UCAS - AI学院 - 自然语言处理专项课 - 第11讲 - 课程笔记
UCAS - AI学院 - 自然语言处理专项课 - 第11讲 - 课程笔记
- 机器翻译
-
- 概论
- 统计机器翻译
- 神经机器翻译
- 系统融合
- 译文质量评估
- 语音翻译
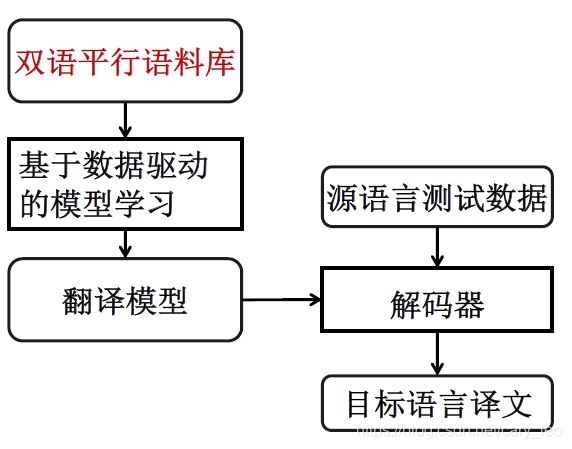
机器翻译
概论
- 机器翻译:用计算机把一种语言(源语言)翻译成另一种语言(目标语言)的技术
- 困难
- 歧义和未知现象
- 文化差异和世界知识常识
- 解不唯一,标准认为制定
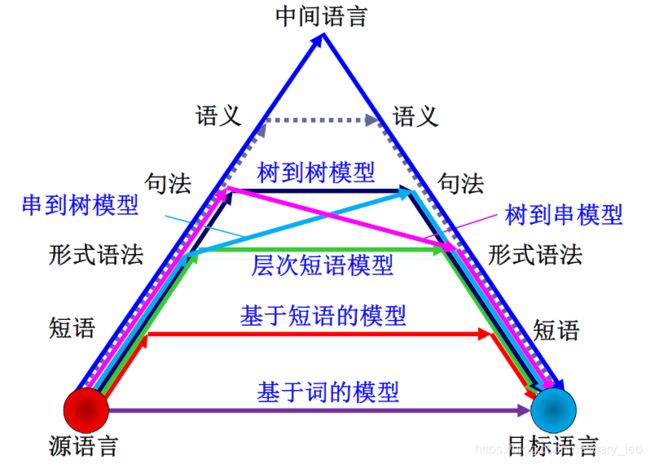
- 基本方法
- 基本转换法
- 直接进行单词、短语、句子的置换,并适当进行次序调整
- 基于规则的翻译方法
- 翻译机制与语法分开,用规则描述语法
- 词法分析——句法/语义分析——句子结构到译文结构——译文句法结构生成——源语言词汇到译文词汇的转换——译文词法选择与生成
- 独立分析——独立生成——相关转换
- Pros:保持原文结构,产生译文与原文关系密切,对已知规则结构翻译效果较好
- Cons:规则人工编写,难以处理非规范语言现象
- 基于中间语言的翻译方法
- 利用中间人机制实现
- Pros:中间语言设计可以不考虑翻译语言对,适合多语言互译
- Cons:中间语言的设计维护很难
- 基于语料库的翻译方法
- 基于事例的方法
- 输入——事例相似度——翻译结果
- Pros:不需要对句子做深入分析
- Cons:相似度难以把握,难处理陌生语言现象
- 基于事例的方法
- 基本转换法
统计机器翻译
-
思想
-
基本原理:噪声信道模型
- 一种语言 T T T由于经过一个噪声信道而发生变形,从而在信道的另一端呈现为另一种语言 S S S
- 根据观察到的 S S S,恢复最为可能的 T T T
- 源语言句子 S = s 1 m S=s_1^m S=s1m,目标语言句子 T = t 1 l T = t_1^l T=t1l
- 贝叶斯公式 P ( T ∣ S ) ∝ P ( T ) P ( S ∣ T ) P(T|S) \propto P(T) P(S | T) P(T∣S)∝P(T)P(S∣T)
- 目标 T = arg max T P ( T ) P ( S ∣ T ) T = \arg\max_T P(T) P(S|T) T=argmaxTP(T)P(S∣T)
- 语言模型 P ( T ) P(T) P(T),翻译模型 P ( S ∣ T ) P(S | T) P(S∣T)
-
语言模型概率估计
- 给定句子 T = t 1 l T = t_1^l T=t1l, P ( T ) = P ( t 1 ) P ( t 2 ∣ t 1 ) ⋯ P ( t l ∣ t 1 … t l − 1 ) P(T) = P(t_1) P(t_2|t_1) \cdots P(t_l | t_1 \dots t_{l - 1}) P(T)=P(t1)P(t2∣t1)⋯P(tl∣t1…tl−1)
- n-gram问题
-
翻译概率估计
- 定义目标语言句子中的词与源语言句子中的词之间的对应关系
- 对位关系集合 A ( S , T ) \mathcal A(S, T) A(S,T)——对位模型
- 将之视为隐含变量,则 P ( S ∣ T ) = ∑ A P ( S , A ∣ T ) P(S|T) = \sum_A P(S, A | T) P(S∣T)=∑AP(S,A∣T)
- 对位序列 A = a 1 m , a j ∈ [ 1 , … , l ] A = a_1^m, a_j \in [1, \dots, l] A=a1m,aj∈[1,…,l]
- P ( S , A ∣ T ) = P ( m ∣ T ) P ( A ∣ T , m ) P ( S ∣ T , A , m ) P(S, A|T) = P(m|T) P(A|T, m) P(S|T, A, m) P(S,A∣T)=P(m∣T)P(A∣T,m)P(S∣T,A,m)(生成单词 × 满足对应关系(对位模型) × 对应原句(词汇翻译模型))
- P ( S , A ∣ T ) = p ( m ∣ T ) P ( A ∣ T , m ) P ( S ∣ T , A , m ) = p ( m ∣ T ) ∏ j m [ P ( a j ∣ a 1 j − 1 , s 1 j − 1 , m , T ) P ( s j ∣ a 1 j , s 1 j − 1 , m , T ) ] P(S, A|T) = p(m|T) P(A|T, m) P(S|T, A, m) = p(m|T) \prod_j^m \left[P\left(a_j| a_1^{j-1}, s_1^{j - 1}, m, T\right) P\left(s_j| a_1^{j}, s_1^{j - 1}, m, T\right)\right] P(S,A∣T)=p(m∣T)P(A∣T,m)P(S∣T,A,m)=p(m∣T)∏jm[P(aj∣a1j−1,s1j−1,m,T)P(sj∣a1j,s1j−1,m,T)]
- 上述分解形式可变,根据不同的假设条件可以分解为5种不同的翻译模型
-
IBM TM1
- 假设(很强的假设)
- ϵ = p ( m ∣ T ) \epsilon = p(m|T) ϵ=p(m∣T)为较小常量
- a j ∼ uniform ( 0 , . . , l ) a_j \sim \operatorname{uniform}(0, .. ,l) aj∼uniform(0,..,l),均匀分布 P ( a j ∣ a 1 j − 1 , s 1 j − 1 , m , T ) = 1 l + 1 P\left(a_j| a_1^{j-1}, s_1^{j - 1}, m, T\right) = \frac 1{l + 1} P(aj∣a1j−1,s1j−1,m,T)=l+11
- s j ∼ Categorical ( θ t a j ) s_j \sim \operatorname{Categorical}(\theta_{t_{a_j}}) sj∼Categorical(θtaj),只满足目标词的类别分布 P ( a j ∣ a 1 j , s 1 j − 1 , m , T ) = P ( s j ∣ t a j ) P\left(a_j| a_1^{j}, s_1^{j - 1}, m, T\right) = P \left(s_j | t_{a_j}\right) P(aj∣a1j,s1j−1,m,T)=P(sj∣taj)
- P ( S , A ∣ T ) = ϵ ∏ j 1 l + 1 P ( s j ∣ t a j ) = ϵ ( l + 1 ) m ∏ j m P ( s j ∣ t a j ) P(S, A|T) = \epsilon \prod_j \frac{1}{l+1} P \left(s_j | t_{a_j}\right) = \frac{\epsilon}{(l+1)^m} \prod_j^m P \left(s_j | t_{a_j}\right) P(S,A∣T)=ϵ∏jl+11P(sj∣taj)=(l+1)mϵ∏jmP(sj∣taj)
- P ( S ∣ T ) = ∑ A P ( S , A ∣ T ) = ∑ A ϵ ( l + 1 ) m ∏ j m P ( s j ∣ t a j ) = ϵ ( l + 1 ) m ∑ a 1 l ⋯ ∑ a m l ∏ j m P ( s j ∣ t a j ) P(S|T) = \sum_A P(S, A | T) = \sum_A \frac{\epsilon}{(l+1)^m} \prod_j^m P \left(s_j | t_{a_j}\right) = \frac{\epsilon}{(l+1)^m} \sum_{a_1}^l \cdots \sum_{a_m}^l \prod_j^m P \left(s_j | t_{a_j}\right) P(S∣T)=∑AP(S,A∣T)=∑A(l+1)mϵ∏jmP(sj∣taj)=(l+1)mϵ∑a1l⋯∑aml∏jmP(sj∣taj)
- 训练
- 拉格朗日乘子法: h ( p , λ ) = P ( S ∣ T ) − ∑ t λ t ( ∑ s P ( s ∣ t ) − 1 ) h(p, \lambda) = P(S|T) - \sum_t \lambda_t \left( \sum_s P(s|t) - 1 \right) h(p,λ)=P(S∣T)−∑tλt(∑sP(s∣t)−1)
- 导数为0: ∑ A ϵ ( l + 1 ) m ∑ j δ ( s = s j ) δ ( t = t a j ) 1 p ( s ∣ t ) ∏ k m P ( s k ∣ t a k ) − λ t = 0 \sum_A \frac{\epsilon}{(l+1)^m} \sum_j \delta(s = s_j) \delta(t = t_{a_j}) \frac{1}{p(s|t)}\prod_k^m P\left(s_k | t_{a_k}\right) - \lambda_t = 0 ∑A(l+1)mϵ∑jδ(s=sj)δ(t=taj)p(s∣t)1∏kmP(sk∣tak)−λt=0
- p ( s ∣ t ) = 1 λ t ∑ A ϵ ( l + 1 ) m ∑ j δ ( s = s j ) δ ( t = t a j ) ∏ k m P ( s k ∣ t a k ) p(s|t) = \frac 1 {\lambda_t} \sum_A \frac{\epsilon}{(l+1)^m} \sum_j \delta(s = s_j) \delta(t = t_{a_j}) \prod_k^m P\left(s_k | t_{a_k}\right) p(s∣t)=λt1∑A(l+1)mϵ∑jδ(s=sj)δ(t=taj)∏kmP(sk∣tak)
- EM训练思路:任意初始值,不断计算右侧值,更新 p ( s ∣ t ) p(s|t) p(s∣t)的估计值
- 模型最终表示 P ( S ∣ T ) = ϵ ( l + 1 ) m ∏ j m ∑ a j l p ( s j ∣ t a j ) P(S|T) = \frac{\epsilon}{(l+1)^m} \prod_j^m \sum_{a_j}^l p(s_j | t_{a_j}) P(S∣T)=(l+1)mϵ∏jm∑ajlp(sj∣taj)
- 实现过程
- 根据概率分布选择源语言句子长度 m m m
- 对每一个 j = 1 , … , m j = 1, \dots, m j=1,…,m,根据均匀分布原则确定 a j a_j aj
- 对每一个 j = 1 , … , m j = 1, \dots, m j=1,…,m,根据概率 p ( f i ∣ e a j ) p(f_i | e_{a_j}) p(fi∣eaj)选择一个法语单词 f j f_j fj
- 假设(很强的假设)
-
IBM TM2
- 假设
- ϵ = p ( m ∣ T ) \epsilon = p(m|T) ϵ=p(m∣T)为较小常量
- P ( a j ∣ a 1 j − 1 , s 1 j − 1 , m , T ) = a ( a j ∣ j , m , l ) P\left(a_j| a_1^{j-1}, s_1^{j - 1}, m, T\right) = a(a_j | j, m, l) P(aj∣a1j−1,s1j−1,m,T)=a(aj∣j,m,l)依赖于位置 j j j,对应关系 a j a_j aj和源语言句子长度 m m m以及目标句子长度 l l l——对位概率
- s j ∼ Categorical ( θ t a j ) s_j \sim \operatorname{Categorical}(\theta_{t_{a_j}}) sj∼Categorical(θtaj),只满足目标词的类别分布 P ( a j ∣ a 1 j , s 1 j − 1 , m , T ) = P ( s j ∣ t a j ) P\left(a_j| a_1^{j}, s_1^{j - 1}, m, T\right) = P \left(s_j | t_{a_j}\right) P(aj∣a1j,s1j−1,m,T)=P(sj∣taj)
- 类似于TM1的推导,可以得到TM2: P ( S ∣ T ) = ϵ ∏ j m ∑ i l a ( i ∣ j , m , l ) p ( s j ∣ t a j ) P(S|T) = \epsilon \prod_j^m \sum_i^l a(i|j, m, l) p(s_j | t_{a_j}) P(S∣T)=ϵ∏jm∑ila(i∣j,m,l)p(sj∣taj)
- 如果对位概率为常数,则TM2退化为TM1
- 实现过程
- 根据概率分布选择源语言句子长度 m m m
- 对每一个 j = 1 , … , m j = 1, \dots, m j=1,…,m,根据概率 a ( a j ∣ j , m , l ) a(a_j | j, m, l) a(aj∣j,m,l)确定 a j a_j aj
- 对每一个 j = 1 , … , m j = 1, \dots, m j=1,…,m,根据概率 p ( f i ∣ e a j ) p(f_i | e_{a_j}) p(fi∣eaj)选择一个法语单词 f j f_j fj
- 问题:一个目标语言单词可以生成过多的源语言单词
- 假设
-
IBM TM3
- 繁衍率 Φ t \Phi_t Φt:又称产出率,目标语言单词可对应源语言单词的数目——一对多关系
- 繁衍率复制目标词——空指情形判断(源语言词无目标语言对应)——条件概率转换——调整词顺序
-
IBM TM4:考虑片段的中心词的概率和其他单词的位置概率
-
IBM TM5:源语言句子单词间的相对位置
-
IBM翻译模型特点:基于词的模型
-
基于短语的翻译模型
-
生成式模型转向判别式模型
- T = arg max T P ( T ) P ( S ∣ T ) T = \arg\max_T P(T) P(S|T) T=argmaxTP(T)P(S∣T)
- P ( S ∣ T ) P(S|T) P(S∣T)往往不是我们期望的思路
- T = arg max T P ( T ) P ( T ∣ S ) T = \arg\max_T P(T) P(T|S) T=argmaxTP(T)P(T∣S)违反噪声信道模型?但是质量相当
-
最大熵方法
- 反向模型 P ( S ∣ T ) P(S|T) P(S∣T)无法使用噪声信道模型解释
- 将语言模型概率、正向、反向翻译概率都视为特征,使用最大熵方法建模
- 基本思想:参数与样例的经验分布一致,对未知事件不做任何假设,保证模型尽可能均匀——熵最大
- M M M个特征 h 1 ( T , S ) , … , h M ( T , S ) h_1(T, S), \dots, h_M(T, S) h1(T,S),…,hM(T,S),具有权值 λ 1 , … , λ M \lambda_1, \dots, \lambda_M λ1,…,λM
- 最佳译文 T ′ = arg max T P ( T ∣ S ) = arg max T 1 Z exp { ∑ m M λ m h m ( T , S ) } ∝ arg max T ∑ m M λ m h m ( T , S ) T^\prime = \arg\max_T P(T | S) = \arg\max_T \frac {1}{Z} \exp\{\sum_m^M \lambda_m h_m(T, S)\} \propto \arg\max_T \sum_m^M \lambda_m h_m(T, S) T′=argmaxTP(T∣S)=argmaxTZ1exp{∑mMλmhm(T,S)}∝argmaxT∑mMλmhm(T,S)
- 两个特征 h 1 = log P ( T ) h_1 = \log P(T) h1=logP(T)和 h 2 = log P ( S ∣ T ) h_2 = \log P(S|T) h2=logP(S∣T),且权重均为1,则此时等价为噪声信道模型——对数线性模型
-
翻译基本的单元由词转向词语
- 词的翻译模型:消歧问题,一对多、多对一、多对多情形难以处理
- 短语翻译模型:短语翻译规则,直接将繁衍率信息、上下文信息以及局部对位调序信息记录在翻译规则中
- 短语划分——短语翻译——短语调序
-
短语:连续的词串n-gram
- T ′ = arg max T P ( T ∣ S ) = arg max T , S 1 k P ( T , S 1 K ∣ S ) = arg max T , S 1 k , T 1 K , T 1 K ′ P ( S 1 K ∣ S ) P ( T 1 K ∣ S 1 K , S ) P ( T 1 K ′ ∣ T 1 K , S 1 K , S ) P ( T ∣ T 1 K ′ , T 1 K , S 1 K , S ) T^\prime = \arg\max_T P(T | S) = \arg\max_{T, S_1^k} P(T, S_1^K | S) = \arg\max_{T, S_1^k, T_1^K, T_1^{K^\prime}} P(S_1^K | S) P(T_1^K | S_1^K, S) P(T_1^{K^\prime} | T_1^K, S_1^K, S) P(T| T_1^{K^\prime}, T_1^K, S_1^K, S) T′=argmaxTP(T∣S)=argmaxT,S1kP(T,S1K∣S)=argmaxT,S1k,T1K,T1K′P(S1K∣S)P(T1K∣S1K,S)P(T1K′∣T1K,S1K,S)P(T∣T1K′,T1K,S1K,S)
- 分别对应短语划分模型、短语翻译模型、短语调序模型、目标语言模型
-
短语划分模型 P ( S 1 K ∣ S ) P(S_1^K | S) P(S1K∣S)
- 目标:将一个词序列如何划分为短语序列
- 方法:一般假设每一种短语划分方式都是等概率的
-
短语翻译模型 P ( T 1 K ∣ S 1 K , S ) P(T_1^K | S_1^K, S) P(T1K∣S1K,S)
- 学习短语翻译规则
- 双语句对词语对齐:IBM模型,找到词之间的关系
- 短语翻译规则抽取
- 算法:寻找满足对齐一致性的短语对
- 对齐一致性: S i j S_i^j Sij中每个词 S k S_k Sk,若 ( k , k ′ ) ∈ A (k, k^\prime) \in A (k,k′)∈A,则 i ′ ≤ k ′ ≤ j ′ i^\prime \le k^\prime \le j^\prime i′≤k′≤j′; T i p r i m e j ′ T_{i^prime}^{j^\prime} Tiprimej′中每个词 T t T_t Tt,若 ( t , t ′ ) ∈ A (t, t^\prime) \in A (t,t′)∈A,则 i ≤ t ≤ j i \le t \le j i≤t≤j
- 最长匹配优先,同时限制匹配最大长度(太长的短语太罕见)
- 估计短语翻译概率(最大似然)
- 正向、逆向短语翻译概率 p ( t ∣ s ) , p ( s ∣ t ) p(t|s), p(s|t) p(t∣s),p(s∣t)
- 短语看作整体、翻译的可能性
- 正向、逆向词汇化翻译概率 p l e x ( t ∣ s ) , p l e x ( s ∣ t ) p_{lex}(t|s), p_{lex}(s|t) plex(t∣s),plex(s∣t)
- 刻画短语内部的翻译情况——词集合
- 针对词的互译程度
- p l e x ( t ∣ s ) = ∏ j ∣ t ∣ 1 ∣ { i ∣ ( j , i ) ∈ A } ∣ ∑ ( j , i ) ∈ A p ( t j ∣ s i ) p_{lex}(t|s)= \prod_j^{|t|} \frac {1}{|\{i | (j, i) \in A\}|} \sum_{(j, i) \in A} p(t_j | s_i) plex(t∣s)=∏j∣t∣∣{i∣(j,i)∈A}∣1∑(j,i)∈Ap(tj∣si)
- 对于每一个目标短语词,计算每一个对应关系的词对概率,获得平均概率后连乘
- 正向、逆向短语翻译概率 p ( t ∣ s ) , p ( s ∣ t ) p(t|s), p(s|t) p(t∣s),p(s∣t)
- 学习短语翻译规则
-
短语调序模型 P ( T 1 K ′ ∣ T 1 K , S 1 K , S ) P(T_1^{K^\prime} | T_1^K, S_1^K, S) P(T1K′∣T1K,S1K,S)
- 距离跳转模型
- d = n e x t b e g i n − l a s t e n d − 1 d = next_{begin} - last_{end} - 1 d=nextbegin−lastend−1
- 针对源语言中的位置,翻译顺序针对目标语言中的位置
- 跳转距离越大,惩罚值越大
- 惩罚值需要同时受到上下文的影响
- 分类模型
- 一种方案
- M o n o t o n e : n e x t b e g i n − l a s t e n d = 1 Monotone : next_{begin} - last_{end} = 1 Monotone:nextbegin−lastend=1
- S w a p : n e x t e n d − l a s t b e g i n = − 1 Swap : next_{end} - last_{begin} = -1 Swap:nextend−lastbegin=−1
- KaTeX parse error: Undefined control sequence: \and at position 50: …t_{end} \neq 1 \̲a̲n̲d̲ ̲next_{end} - la…
- 综合调序因素、语义因素、翻译因素等选择最佳调序方案
- 分类器设计:最大熵分类器(综合训练语料特征),给出上述三种方案的概率,综合其他因素打分确定调序策略
- 一种方案
- 距离跳转模型
-
目标语言模型 P ( T ∣ T 1 K ′ , T 1 K , S 1 K , S ) P(T| T_1^{K^\prime}, T_1^K, S_1^K, S) P(T∣T1K′,T1K,S1K,S)
- 深度模型
-
短语翻译模型的8个特征
- h 1 ( T , S ) = log p ( t ∣ s ) h_1(T, S) = \log p(t|s) h1(T,S)=logp(t∣s)
- h 2 ( T , S ) = log p ( s ∣ t ) h_2(T, S) = \log p(s|t) h2(T,S)=logp(s∣t)
- h 3 ( T , S ) = log p l e x ( t ∣ s ) h_3(T, S) = \log p_{lex}(t|s) h3(T,S)=logplex(t∣s)
- h 4 ( T , S ) = log p l e x ( s ∣ t ) h_4(T, S) = \log p_{lex}(s|t) h4(T,S)=logplex(s∣t)
- h 5 ( T , S ) = log P ( T 1 K ′ ∣ T 1 K , S 1 K , S ) h_5(T, S) = \log P(T_1^{K^\prime} | T_1^K, S_1^K, S) h5(T,S)=logP(T1K′∣T1K,S1K,S)
- h 6 ( T , S ) = log P ( T ∣ T 1 K ′ , T 1 K , S 1 K , S ) h_6(T, S) = \log P(T| T_1^{K^\prime}, T_1^K, S_1^K, S) h6(T,S)=logP(T∣T1K′,T1K,S1K,S)
- h 7 ( T , S ) = log len ( T ) h_7(T, S) = \log \operatorname{len}(T) h7(T,S)=loglen(T)
- h 8 ( T , S ) = log count ( p h r a s e s ) h_8(T, S) = \log \operatorname{count}(phrases) h8(T,S)=logcount(phrases)(源语言短语划分数目越少越好)
-
短语模型的解码算法
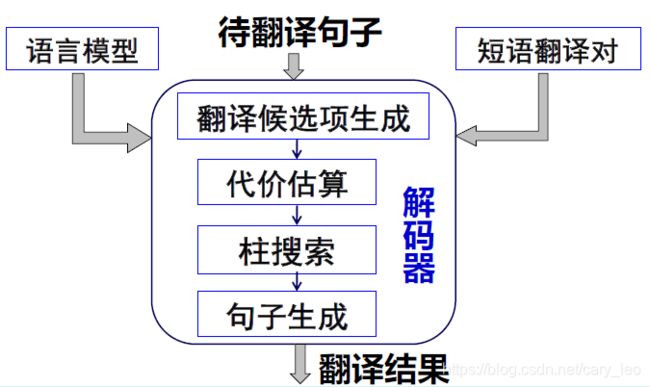
- 翻译候选生成
- 根据测试句子,搜索短语翻译规则表
- 代价估算
- S c o r e = 已 翻 译 代 价 + 未 翻 译 代 价 Score = 已翻译代价 + 未翻译代价 Score=已翻译代价+未翻译代价
- 已翻译代价:已翻译词的模型概率
- 未翻译代价:最大概率或其他因素
- 最大概率P102: T P ( f s t a r t e n d ) = max ∑ λ i log ( p i ( e ∣ f ) ) TP(f_{start}^{end}) = \max \sum \lambda_i \log (p_i(e|f)) TP(fstartend)=max∑λilog(pi(e∣f))
- 柱搜索
- 给定一个输入句子,生成对应的短语序列,每个短语对应一组翻译候选,短语序列按从左到右的顺序或目标短语生成的先后顺序搜索最可能的翻译假设(hypothesis)
- 排序:根据当前状态下被翻译的源语言单词的个数,将翻译假设放入不同的堆栈
- 避免栈内元素过多,采用合适的剪枝策略(翻译阈值、柱容量、观察分值)
- 译文生成
- 从最后一个栈中找到概率最大的Hypothesis,根据其指向父亲节点的指针向前回溯
- 可以产生n-best 翻译结果
- 翻译候选生成
-
-
基于短语的SMT系统实现

-
统计机器翻译
神经机器翻译
- 统计机器翻译的优势
- 可解释性高
- 模块随便加
- 错误易追踪
- 统计机器翻译的缺陷
- 数据稀疏(无对应短语翻译规则,退化到词的翻译)
- 复杂结构无能为力(长难句,短语顺序跳转非常复杂)
- 强烈依赖先验知识
- 神经机器翻译:连续分布式表示方法
- 编码网络——分布式语义表示——解码网络
- 向量映射——双向编码网络——注意力机制——解码网络——概率采样
- 循环神经网络
- 输入: t − 1 t - 1 t−1时刻历史 h t − 1 h_{t-1} ht−1与 t t t时刻单词输入 w t w_t wt
- 输出: t t t时刻历史 h t h_{t} ht与 t + 1 t + 1 t+1时刻单词输入概率 y t y_t yt
- 编码: h t = tanh ( U s L ( w t ) + W s h t − 1 ) h_t = \tanh (U_s L(w_t) + W_s h_{t - 1}) ht=tanh(UsL(wt)+Wsht−1), L ( w t ) L(w_t) L(wt)为词嵌入编码,随机初始化,0时刻历史置0,每个时刻输入对应时刻的词
- 解码: h t = tanh ( U t L ( w t ) + W t h t − 1 ) h_t = \tanh (U_t L(w_t) + W_t h_{t - 1}) ht=tanh(UtL(wt)+Wtht−1),0时刻历史来自源语言编码过程的最终历史,去归一化概率的最大者为当前时刻的输出,同时作为下一步的输入
- 训练时,解码阶段使用参照译文作为输入;测试时,使用前一时刻的最大采样作为输入
- 计算单元:LSTM
- 源端表示问题:一个实数向量无法表示源语言句子的完整语义
- 注意力机制:过去所有的历史向量 α t \alpha_t αt加权获得注意力上下文向量 c t c_t ct
- 与历史信息综合得到当前时刻的概率分布
- 不同时刻产生的注意力权重不同,专注于不同的历史信息上下文
- 深层次语义提取
- 多层RNN
- 双向RNN编码(解码时只能从左到右)
- 变革
- CNMT:基于CNN的翻译模型
- padding + 窗口卷积
- 不断卷积提取深层次语义——源语言编码
- 解码部分,已生成部分(也卷积处理)与源编码内容综合产生下一个表示
- 效率更高,可以多层
- Transfomer:Google第二代纯注意力机制网络
- 自注意力机制:每一个词和所有词比较,得到注意力权重(已生成部分同样处理)
- 编码器内部自注意力机制: Attention ( q , K , V ) = softmax ( q K ⊤ d k ) V \operatorname{Attention}(q, K, V) = \operatorname{softmax}(\frac{qK^\top}{\sqrt{d_k}}) V Attention(q,K,V)=softmax(dkqK⊤)V
- 解码器内部自注意力机制,由于生成顺序限制,只能和前侧已生成内容计算自注意力权重
- 编码-解码跨自注意力机制
- 产生的输出作为下一个时刻的输入
- 源端双向编码,目标端单项编码
- 相对来说比RNN实现更加高效(Transformer O ( n 2 d ) O(n^2 d) O(n2d),RNN O ( n d 2 ) O(n d^2) O(nd2))
- CNMT:基于CNN的翻译模型
- 难题:
- 缺乏可解释性
- 难以利用先验知识、相关知识
- 训练、测试复杂度高
- 领域、场景迁移性差
系统融合
- 多翻译引擎集成策略

-
系统融合方法
-
句子级系统融合
- 同一源语言句子,利用最小贝叶斯风险解码或重打分方法比较多个机器翻译系统输出,将最优翻译结果作为最终一致翻译结果
- E m b r = arg min Y ′ R ( Y ′ ) = arg min Y ′ ∑ Y P ( Y ∣ X ) L ( Y , Y ′ ) E_{mbr} = \arg\min_{Y^\prime} R(Y^\prime) = \arg\min_{Y^\prime} \sum_Y P(Y | X) L(Y, Y^\prime) Embr=argminY′R(Y′)=argminY′∑YP(Y∣X)L(Y,Y′)
- L ( Y , Y ′ ) L(Y, Y^\prime) L(Y,Y′)代表两个译文的相似度,若其二者越相似,其相似度(距离)值最小,代表其最“大众化”,选择其的平均风险最小
-
短语级系统融合
- 利用多个翻译系统的输出结果,重新抽取短语翻译规则集合(对应关系),并利用新的短语翻译规则进行重新解码
-
词语级系统融合
-
首先将多个翻译系统的译文输出进行词语对齐,构建一个混淆网络,对混淆网络中的每个位置的候选词进行置信度估计,最后进行混淆网络解码

-
-
基于深度学习的系统融合
- 首先将多个翻译系统译文进行编码,然后采用层次注意机制模型预测每个时刻目标语言输出
- 底层注意机制
- 决定该时刻更关注哪个源语言片段
- 第 k k k个系统第 j j j个输出对应的上下文: c j k = ∑ i m α j i k h i c_{jk} = \sum_i^m \alpha_{ji}^k h_i cjk=∑imαjikhi
- α j i k = exp ( e j i ) ∑ l m exp ( e j l ) \alpha_{ji}^k = \frac {\exp(e_{ji})}{\sum_l^m \exp(e_{jl})} αjik=∑lmexp(ejl)exp(eji)
- e j i = v a ⊤ tanh ( W a s ~ j − 1 + U a h i ) e_{ji} = v_a^\top \tanh (W_a \tilde s_{j - 1} + U_a h_i) eji=va⊤tanh(Was~j−1+Uahi)
- 上层注意机制:决定该时刻更依赖哪个系统的输出
- c j = ∑ k K = β j k c j k c_j = \sum_k^K = \beta_jk c_jk cj=∑kK=βjkcjk
- β j k = exp ( s ~ j − 1 ) c j k ∑ k ′ exp ( s ~ j − 1 ) c j k ′ \beta_{jk} = \frac {\exp(\tilde s_{j - 1}) c_{jk}}{\sum_{k^\prime}\exp(\tilde s_{j - 1}) c_{jk^\prime}} βjk=∑k′exp(s~j−1)cjk′exp(s~j−1)cjk
-
译文质量评估
- 主观评测
- 流畅度(语句流畅程度)
- 充分性(信息表达程度)
- 语义保持性(语义一致)
- 客观评测
- 句子错误率:与GT不完全相同的句子占全部译文的比例——不可行
- 单词错误率mWER:分别计算译文与每个GT的参考距离,以最短为评分依据,进行归一化处理
- 与位置无关的单词错误率mPER:不考虑单词在句子中的顺序
- METEOR:与GT词对齐,计算词汇完全匹配、词干匹配、同义词匹配等各种情况的准确率、召回率和F平均值
- F 10 = 10 P R R + 9 P F_{10} = \frac {10PR}{R + 9P} F10=R+9P10PR
- S c o r e = F ( 1 − P e n a l t y ) Score = F (1 - Penalty) Score=F(1−Penalty)
- P e n a l t y = 0.5 ( # c h u n k s # u n i g r a m s _ m a t c h e d ) Penalty = 0.5 \left(\frac{\#chunks}{\#unigrams\_matched}\right) Penalty=0.5(#unigrams_matched#chunks)
- # c h u n k s \#chunks #chunks指系统译文中所有被映射到参考译文中一元文法可能构成的语块的个数(连续匹配的语块个数)
- # u n i g r a m s _ m a t c h e d \#unigrams\_matched #unigrams_matched只所有匹配的一元文法的个数
- 不区分大小写,分值越大越好
- BLEU:将机器翻译候选译文与多个参考译文相比较,越接近正确率越高
- 统计同时出现在系统译文和参考译文中的n元词的个数
- 把匹配到GT的n元词的数目除以系统译文的n元词数目,得到评测结果
- 对一元文法出现次数过多导致过分精准的修正
- 记参考译文中最大出现次数 A m a x A_{max} Amax
- 记系统译文该词出现总次数 B m a x B_{max} Bmax
- 分子取值为 Count c l i p ( u n i g r a m ) = min { A m a x , B m a x } \operatorname{Count}_{clip} (unigram) = \min \{A_{max}, B_{max}\} Countclip(unigram)=min{Amax,Bmax}
- 精确度:取所有候选系统译文中的n-gram匹配个数和总次数的微观平均(避免某个句子n-gram精确度出现0的情况)
- P n = ∑ C ∑ n g r a m Count c l i p ( n g r a m ) ∑ C ∑ n g r a m Count ( n g r a m ) P_n = \frac{\sum_C \sum_{ngram} \operatorname{Count}_{clip} (ngram)}{\sum_C \sum_{ngram} \operatorname{Count} (ngram)} Pn=∑C∑ngramCount(ngram)∑C∑ngramCountclip(ngram)
- n值增加,匹配精度指数级下降——对数加权平均,相当于精度的几何平均,最大n取4
- 译文过段的问题——长度惩罚项
- B L E U = B P ⋅ exp ( ∑ n w n log p n ) BLEU = BP \cdot \exp(\sum_n w_n \log p_n) BLEU=BP⋅exp(∑nwnlogpn)
- B P BP BP为惩罚项,当 c ≤ r c \le r c≤r时, B P = e ( 1 − r / c ) BP = e^{(1 - r / c)} BP=e(1−r/c)
- NIST:出现较少的ngram更加重要,权重应该更大
- Info ( w 1 … w n ) = log 2 ( Num ( w 1 … w n − 1 ) Num ( w 1 … w n ) ) \operatorname{Info}(w_1 \dots w_n) = \log_2 \left( \frac{\operatorname{Num}(w_1 \dots w_{n - 1})}{\operatorname{Num}(w_1 \dots w_{n})}\right) Info(w1…wn)=log2(Num(w1…wn)Num(w1…wn−1))
- F-ratio:不同系统之间的得分偏差除以某一系统本身的得分偏差
- S c o r e = ∑ n { ∑ Info ( # n g r a m s _ c o o c c u r ) / # n g r a m } ⋅ exp { β log 2 [ min ( L s y s L ˉ r e g , 1 ) ] } Score = \sum_n \left\{ \sum \operatorname{Info}(\#ngrams\_cooccur) / \#ngram \right\} \cdot \exp \left\{\beta\log^2 \left[\min \left( \frac {L_{sys}}{\bar L_{reg}}, 1\right) \right] \right\} Score=∑n{∑Info(#ngrams_cooccur)/#ngram}⋅exp{βlog2[min(LˉregLsys,1)]}
- L ˉ r e g \bar L_{reg} Lˉreg为参考译文句子的平均长度, L s y s L_{sys} Lsys为系统译文的长度
- β \beta β为经验值一般取0.5, N N N一般取5
- 越大越好
- TER、GTM等
- 对评测方法的评测(ranking等)
- 译文错误
- 模型错误:概率最大结果不正确
- 搜索错误:找不到概率最大结果
语音翻译
-
语音翻译:用计算机实现持不同语言的说话人之间话语翻译的过程
- 一般又称为口语翻译或口语对话翻译
- 里程碑:英日对话系统
-
基本原理

- V2T:语音识别
- T2T:语言理解与翻译
- T2V:语音和车工
-
口语翻译特点
- 系统工作环境复杂(噪声、非语声、停顿、无边界、口语、集外词)
- 语音识别困难很大
- 翻译模块面对的是复杂多变的口语语句(冗余、省略、颠倒、错误)
- 合成语音的众多要素
- 系统尚无法有效地获得和利用对话过程中的非语言信息——意图理解
-
系统实现方法
-
需要解决的问题
- 噪声或冗余词的识别和过滤
- 人名等实体识别和翻译
- 语序调整
-
级联方法
- 语音识别-机器翻译-语音合成

-
端到端方法

- 现有技术:源语言文本 -》 目标语言文本、源语言语音 -》 目标语言语音
- 问题:缺少大量的语音-翻译平行语料
- 解决方案:源语言语音 -》 目标语言文本,编解码器共享
-
机器同传
-
-
现状
- 限定领域
- 词汇量基本没有限制
- 自然口语
- 多语言双向翻译
- 多方法、多策略结合
-
问题
- 口语的声学特性分析不够,语音识别的鲁棒性差
- 口语的语言学特性有待于深入研究,非规范语言现象的处理能力差,歧义消解能力差,解析机制的鲁棒性和正确率都有待于进一步提高
- 翻译方法不够奏效,译文质量差
- 对话情景知识的表示和利用,多媒体、多模态集成
翻译技术有待于深入研究