【C++】详解priority_queue(优先级队列)与函数对象
目录
一、priority_queue 的介绍和使用
1.1priority_queue 的介绍
2.2priority_queue 的使用
二、仿函数
2.1什么是仿函数
2.2仿函数的作用
三、函数对象的特点(知识点多)
3.1分析特点5(比较普通函数与函数对象)
3.1.1利用普通函数传递参数
拓展之:深度剖析函数利用模板的本质
3.1.2利用函数对象传递参数
3.1.3函数对象作为for_each的参数(知识点较多)
2.第三个参数传递函数:(计算从0到100)
3.第三个参数传递函数对象:(计算从0到100)
4.难点:关于第三个参数是传值的易错点
5.拓展:如果我重写for_each,加上引用,会不会得到我想要的效果?
3.2分析特点6(一共俩句话)
3.2.1分析保持函数的调用状态(本质是因为成员变量不会销毁)
3.2.2参数个数可变是什么意思?代码分析过程中居然用到了匿名对象!
1.分析函数对象的用法及匿名对象
2.探究匿名对象的生命周期
3.回忆匿名对象拆分开怎么写
4.讨论多参数问题(多参数不是重载函数多,而是类中多变量)
四、函数对象的分类
4.1一元函数
4.2二元函数
4.3一元判定函数
4.4二元判定函数
五、总结知识点(未完待续.....)
一、priority_queue 的介绍和使用
1.1priority_queue 的介绍
priority_queue (优先级队列)是一种容器适配器,它与 queue 共用一个头文件,其底层结构是一个堆,并且默认情况下是一个大根堆,所以它的第一个元素总是它所包含的元素中最大的,并且为了不破坏堆结构,它也不支持迭代器。
同时,由于堆需要进行下标计算,所以 priority_queue 使用 vector 作为它的默认适配容器 (支持随机访问):

但是,priority_queue 比 queue 和 stack 多了一个模板参数 – 仿函数;关于仿函数的具体细节,我们将在后文介绍
class Compare = less
2.2priority_queue 的使用
优先级队列默认使用 vector 作为其底层存储数据的容器,在 vector 上又使用了堆算法将 vector 中元素构造成堆的结构,因此 priority_queue 就是堆,所有需要用到堆的位置,都可以考虑使用 priority_queue。(注意:默认情况下priority_queue是大堆)
priority_queue 的使用文档
| 函数声明 | 接口说明 |
| priority_queue() | 构造一个空的优先级队列 |
| priority_queue(first, last) | 迭代器区间构造优先级队列 |
| empty( ) | 检测优先级队列是否为空 |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push(x) | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
| size() | 返回优先级队列中的元素个数 |
注意事项:

priority_queue 默认使用的仿函数是 less,所以默认建成的堆是大堆;如果我们想要建小堆,则需要指定仿函数为 greater,该仿函数包含在头文件 functional 中,并且由于仿函数是第三个缺省模板参数,所以如果要传递它必须先传递第二个模板参数即适配容器


void test_priority_queue() {
priority_queue pq; //默认建大堆,仿函数为less
pq.push(5);
pq.push(2);
pq.push(4);
pq.push(1);
pq.push(3);
while (!pq.empty()) {
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
priority_queue, greater> pq1; //建小堆,仿函数为greater,需要显式指定
pq1.push(5);
pq1.push(2);
pq1.push(4);
pq1.push(1);
pq1.push(3);
while (!pq1.empty()) {
cout << pq1.top() << " ";
pq1.pop();
}
cout << endl;
} 
二、仿函数
2.1什么是仿函数
仿函数也叫函数对象,仿函数是一个类,但是该类必须重载函数调用运算符 ( ),即 operator()(参数);由于这样的类的对象可以像函数一样去使用,所以我们将其称为仿函数/函数对象,如下:
namespace lzy {
class less {
public:
bool operator()(const int& x, const int& y) const
{
cout << "less类" << endl;
return x < y;
}
};
class greater
{
public:
bool operator()(const int& x, const int& y)
{
cout << "greater类" << endl;
return x > y;
}
};
}
void functor_test() {
lzy::less lessFunc;
cout << lessFunc(1, 2) << endl; //lessFunc.operator(1,2)
lzy::greater greaterFunc;
cout << greaterFunc(1, 2) << endl; //greaterFunc.operator(1,2)
}
可以看到,因为 less 类和 greater 类重载了 () 操作符,所以类对象可以像函数一样去使用,因此它们被称为仿函数。
2.2仿函数的作用
我们以最简单的冒泡排序为例来说明仿函数的作用,我们知道,排序分为排升序和排降序,那么在没有仿函数的时候,即C语言阶段,我们是如何来解决这个问题的呢 – 答案是函数指针;
将排序函数的最后一个参数定义为函数指针,然后通过用户给排序函数传递不同的比较函数来决定升序还是降序:

但是!!在 C++ 中,我们不再使用函数指针解决升序降序的问题,转而使用更加方便的仿函数
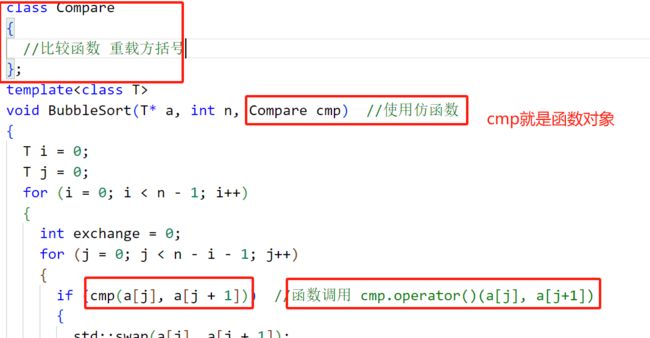
三、函数对象的特点(知识点多)
- 函数对象是一个类的对象,而不是函数
- 函数对象是重载了operator()的类对象
- 函数对象的调用格式类似于函数调用,所以也称仿函数
- 函数对象也具有参数和返回值
- 函数对象作为一个对象,可以作为参数传递给函数或其它类函数对象独有的特点
- 保持函数的调用状态,参数个数可变(因为函数在栈中,之后会销毁)
3.1分析特点5(比较普通函数与函数对象)
3.1.1利用普通函数传递参数
代码作用:给定成绩数组,找出大于或者小于基准值的成绩分数
#include
using namespace std;
int baseScore = 0;
int arrSize = 5;
typedef bool (*pf) (int,int); //函数指针,是为了代码将来的可维护性 不需要修改count函数内部
int count(int grade[],pf p)//传递int int形的接口
{
int sum=0;
for(int i=0;i=base;// 也可以返回整数值,设置各种比较情况
}
bool Cmp_small(int base,int num)// 修改比较函数
{
return num<=base;// 也可以返回整数值,设置各种比较情况
}
int main()
{
int grade[arrSize]={1,2,3,4,5};
cout << count(grade,Cmp_big) << endl;
return 0;
}
这里利用到了函数指针的知识点,但在这里我不想过多探讨,所以看注释就好啦

这里通过传递不同的函数比较方法,可以有不同的效果,p是一个函数指针,而函数名正好也是函数指针,所以这里重点正是cmp_big给了p,使得p变成了大于基准值比较函数(sort的第三个参数,实则正可以理解为函数指针(C语言中),在C++的话一定就是模板了)
拓展之:深度剖析函数利用模板的本质
但是在看了sort函数的底层时,我发现大部分还是用模板(谁还用函数指针啊真是)(但是C没模板,那么C一定就得用函数指针当sort函数的第三个参数了)

这样用着蛮不错的哦,但是如果我们的函数要实例化的话,你就会惊奇的发现:


这个东西长得不就是我们的函数指针吗?这也充分验证了我们函数名就是函数指针的观点!
模板的好处正是用起来爽,但其实并没有提高效率
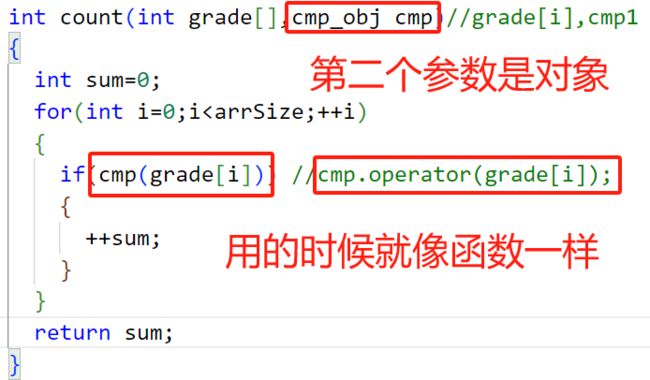
3.1.2利用函数对象传递参数
#include
using namespace std;
int baseScore = 0;
int arrSize = 5;
//方法二 利用函数对象
class cmp_obj
{
public:
int base;
bool operator()(int score) const
{
return (score>=base);
}
};
int count(int grade[],cmp_obj cmp)//grade[i],cmp1 cmp1(grade[i]) cmp1.oprara(grade[i]);
{
int sum=0;
for(int i=0;i
分析代码:

这里没有比较函数,有的只是对象和重载operator( ),所以要修改比较规则,那么重载里面修改就好了
这正是函数对象作为一个对象,可以作为参数传递给函数或其它类函数对象独有的特点

利用函数的话,修改基准值得用全局变量,但是利用函数对象的话就不需要,这都是优势!
3.1.3函数对象作为for_each的参数(知识点较多)
1.for_each函数:
template
Function for_each(InputIterator first, InputIterator last, Function fn)
//第三个参数是函数或者是函数对象
{
while (first!=last) {
fn (*first);//取值 传递到fn函数/函数对象
++first;
}
return fn; //如果是函数对象 返回是有意义的 如果是函数 反而是没有意义的
}

这里重点知识点就是:for_each的第三个参数可以传递函数对象/函数
传递函数时:往往不需要接收返回值,因为接收函数没有意义
传递函数对象:一定得接收返回值,因为不接受的话因为是传值,就会丢失想要的值
2.第三个参数传递函数:(计算从0到100)
#include
#include
#include
using namespace std;
int sum=0;
void f(int x)
{
sum+=x;//这里是f函数
}
int main()
{
vector v;
for(int i=0;i<100;i++)
{
v.push_back(i);
}
//不需要接收返回值 接收函数没有意义
for_each(v.begin(),v.end(),f);//在迭代器的范围内,每次取一个x元素,计算f(x)
// for(int i=0;i

如果我们将for_each拆分开来:
for(int i=0;i

很明显,用for_each是更爽的! 只可惜有一定的使用难度成本,让我们继续往下看!
3.第三个参数传递函数对象:(计算从0到100)
//print为仿函数
class print
{
int count;
public:
int get_count()
{
return count;
}
print() {count = 0;} //必须写默认构造 要不然下面匿名对象会出问题
void operator()(int x)
{
cout << x << " ";
++count;
}
};
在这里仿函数类中,我们用get_count函数接收私有变量,并且写好了默认构造函数,接着重载了operator( ) ,因为这个我们是用来输出的,所以返回值写成void就好了
int main()
{
list l;//初始化
for (size_t i= 1;i<10;++i)
{
l.push_back(i);
}
//遍历ilist元素并打印
print p = for_each(l.begin(),l.end(),print());//打印l元素个数 这里的第三个参数好好分析一下
cout <<"count="<
这里我们先对list进行了初始化,接着难点来了:

利用构造函数创建匿名对象与对象调用重载()函数是很容易混淆的!!!
接着由于返回值是函数对象,所以可以利用p来验证最后的结果~
4.难点:关于第三个参数是传值的易错点

但是如果我不接受返回值,直接输出p1.get_count( ) ,你会不会汗流浃背呢?

这就说明,我们这里进去的值出来后就被销毁了,为了避免销毁,得加上返回值哦!
5.拓展:如果我重写for_each,加上引用,会不会得到我想要的效果?
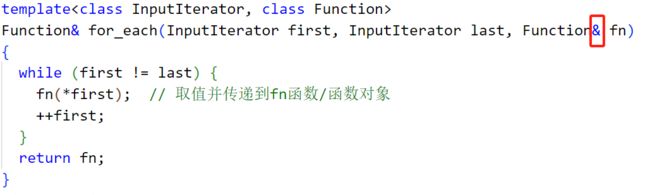
Function& for_each(InputIterator first, InputIterator last, Function& fn)
{
while (first != last) {
fn(*first); // 取值并传递到fn函数/函数对象
++first;
}
return fn;
}
注意:类对象引用初始化的时候,一定得加上引用的是谁,类类型也是可以用引用的

3.2分析特点6(一共俩句话)
3.2.1分析保持函数的调用状态(本质是因为成员变量不会销毁)
保留函数的调用状态是什么意思呢? 我们看一段代码!
int sum = 0;
void f(int x)
{
sum += x;
}
class add
{
int comm;
public:
int Getsum() { return comm; }
add() { comm = 0 ;}
void operator()(int x)
{
comm += x;
}
};
int main()
{
int i = 0;
for ( i = 1; i <= 100; i++)
f(i);
cout << sum << endl; //5050
add fobi;
for (i = 1;i <= 100;i++)
fobi(i); //调用格式类似于函数
cout << fobi.Getsum ()<< endl; //5050,保留函数状态
return 0;
}

这段代码的知识点很多咧~ 让小羊博主一起带你们分析一波!
直观上来说,一个是普通函数,一个是重载(),那么保留函数的调用状态是什么意思?
1.本质上是因为类中的成员变量不会被销毁,但是函数中的sum与x出了作用域就会清空
2.在这俩个函数都是void的情况,为了输出最终结果,俩方势力也是煞费脑筋:
函数势力是利用了全局变量 int sum=0; 才使得得到想要结果(可惜这样是不安全的)

而重载势力是利用了共有函数接口取回最终的结果值


而且看到这个写法会不会觉得很奇怪咧,有俩个括号,意思是第一个是缺省参数吗?
不不不不,这里是重载()函数,所以长得有些奇怪,只有第二个int x才是参数~
3.2.2参数个数可变是什么意思?代码分析过程中居然用到了匿名对象!
1.分析函数对象的用法及匿名对象
#include
using namespace std;
class add_two
{
int comm;
//int hehe;
public:
int Getsum() { return comm; }
add_two()
{ comm = 0;}
add_two(int v) { comm = v;}
int operator()(int x) //不是说这个是特殊语法 是因为operator*(int x) 等等重载函数都是这么写的
{
return (comm + x );
}
};
void test1()
{
int ret = add_two()(2); //利用匿名对象
cout << ret << endl;// ret=2;
ret = add_two(5)(2);//ret=7;
cout << ret << endl;
ret = add_two(6)(2);//ret=8;
cout << ret << endl;
}
int main()
{
test1();
return 0;
}
代码分析:
还是老样子,在类中依然重载了operator( ) , 所以让我们看看主函数是怎么调用的吧
类中有俩个构造函数,一个是有参,一个是无参(并且给了默认值是0)
(吐槽:直接给缺省不就行了,还写俩个构造函数)
add_two():虽然是俩个括号 但是第一个是构造函数 然后用了匿名对象的知识点!!!!这部分创建了一个 add_two 的匿名对象(生命周期只有一行),使用了默认构造函数,该构造函数将 comm 成员初始化为 0。这个对象实际上是一个函数对象(因为我们重载了operator(),所以对象后面跟上括号,自然而然就会去调用重载函数去了),因为我们可以调用它。
接下来,像调用函数一样传递了一个整数参数 2 给这个匿名对象。由于 add_two 类重载了 operator(),因此可以将它视为函数调用。
int ret = ...:最后,将这个函数对象调用的结果(在这种情况下是 0 + 2 = 2)赋值给整数变量 ret。
所以,int ret = add_two()(2); 的含义是创建一个 add_two 的匿名对象,然后将其当做函数调用,将参数 2 传递给它,最后将结果 2 赋给 ret。这展示了函数对象的使用,允许像调用函数一样使用类的实例。

但如果想充分发挥函数对象的作用的话,其实我们可以直接输出:

2.探究匿名对象的生命周期
//讲解匿名对象
class MyClass {
public:
MyClass() {
std::cout << "MyClass constructor" << std::endl;
}
~MyClass() {
std::cout << "MyClass destructor" << std::endl;
}
};
int main() {
cout << "flag1" << endl;
MyClass(); // 创建匿名对象 匿名对象的生命周期只有这一行
cout << "flag2" << endl;
return 0;
}
匿名对象的生命周期只有创建的那一行,走了之后就会被销毁掉!
3.回忆匿名对象拆分开怎么写
好了,我们了解完匿名对象的知识点后,让我们来回忆一下上面那个例子拆分开来是什么效果
//int tmp=add_two(100);
add_two addFunction(100); // 创建一个 add_two 对象
ret = addFunction(2); // 调用对象的 operator(),传递参数 2
cout << ret << endl;
4.讨论多参数问题(多参数不是重载函数多,而是类中多变量)

#include
// 基本情况:当没有参数时,返回0
int sum() {
return 0;
}
// 使用可变参数模板来计算总和
template
T sum(T first, Args... rest) {
return first + sum(rest...);
}
int main() {
int result = sum(1, 2, 3, 4, 5);
std::cout << "Sum: " << result << std::endl;
double result2 = sum(1.1, 2.2, 3.3, 4.4);
std::cout << "Sum: " << result2 << std::endl;
return 0;
}

四、函数对象的分类
函数对象是重载了operator() 的类的一个实例,operator()是函数调用运算符。
标准C++库根据 operator() 参数个数为0个,1个,2个加以划分的。要有以下3种类型:
- 发生器:一种没有参数且返回一个任意类型值的函数对象,例如随机数发生器。
- 一元函数:一种只有一个任意类型的参数,且返回-个可能不同类型值的函数对象。
- 二元函数:一种有两个任意类型的参数,且返回一个任意类型值的函数对象。
- 一元判定函数: 返回bool型值的一元函数
- 二元判定函数: 返回bool型值的二元函数
4.1一元函数
templat
class unary_function
{
typedef _A argument_type;
typedef _R result_type;
};
有俩个模板参数 第一个是输出参数 参数类型 第二个模板参数定义为结果类型 返回类型 动态特性非常强
p62 即使类中从来没有用过 但是还是可以定义用 (意思是,这个基类是在上面的类继承下来的,所以说它的arg也可以当成输出参数,即使我们的基类没有写)
P62页代码:
#include
#include
#include
#include
using namespace std;
template
struct unary {
typedef _A argument_type;
typedef _R result_type;
};
template//邸老师说 希望这里删去
class CSum : public unary<_inPara, _outPara> {
public:
_outPara sum;//这里可以使用 result_type;
CSum() { sum = 0; }
void operator()(_inPara n) { sum += n; } //这里同理也可以用 argument_type;
_outPara GetSum() { return sum; }
};
template
class CPrint
{
public://这个记得加
CPrint(){};
void operator()(_input var)
{
cout << var << " ";
}
};
int main()
{
//传int
vector v;
for (int i = 1;i <= 5;i++) { v.push_back(i); }
//遍历int
vector::iterator it=v.begin();
for(;it!=v.end();++it)
{
cout << *it << " ";//这样遍历 可以防止出界 比那个[]遍历更安全
}cout << endl;
CSum sobj = for_each(v.begin(), v.end(), CSum());//类的显示实例化+匿名对象
cout << "sum(int)=" << sobj.GetSum() << endl;
//传float
vector v2;
float f = 1.3f;
for (int i = 1;i <= 5;i++) {
v2.push_back(f);
f += 1.0f;
}
//遍历float
vector::iterator it1=v2.begin();
for(;it1!=v2.end();++it1)
{
cout << *it1 << " ";//这样遍历 可以防止出界 比那个[]遍历更安全
}cout << endl;
CSum sobj2 = for_each(v2.begin(), v2.end(), CSum());
cout << "sum(float)=" << sobj2.GetSum() << endl;
//利用CPrint函数对象 与 for_each代替迭代器输出
vectorv3={1,2,3,4,5};
for_each(v3.begin(), v3.end(), CPrint());
cout << endl;
//同理
vectorv4={1.1,2.1,3.1,4.1,5.1};
for_each(v4.begin(), v4.end(), CPrint());
//lambad表达式
return 0;
}
4.2二元函数
4.3一元判定函数
4.4二元判定函数
五、总结知识点(未完待续.....)

一个类中重载了(),那么这个类创造的对象就叫做函数对象!!!同时这个类被叫做仿函数
再用起来的时候,函数对象就是函数名!!!!(底层不是)
