【数据结构复习之路】串 (超详细讲解)& 严蔚敏版
专栏:数据结构复习之路
复习完上面一章【线性表】【栈和队列】,我们接着复习串,这篇文章我写的非常详细且通俗易懂,看完保证会带给你不一样的收获。如果对你有帮助,看在我这么辛苦整理的份上,三连一下啦

目录
一、串的基本概念
1、串的定义
2、串的基本操作
二、顺序存储
三、链式存储
四、朴素模式匹配算法(暴力)
五、KMP
1、深入浅出之 next数组
2、利用next数组实现KMP
3、KMP算法的进一步优化
4、时间复杂度(超详细)
结尾
Reference
一、串的基本概念
1、串的定义
串(string)(或字符串)是由零个或多个字符组成的有序序列,一般记为
S = ‘ a1a2…an ’ (n>=0)
其中,S是串的名,用单引号括起来的字符序列是串的值;ai (1≤i≤n)可以是字母、数字或其他字符;串中字符的数目n成为串的长度。零个字符的串称为空串(null string),它的长度为0。
串中任意个连续的字符组成的子序列称为该串的子串。包含子串的串相应的称为主串。通常称字符在序列中的序号为该字符在串中的位置。子串在主串中的位置则以子串的第一个字符在主串中的位置来表示。其中串的位序是从 1 开始的。
值得一提的是,串本身也是一种的特殊的线性表,数据元素间呈线性关系。但串的数据对象限定为字符集,并且串的基本操作,如增删改查等,通常都是以子串为操作对象(而线性表主要以单个元素作为操作对象)。
2、串的基本操作
StrAssign(&T, chars) : 赋值操作。把串T赋值为 chars
StrCopy(&T , S) :复制操作。由串S复制得到串T,
类似于:字符串拷贝函数strcpy
StrEmpty(S) : 判空操作。
StrLength(S) : 求串长。返回串S的元素个数,
类似于:求字符串长度函数strlen
ClearString(&S) : 清空操作。将串清为空串。
DestroyString(S) : 销毁串。
Concat(&T , S1 , S2) : 串联接。用T返回由S1和S2联接而成的新串,
类似于:字符串连接函数strcat
SubString(&Sub , S , pos , len) :求字串。用Sub 返回串S的第pos个字符起长度为len的字串。
Index(S , T) : 定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置,否则返回0。
StrCompare(S , T) : 比较操作。从第一个字符开始往后依次比较,先出现更大字符的串就更大。若S > T,则返回值 > 0 ;若S = T,则返回值 = 0;若S < T,则返回值小于0。
类似于:字符串比较函数strcmp
StrDelete(&S , pos , len) :删除操作。从串S中删除第pos个字符起长度为len的子串。
StrInsert(&S , pos , T) : 插入操作。在串S的第pos个字符之前插入串T。
二、顺序存储
学了前面两章,顺序存储无非就是静态分配和动态分配(堆分配),基本结构应已熟烂于心了。
串的定义(静态):
#define MAXLEN 210
typedef struct{
char ch[MAXLEN]; //每个分量存储一个字符
int length; //串的实际长度
} SString; 串的定义(动态):
#define MAXLEN 210
#define ADDLEN 50
typedef struct{
char *ch; //按串长分配存储区
int length; //串的实际长度
} HString; ⚠️:这里的定义 和 严蔚敏、吴伟民:《数据结构(C语言版)》中的定义有点区别。书中的定义没用采用length的方法,而是选择在ch[ ] 的第一个元素ch[0] 存当前的length 长度。这虽然可以让字符的位序和数组的下标相同,并且也能很方便得到当前的length,但是ch[ ]的数据类型是char,其最大只能到127(不知道127代表的字符,可以强制转换一下就行了),即使采用unsigned char 也最大只能到255,如果超出了最大长度就要选择“截断”,所以缺点也就显而易见了,本篇文章的定义是,ch[ ]字符数组的第一个元素ch[0]不存数据,从ch[1]开始存,并且格外采用int length 存储串长(四个字节的存储量),这样就相得益彰了。
上面介绍的基本操作大多数都是非常简单的,这里就选择部分进行代码分析吧!
SubString(&Sub , S , pos , len) :求字串。用Sub 返回串S的第pos个字符起长度为len的字串。
bool SubString(SString &Sub , SString S , int pos , int len)
{
if (pos + len - 1 > S.length) return false;
for (int i = pos ; i < pos + len ; ++i)
{
Sub.ch[i - pos + 1] = S.ch[i];
}
Sub.length = len;
return true;
}StrCompare(S , T) : 比较操作。从第一个字符开始往后依次比较,先出现更大字符的串就更大。若S > T,则返回值 > 0 ;若S = T,则返回值 = 0;若S < T,则返回值小于0。
bool StrCompare(SString S , SString T)
{
for (int i = 1 ; i <= S.length && i <= T.length ; ++i)
{
if (S.ch[i] != T.ch[i])
{
return S.ch[i] - T.ch[i];
}
}
//扫描过的所有字符都相同后,串更长的串值更大,如果相等,则为0。
return S.length - T.length;
}Index(S , T) : 定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置,否则返回0。
int Index(SString S , SString T)
{
int t = 1 , n = S.length , m = T.length;
SString sub;
while (i < n - m + 1) //n - m + 1之后的长度已经小于 m了,没有看的必要了
{
SubString(sub , S , i , m);
if (StrCompare(sub , T) != 0) ++i;
else return i; //返回子串在主串中的位置
}
return 0;//不存在
}上面都是静态分配实现的,下面用堆分配实现两个基本操作:
StrInsert(&S , pos , T) : 插入操作。在串S的第pos个字符之前插入串T。
bool StrInsertHString(HString &S , int pos , HString T)
{
if (pos < 1 || pos > S.length) return false ;
if (S.length + T.length > MAXLEN - 1) { //扩容
S.ch = (char *)realloc(S.ch , (S.length + T.length) *sizeof(char));
}
for (int i = S.length ; i >= pos ; --i )
{
S.ch[i + T.length] = S.ch[i]; //为插入T腾出位置
}
for (int i = pos ; i < T.length ; ++i)
{
S.ch[i] = T.ch[i - pos + 1];
}
S.length = S.length + T.length;
return true;
}realloc函数我在栈和队列里面讲过。
StrDelete(&S , pos , len) :删除操作。从串S中删除第pos个字符起长度为len的子串。
bool StrDeleteHString (&S , int pos , int len)
{
if (pos + len > S.length + 1) return false;
for (int i = pos ; i < pos + len && i + len <= S.length ; ++i) // i < pos + len是因为前移的元素个数大于被删除数len , i + len <= S.length是由于前移元素小于被删除数len
{
S.ch[i] = S.ch[i + len];//将数据前移(覆盖部分要被删除的元素)
}
char *p = S.ch + S.length - len;
free(p); //删除剩余的无用空间
S.length = S.length - len;
return true;
}三、链式存储
和线性表的链式存储结构相类似,也可以采用链表方式存储串值。在具体实现时,每个结点既可以存放一个字符, 也可以存放多个字符。每个结点称为块,整个链表称为块链结构。图(a)是结点大小为4 (即每个结点存放4个字符)的链表,最后一个结点占不满时通常用“#”或其他非串值字符补上;图(b)是结点大小为1的链表。

typedef struct StringNode{
char ch[NodeSize]; //块结点
struct StringNode *next;
}StringNode;
typedef struct{
StringNode *head , *tail; //串的头尾指针
int length;
} LString; 这里选择设置串的头尾指针,类比于队列的链式存储,可以很方便的找到尾结点,这也就方便了串的联结操作,但应注意的是,联结时需要处理串尾的无效字符。
总之,串的链式存储的操作可以类比之前在线性表、栈和队列讲的链式操作,并且这种操作存储密度低,而且没有上面两种存储结构灵活,所有就不在此做过多介绍了。
四、朴素模式匹配算法(暴力)
问题:Index(S , T) : 定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置,否则返回0。
上面在讲顺序存储时已经讲过了, 当然只是为了运用我们写的函数而已。具体的实现如下:
//朴素匹配算法
int Index(SString S , SString T)
{
int i = 1 , k = 1;
while (i <= S.length && k <= T.length)
{
if (S.ch[i] == T.ch[k]) {
++i ; ++k;
}
else {
i = i - k + 2; //从主串的下一个字符开始重新比较
k = 1;//模式串也需重新开始
}
}
if (k > T.length) return i - T.length;
else return 0;
}时间复杂度:O(n * m):n 为S的长度,m为T的长度
五、KMP
1、深入浅出之 next数组
分析上面朴素匹配算法,不难看出暴力的做法包含了大量的重复匹配步骤,无法利用每趟已经匹配的部分字符,就比如下面这个栗子:
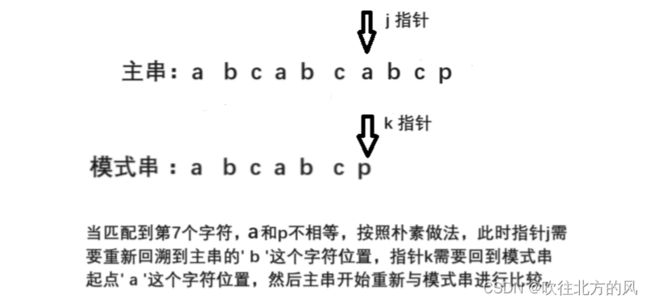
然而此时已经对模式串的 'p' 字符前面的 abcabc 完成了匹配,那能否让 j 指针保持不动,而让k指针回溯到某个位置,以利用已经匹配的这段字符串。答案是可以了的,并且k指针回溯的位置取决于已经匹配的这段模式串的最大相等前后缀数。abcabc的最大前后缀匹配串为 “ abc ” ,长度为3(前后缀不能是本身),那么此时就只需要将 k 指针移动到模式串位序为 3 + 1的位置(数组下标从 1 开始需 + 1 , 若从 0 开始不需要 + 1),然后开始后续匹配。

说到这里,你可能已经明白了KMP算法的大概趋向了。
KMP算法的核心:是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next[k] 来得出每次模式串需要回溯的位置。因此,
next[ k ]的含义是: 在子串的第 k 个字符与主串发生失配时,则跳到子串的next[ k ]位置重新与主串当前位置进行比较。
从前面的讨论可知,next函数值仅取决于模式串本身,而与主串无关。
上面都是对于KMP算法的一个指引,下面开始讲如何实现 next[k]。
对于模式串的第一个字符的next[1],我们知道第一个字符的前面已无字符,所有就更别提前后缀了,所以其 next[1] = 0 ,并且对于第一个字符如果不匹配,后续就无法再对 k 指针回溯了,所以当 k = next[1] = 0时,就要让 j 和 k 指针同时 + 1 (如果 k != 0 , j 指针需保持不变,这里没听懂,没关系,后续代码会介绍)。当然,除第一个字符外,模式串中其余的字符对应的next数组的值等于其最大公共前后缀长度加上1。
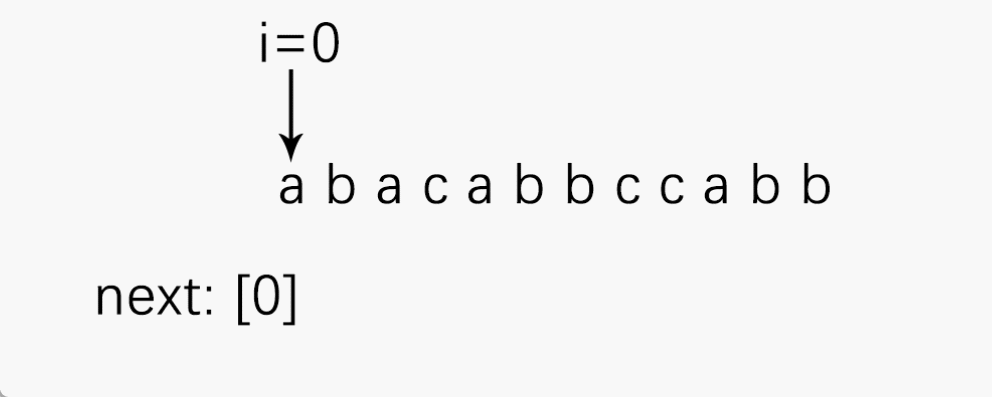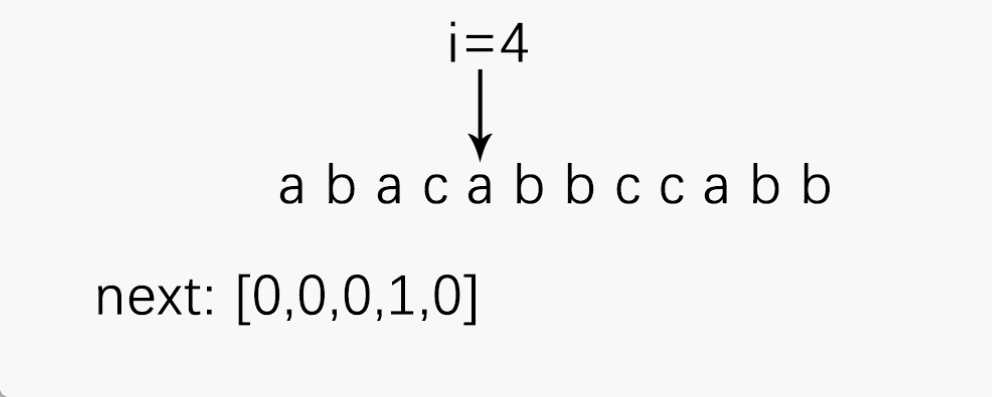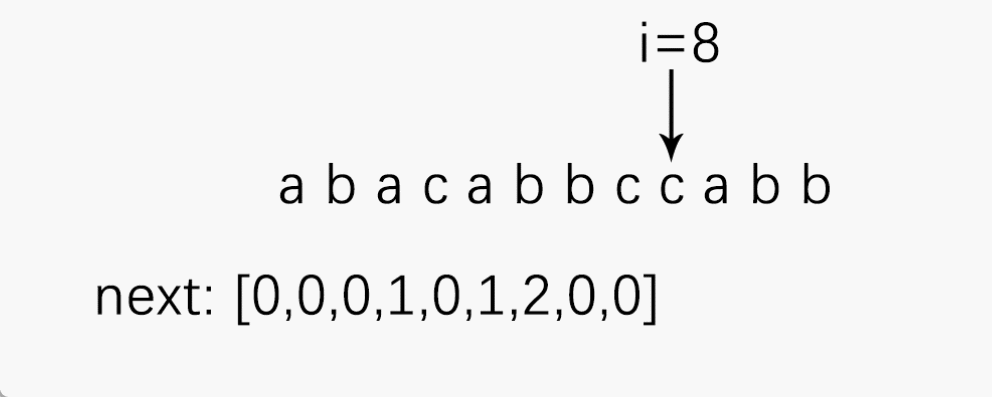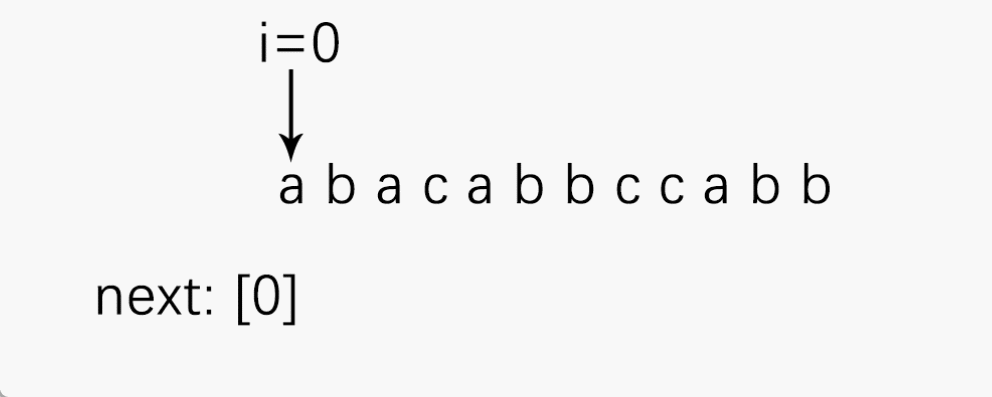
可以通过一个栗子来理解next[ ]的求解:
为了便于理解,我先求出最大相等前后缀,再通过它得出next[k]。
注意:next数组的下标也要从 1 开始!!!

⚠️⚠️⚠️:如果字符数组,即模式串的下标是从0开始的,那么上述next[k]数组应该为:
除第一个字符的next[0] = -1,其余不用+1。并且next数组从下标 0 开始!!!
![]()
现在你已经清楚 next[k] 的手动求解过程了,那么代码实现就顺其自然了。
这个查找过程实际上仍然是模式匹配,只是匹配的模式与目标在这里是同一个串T。
void get_next(SString T , int next[])
{
int i = 1 , k = 0; //这里k要为0
next[1] = 0;
while (i < T.length)
{
if (k == 0 || T.ch[i] == T.ch[k]) //ch[i]表示后缀,ch[k]表示前缀,同时ch[i]也是主串,ch[k]是模式串
{
++i; ++k;
next[i] = k;
}
else{
k = next[k]; //当遇到模式串与主串不匹配时,利用next将k指针回溯
}
}
}为了助于大家理解上述代码,这里我举了一个栗子,带着大家走一遍流程:
代码实现求 【 a b a b a a c 】的next[k]数组详细过程!!!

接着上面图解的辅助,阐述一下它的算法思想:
【1】就如上面的图4和图5,当已经得到 next[4] = 2 时,最长相等前后缀为 “a”,之后计算 next[5] 时,由于 ch[4] == ch[ next[4] ] ,因此可以把最长相等前后缀 “a” 扩展为 “ab”,因此 next[5] = next[4] + 1,并令 k 指向 next[5]。
【2】就如上面的图7和图8,当ch[i] != ch[k],就要运用next回溯,k = next[k] = k1 ,此时在主串T 的第 i 个字符前面一定存在 ![]() 到
到 ![]() 的字符串与
的字符串与  到
到 ![]() 的字符串相等(当然k1 = 1 的话,就直接回溯到起点了),然后只需比较
的字符串相等(当然k1 = 1 的话,就直接回溯到起点了),然后只需比较  是否与
是否与![]() 相等即可,如果不相等,就继续回溯,直到 k = next[1] = 0 ,然后++i , ++j .........。【这段话也正是KMP算法真正的核心思想】
相等即可,如果不相等,就继续回溯,直到 k = next[1] = 0 ,然后++i , ++j .........。【这段话也正是KMP算法真正的核心思想】
【3】就如上图的图1和图3,当 k = next[1] = 0时,表明k已经无法再继续回溯,说明此时在主串T 的第 i 个字符前面的字符串一定不存在前后缀,所以放心的让next[]等于1就完事了!
2、利用next数组实现KMP
只要next数组求出来了,利用它来求模式串的匹配问题就非常简单了。这基本和朴素模拟匹配的步骤很相似。
int Index_KMP(SString S, SString T){
int i = 1 , k = 1; //注意这里k要为1
int next[255]; //定义next数组
get_next(T, next); //得到next数组
while (i <= S.length && k <= T.length){
if (k == 0 || S.ch[i] == T.ch[k]){ //字符相等则继续,这里的j == 0时,也证实了我上面讲的那段话!
++i; ++k;
}
else{
k = next[k]; //模式串的 K指针回溯,主串的i指针不变
}
}
if (k > T.length){
return i - T.length; //匹配成功
}
else{
return 0;
}
}
3、KMP算法的进一步优化
直接看我上面举的那个栗子: 【 a b a b a a c 】
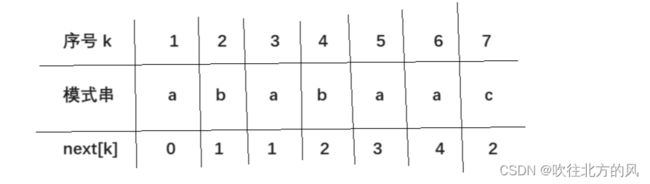
如图3,当 k == 0 时,执行完++i, ++k后 ,应该执行next[i] = k 这一步,即next[3] = 1,但是观察 i == 3 时,这段字符串:“ aba”。我们可以发现 ![]() 最终指向的 的值为 ‘ a ’,其值和
最终指向的 的值为 ‘ a ’,其值和 是一样的,如果我们就这么确定next[3] = 1,并利用next数组实现KMP时,若发现主串和模式串在 时不匹配,此时就要采用k = next[3]回溯,然后 k = 1,就如之前所说:【
是一样的,如果我们就这么确定next[3] = 1,并利用next数组实现KMP时,若发现主串和模式串在 时不匹配,此时就要采用k = next[3]回溯,然后 k = 1,就如之前所说:【![]() 最终指向的 的值为 ‘ a ’,其值和是一样的】,显然也不匹配。
最终指向的 的值为 ‘ a ’,其值和是一样的】,显然也不匹配。
因此当我们在求next数组,发现![]() 时, 应该让 next[3] = next[k] 。这里的话,就是
时, 应该让 next[3] = next[k] 。这里的话,就是
next[3] = next[1] = 0 ,然后当利用next数组实现KMP时,若发现主串和模式串在 时不匹配,此时
k 回溯到 k = next[3] = 0 ,然后就直接++i , ++k ,不用再接二连三的采用next数组回溯了。这能节省一部分时间。
最后根据我上面讲的优化思想,你应该可以得出优化后的next数组:nextval数组

当然如图5,nextval[5] = nextval[3] = 0。所以会得到最终的结果的!
代码实现:
void get_nextval(SString T, int nextval[]){
int i = 1, k = 0; //注意这里 K为 0
nextval[1] = 0;
while (i < T.length){
if (k == 0 || T.ch[i] == T.ch[k]){ //ch[i]表示后缀的单个字符,ch[K]表示前缀的单个字符
++i; ++k;
if (T.ch[i] != T.ch[k]){ //若当前字符与前缀字符不同
nextval[i] = k; //则当前的 K 为 nextval在 i 位置的值
}else{
//如果与前缀字符相同
//则将前缀字符的nextval值给nextval在i位置上的值
nextval[i] = nextval[k]; //就如nextval[5] = nextval[3] = 0
}
}
else{
k = nextval[k]; //否则令 K指针 回溯,循环继续
}
}
}
4、时间复杂度(超详细)
n = S.length , m = T.length
观察 Index_KMP 函数我们发现,while循环最多 n 次,并且对于循环里的回溯操作, k 回退的次数可能不可预计,那为什么 KMP 的时间复杂度为 O(n + m) 呢?
首先,在 KMP 整个 while 循环中 i 是不断加 1 的,所以在整个过程中 i 的变化次数是 O(n) 级别,接下来考虑 k 的变化,我们注意到++i 和 ++k 这步操作是在同一行,那么每次++i,必然也会++k ,既然 i 的变化次数是 O(n) 级别 ,那么在整个过程中 k 最多增加 n 次;而其它情况 k 通过回溯,都是不断减小的,由于 k 最小不会小于 0,因此在整个过程中,由于每次回溯后必然要通过++k来增加,那么回溯也就受限于 k 的次数,所以总的回溯次数也必然不会操作 n 次。也就是说 while 循环对整个过程来说最多只会执行 n 次,因此 k 在整个过程中变化次数是 O(n)级别的。由于 i 和 k 在整个过程中的变化次数都是 O(n) ,因此 while 循环部分的整体复杂度就是 O(n)。考虑到计算 next 数组需要 O(m) 的时间复杂度(分析方法与上同)。
因此 KMP 算法总共需要 O(n + m) 的时间复杂度。
结尾
最后,非常感谢大家的阅读。我接下来还会更新 数组和广义表 ,如果本文有错误或者不足的地方请在评论区(或者私信)留言,一定尽量满足大家,如果对大家有帮助,还望三连一下啦!
我的个人博客,欢迎访问!
Reference
【1】严蔚敏、吴伟民:《数据结构(C语言版)》
【2】b站:王道数据结构
【3】数据结构:串(String)【详解】