pytorch逐行搭建CNN系列(一)AlexNet
一 开天辟地
- 提出了ReLU激活函数,一般神经元的激活函数会选择sigmoid函数或者tanh函数,实验表明用ReLU比tanh快6倍。
- 成功使用Dropout机制
- 使用了重叠的最大池化(Max Pooling)。此前的CNN通常使用平均池化,而AlexNet全部使用最大池化,成功避免了平均池化带来的模糊化效果
- 提出LRN(局部响应归一化)
- 使用GPU加速训练
- 使用了数据增强策略(Data Augmentation)
【注】 AleNet是真正意义上的第一个深度卷积神经网络,是后期系列CNN的鼻祖,在此留下双膝!
二 曲径通幽
首先请明确,该网络共有8层(5个卷积层 + 3个全连接层),如下图所示:
———————————————————————————————————————————
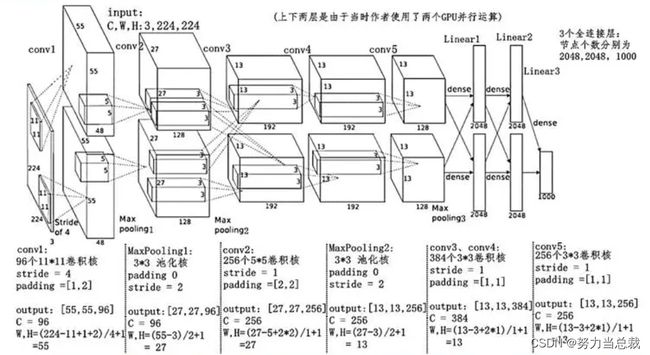
【注】上图是抄袭别人的,没有找到作者,在此鸣谢!
接下来对每一层进行梳理:
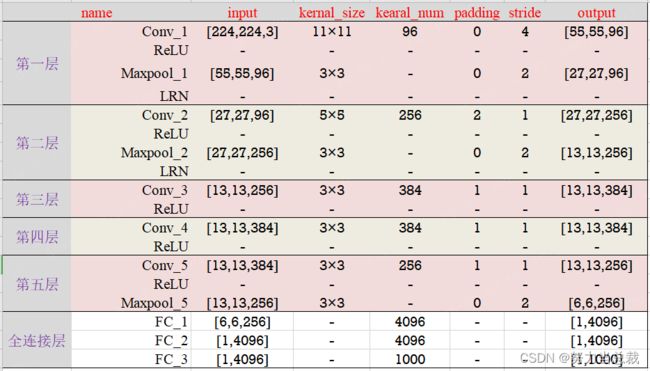
【注】股票连亏20多个交易日,亏麻了……专注力不太行了,上表中的参数可能在写的时候有手误,抱歉!
1-0 卷积层
输入图像:227*227*3
【图像的长*宽*通道数,实际与论文中示意图不一致,论文中长宽为224*224】
卷 积 核:
尺寸信息:11*11*3
【滑动窗口/卷积核的长*宽*通道数,其中通道数默认与上一层的输入通道数一致】
数量: 96
【一般结合GPU硬件的配置,按照16的倍数递增】
步 长:stride= 4
填 充 值:padding = 0
输出特征图:55*55*96
【特征图尺寸计算公式:(图像尺寸-卷积核尺寸 + 2*填充值)/步长+1】
【即 (227-11 + 2*0)/4+1 = 55 】
【96 为通道数,由该卷积层的卷积核数量决定 】
参数量:(11x11x3+1)x96=34944
【11x11x3为卷积核,1为偏置参数,96为卷积核个数】
1-1 激活函数
ReLU
1-2 池化层
输入特征图:55*55*96
池 化 核:3*3*1
步 长: stride = 2
填 充 值: padding = 0
输出特征图:27*27*96
【特征图尺寸计算公式:(图像尺寸-池化核尺寸 + 2*填充值)/步长+1】
【即 (55-3 + 2*0)/2+1 = 27 】
【96 为通道数,池化操作只改变输入特征图的尺寸大小,不改变通道数 】
1-3 归一化
LRN(Local Response Normalization)
【实验确实证明它可以提高模型的泛化能力,但是提升的很少,以至于后面不再使用】
———————————————————————————————————————————
2-0 卷积层
输入特征图:27*27*96
卷 积 核:
尺寸信息:5*5*48
【通道数默认与上一层的输入通道数一致,故应该是96,但作者将原始特征图分为两组数据在双GPU中进行训练,故通道数为96/2 = 48】
数量: 256
步 长:stride= 1
填 充 值:padding = 2
输出特征图:27*27*256
【即 (27-5 + 2*2)/1+1 = 27 】
参数量:(5x5x96+1)x256=614656
2-1 激活函数
ReLU
2-2 池化层
输入特征图:27*27*256
池 化 核:3*3*1
步 长: stride = 2
填 充 值: padding = 0
输出特征图:13*13*256
【即 (27-3 + 2*0)/2+1 = 13 】
2-3 归一化
LRN
———————————————————————————————————————————
3-0 卷积层
输入特征图:13*13*256
卷 积 核:
尺寸信息:3*3*256
数量: 384
步 长:stride= 1
填 充 值:padding = 1
输出特征图:13*13*384
【即 (13-3+ 2*1)/1+1 = 13 】
参数量:(3x3x256+1)x384=885120
3-1 激活函数
ReLU
———————————————————————————————————————————
4-0 卷积层
输入特征图:13*13*384
卷 积 核:
尺寸信息:3*3*384
数量: 384
步 长:stride= 1
填 充 值:padding = 1
输出特征图:13*13*384
【即 (13-3+ 2*1)/1+1 = 13 】
参数量:(3x3x192+1)x192x2=663936
4-1 激活函数
ReLU
———————————————————————————————————————————
5-0 卷积层
输入特征图:13*13*384
卷 积 核:
尺寸信息:3*3*384
数量: 256
步 长:stride= 1
填 充 值:padding = 1
输出特征图:13*13*256
【即 (13-3+ 2*1)/1+1 = 13 】
参数量:(3x3x192+1)x128x2=442624
5-1 激活函数
ReLU
5-2 池化层
输入特征图:13*13*256
池 化 核:3*3*1
步 长: stride = 2
填 充 值: padding = 0
输出特征图:6*6*256
【即 (13-3 + 2*0)/2+1 = 6 】
———————————————————————————————————————————
6-0 全连接层
输入特征图:6*6*256
卷 积 核:
尺寸信息:6*6*256
数量: 4096
步 长:stride= 0
填 充 值:padding = 0
输出特征图:1*1*4096
【即 (6-6+ 2*0)/1+1 = 1 】
参数量:(6x6x256+1)x4096=37752832
6-1 激活函数
ReLU
6-2 Dropout
【Dropout是一种正则方法,能够有效缓解模型的过拟合问题,从而使得训练更深更宽的网络成为可能。当丢失率为0.5 时,Dropout会有最强的正则化效果】
———————————————————————————————————————————
7-0 全连接层
输入特征图:1*1*4096
参数量:(4096+1)x4096=16781312
7-1 激活函数
ReLU
7-2 Dropout
输出特征图:1*1*4096
———————————————————————————————————————————
8-0 输出层
输入特征图:1*1*4096
参数量:1000x4096=4096000
8-1 分类映射
Softmax:将输入映射为0-1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。也就是说,分类问题是一个非黑即白的场景,要么是A,要么是B,要么是C,但是我们想知道更多的信息,于是通过softmax函数输出是A的概率(假设是0.88),是B的概率(假设是0.08),是C的概率(假设是0.01)。
三 纸上得来终觉浅 绝知此事要躬行
【注】比起粘贴和复制,手巧代码更助于人的成长,但也会牺牲约会时间……
1 CIAFR10_数据集加载
import torchvision
import torchvision.transforms as transforms
batchSize = 128 # 该参数根据计算机性能可修改
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 将图像的像素值归一化到[-1,1]之间
# Compose将多个transforms的操作整合在一起
data_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize()])
trainset = torchvision.datasets.CIFAR10(root='./Cifar-10',
train=True, download=True, transform=data_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batchSize, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./Cifar-10',
train=False, download=True, transform=data_transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batchSize, shuffle=False)
2 模型搭建
import torch
import torch.nn as nn
import torch.functional as F
class AlexNet(nn.Module):
def __init__(self, in_channels =1, num_classes=1000):
# 针对输入图像的不同通道数和类别数在此定义了两个参数:in_channels, num_classes 在不同应用场景中可供修改。
super(AlexNet,self).__init__()
# 第一层
self.c1=nn.Conv2d(in_channels=in_channels,out_channels=96,kernel_size=11,stride=4,padding=2)
self.a1=nn.ReLU(inplace=True)
self.p1=nn.MaxPool2d(kernel_size=3,stride=2)
self.l1 = nn.LocalResponseNorm(size=96, alpha=0.0001, beta=0.75, k=1.0)
# 第二层
self.c2=nn.Conv2d(96,256,5,stride=1,padding=2)
self.a2=nn.ReLU(inplace=True)
self.p2=nn.MaxPool2d(kernel_size=3,stride=2)
self.l2 = nn.LocalResponseNorm(size=256, alpha=0.0001, beta=0.75, k=1.0)
# 第三层
self.c3=nn.Conv2d(256,384,3,stride=1,padding=1)
self.a3=nn.ReLU(inplace=True)
# 第四层
self.c4=nn.Conv2d(384,384,3,stride=1,padding=1)
self.a4=nn.ReLU(inplace=True)
# 第五层
self.c5=nn.Conv2d(384,256,3,stride=1,padding=1)
self.a5=nn.ReLU(inplace=True)
self.p5 = nn.MaxPool2d(kernel_size=3, stride=2)
# 第六层
self.fc1_d=nn.Dropout(p=0.5)
self.fc1=nn.Linear(256*6*6,2048)
self.fc1_a=nn.ReLU(inplace=True)
# 第七层
self.fc2_d=nn.Dropout(p=0.5)
self.fc2=nn.Linear(2048,2048)
self.fc2_a=nn.ReLU(inplace=True)
# 第八层
self.fc3=nn.Linear(2048,num_classes)
# 定义了前向传播的过程,描述各层之间的连接关系。
def forward(self,x):
x = self.c1(x)
x = self.a1(x)
x = self.p1(x)
x = self.l1(x)
x = self.c2(x)
x = self.a2(x)
x = self.p2(x)
x = self.l2(x)
x = self.c3(x)
x = self.a3(x)
x = self.c4(x)
x = self.a4(x)
x = self.c5(x)
x = self.a5(x)
x = self.p5(x)
# 将张量(多维数组)平坦化处理
x=torch.flatten(x,start_dim=1)
x=self.fc1_d(x)
x = self.fc1(x)
x = self.fc1_a(x)
x=self.fc2_d(x)
x = self.fc2(x)
x = self.fc2_a(x)
x=self.fc3(x)
return x
if __name__ == '__main__':
# 从区间[0, 1)的均匀分布中抽取的一组随机数,此处为四维张量,对模型结构进行验证。
x = torch.rand([1, 3, 224, 224])
model = AlexNet(in_channels =3, num_classes=1000)
y = model(x)
3 模型训练
from torch.optim import lr_scheduler
from tqdm import tqdm
# 优先调用 GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 超参数设置
n_epochs = 100
in_channels = 3
num_classes = 10
learning_rate = 0.0001 #学习率,优化器迭代的步长
momentum = 0.9 # 动量因子,用来矫正优化率,可选参数
# 实例化模型
model = AlexNet(in_channels = in_channels, num_classes = num_classes)
model = model.to(device)
# 定义损失函数(交叉熵损失)
criterion = torch.nn.CrossEntropyLoss()
# 定义优化器(随机梯度下降法)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, momentum = momentum)
# 动态调整学习率:每隔10轮变为原来的0.5。
# 其中StepLR()用于调整学习率,一般情况下会设置随着epoch的增大而逐渐减小,从而达到更好的训练效果。
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 开始训练模型
for epoch in range(n_epochs):
running_loss = 0.0
running_correct = 0
print("Epoch {}/{}".format(epoch, n_epochs))
print("-"*10)
# 读取数据
# for data in tqdm(trainloader): # 可自动生成进度条
for data in trainloader:
X_train, y_train = data
X_train, y_train = X_train.cuda(), y_train.cuda()
# 计算训练值
outputs = model(X_train)
# torch.max(input, dim)函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引
_,pred = torch.max(outputs.data, 1)
# 计算观测值(label)与训练值的损失函数
loss = criterion(outputs, y_train)
###————————————————————————————————————————————————————————————
# 反向传播部分
# 梯度归零
optimizer.zero_grad()
# 反向传播,计算当前梯度
loss.backward()
# 根据梯度更新网络参数
optimizer.step()
# item()得到元素张量的元素值
running_loss += loss.data.item()
running_correct += torch.sum(pred == y_train.data)
# 验证模型
testing_correct = 0
for data in testloader:
X_test, y_test = data
X_test, y_test = X_test.cuda(), y_test.cuda()
# eval():如果模型中有Batch Normalization和Dropout,则不启用,以防改变权值
# model.eval()
# 进行预测
outputs = model(X_test)
_, pred = torch.max(outputs.data, 1)
testing_correct += torch.sum(pred == y_test.data)
print("Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Accuracy is:{:.4f}".format(torch.true_divide(running_loss, len(trainset)),
torch.true_divide(100*running_correct, len(trainset)),
torch.true_divide(100*testing_correct, len(testset))))
torch.save(model.state_dict(), "model_parameter.pkl")
4 模型预测
【注】过几天更,忙着盯盘……
5 完整代码
import torch
import torch.nn as nn
import torch.functional as F
import torchvision
import torchvision.transforms as transforms
import tqdm
from torch.optim import lr_scheduler
class AlexNet(nn.Module):
def __init__(self, in_channels =1, num_classes=1000):
super(AlexNet,self).__init__()
self.c1=nn.Conv2d(in_channels=in_channels,out_channels=96,kernel_size=11,stride=4,padding=2)
self.a1=nn.ReLU(inplace=True)
self.p1=nn.MaxPool2d(kernel_size=3,stride=2)
self.l1 = nn.LocalResponseNorm(size=96, alpha=0.0001, beta=0.75, k=1.0)
self.c2=nn.Conv2d(96,256,5,stride=1,padding=2)
self.a2=nn.ReLU(inplace=True)
self.p2=nn.MaxPool2d(kernel_size=3,stride=2)
self.l2 = nn.LocalResponseNorm(size=256, alpha=0.0001, beta=0.75, k=1.0)
self.c3=nn.Conv2d(256,384,3,stride=1,padding=1)
self.a3=nn.ReLU(inplace=True)
self.c4=nn.Conv2d(384,384,3,stride=1,padding=1)
self.a4=nn.ReLU(inplace=True)
self.c5=nn.Conv2d(384,256,3,stride=1,padding=1)
self.a5=nn.ReLU(inplace=True)
self.p5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.fc1_d=nn.Dropout(p=0.5)
self.fc1=nn.Linear(256*6*6,2048)
self.fc1_a=nn.ReLU(inplace=True)
self.fc2_d=nn.Dropout(p=0.5)
self.fc2=nn.Linear(2048,2048)
self.fc2_a=nn.ReLU(inplace=True)
self.fc3=nn.Linear(2048,num_classes)
def forward(self,x):
x = self.c1(x)
x = self.a1(x)
x = self.p1(x)
x = self.l1(x)
x = self.c2(x)
x = self.a2(x)
x = self.p2(x)
x = self.l2(x)
x = self.c3(x)
x = self.a3(x)
x = self.c4(x)
x = self.a4(x)
x = self.c5(x)
x = self.a5(x)
x = self.p5(x)
x=torch.flatten(x,start_dim=1)
x=self.fc1_d(x)
x = self.fc1(x)
x = self.fc1_a(x)
x=self.fc2_d(x)
x = self.fc2(x)
x = self.fc2_a(x)
x=self.fc3(x)
return x
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batchSize = 128
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
data_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize()])
trainset = torchvision.datasets.CIFAR10(root='./Cifar-10',
train=True, download=True, transform=data_transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batchSize, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./Cifar-10',
train=False, download=True, transform=data_transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batchSize, shuffle=False)
model = AlexNet(in_channels = 3, num_classes = 10).to(device)
n_epochs = 40
num_classes = 10
learning_rate = 0.0001
momentum = 0.9
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
for epoch in range(n_epochs):
print("Epoch {}/{}".format(epoch, n_epochs))
print("-"*10)
running_loss = 0.0
running_correct = 0
for data in trainloader:
X_train, y_train = data
X_train, y_train = X_train.cuda(), y_train.cuda()
outputs = model(X_train)
loss = criterion(outputs, y_train)
_,pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.data.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
for data in testloader:
X_test, y_test = data
X_test, y_test = X_test.cuda(), y_test.cuda()
outputs = model(X_test)
_, pred = torch.max(outputs.data, 1)
testing_correct += torch.sum(pred == y_test.data)
print("Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Accuracy is:{:.4f}".format(torch.true_divide(running_loss, len(trainset)),
torch.true_divide(100*running_correct, len(trainset)),
torch.true_divide(100*testing_correct, len(testset))))
torch.save(model.state_dict(), "model_parameter.pkl")