【C++】哈希应用——布隆过滤器
⭐博客主页:️CS semi主页
⭐欢迎关注:点赞收藏+留言
⭐系列专栏:C++进阶
⭐代码仓库:C++进阶
家人们更新不易,你们的点赞和关注对我而言十分重要,友友们麻烦多多点赞+关注,你们的支持是我创作最大的动力,欢迎友友们私信提问,家人们不要忘记点赞收藏+关注哦!!!
哈希应用——布隆过滤器
- 一、布隆过滤器提出
- 二、布隆过滤器的概念
-
- 1、布隆过滤器的特点
- 2、如何控制误判率
- 三、布隆过滤器的实现
-
- 1、介绍三种字符串转换成整型
- 2、布隆过滤器的插入
- 3、布隆过滤器的查找
- 4、布隆过滤器的删除
- 四、布隆过滤器的优点
- 五、布隆过滤器的缺陷
一、布隆过滤器提出
我们在看抖音的时候,经常会有推荐的广告出现和推荐的抖音内容出现,那么这个推荐是怎么实现的呢?那当然是用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录,这样才能实现去重的效果,那么还有一个很棘手的问题,我们如何快速查找呢?我们有下面三种做法实现查找:
第一种做法:我们利用哈希表或者哈希桶,但我们发现利用哈希表太浪费空间了。
第二种做法:我们利用位图的概念来存储用户记录,但缺点是我们能存整型的,但处理不了string等字符串类型的。
第三种做法:那我们就把第一种做法中的哈希表和第二种做法的位图结合起来就好了,既节省了空间还能存string等字符串类型的值。
二、布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
布隆过滤器实质上是位图的延伸和变形,能够有效地降低误判率,其降低误判率的形式是当一个数据映射到位图当中,布隆过滤器会用多个哈希函数将其映射到多个比特位,当判断一个数据是否在位图当中时,需要分别根据这些哈希函数计算出对应的比特位,如果这些比特位都被设置为1则判定为该数据存在,否则则判定为该数据不存在。当使用多个哈希函数将其映射到多个比特位的时候,能够有效地降低误判率,那么我们用下面的QQ昵称进行讲解:
我们假设一个数据映射到三个比特位,我们发现张三先映射了这三个位,而当我们判断李四有没有在这个位图中的时候,先是进行映射三个比特位,发现前两个映射到与张三一样的比特位上,发生哈希函数冲突,但最后一个映射到位图的最后一个位上,最后一个比特位是0,则判断在位图中没有李四这个昵称,所以可以用李四这个昵称。

但随着我们插入的昵称越来越多的时候,其误判率越来越高,也就是我们的哈希冲突更加多了,我们看下图,发生完全误判的情况:(王五明明没有在位图中出现,但却发生了误判,这是因为王五这个昵称的三个比特位都到发生哈希冲突了,因为“张三”和“李四”这两个昵称已经占了“王五”这个昵称的比特位了)

1、布隆过滤器的特点
当布隆过滤器判断一个数据不存在在位图中是很准确的,因为必然它被映射到位图中是至少有一个比特位是0的!
当布隆过滤器判断一个数据存在在位图中是不准确的,因为可能有误判的出现,其他的昵称可能已经占用了这个新数据的比特位,而并不是这个新的昵称真的已经在位图中存在的。
2、如何控制误判率
判断条件一:位图的大小。当位图较小的时候,很快布隆过滤器会将这个位图的所有位都置1,此时布隆过滤器的误判率会很高,因此位图越长的时候,其产生的误判率会越低。
判断条件二:哈希函数的多少。当哈希函数越多的时候,很快这个位图的比特位会被布隆过滤器的所有位都置为1,但如果哈希函数的个数太少,也会导致误判率变高。
所以根据位图的大小和哈希函数的多少,有人总结了如下的公式:

其中k为哈希函数个数,m为布隆过滤器长度,n为插入的元素个数,p为误判率。我们这里取k=3,ln2取0.7,那么m与n的关系是m=4*n,也就是布隆过滤器的长度是插入元素长度的4倍。
三、布隆过滤器的实现
布隆过滤器可以实现一个模板类,因此插入到位图(布隆过滤器)不仅仅可以是字符串,还可以是其他类型,而一般情况下布隆过滤器都是用来处理字符串的,所以这里可以将模板参数K的缺省类型设置为string。
//布隆过滤器
template<size_t N, class K = string, class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class bloomfilter
{
public:
//...
private:
bitset<N> _bs;
};
同时,我们排名前三的三种字符串转成整型的算法操作如下:
1、介绍三种字符串转换成整型
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
这里选取将字符串转换成整型的哈希函数,是经过测试后综合评分最高的BKDRHash、APHash和DJBHash,这三种哈希算法在多种场景下产生哈希冲突的概率是最小的。此时本来这三种哈希函数单独使用时产生冲突的概率就比较小,现在要让它们同时产生冲突概率就更小了。
2、布隆过滤器的插入
也就是通过这三个转换成整型的函数分别算出三个不同的比特位,映射到位图中。插入元素时,需要通过三个哈希函数分别计算出该元素对应的三个比特位,然后将位图中的这三个比特位设置为1即可
void Set(const K& key)
{
// 计算出key对应的三个位
size_t i1 = Hash1()(key) % N;
size_t i2 = Hash2()(key) % N;
size_t i3 = Hash3()(key) % N;
// 置1
_bs.set(il);
_bs.set(i2);
_bs.set(i3);
}
3、布隆过滤器的查找
在检测中,我们只需用三个哈希函数分别计算出该元素对应的三个比特位,然后判断位图中的这三个比特位是否被设置为1。
只要这三个比特位当中有一个比特位未被设置则说明该元素一定不存在。
如果这三个比特位全部被设置,则返回true表示该元素存在但可能造成误判。
bool Test(const K& key)
{
size_t i1 = Hash1()(key) % N;
if (_bs.test(il) == false)
{
return false;
}
size_t i2 = Hash2()(key) % N;
if (_bs.test(i2) == false)
{
return false;
}
size_t i3 = Hash3()(key) % N;
if (_bs.test(i3) == false)
{
return false;
}
// 三个都存在,可能导致误判
return true;
}
4、布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
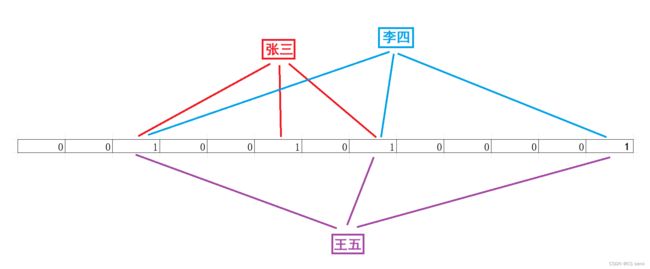
如上图,如果我们删除“李四”这个数据的话,那么三个1都要置0,则导致张三有俩置0了!那张三的数据岂不是很奇怪?
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
四、布隆过滤器的优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无
关 - 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
五、布隆过滤器的缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题