数据结构与算法在前端领域的应用
这是一个我即将做的一个《数据结构与算法在前端领域的应用》主题演讲的一个前菜。希望通过这个分享让大家认识到其实前端领域也有很多算法的,从而加深前端同学对算法的认识。如果大家对数据结构和算法感兴趣,欢迎关注我的个人公众号,或者入群和我交流,二维码在文章末尾。
关于我
我是一个对技术充满兴趣的程序员, 擅长前端工程化,前端性能优化,前端标准化等。
做过.net, 搞过Java,现在是一名前端工程师。
除了我的本职工作外,我会在开源社区进行一些输出和分享,GitHub 共计获得1.5W star。比较受欢迎的项目有leetcode题解 , 宇宙最强的前端面试指南 和我的第一本小书
为什么大家觉得算法没用
在我的职业生涯中,碰到很多非算法岗的研发同学吐槽“算法在实际业务中没什么用”, 甚至在面试官也问过我这个问题。我们姑且不来判断这句话正确与否,我们先来看下为什么大家会有这样的想法。
我发现很多人喜欢用冰山这个图来表示这种只看到总体的一小部分的情况。我也来借用一下这个创意。

根据我的经验,我们写的业务代码通常不到总包体的 5%, 下面是我以前做过的一个实际项目的代码分布。
$ du -sh node_modules # 429M
$ du -sh src # 7.7M大家可以拿自己的实际项目看一下,看是不是这样的。
其实不难看出业务代码在整个应用的比例是很小的,软件工程有一个至理名言,“软件开发的 90%的工作是由 10%的人完成的”, 这句话很对,那么剩下的 10 的工作却由剩下的 90%来完成。
因此我们感觉算法没用,是因为我们没用深入剩下的“90%” 很多场景我们接触不到,并且没有思考过,就很容易“井底之蛙”,到头来就变成“只会用别人造好的轮子组装代码”的“前端打字员”。
那剩下的 90% 究竟有哪些涉及到算法呢?是否可以举例说明呢?那接下来让我们来继续看一下。
前端中算法的应用场景都有哪些
说实话,这部分内容实在太多啦,为了让大家有一个直观的感受,我画了一个图。
图中黄色的代表我自己实现过。

这些都是前端开发过程的一些东西, 他们多多少少涉及到了数据结构和算法的知识
下面我们来简单分析一下。
VDOM
事实上 VDOM 就是一种数据结构,但是它并不是我们在《数据结构与算法》课程中学习到的一些现成的数据结构。
逻辑上 VDOM 就是用来抽象 DOM 的,底层上 VDOM 普遍实现是基于 hash table 这种数据结构的。
一个典型的 VDOM 可以是:
{
type: 'div',
props: {
name: 'lucifer'
},
children: [{
type: 'span',
props: {},
children: []
}]
}不难看出,VDOM 是一种递归的数据结构,因此使用递归的方式来处理是非常直观和容易的。
我上面提到了 VDOM 是 DOM 的抽象(ye, a new level of abstraction)。根据 VDOM 我们可以创建一个对应的真实 DOM。
如果我们只是做了这一层抽象的话,我们相当于引入了一种编程模式,即从 面向 DOM 编程,切换到面向 VDOM 编程,而现在 VDOM 又是由数据驱动的,因此 我们的编程模式切换到了“数据驱动”。
事实上,VDOM 部分还有一个 VDOM diff 算法,相信大家都听说过。关于 DOM diff 的算法,以及它是如何取舍和创新的,我之前在一个地方回答过,这里给一个链接地址: https://juejin.im/post/5d3d8cf15188256ac355a9f0
Hooks
Hooks 是 React16 添加的一个新功能, 它要解决的问题是状态逻辑复用。
Hooks 逻辑上解决了纯函数无法持久化状态的“问题”,从而拓宽了纯函数组件的 适用范围。
底层上 Hooks 使用数据来实现状态的对应关系,关于这部分可以参考我的[第一期]实现一个简化版的 React Hook - useState
Fiber
Fiber 也是 React16 添加的一个新功能。
事实上 Fiber 类似 VDOM,也是一个数据结构,而且同样也是一个递归的数据结构。
为了解决 React 之前一次全量更新的"问题", React 引入了 fiber 这种数据结构, 并重写了整个调和算法,并且划分了多个阶段。关于这部分内容,我只推荐一篇文章,Inside Fiber: in-depth overview of the new reconciliation algorithm in React
其实之前我的从零开始实现 React 系列教程 也欠了 fiber ?, 等我开心的时候补充上去哈。
Git
我之前写过一个 Git 终端(代码被我 rm -rf 啦)。这过程还是用到了很多数据结构和算法的, 我也学到了很多东西, 甚至 React16 新的调和算法也有 Git 思想。
很直观的,Git 在推送本地仓库到远程的时候会进行压缩,其实这里就用到了最小编辑距离算法。Leetcode 有一个题目72. Edit Distance, 官方难度 hard, Git 的算法要是这个算法的复杂版本。
另外 Git 其实很多存储文件,数据的时候也用到了特殊的数据结构,我在这里进行了详细的描述,感兴趣的可以去看看。
Webpack
Webpack 是众所周知的一个前端构建工具,我们可以用它做很多事情。至今在前端构建领域还是龙头老大 ? 的位置。
Webpack 中最核心的 tapable 是什么,是如何配合插件系统的?webpack 是如何对资源进行抽象的, webpack 是如何对依赖进行处理的?更复杂一点 Tree Shaking 如何做,分包怎么做, 加速打包怎么做。
其实 webpack 的执行过程是基于事件驱动的,tapable 提供了一系列钩子, 让 plugin 深入到这些过程之中去。听起来有点像事件总线,其实其中的设计思想和算法 细节要复杂和精妙很多。
关于这部分细节,我在我的从零实现一个 Webpack
之后会加入更多特性,比如 tapable
AST
AST(抽象语法树)是前端 编译(严格意义上是转义)的理论基础, 你如果想深入前端编译,就一定不能不会这个知识点。
和 AST 相似的,其实还有 CST,prettier 等格式化工具会用到, 有兴趣可以搜一下。
这个网站 可以让你对 AST 有一个直观的认识。
AST 厉害就厉害在它本身不涉及到任何语法,因此你只要编写相应的转义规则,就可以将任何语法转义到任何语法。这就是 babel, PostCSS, prettier, typescript 等的原理, 除此之外,还有很多应用场景,比如编辑器。
之前自己写过一个小型的生成 AST 的程序,源代码忘记放哪了。?
Browser History
像浏览器中的历史页面,移动端 webview 的 view stack, 都用到了 栈这种数据结构。
剩下的我就不一一说了。其实都是有很多数据结构和算法的影子的。
OK,说了那么多。这些都是“大牛”们做的事情,好像和我日常开发没关系啊。我只要用他们做好的东西,调用一下,一样可以完成我的日常工作啊。让我们带着这个问题继续往下看。
算法在日常开发中的应用都有哪些
大神: “你可以先这样,再这样,然后就会抽象为纯算法问题了。”
我: “哇,好厉害。”其实就是你没有掌握,或者“再思考”,以至于不能融汇贯通。
比如你可以用 vue 组件写一个递归,实现一些递归的功能,也是可以的, 但是大多数人都想不到。
接下来,我会举几个例子来说明“算法在日常开发中的应用”。注意,以下所有的例子均来自我的实际业务需求。
第一个例子 - 撤销与重做
业务描述
某一天,可(gai)爱(si)的产品提了一个需求,”我们的系统需要支持用户撤销和重做最近十次的操作。“

让我们来回忆一下纯函数。

纯函数有一个特性是给定输入,输出总是一样的。
关于函数式编程可以参考我之前的几篇文章和一个分享
我们对问题进行一些简化,假设我们的应用是纯粹的数据驱动,也就是说满足 纯的特性。

我们继续引入第二个知识点 - reducer.
reducer 是一个纯函数,函数签名为 (store1,action1)=>store2。即给定 state 和 action,一定会返回确定的新的 state。
本质上 reducer 是 reduce 的空间版本。
假设我们的应用初始 state 为 state1, 我们按照时间先后顺序分别发送了三个 action, action1, action2, action3。
我们用一个图来表示就是这样的:

运用简单的数据知识,我们不难推导出如下关系:

如果对这部分知识点还比较迷茫,可以看下我之前的一篇文章,从零实现一个 Redux
解决方案
基础知识铺垫完了,我们来看一下怎么解决这个问题。
第一种方案,我们可以将每次的store,即store1, store2, store3都存起来。比如我想回退到第二步,我们只需要将store2取出来,覆盖当前store,然后重新渲染即可。这种方案很直观,可以满足我们的业务需求。但是缺点也很明显,store在这里被存储了很多。每次发送一个action都会有一个新的store被存起来。当我们应用比较大的时候,或者用户触发了很多action的时候,会占据大量内存。实际场景中性能上我们很难接受。

第二种方案,有了上面的铺垫,我们发现, 事实上我们没必要存储所有的store。因为store可以被计算出来。因此我们只要存储action即可。比如我们要回退到第二步,我们拿出来store1,然后和action运算一次,得到store2, 然后将store2覆盖到当前的store即可。

这种做法,只需要存储一个store1, 以及若干个action。action相对于store来说要小很多。这是这种做法相比与上一种的优势。同时由于每次都需要从头(store1)开始计算, 因此是一种典型的“时间换空间”的优化手段。
实际上这种做法,我们可以进行小小的优化。比如我们设置多个snapshot, 然后我们就不必每次从头开始计算,而是算出最近的一个snapshot, 然后计算即可。无疑这种做法可以减少很多计算量,但是会增加空间占用。这是典型的“空间换时间”, 如果根据实际业务进行取舍是关键。
第三种方案,我们可以用树来表示我们的store。每次修改store,我们不是将整个store 销毁然后创建一个新的,而是重用可以重用的部分。
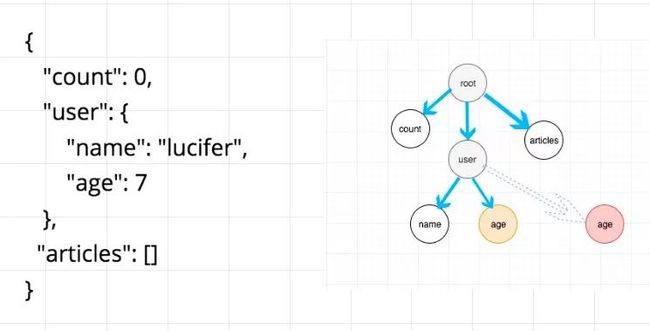
如图我要修改 store.user.age。我们只需要将root和user的引用进行修改,同时替换age节点即可。
如果大家对immutable研究比较深的话应该能发现,这其实就是immutable的原理
第二个例子 - 巨型Mapper的优化
业务描述
由于业务需要,我们需要在前端缓存一些HTTP请求。我们设计了如下的数据结构,其中key表示资源的URL, value会上次服务端的返回值。
现在我们的项目中已经有上千个接口,当接口多起来之后,缓存占用会比较大,我们如何对此进行优化?
注:我们的key中的前缀是有规律的,即有很多重复的数据在。返回值也有可能是有很多重复的。

这是一个典型的数据压缩算法。数据压缩算法有很多,我这里就不介绍了,大家可以自行了解一下。
对数据压缩算法感兴趣的,可以看下我之前写的游程编码和哈夫曼编码
第三个例子 - 实现自动联想功能
业务描述
现在很多输入框都带了自动联想的功能, 很多组件库也实现了自动填充组件。
现在需要你完成这个功能,你会怎么做?
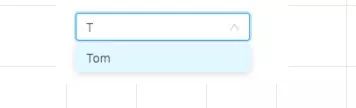
我们可以用前缀树,很高效的完成这个工作。

对这部分原理感兴趣的可以看下我的这个题解
第四个例子 - 相似度检测
业务描述
由于业务需要,我们需要对字符串进行相似度检测。对于相似度超过一定阀值的数据,我们认为它是同一个数据。

关于相似度检测,我们其实可以借助“最小编辑距离”算法。对于两个字符串a和b,如果a和b的编辑距离越小,我们认为越相似, 反之越不相似。特殊情况,如果编辑距离为0表示是相同的字符串, 相似度为100%。我们可以加入自己的计算因子,将相似度 离散在0 - 100%之间。
这部分的内容,我在介绍Git的时候介绍过了,这里不再重复。
其实我们可以进一步扩展一下,比如 对于一些无意义的词不计入统计范围,我们可以怎么做?
算法不好会怎么样
这恐怕是很多人最关心的问题。
我虽然知道了算法有用,但是我不会怎么办?会有什么样的影响呢?
这就回到了我们开头的问题,“为什么很多人觉得算法没用”。事实上,我们日常开发中真正用到算法的场景很少,大部分都被别人封装好了。即使真正需要用到一些算法,我们也可以通过一些“低劣”的手段完成,在很多对性能和质量要求 不高的业务场景都是没有问题的。这就是为什么“前端同学更加觉得算法没用”的原因之一。
那既然这么说,是不是真的算法就没用呢?或者说算法不好也不会怎么样了么?当然不是, 如果算法不好,会 很难创新和突破。想想如今前端框架,工具的演进,哪一个不是建立在 无数的算法之上。将视角聚焦到我们当下的业务上,如果算法不好,我们也同样很难让业务不断精进, 不断赋能业务。
React框架就是一个非常典型的例子,它的出现改变了传统的编程模式。Redux的作者,React团队现任领导者 dan 最近发表了一篇个人博客 Algebraic Effects for the Rest of Us这里面也有很多算法相关的东西,大家有兴趣的可以读读看。
另外我最近在做的一个 stack-visualizer,一个用于跟踪浏览器堆栈信息,以便更好地调试地工具, 这个也是和算法有关系的。
关注我
最近我重新整理了下自己的公众号,并且我还给他换了一个名字《脑洞前端》,它是一个帮助你打开大前端新世界大门的钥匙?,在这里你可以听到新奇的观点,看到一些技术尝新,还会收到系统性总结和思考。
我会尽量通过图的形式来阐述一些概念和逻辑,帮助大家快速理解,图解前端是我的目标。
之后我的文章同步到微信公众号 脑洞前端 ,您可以关注获取最新的文章,或者和我进行交流。

交流群
现在还是初级阶段,需要大家的意见和反馈,为了减少沟通成本,我组建了交流群。大家可以扫码进入
QQ 群

微信群

(由于微信的限制,100个人以上只能邀请加入, 你可以添加我的机器人回复“大前端”拉你进群)