MNIST手写数字识别实战演练
一、准备工作
1.安装tqdm
Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。
- 可以在命令行使用pip命令安装,也可以在pycharm中安装,按图中步骤,点一下cuda库,然后在搜索框 搜索tqdm直接点击install即可。

- 安装好之后测试一下:
import time
from tqdm import tqdm#导入tqdm
a = 10
b = range(a)#从0到10
c = tqdm(b, total=a)#使用tqdm产生一个进度条,并且会实时的推算剩余时间
for i in c:
time.sleep(1)#使用for循环迭代,把进度条打印出来了,
运行结果:
0%| | 0/10 [00:002.计算数据标准化参数
使用官方提供的:均值mean = 0.1307,标准差std = 0.3081
3.模型保存与优化器保存
torch.save(model.state_ldict(),path)#模型保存
torch.save(optimizer.state_dict(), path)#优化器保存
#模型加载
model.loade_state_dict(torch.load(path))
optimizer.load_state_dict(torch.load(path))
4.深度学习torch三件套
(1)梯度置0:optimizer.zero_grad()
#传播:前向传播,把原来的图像通过transfroms翻译之后作为参数传入,给我们返回一个模型计算出来的值,然后通过这个值与标签进行比对,继而得到损失值
#然后使用损失进行反向传播,再进行单次优化
(2)反向传播:loss.backward()
#梯度置0就是把loss关于weigh的导数置为0,都不需要与其他的mini_batch混合起来计算
当网络参数进行反馈的时候,梯度是一个累加的过程,而不是可替代的;但是在处理每一个batch_size的时候都是累加的,但是我们并不希望他是累加的,我们希望每一次都是独立的。如果累加的话酒瓯相当于增加了batch_size的尺寸了,这是我们不需要的,所以在进行每一次训练而不是每一轮都需要进行梯度置0.
(3)单次优化:optimizer.step
#梯度置0:optimizer.zero_grad()
#反向传播:loss.backward()
#单次优化:optimizer.step二、训练
1.MNIST手写数字识别训练流程:
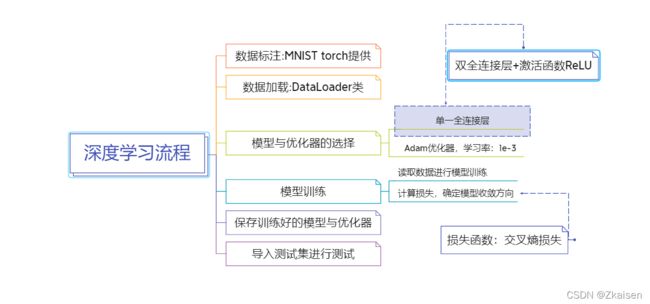
2.交叉熵损失:
http://zhuanlan.zhihu.com/p/35709485
3.代码:
(1)数据源标注与图像预处理
from torchvision.datasets import MNIST
from torchvision import transforms
#图像处理
my_transforms = transforms.Compose(
[transforms.PILToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))#图像标准化处理
]
)
#获取数据源
mnist_train = MNIST(root="../MNIST_data", train=True, download=True, transform=my_transforms)(2)数据加载
#数据加载
from torch.utils.data import DataLoader#导入数据加载器
dataloader = DataLoader(mnist_train, batch_size=8, shuffle=True)
for (images, labels) in dataloader:
pass(3)模型选择
from torch import nn
class MnistModel(nn.Module):
def __init__(self):#继承__init__方法
super(MnistModel, self).__init__()
self.fc1 = nn.Linear(1*28*28, 10)#最初传入的图片的像素点是1*28*28的,最后我们要收敛成10个结果
def forward(self, image):#继承前向传播的方法
image_viwed = image.view(-1, 1*28*28)#此处需要拍平
out = self.fc1(image_viwed)
return out
#实例化模型
model = MnistModel()(4)优化器选择:Adam
from torch import optim#导入优化器
optim.Adam(model.parameters(), lr=1e-4)(5)损失函数
#损失函数
loss_functon = nn.CrossEntropyLoss()(6)在dataloader上面套一个tqdm
dataloader = tqdm(dataloader, total=len(dataloader))(7)做一个循环
#循环可迭代对象
for (images, labels) in dataloader:(8)深度学习torch三件套
#梯度置零
optimizer.zero_grad()
#前向传播
output = model(images)
#计算损失
loss = loss_functon(output, labels)
#反向传播
loss.backward()
#优化器更新
optimizer.step()
(9)模型与优化器的保存
#保存模型
save(model.state_dict(), 'models/model.pkl')
save(optimizer.state_dict(), 'models/optimizer.pkl')
#save中第二个参数是保存路径'models/model.pkl'(10)运行代码完成第一轮epoch
运行结果:
0%| | 0/7500 [00:00(11)运行完成后,在当前保存路径下可以看到保存好的模型和优化器
三、测试观察训练效果
1.手写数字识别分类测试
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
from tqdm import tqdm
# from MNIST_train import test
import os#判断路径是否存在的模块
# import numpy as np
import torch
class MnistModel(nn.Module):
def __init__(self):#继承__init__方法
super(MnistModel, self).__init__()
self.fc1 = nn.Linear(1*28*28, 10)#最初传入的图片的像素点是1*28*28的,最后我们要收敛成10个结果
def forward(self, image):#继承前向传播的方法
image_viwed = image.view(-1, 1*28*28)#此处需要拍平
out = self.fc1(image_viwed)
return out
#实例化模型
model = MnistModel()
if os.path.exists('models/model.pkl'):
model.load_state_dict(torch.load('models/model.pkl'))
#损失函数
loss_functon = nn.CrossEntropyLoss()
#图像处理
my_transforms = transforms.Compose(
[transforms.ToTensor(),
#transforms.PILToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))#图像标准化处理
]
)
#获取数据源
mnist_train = MNIST(root="../MNIST_data", train=False, download=True, transform=my_transforms)
#数据加载
# from torch.utils.data import DataLoader#导入数据加载器
dataloader = DataLoader(mnist_train, batch_size=8, shuffle=True)
dataloader = tqdm(dataloader, total=len(dataloader))
model.eval()
with torch.no_grad():
for images, labels in dataloader:
#获取结果
output = model(images)
print(output)
exit()
#计算损失
loss = loss_functon(output, labels)
运行结果:
0%| | 0/1250 [00:002.获取每个分类中可能性最大的
model.eval()
with torch.no_grad():
for images, labels in dataloader:
#获取结果
output = model(images)
result = output.max(dim=1)#在dim=1的维度上面比较每一个列表里的十个数
print(result)
exit()
运行结果:
0%| | 0/1250 [00:003.获取最大可能的索引
for images, labels in dataloader:
#获取结果
output = model(images)
result = output.max(dim=1).indices#获取索引
print(result)#打印训练结果
print(labels)#打印标签
exit()
#计算损失
loss = loss_functon(output, labels)
#运行结果:
0%| | 0/1250 [00:004.比较结果与标签
print(result.eq(labels))#比较result与labels是否相等运行结果:
0%| | 0/1250 [00:005.求准确率,即均值
布尔类型不能直接求均值,需要使用强制类型转化吧布尔值转换为浮点类型
print(result.eq(labels).float().mean())#先转换成浮点类型再求均值
运行结果:
0%| | 0/1250 [00:006.item将元素取出来
print(result.eq(labels).float().mean().item())#把识别准确率取出来
运行结果:
1.0
0%| | 0/1250 [00:007.append方法把识别准确率保存下来
# from torchvision.datasets import MNIST
# from torchvision import transforms
# from torch.utils.data import DataLoader
# from torch import nn
# from torch import optim#导入优化器
# from tqdm import tqdm#导入tqdm
# from torch import save
# from torch import save, load
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
from tqdm import tqdm
# from MNIST_train import test
import os#判断路径是否存在的模块
import numpy as np
import torch
class MnistModel(nn.Module):
def __init__(self):#继承__init__方法
super(MnistModel, self).__init__()
self.fc1 = nn.Linear(1*28*28, 10)#最初传入的图片的像素点是1*28*28的,最后我们要收敛成10个结果
def forward(self, image):#继承前向传播的方法
image_viwed = image.view(-1, 1*28*28)#此处需要拍平
out = self.fc1(image_viwed)
return out
#实例化模型
model = MnistModel()
if os.path.exists('models/model.pkl'):
model.load_state_dict(torch.load('models/model.pkl'))
#损失函数
loss_functon = nn.CrossEntropyLoss()
#图像处理
my_transforms = transforms.Compose(
[transforms.ToTensor(),
#transforms.PILToTensor(),
transforms.Normalize(mean=(0.1307,), std=(0.3081,))#图像标准化处理
]
)
#获取数据源
mnist_train = MNIST(root="../MNIST_data", train=False, download=True, transform=my_transforms)
#数据加载
# from torch.utils.data import DataLoader#导入数据加载器
dataloader = DataLoader(mnist_train, batch_size=8, shuffle=True)
dataloader = tqdm(dataloader, total=len(dataloader))
succeed = []#保存准确率的列表
model.eval()
with torch.no_grad():
for images, labels in dataloader:
#获取结果
output = model(images)
result = output.max(dim=1).indices#获取索引
# print(result)#打印训练结果
# print(labels)#打印标签
# print(result.eq(labels))#比较result与labels是否相等
# print(result.eq(labels).float().mean())
# print(result.eq(labels).float().mean().item())#把识别准确率取出来
succeed.append(result.eq(labels).float().mean().item())
# exit()
#计算损失
loss = loss_functon(output, labels)
print('一轮的成功率', np.mean(succeed))
运行结果:
0%| | 0/1250 [00:00上述便是对手写数字识别的训练,那么如何进行多轮训练呢?