Scala 语言
Scala
一、概述
Scala用一种简洁的高级语言将 面向对象 和 函数式编程 结合在一起。
领域模型设计--------------面向对象开发设计的核心
数据集计算模型----------大数据开发的核心
Scala是一门多范式的编程语言,同时支持面向对象和面向函数编程风格。它以一种优雅的方式解决现实问题。虽然它是强静态类型的编程语言,但是它强大的类型推断能力,使其看起来就像是一个动态编程语言一样。Scala语言最终会被翻译成java字节码文件,可以无缝的和JVM集成,并且可以使用Scala调用java的代码库。除了Scala编程语言自身的特性以外,目前比较流行的Spark计算框架也是使用Scala语言编写。Spark 和 Scala 能够紧密集成,例如 使用Scala语言操作大数据集合的时候,用户可以像是在操作本地数据集那样简单操作Spark上的分布式数据集-RDD(这个概念是Spark 批处理的核心术语),继而简化大数据集的处理难度,简化开发步骤。
资料参考:https://docs.scala-lang.org/tour/tour-of-scala.html
二、安装及配置
https://www.scala-lang.org/download/2.11.12.html
① windows安装:下载msi文件,直接安装。
配置环境变量:
SCALA_HOME=C:\Program Files (x86)\scala
PATH=C:\Program Files (x86)\scala/bin;
安装测试: cmd 窗口,输入 scala,出现提示,即安装完成。
② Linux 安装: 下载rpm文件,解压安装、
rpm -ivh scala-2.11.12.rpm
同时在 .bashrc中,或者/etc/profile中,配置环境变量。
安装测试:键入 scala,出现提示,即安装成功。
☆☆☆ IDEA 集成开发环境
在File>Setting>Plugins点击 install pluginfromdisk选项,搜索scala插件,安装成功后,重启IDEA。
三、数据
①.数据类型
在scala中一切皆对象,但是没有原始数据类型。
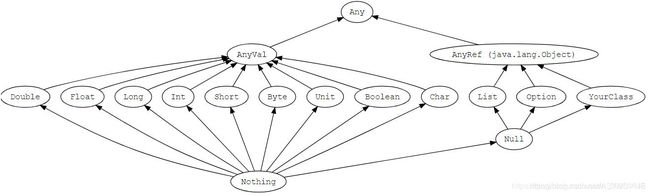
所有的数值变量类型都是 AnyVal的子类,这些变量的值都有字面值。
对于一些对象类型的变量都是 AnyRef的子类。对于 AnyRef类下的变量(除String类型),一般不允许直接赋值字面量,都需要借助 new关键创建。
②.变量声明
var 变量名:数据类型(可省略) = 值:数据类型(可省略)
Scala语言是一种可以做类型自动推断的强类型的编程语言。变量的类型可通过编译器在编译的时候推断出最终类型。因此Scala中声明一个变量主需要告知编译器该变量的值是常量还是变量,例如:例如声明一个变量使用var即可,如果声明的是一个常量使用val关键字。
var i =1 // Int
var j = 1:Byte // Byte
var b = true //Boolean
var name = "zs" //String
var c = 'a' // Char
③.数值转换 ★
1.符合java的数据转换规则,低精度向高精度转换
scala> var a = 1
a: Int = 1
scala> var b= 2:Byte
b: Byte = 2
//将 Byte 类型 赋值给 Int 类型
scala> a=b
a: Int = 2
2.高精度向低精度转换,借助于 asInstanceOf [ 低精度类型 ]
scala> var f1 = 2.0f
f1: Float = 2.0
scala> var d1 = 3.0
d1: Double = 3.0
scala> f1 = d1.asInstanceOf[Float]
f1: Float = 3.0
3.String 转换为任意val类型 ★
使用to类型关键字
scala> var s1 = "234"
s1: String = 234
scala> var d2 = 2.0
d2: Double = 2.0
scala> d2=s1.toDouble
d2: Double = 234.0
④.数组
//定义一个空数组
scala> var a=new Array[Int](5)
a: Array[Int] = Array(0, 0, 0, 0, 0)
//定义一个有数据的数组
scala> var a=Array(1,2,3,4,5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
//获取任一元素
scala> a(1)
res0: Int = 2
scala> a(0)
res1: Int = 1
//改变某一个数值
scala> a(0)= -1
//展示数组
scala> a
res3: Array[Int] = Array(-1, 2, 3, 4, 5)
//数组长度
scala> a.length
res4: Int = 5
//数组尺寸
scala> a.size
res5: Int = 5
☆☆☆数组的遍历(to包含最后,until不包含最后的元素)
//第一种,使用下标遍历
var array1 = (3,4,1,2)
for (i <- 0 to array1.length-1){
println(array1(i))
}
//第二种,使用元素直接遍历
var arg1 = Array(5,3,8,7)
for(i <- arg1) println(s"参数是$i")
//第三种*
var array1 = (3,4,1,2)
array1.foreach(item => println(item))
⑤.元祖 ★
元组是在Scala编程语言中的一种特殊变量,该变量可以组合任意几种类型的变量,构建一个只读的变量类型。访问元组的成员可以使用_元素下标访问。
scala> var yuanzu = (1,"zyl",true,2999.9f)
yuanzu: (Int, String, Boolean, Float) = (1,zyl,true,2999.9)
scala> yuanzu._1
res0: Int = 1
scala> yuanzu._2
res1: String = zyl
scala> yuanzu._3
res2: Boolean = true
scala> yuanzu._4
res3: Float = 2999.9
⑥.Unit 类型
Scala 中用void作为保留关键字,使用 Unit 作为 void 替换,在 scala 中,Unit 表示什么也没有。
scala> var null1 = ()
null1: Unit = ()
scala> null1
四、分支循环
①.if 条件分支 ( java)
if(条件){
...
}else if(条件){
...
}else{
...
}
scala> var age=35
age: Int = 35
scala> if(age<18){
| print(s"归来是少年,你的年龄:${age}")
| }else if(age<30){
| println(s"正是奋斗时青年,你的年龄:${age}")
| }else{
| println(s"趋于安稳的中年,你的年龄:${age}")
| }
趋于安稳的中年,你的年龄:35
在Scala语法中if分支可以作为变量的赋值语句。可以将分支中返回的结果作为返回值,在利用分支做赋值的时候,不可以给return关键字,系统会自动将代码块最后一行的结果作为返回值。
②.while/do-while(java)
while(条件){
...
}
打印九九乘法表
scala> var i=1
i: Int = 1
scala> while (i <= 9){
| var j=1;
| while (j<=i){
| if(j<i){
| print(s"$i*$j="+(i*j)+"\t")
| }else{
| println(s"$i*$j="+(i*j)+"\t")
| }
| j +=1
| }
| i +=1
| }
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
③.Break
Scala 语言中默认是没有 break 语句,但是在 Scala 2.8 版本后可以使用另外一种方式来实现 break 语句。当在循环中使用 break 语句,在执行到该语句时,就会中断循环并执行循环体之后的代码块。
//导包
import scala.util.control.Breaks
//break 的使用
val break = new Breaks //①
break.breakable( //②
for (i<-0 to 10){
if(i==5){
break.break() //③
}
println(s"$i\t")
}
)*
③.for循环 ★
//九九乘法表
for(i <- 1 to 9;j <- 1 to i){
print(s"$i*$j="+(i*j)+"\t")
if(i==j){
println()
}
}
//带条件的for循环
for(i<- 1 to 10;if(i%2==0)){
println(s"$i 是一个偶数")
}
//yield 的使用
var arr1 = Array(3,7,6,9)
var arr2 = for(i <- arr1) yield i*i
for(i<-arr2){
print(s"$i\t")
}
五、模式、数值匹配
根据参数值做匹配,如果匹配到对应的值,则返回对应的值,其中_表示默认匹配。
//match...case
var arr = Array(3,4,5,6)
var num = arr(new Random().nextInt(4))
var res = num match {
case 3 => "第一个元素"
case 4 => "第二个元素"
case 5 => "第三个元素"
case default => "最终元素"
}
println(res)
println(arr(3))
//match...case 2
for(i <- 0 to 10){
var struct1 = Array(1,"zyl",true,new Date())
var rand = struct1(new Random().nextInt(4))
var result = rand match {
case x:Int => s"id$x"
case x:String => s"name$x"
case x:Boolean => s"sex$x"
case _ => s"什么都不是"
}
println(s"这是第$i 次计算 $result")
}
六、=> 的使用场景
原文链接:https://blog.csdn.net/someInNeed/article/details/90047624
①.表示函数的返回类型(Function Type)
(x: Int) => Int 或者 Int => Int。左边是参数类型,右边是方法返回值类型。
②.匿名函数
匿名函数定义,=>左边是参数 右边是函数实现体 (x: Int)=>{}
③.case语句
在模式匹配 match 和 try-catch 都用 “=>” 表示输出的结果或返回的值
④.By-Name Parameters(传名参数)
传名参数在函数调用前表达式不会被求值,而是会被包裹成一个匿名函数作为函数参数传递下去,例如参数类型为无参函数的参数就是传名参数。
//函数double
scala> def doubles(x: => Int) = {
println("Now doubling " + x)
x*2
}
doubles: (x: => Int)Int
//调用函数
scala> doubles(3)
Now doubling 3
res2: Int = 6
scala> def f(x: Int): Int = {
println(s"Calling f($x)")
x+1
}
f: (x: Int)Int
//调用函数
scala> doubles(f(3))
Calling f(3)
Now doubling 3
Calling f(3)
res9: Int = 8
对于函数doubles而言,它的参数x就是by-name的。如果调用doubles的时候,直接给个普通的值或者非函数变量。那么doubles的执行结果就跟普通的函数没有区别。但是当把一个返回值为Int类型的函数,例如f(2),传递给doubles的时候。那么f(2)会被先计算出返回值3,返回值3传入doubles参与运算。运算完成以后得8,f(2)会被doubles在执行以后,再调用一遍。
七、函数 ★
函数声明:
def 函数名(参数:类型,参数2:类型,....): 返回值类型 ={ 方法实现 }
①.标准函数
scala> def sum1(x:Int,y:Int):Int={
x+y}
sum1: (x: Int, y: Int)Int
scala> sum1(3,4)
res0: Int = 7
//可以省略 `return` 关键字,及 返回值类型
scala> def sum1(x:Int,y:Int)={
x*y}
sum1: (x: Int, y: Int)Int
scala> sum1(2,3)
res1: Int = 6
②.可变长参数
在参数类型后使用 * 标识可变长参数
scala> def sum1(x:Int*) = {
| var sum = 0
| for(i <- x){
| sum = sum +i
| }
| sum
| }
sum1: (x: Int*)Int
scala> sum1(1,2,3,4,5)
res3: Int = 15
//本身可变长参数是一种数组,因此可以使用 数组的函数
scala> def sum1(x:Int*)= {
| x.sum
| }
sum1: (x: Int*)Int
scala> sum1(1,2,3,4,5)
res3: Int = 15
③.命名参数
可以在返回值中给出参数的 参数名 信息
scala> def mes(name:String,tip:String) = {
| println(s"${tip}----${name}")
| }
mes: (name: String, tip: String)Unit
scala> mes("zyl","hello")
hello----zyl
scala> mes("hello","zyl")
zyl----hello
scala> mes(tip="hello",name="zyl")
hello----zyl
④.默认值参数
返回值中显示已给定的参数的默认值,也可以自己赋值,改变默认值。
scala> def mes(name:String,tip:String="hi"){
| println(s"${name},${tip}")
| }
mes: (name: String, tip: String)Unit
scala> mes("zyl")
zyl,hi
scala> mes(name="zyl")
zyl,hi
scala> mes("zyl","hello")
zyl,hello
scala> mes(name="zyl",tip="exec")
zyl,exec
⑤.内嵌函数
一个函数内部嵌套另一个函数,内部函数的返回值类型需要给出
scala> def factorial(x:Int) = {
| def mul(y:Int):Int={
| if(y>1){
| y*mul(y-1)
| }
| else{
| 1
| }
| }
| mul(x)
| }
factorial: (x: Int)Int
scala> factorial(5)
res12: Int = 120
⑥.柯里化 ★
在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数的技术。
scala> def sum(x:Int)(y:Int)={
| x+y
| }
sum: (x: Int)(y: Int)Int
scala> sum(1)(2)
res13: Int = 3
scala> sum(1)(_)
res14: Int => Int = <function1>
scala> res14(5)
res15: Int = 6
//可以不给任何实参 以函数名 _ 组成
scala> var res = sum _
res: Int => (Int => Int) = <function1>
scala> res(2)
res17: Int => Int = <function1>
scala> res17(5)
res18: Int = 7
⑦.匿名函数 ★
(x:Int,y:Int) => {x+y}箭头左边是参数列表,右边是函数体。使用匿名函数后,我们的代码变得更简洁了。
def 可以声明一个标准函数,也可以定义一个函数式变量
scala> var sum=(x:Int,y:Int) => {
x+y}
sum: (Int, Int) => Int = <function2>
scala> sum(1,2)
res19: Int = 3
// def 也可以定义一个函数式变量
scala> def sum1=(x:Int,y:Int) => {
| x*y
| }
sum1: (Int, Int) => Int
scala> sum1(2,3)
res20: Int = 6
//☆
scala> def method(x:Int,y:Int,f:(Int,Int)=>Int):Int = {
| f(x,y)
| }
method: (x: Int, y: Int, f: (Int, Int) => Int)Int
scala> var f=(a:Int,b:Int)=>a*b
f: (Int, Int) => Int = <function2>
scala> method(3,4,f)
res0: Int = 12
☆☆☆☆☆
def sum(x:Int,y