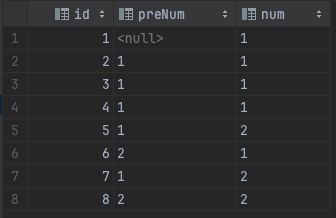
- 将 num 进行分组(
partition by num), 再通过 id 进行排序, 查询当前行的 num 和 前一行的 num
select
id,
lag(num, 1) over (partition by num order by id) as preNum,
num
from t_log
查询结果, id = 6 的数据被分到 num = 1 的数据组中, id = 5 的前一行数据 preNum = null
4 LEAD() 函数
LEAD()函数对于计算同一结果集中当前行和后续行之间的差异非常有用
4.1 LEAD()函数的参数
LEAD(<expression>[,offset[, default_value]]) OVER (
PARTITION BY (expr)
ORDER BY (expr)
)
expression
LEAD()函数返回的值expression从offset-th有序分区排
offset
offset是从当前行向前行的行数,以获取值。 offset必须是一个非负整数。如果offset为零,则LEAD()函数计算expression当前行的值。 如果省略 offset,则LEAD()函数默认使用一个
default_value
如果没有后续行,则LEAD()函数返回default_value。例如,如果offset是1,则最后一行的返回值为default_value。 如果您未指定default_value,则函数返回 NULL
PARTITION BY子句
PARTITION BY子句将结果集中的行划分LEAD()为应用函数的分区。 如果PARTITION BY未指定子句,则结果集中的所有行都将被视为单个分区
ORDER BY子句
ORDER BY子句确定LEAD()应用函数之前分区中行的顺序
4.2 代码示例
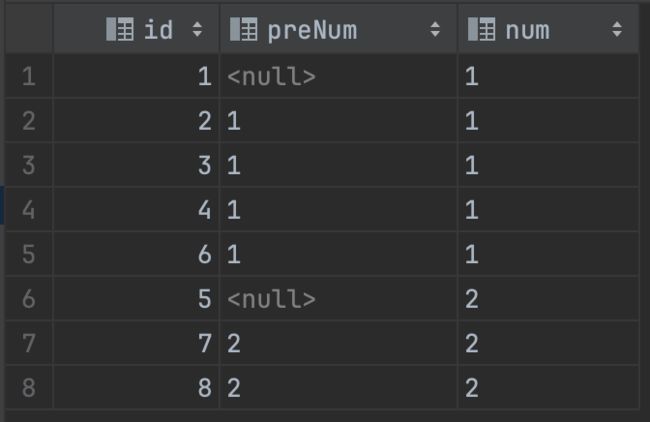
通过 id 进行排序, 查询当前行的 num 和 后一行的 num
select
id,
num,
lead(num, 1) over (order by id) as nextNum
from t_log
查询结果
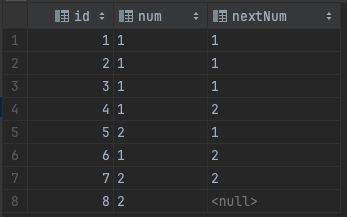
将 num 进行分组(partition by num), 再通过 id 进行排序, 查询当前行的 num 和 后一行的 num
select
lag(num, 1) over (partition by num order by id) as preNum,
num
from t_log
查询结果, id = 6 的数据被分到 num = 1 的数据组中, 后一行数据 nextNum = null