Flink实时流处理开发入门指南
本文为Flink开发教程系列首篇文章,首发于微信公众号:码上观世界。
文章目录
-
Flink 的批和流
-
批处理示例
流处理示例
开发环境准备
-
PyFlink 安装
Flink 服务部署
再论流处理与批处理
-
物化视图(Materialized Views)
动态表(Dynamic Tables)
动态表定义
连续查询(Continuous Queries)
表转换为流
-
Append-only 流
Retract 流
upsert 流
结果持久化
常见问题
-
Queston0
Queston1
Queston2
Queston3
Queston4
Queston5
Queston6
Flink 的批和流
首先通过 Python 快速演示 Flink 中批处理和流处理的异同,以建立对 Flink 的初步认识。示例程序功能是从文件中读出 CSV 格式的单词数据(每行一个单词),然后做简单的分组计算,然后将结果保存到输出文件。
批处理示例
exec_env = ExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = BatchTableEnvironment.create(exec_env, t_config)
t_env.connect(FileSystem().path('/tmp/input.csv')) \
.with_format(OldCsv()
.field('word', DataTypes.STRING())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())) \
.create_temporary_table('mySource')
t_env.connect(FileSystem().path('/tmp/output/file_output')) \
.with_format(OldCsv()
.field_delimiter('\t')
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.create_temporary_table('mySink')
tab = t_env.from_path('mySource')
tab.group_by(tab.word) \
.select(tab.word, lit(1).count) \
.execute_insert('mySink').wait()
示例中通过 create_temporary_table 将文件输入数据命名为临时表 mySource,将文件输出数据命名为临时表 mySink,然后通过形如:
insert into mySink select word,count(1) from mySource group by mySink
的 SQL 形式计算输出,最后通过 execute_insert 触发任务的提交,wait 任务执行完成。
流处理示例
exec_env = StreamExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = StreamTableEnvironment.create(exec_env, t_config)
my_source_ddl = """
create table mySource (
word VARCHAR
) with (
'connector' = 'filesystem',
'format' = 'csv',
'path' = 'tmp/input.csv'
)
"""
my_sink_ddl = """
create table mySink (
word VARCHAR,
`count` BIGINT
) with (
'connector' = 'filesystem',
'format' = 'csv',
'path' = 'tmp/output/sql_output'
)
"""
t_env.execute_sql(my_source_ddl)
t_env.execute_sql(my_sink_ddl)
t_env.from_path('mySource').select('word, 1').insert_into('mySink')
t_env.execute("tutorial_job")
示例中通过 SQL 语法重写了批处理中的 API 语法调用,通过 execute_sql 来执行,然后通过形如 SQL 语法:
insert into mySink select word,1 from mySource
最后通过 insert_into 触发任务执行。
从上面两个示例中,可以看到两者的相同处理逻辑:从源端加载数据,然后经过变换处理,输出到目标端。用图示可以描述如下:

实际上,源端可以是内存数据集合(Collection)、数据库系统(包括 NOSQL)、文件系统(如 HDFS)、网络 Socket、消息队列(如 Kafka、RabbitMQ)等,目标端也可以是数据库系统、文件系统、或者消息队列等,变换除了示例中的分组统计,还可以是诸如过滤(filter)、映射(map)、聚合(如 keyBy)以及其他复杂的流的合并与分拆等。
两个示例中 API 虽有不同,但是仅仅是形式不同,本质上底层调用是一致的,批处理也可以使用这种 SQL 语法的 API 调用,我们需要关注的是两者的主要区别。
1. 执行环境
批处理使用:
BatchTableEnvironment.create(ExecutionEnvironment.get_execution_environment())
流处理使用:
StreamTableEnvironmentt.create(StreamExecutionEnvironment.get_execution_environment())
两种方式都是用方法 get_execution_environmen 获取执行环境,该方法根据程序启动方式的不同,创建不同的执行环境,比如通过 IDE 启动程序,会通过 createLocalEnvironment 创建本地执行环境。示例程序通过 python flink_demo_files.py 执行任务也会创建本地环境,也就是说对于快速演示学习,可以不用部署 Flink 服务。
2. 数据边界
虽然两种方式都是从文件中读取数据,对于确定的时刻,比如都一次性读取一批数据,两者的数据是相同的,而且是数量有限的,但是当文件本身的数据是不断地写入的话,该文件数据就是无界的,因此从数据的处理方式来看,流处理包含了批处理,批处理是流处理的一个特例。对于无限的数据,当确定时间段或者数据数量(即 Window)之后,对于固定时间段或者数据量的数据,就转化为常规的批处理。下图展示了无界数据流和有界数据流之间的关系。

3. 时间相关
对于无界数据流,数据是跟时间是强相关的,比如来源于 Kafka 消息队列的数据的产生时间(Event Time)、到达 Flink 系统的时间(Injestion Time)、以及流处理的时间(Process Time)。只有知道数据的时间,才能区分该数据是属于历史数据还是即时数据,特别是对于顺序敏感的应用场景,时间就显得更为重要。
4. 状态与容错
由于流处理一般用于无限数据流的场景,所以一旦任务提交,程序将永远执行,如果中途因为程序异常崩溃,之前计算的结果可能就无法恢复,对于易逝性数据或者需要较大开销的场景,重新计算是无法接受的。因此流处理提供了大量状态管理的方法,比如支持多种外部系统持久化状态、定时 CheckPoint 等。而批处理是一次性提交,数据处理完,程序也就结束了。
通过初步了解 Flink,对于初学者来说,如果觉得不过如此,那就显得过于 Too Young Too Simple 了。殊不知,对于一门新技术框架,没有大量的踩坑和填坑经历是无法掌握其精髓的。比如在流处理中,本可以像批处理那样计算(count group by),但是因为文件系统不支持更新写入,因此如果没有实践,可能是不会有深刻理解的。为了能够跟上本文节奏,建议读者安装相关的开发环境。
开发环境准备
软硬件要求如下。
以下版本要求必选:
Java:OpenJDK 1.8
Python:3.8
apache-flink:release 1.12.0
PyFlink:1.12.0
cygwin 64 位
以下版本要求可选:
Linux CentOS:7.8(16 cores 64GB)
Windows 10(2.30GHz 16GB)
PyFlink 安装
python -m pip install apache-flink --timeout 3600
为保证快速下载,需要设置以下下载源。
更改 Python 包的下载源:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
在 Linux 系统和 Windows 系统,相应的文件路径分别为:
#Linux
~/pip/pip.conf
#Windows
%APPDATA%/pip/pip.ini
Flink 服务部署
下载最新 release 版本,如 1.12.0,如果是 Windows 系统,需要通过 cygwin,将 Flink 包解压到 cygwin 相应路径下,然后执行如下命令:
tar -xzf flink-1.12.0-bin-scala_2.11.tgz
cd flink-1.12.0-bin-scala_2.11
./bin/start-cluster.sh
如果部署过程一切正常,可以正常显示如下链接:
http://localhost:8081/
再论流处理与批处理
物化视图(Materialized Views)
通过文章第一部分对批处理和流处理的演示和比较,我们再回顾两者的几点区别,比如:

我们主要关注第二点,批处理查询实际上是关系数据查询,针对的是全部数据,而流处理查询永远无法访问所有数据,只能访问当前的快照数据(SnapShot),这类似于高级关系数据库系统中提供的物化视图特性——缓存当前查询结果,只有当基础数据发生变化,才需要更新视图,这带来的好处是更高效快捷的查询。
物化视图常用于结果汇总表,比如报表展示的数据直接来自物化视图,而不需要每次查询基础表重新计算。如果把这个概念推广到数据仓库的分层建模领域,数据汇总层(DWS)可以看作是数据明细层(DWD)的物化视图;同理 DWD 又可以看做 ODS 的物化视图,每层通过定期更新保证视图最新。
应用到流处理领域,基于流数据创建视图表,可以当有新的数据到来,就更新视图。
动态表(Dynamic Tables)
动态表是 Flink 的核心概念,且有相关 API 和 SQL 支持,比如上面示例中 .create_temporary_table('mySource') 创建的表,该表会随着数据的输入而变化,你可以简单把这个表理解为基于流上的物化视图,只不过在 Flink 内部,没有真正的物化,它是一个逻辑概念。只要流应用不终止,基于动态表就可以产生连续的查询结果,查询结果表又形成了新的动态表。当输入的动态表发生变化,连续的查询就可以在结果动态表中反应这种改变,下图描述了流、动态表和连续查询的关系:

从图中可以总结如下几点结论:
流可以转换为动态表
基于动态表的连续查询生成新的动态表
结果动态表可以转回流
下面通过服务器点击流日志数据进一步描述上述概念。
动态表定义
假设有这样的用户点击事件 schema(user,time,url),可以使用以下语句定义动态表:
CREATE TABLE clicks (
user VARCHAR, // the name of the user
url VARCHAR, // the URL that was accessed by the user
cTime TIMESTAMP(3) // the time when the URL was accessed
) WITH (...);
随着点击事件源源不断地被插入到源端系统(左图),动态表(右图)的数据也持续增加。
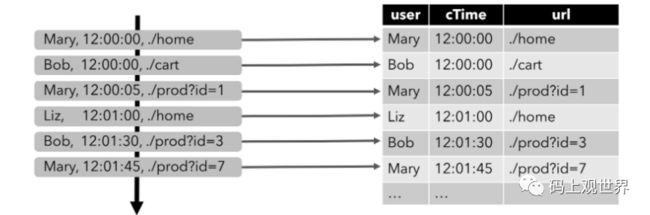
连续查询(Continuous Queries)
这里通过两个示例来演示基于动态表的查询,第一个是简单的分组统计,下图展示了随着 clicks 表插入新的记录,查询是如何进行的:

如上图所示:当第一条记录(Mary,./home)进入系统,查询结果只有一条[(Mary,1)];当第二条记录(Bob,./cart)进入系统,此时查询结果变成 2 条 [(Mary,1),(bob,1)];当第三条记录(Mary,./prod?id=1)进入系统,此时更新查询结果中的 (Mary,1) 为 (Mary,2),但记录总数还是 2 条:[(Mary,2),(bob,1)];依次类推,从整体来看,结果表随着记录的进入连续实时更新。
通过 Java 程序演示上述过程如下:
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStream clickEventDataStream = env.fromElements(
new ClickEvent("marry", "12:30:30", "/home.html"),
new ClickEvent("Bob", "12:45:30", "/cart.html"),
new ClickEvent("Liz", "13:15:30", "/prod.html"),
new ClickEvent("marry", "12:30:30", "/home.html"),
new ClickEvent("Bob", "12:45:30", "/cart.html"),
new ClickEvent("Liz", "13:15:30", "/prod.html")
);
DataStream mapClickEventDataStream = clickEventDataStream.map(new MapFunction() {
@Override
public ClickEvent map(ClickEvent clickEvent) {
clickEvent.setTimestamp(Timestamp.valueOf("2020-12-16 " + clickEvent.getTime()));
return clickEvent;
}
});
tEnv.createTemporaryView("clickEvents", mapClickEventDataStream, $("user"), $("url"));
Table groupTable = tEnv.sqlQuery("select user,count(url) as cnt from clickEvents group by user");
env.execute("stream job demo");
}
第二个是带有时间窗口的分组聚合查询,下图展示了每小时查询处理的结果(右图):

该查询定义了 1 个小时的时间窗口,并且按照 user 和窗口分组:当第一个小时结束(12:00:00-12:59:59),查询计算出 2 个结果记录然后追加到结果表;同理对第二个小时(13:00:00-13:59:59),第三个小时(14:00:00-14:59:59)的计算结果追加到结果表。
通过 Python 程序演示上述过程如下:
exec_env = StreamExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = StreamTableEnvironment.create(exec_env, t_config)
my_source_ddl = """
create table clicks (
`user` VARCHAR,
`ctime` TIMESTAMP,
`url` VARCHAR
) with (
'connector' = 'filesystem',
'format' = 'csv',
'path' = 'tmp/click_input'
)
"""
my_sink_ddl = """
create table sink (
`user` VARCHAR,
`ctime` TIMESTAMP,
`cnt` bigint
) with (
'connector' = 'filesystem',
'format' = 'csv',
'path' = 'tmp/output/click_output'
)
"""
t_env.execute_sql(my_source_ddl)
t_env.execute_sql(my_sink_ddl)
t_env.execute_sql("""
insert into sink select user,tumble_end(ctime,interval '1' hours) as end_time,count(url) as cnt
from clicks
group by user,tumble_end(ctime,interval '1' hours)
""")
t_env.execute("tutorial_job")
上述代码仅作为阅览,但无法执行,因为当前版本还不支持 TUMBLE_END 这样的窗口函数,会抛出这样的异常:
org.apache.flink.table.planner.codegen.CodeGenException: Unsupported call: TUMBLE_END(TIMESTAMP(6), INTERVAL SECOND(3) NOT NULL)
除非使用 Java(Scala) API 才可以解决这个问题,但是因为涉及到窗口(Window)、水位线(WaterMark)以及自定义窗户处理函数(ProcessFunction)相关的内容,为了避免问题复杂化,本文暂不做深入讲解。有兴趣的读者请关注本文后续相关文章。
通过上面两个查询示例的演示,我们再总结下两者的异同:
虽然两者都是分组查询,但是后者是带有时间窗口的查询,其本身需要维护当前窗口内的数据记录(状态)直到触发窗口操作;
简单分组查询每当有新记录进入便触发查询,而且查询结果会就地更新,会产生插入(Insert)和更新(Update)事件;
窗口分组查询当达到窗口操作条件才会触发窗口查询,查询结果 Append 到结果表,会产生插入(Insert)事件。
表转换为流
上述示例中基于动态表上的连续查询,结果是新的结果动态表,实际上动态表还可以转为流,用于进一步操作,比如持久化等,那如何将动态表转为流呢?
我们知道数据库中有三种数据更新方式,插入(Insert)、更新(Update)和删除(Delete),因为数据库存在主键的缘故,更新和删除可以在原有记录上进行。但是对于分布式系统,原地更新涉及到较大的系统开销,通常是采用追加方式,比如更新操作会转化为删除和插入两条记录,在必要的时候将原有记录合并丢弃。同样在 flink 中也提供了三种更新方式,连续的事件形成 3 种不同的流:
Append-only 流
当动态表种只有插入事件的数据,形成追加流,
Flink 提供了表到撤销流转化的 toAppendStream,代码示例为:
Table groupTable = tEnv.sqlQuery("select * from clickEvents");
DataStream> appendStreamTableResult= tEnv.toAppendStream(groupTable, Row.class);
appendStreamTableResult.print();
Retract 流
当动态表种种不仅存在插入还存在更新或者删除事件的数据时,删除事件会被编码为撤回事件,更新事件被编码为撤回(旧)和插入(新)事件,比如下图可视化事件转化效果:

比如第一条记录(Mary,1)进入后,产生一条 Insert 事件,当第二条进入时,产生原有记录的撤回事件,和新的插入事件(Mary,2)。
Flink 提供了表到撤销流转化的 API——toRetractStream,代码示例为:
Table groupTable = tEnv.sqlQuery("select user,count(url) as cnt from clickEvents group by user");
DataStream> retractStreamTableResult = tEnv.toRetractStream(groupTable, Row.class);
retractStreamTableResult.print();
upsert 流
Retract stream 流存在的问题是频繁的更新会导致过多的事件数据,而 upsert 流将其更新事件产生的 2 条记录合并为 1 条 upsert 记录,减少了数据量,提高了处理效率,但同时要求存储系统具有唯一键(Unique Key),上例中只有 Upsert 消息记录,示意图如下:

Flink 目前只提供了表到 append 流和 retract 流的转化,暂不支持对 upsert 流的转化,但是 Flink 有 DynamicTableSink 接口,开发者可以自行开发实现。
这里做个小结:
Append-only 流只适合于动态表只有插入数据的场景,而 Retract stream 流不仅适合于插入数据的场景,还适合于有更新和删除数据的场景。
实际应用中,不带窗口的分组查询是常见的会更新动态结果表,因此只能转化为 Retract 流,而非分组查询以及带窗口查询的结果动态表只有插入事件,所有可以转化为 Append 流。
带有更新事件的流不可用不支持更新操作的系统来存储,比如常规的操作系统的文件系统。动态表转为 upsert 流目前暂不支持,可以通过 DynamicTableSink 接口自行实现.
结果持久化
回到文章开头部分,明白了我们在演示流处理时候为什么不像批处理那样分组查询的原因:文件系统不支持更新操作,会报出异常:
pyflink.util.exceptions.TableException: "AppendStreamTableSink doesn't support consuming update changes which is produced by node GroupAggregate(groupBy=[user, end_time],select=[user, end_time, COUNT(url) AS cnt])"
如果想持久化动态结果数据,需要更换支持更新操作的存储系统,比如关系数据库系统,下面通过 MySQL 来演示。
首先创建表:
CREATE TABLE `mysqlSink` (
`word` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`count` bigint(20) NULL DEFAULT NULL,
PRIMARY KEY (`word`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci
ROW_FORMAT = Compact;
然后创建 jdbc sink:
create table mysql_sink (
word VARCHAR,
`count` BIGINT,
primary key(word) NOT ENFORCED
) with (...)
完整的示例程序如下:
exec_env = StreamExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = StreamTableEnvironment.create(exec_env, t_config)
my_source_ddl = """
create table mySource (
word VARCHAR
) with (
'connector' = 'filesystem',
'format' = 'csv',
'path' = 'tmp/input.csv'
)
"""
mysql_sink_ddl = """
create table mysql_sink (
word VARCHAR,
`count` BIGINT,
primary key(word) NOT ENFORCED
) with (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://192.168.1.18:3306/hzgas_hand',
'connector.table' = 'mysqlSink',
'connector.driver' = 'com.mysql.jdbc.Driver',
'connector.username' = 'hzgas',
'connector.password' = '******'
)
"""
t_env.execute_sql(my_source_ddl)
t_env.execute_sql(mysql_sink_ddl)
t_env.from_path('mySource').group_by('word').select('word, count(1)').insert_into('mysql_sink')
t_env.execute("tutorial_job")
如果数据库表没有设置主键,结果数据会被追加到表,读者可以自行去验证。
常见问题
Queston0
现象:在 Window 中通过 cygwin 部署 Flink,提示 JVM 参数错误。
Improperly specified VM option 'MaxMetaspaceSize=268435456 ' Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
Solution:这是 Flink 自动获取的 MaxMetaspaceSize 大小不合适造成的,需要手动在 flink-daemon.sh 文件修改该值。
Queston1
现象:通过 PyFlink 提交任务报错提示。
class py4j.jvm.org....ResetClientCallBack dosnot exist in JVM!
Solution:PyFlink 通过 Py4J 启动 Gateway 并跟远程服务通信,会通过 FLINK_HOME 环境变量引用 Flink 相关包,因此需要设置 FLINK_HOME,并保证 PyFlink 和 Flink 服务版本的一致。
Queston2
现象:PyFlink 使用 MySQL 存储时候报错。
Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.factories.TableSinkFactory' in
the classpath.
Reason:
No factory implements 'org.apache.flink.table.delegation.ExecutorFactory'.
Solution:Flink 1.11 版本之前缺少 JDBC 驱动,需要将 Flink JDBC 部署到 Flink lib 路径下,而 1.12 版本不存在该问题。
Queston3
现象:Java 通过 jar 命令行运行报错。
Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.delegation.ExecutorFactory' in the classpath.
Solution:将包 flink-table-planner-blink_2.12-1.12.0.jar 放在类路径下。
如:
java -cp ~\.m2\org\apache\flink\flink-table-planner-blink_2.12\1.12.0\flink-table-planner-blink_2.12-1.12.0.jar main_class
Queston4
现象:控制台通过 Python 命令行运行脚本报错。
Traceback (most recent call last):
File "/usr/local/lib64/python3.6/site-packages/pyflink/util/exceptions.py", line 147, in deco
return f(*a, **kw)
File "/usr/local/lib/python3.6/site-packages/py4j/protocol.py", line 328, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o23.execute.
: org.apache.flink.table.api.TableException: BatchTableSink or OutputFormatTableSink required to emit batch Table.
Solution:这种属于流和批环境的混用导致的。
修改为:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import TableConfig, StreamTableEnvironment
exec_env = StreamExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = StreamTableEnvironment.create(exec_env, t_config)
Queston5
现象:将结果数据写入 MySQL,报错提示找不到驱动类。

Solution:在 MySQL 8.0 driver 名称为 com.mysql.cj.jdbc.Driver,在 MySQL 5.0 driver 名称为 com.mysql.jdbc.Driver。
Queston6
现象:进行分组查询写入文件系统报错。
pyflink.util.exceptions.TableException: "AppendStreamTableSink doesn't support consuming update changes which is produced by node GroupAggregate(groupBy=[word], select=[word, COUNT($f1) AS EXPR$0])"
Solution:toAppendStream 不支持消费更新和删除,使用 toRetractStream 或者更换支持更新操作的存储系统。
参考链接
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/streaming/dynamic_tables.html#dynamic-tables