HDFS基本命令
目录
1.上传文件到HDFS文件系统
2.-appendToFile:追加一个文件到已经存在的文件末尾
3.查看HDFS文件系统中的文件
4.查看上传到HDFS文件系统中指定文件的内容
5.从HDFS文件系统下载指定文件,并存放在指定文件中
6.删除HDFS文件系统中的指定文件
7.创建目录
8.创建多级目录
9.递归删除目录下的所有文件
10.删除指定目录
11. -chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
12.-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
13.-mv:在HDFS目录中移动文件
14.-tail:显示一个文件的末尾1kb的数据
15.-du统计文件夹的大小信息
16.-setrep:设置HDFS中文件的副本数量
17.start-all.sh启动了两套系统
18.安全模式操作
19.启动历史服务
20.查看文件机架信息
HDFS副本机制:
Bolck:数据块
HDFS最基本的存储单元
默认块大小:128M(2.x)
副本机制
作用:避免数据丢失
副本数默认为3
存放机制:
1.一个在本地机架节点
2.副本在同一个机架不同节点
3.一个在不同机架的节点
HDFS优点:
高容错性、适合大数据处理、流式数据访问、可构建在廉价的机器上
HDFS缺点:
不适合低延时数据访问场景、不适合小文件存取场景、不适合并发写入,文件随机修改场景
HDFS基本命令:
1.上传文件到HDFS文件系统
[root@lxm147 opt]# hdfs dfs -put ./testfile.txt /
[root@lxm147 opt]# hdfs dfs -put ./aa.txt /KB21/tt2.-appendToFile:追加一个文件到已经存在的文件末尾
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:
liubei
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt3.查看HDFS文件系统中的文件
[root@lxm147 opt]# hdfs dfs -ls /
[root@lxm147 opt]# hdfs dfs -ls /KB21/tt
4.查看上传到HDFS文件系统中指定文件的内容
[root@lxm147 opt]# hdfs dfs -cat /testfile.txt
5.从HDFS文件系统下载指定文件,并存放在指定文件中
[root@lxm147 opt]# hdfs dfs -get /testfile.txt ./aa.txt
6.删除HDFS文件系统中的指定文件
[root@lxm147 opt]# hdfs dfs -rm /testfile.txt
7.创建目录
[root@lxm147 opt]# hdfs dfs -mkdir /bigdata
8.创建多级目录
[root@lxm147 opt]# hdfs dfs -mkdir -p /aa/bb
9.递归删除目录下的所有文件
[root@lxm147 opt]# hdfs dfs -rm -R /KB21/tt
10.删除指定目录
[root@lxm147 opt]# hdfs dfs -rm -r /bigdata11. -chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt12.-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo13.-mv:在HDFS目录中移动文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo14.-tail:显示一个文件的末尾1kb的数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt15.-du统计文件夹的大小信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx16.-setrep:设置HDFS中文件的副本数量
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
17.start-all.sh启动了两套系统
[root@lxm147 sbin]# start-dfs.sh
[root@lxm147 sbin]# stop-dfs.sh
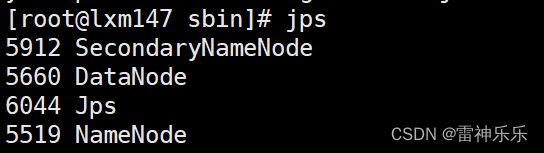
[root@lxm147 sbin]# start-yarn.sh
[root@lxm147 sbin]# stop-yarn.sh 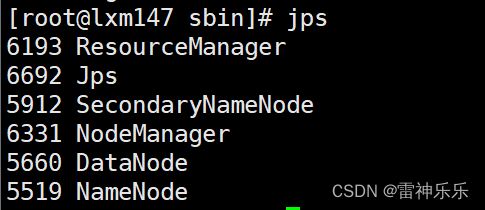
18.安全模式操作
安全模式所有的hdfs报错
# 获取当前是否为安全模式
[root@lxm147 mapreduce]# hdfs dfsadmin -safemode get
# 离开安全模式
[root@lxm147 mapreduce]# hdfs dfsadmin -safemode leave
# 进入安全模式
[root@lxm147 mapreduce]# hdfs dfsadmin -safemode enter
19.启动历史服务
[root@lxm147 ~]# mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[root@lxm148 ~]# jps
4546 SecondaryNameNode
6370 JobHistoryServer
4164 NameNode
4804 ResourceManager
4937 NodeManager
6393 Jps
4302 DataNodehttp://lxm147:9870
http://lxm147:8042
http://lxm147:8088
http://lxm147:19888
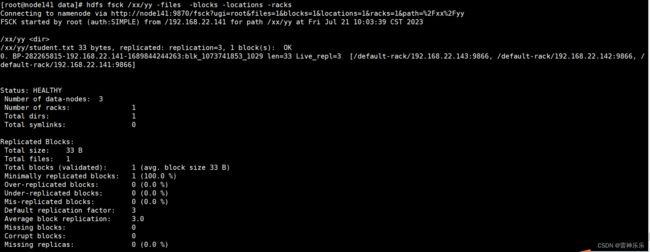
20.查看文件机架信息
hdfs fsck <文件路径> -files -blocks -locations -racks
# 这里的文件路径不要写到具体的文件,写到文件的上级目录即可,否则会报错
# 例如/bigdata目录下有文件,则不需要写到具体的文件
hdfs fsck /bigdata -files -blocks -locations -racks[root@node141 data]# hdfs dfs -ls /xx/yy/
Found 1 items
-rw-r--r-- 3 root supergroup 33 2023-07-21 08:41 /xx/yy/student.txt
[root@node141 data]# hdfs dfs -cat /xx/yy/student.txt
001 zhangsan
002 lisi
003 wangwu