循环神经网络(Recurrent Neural Network)
1. 为什么需要循环神经网络 RNN

上图是一幅全连接神经网络图,我们可以看到输入层-隐藏层-输出层,他们每一层之间是相互独立地,(框框里面代表同一层),每一次输入生成一个节点,同一层中每个节点之间又相互独立的话,那么我们每一次的输入其实跟前面的输入是没有关系地。这样在某一些任务中便不能很好的处理序列信息。
什么是序列信息呢?
通俗理解就是一段连续的信息,前后信息之间是有关系地,必须将不同时刻的信息放在一起理解。
比如一句话,虽然可以拆分成多个词语,但是需要将这些词语连起来理解才能得到一句话的意思。
RNN就是用来处理这些序列信息的任务,比如NLP中的语句生成问题,一句话中的每个词并不是单独存在地,而是根据上下文信息,与他的前后词有关。
为了解决这一问题,循环神经网络 RNN也就应运而生了。
2. 循环神经网络 RNN的结构

先看左半边图,如果不看隐藏层中的W,把它忽略,那么这其实就相当于是一个全连接神经网络的结构。那么从左图中就可以看出RNN呢其实就只是相当于在全连接神经网络的隐藏层增加了一个循环的操作。至于这个循环的操作具体是怎样的呢?单看左图可能有些懵逼,那么现在看上右图。上右图是RNN网络结构按照时间线展开图。
Xt是t时刻的输入,是一个[x0,x1,x2…xn]的向量
U是输入层到隐藏层的权重矩阵
St是t时刻的隐藏层的值
W是上一时刻的隐藏层的值传入到下一时刻的隐藏层时的权重矩阵
V是隐藏层到输出层的权重矩阵
Ot是t时刻RNN网络的输出
从上右图中可以看出这个RNN网络在t时刻接受了输入Xt之后,隐藏层的值是St,输出的值是Ot。但是从结构图中我们可以发现St并不单单只是由Xt决定,还与t-1时刻的隐藏层的值St-1有关。
这样,所谓的隐藏层的循环操作也就不难理解了,就是每一时刻计算一个隐藏层地值,然后再把该隐藏层地值传入到下一时刻,达到信息传递的目的。
具体隐藏层值St计算公式如下:
![]()
得到t时刻隐藏层的值后,再计算输出层的值:
![]()
注意:在同一层隐藏层中,不同时刻的W,V,U均是相等地,这也就是RNN的参数共享。

3. 循环神经网络 RNN的训练方法
训练RNN常用的一种方法是 BPTT算法(back-propagation through time),其本质也是BP算法(Backpropagation Algorithm),BP算法的本质其实又是梯度下降法,这边默认大家已经了解了梯度下降和反向传播算法的原理。

上图是带入了RNN 损失函数Loss的按时间线结构展开图。ht相当于是之前介绍过的隐藏层的值St
在RNN的训练调参过程中,需要调优的参数只有W,U,V三个
![]()

因为ht与h{t-1}有关,而h{t-1}中也有W和U,因此W和U的偏导的求解需要涉及到历史所有时刻的数据,其偏导求起来相对复杂,我们先假设只有三个时刻,那么在第三个时刻也就是t=3时 L对W的偏导数为:

整体的偏导公式就是将所有时刻的偏导数加起来

来看看蓝框部分是一个连乘的形式,ht的计算公式引入激活函数f()后如下:

诶,现在想起来之前上面是不是还有一个坑没填,就是为什么要选择tanh作为隐藏层的激活函数呢?
从上面的式子我们可以看到,引入了激活函数tanh和sigmoid的导数连乘,那我们再看看这两个激活函数导数的图像:
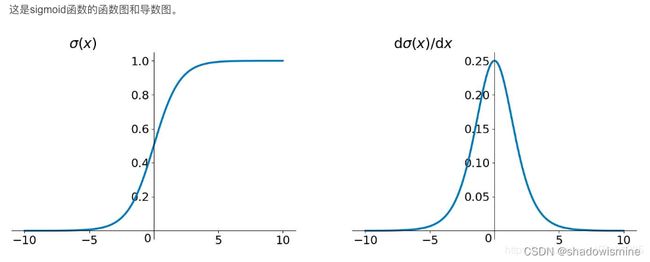
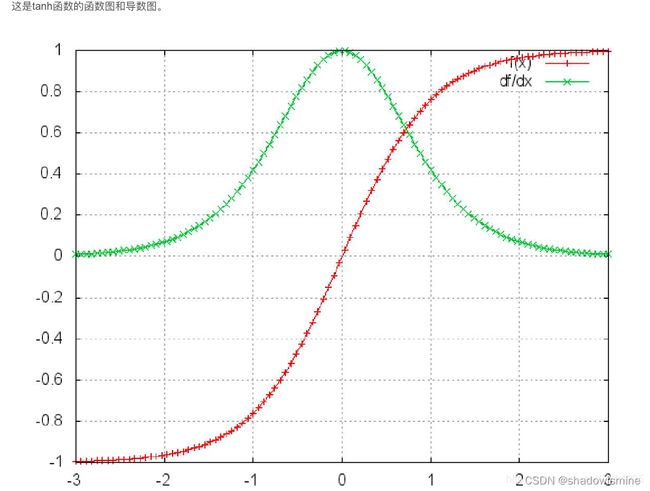
可以看到sigmoid函数和tanh函数的导数始终是小于1地,如果把众多小于1的数连乘,那么就会出现梯度消失的情况。
sigmoid函数的导数介于[0,0.25]之间,tanh函数的导入为[0,1]之间,虽然他们两者都存在梯度消失的问题,但tanh比sigmoid函数的表现要好,梯度消失得没有那么快。
你可能会要问之前在CNN中为了解决梯度消失问题是采用了ReLU激活函数,那么为什么RNN中不选用ReLU激活函数来彻底解决梯度消失的问题呢?
其实在RNN中使用ReLU函数确实也是能解决梯度消失的问题地,但是又会引入一个新问题梯度爆炸,先看看ReLU函数和其导数图:

因为ReLu的导数恒为1,由上面的公式我们发现
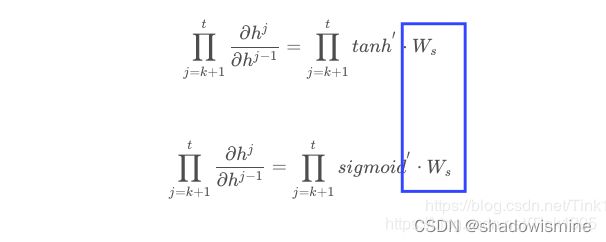
激活函数的导数每次需要乘上一个Ws,只要Ws的值大于1的话,经过多次连乘就会发生梯度爆炸的现象。但是这里的梯度爆炸问题也不是不能解决,可以通过设定合适的阈值解决梯度爆炸的问题。
但是目前大家在解决梯度消失问题地时候一般都会选择使用LSTM这一RNN的变种结构来解决梯度消失问题,而LSTM的激活函数又是选择的tanh,还不会引入梯度爆炸这种新问题,所以可能也就没有必要在基础的RNN上过多的纠结是选用ReLU还是tanh了吧,因为大家实际中用的都是LSTM,只需要理解RNN的思想就行了,于是就选择了一个折中的比sigmoid效果好,又不会引入新的梯度爆炸问题地tanh作为激活函数。
总之需要知道RNN中也能够使用ReLU激活函数来解决梯度消失问题,但是用来ReLU之后引入了新的梯度爆炸问题就得不偿失了,因此在梯度消失这个问题上选择用LSTM来优化是更好的选择。
4. 循环神经网络RNN的多种类型任务
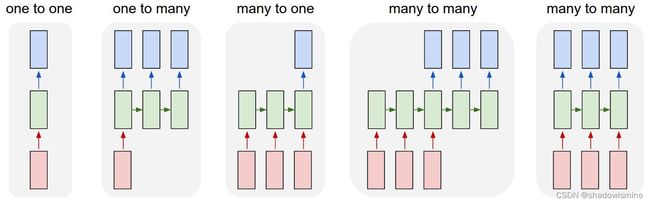
4.1 one-to-one

输入的是独立地数据,输出的也是独立地数据,基本上不能算作是RNN,跟全连接神经网络没有什么区别。
4.2 one-to-n

输入的是一个独立数据,需要输出一个序列数据,常见的任务类型有:
基于图像生成文字描述
基于类别生成一段语言,文字描述
4.3 n-to-n
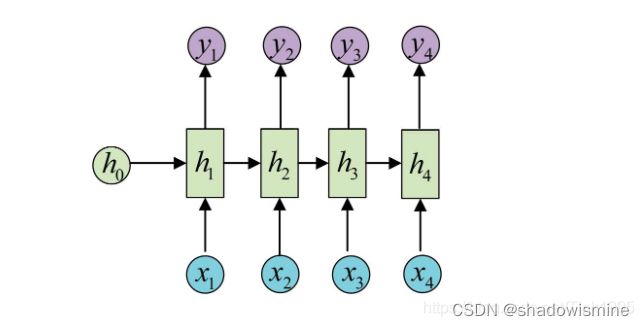
最为经典地RNN任务,输入和输出都是等长地序列
常见的任务有:
计算视频中每一帧的分类标签
输入一句话,判断一句话中每个词的词性
4.4 n-to-one
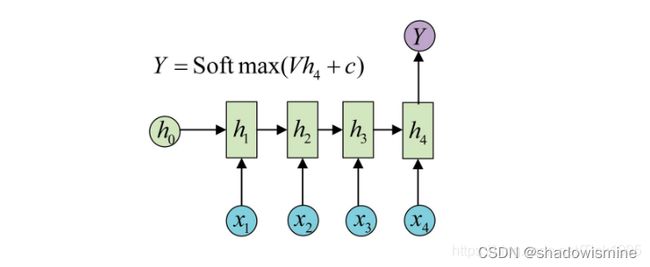
输入一段序列,最后输出一个概率,通常用来处理序列分类问题。
常见任务:
文本情感分析
文本分类
4.5 n-to-m
这种结构是Encoder-Decoder,也叫Seq2Seq,是RNN的一个重要变种。原始的n-to-n的RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。为此,Encoder-Decoder结构先将输入数据编码成一个上下文语义向量c:

语义向量c可以有多种表达方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。Decoder的RNN可以与Encoder的一样,也可以不一样。具体做法就是将c当做之前的初始状态h0输入到Decoder中:

还有一种做法是将c当做每一步的输入:
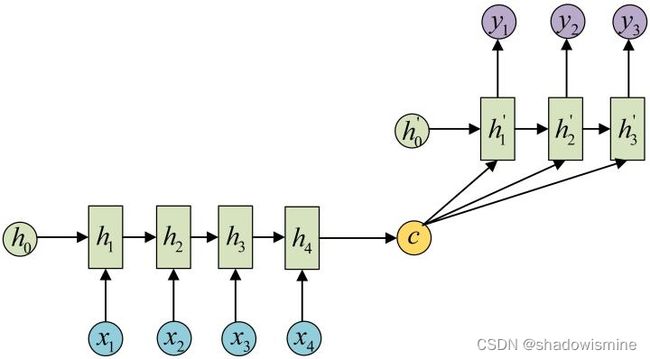
输入序列和输出序列不等长地任务,也就是Encoder-Decoder结构,这种结构有非常多的用法:
机器翻译:Encoder-Decoder的最经典应用,事实上这结构就是在机器翻译领域最先提出的
文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列
阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案
语音识别:输入是语音信号序列,输出是文字序列
基于Encoder-Decoder的结构后续有改良出了NLP中的大杀器transformer和Bert
5. BiRNN 双向RNN
虽然RNN达到了传递信息的目的,但是只是将上一时刻的信息传递到了下一时刻,也就是只考虑到了当前节点前的信息,没有考虑到该节点后的信息。具体到NLP中,也就是一句话,不仅要考虑某个词上文的意思,也还要考虑下文的意思,这个时候普通的RNN就做不到了。于是就有了双向RNN(Bidirectional RNN)。
5.1 BiRNN结构

上面是BiRNN的结构图,蓝框和绿框分别代表一个隐藏层,BiRNN在RNN的基础上增加了一层隐藏层,这层隐藏层中同样会进行信息传递,两个隐藏层值地计算方式也完全相同,只不过这次信息不是从前往后传,而是从后往前传,这样不仅能考虑到前文的信息而且能考虑到后文的信息了。
实现起来也很简单,比如一句话,“我爱NLP”,进行分词后是[“我”,“爱”,“NLP”],输入[[“我”],[“爱”],[“NLP”]],计算forward layer隐藏层值,然后将输入数据翻转成[[“NLP”],[“爱”],[“我”]],计算backward layer 隐藏层值,然后将两个隐藏层的值进行拼接,再输出就行啦。
这就是BiRNN的原理,理解了RNN的原理,应该来说还是比较简单地。
6. DRNN 深层RNN
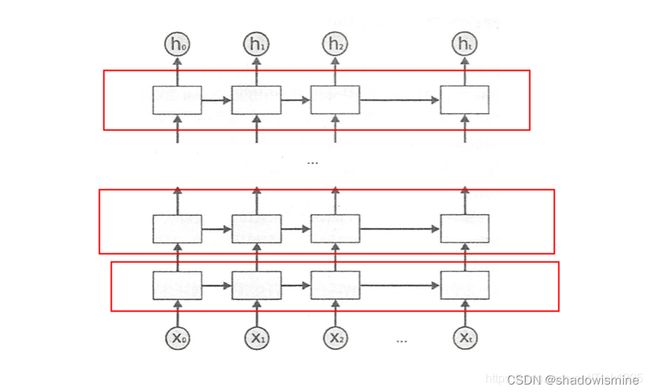
上图是DRNN的结构图,很简单,每一个红框里面都是一个BiRNN,然后一层BiRNN的输出值再作为另一个BiRNN的输入。多个BiRNN堆叠起来就成了DRNN。
原文链接:https://blog.csdn.net/Tink1995/article/details/104868903
RNN 结构详解 | 机器之心