mac下搭建hadoop完全分布式集群
环境要求:
- MacOS Big Sur 11.5.2
- Parallel Desktop 17 Pro Edition
- FinalShell
具体步骤:
1.PD 下载 unbuntu linux 安装,安装完毕后进入终端
2.进行 hostname 的设置(永久更改主机名的方式):
sudo gedit /etc/hostname 打开文件后进行修改,改为 hadoop01 确保防火墙关闭:
sudo ufw status
如果是 inactive 说明关闭,如果不是则 sudo ufw disable 进行关闭。 3.解压 jdk 安装
sudo su 进入 root 模式
找到你本机下载的 jdk 包所在的位置,copy 其路径名,cd 路径名
mv jdk-8u152-linux-x64.tar.gz /usr/local/java, 若没有则需先创建。
tar -zxvf jdk-8u152-linux-x64.tar.gz 进行解压 sudo gedit /etc/profile 配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin: 改完后保存退出,执行 source /etc/profile,在终端 java -version 能看到

说明成功。
4.克隆镜像生成 hadoop02/hadoop03,重复步骤 2 进行主机名修改和关闭防火墙。 克隆的办法是在 PD 的控制中心点击一个镜像然后右键克隆即可,主机名修改完成后,将三台虚拟机全部重启完成重置。
5.配置 SSH 免密登陆
1)在三台虚拟机上分别运行 ifconfig 记录其 ip address
Hadoop01: 192.168.31.6
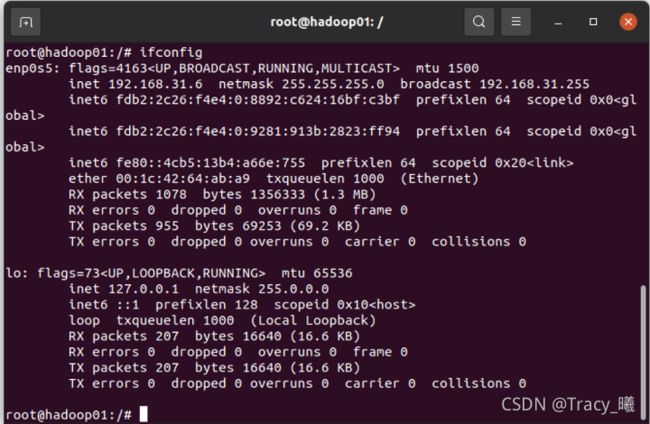
Hadoop02:192.168.31.4
Hadoop03:192.168.31.5
2)hadoop01 的终端:
sudo gedit /etc/hosts 添加三台机器的 ip 地址和主机名:
192.168.31.6 hadoop01
192.168.31.4 hadoop02
192.168.31.5 hadoop03
保存后退出。
3)ping hadoop02,注意要打开 hadoop02 的虚拟机。若通了则说明成功。
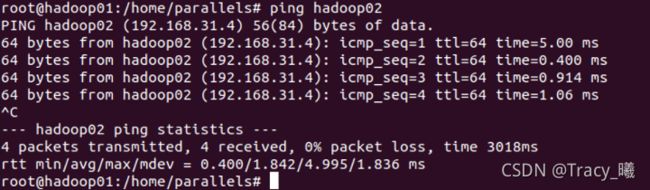
4)sudo apt-get install openssh-server 安装 ssh 等一系列服务,若有则跳过,完成 后
sudo service ssh start 开启服务
5)ssh-keygen -t rsa 生成密码密钥对
6)cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 将生成的公钥加入根目录 7)编辑公钥权限:
chmod 600 authorized_keys ~/.ssh/authorized_keys
chmod 700 ~/.ssh
8)将 hadoop01 上的公钥分发给 hadoop01/hadoop02/hadoop03
ssh-copy-id parallels@hadoop01
ssh-copy-id parallels@hadoop02
ssh-copy-id parallels@hadoop03
注:然后在 hadoop02 上面进到 home/parallels 目录下的.ssh 目录,用 root 用户 执行:
cat authorized_keys >>/root/.ssh/authorized_keys
9)在 hadoop01 分别运行 ssh hadoop01
ssh hadoop02
ssh hadoop03
,若出现下面则通了
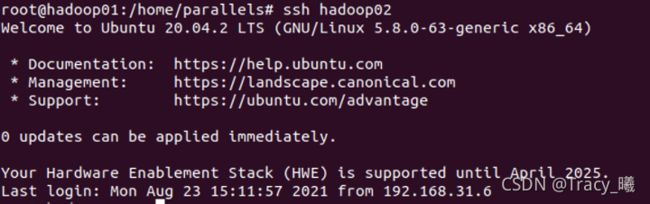
6.安装 hadoop
1)进入压缩包的路径
mv hadoop-2.7.6.tar.gz /usr/local/hadoop, 若没有则需先创建。 2)tar -zxvf hadoop-2.7.6.tar.gz 进行解压
3)创建目录
 4 ) 修改配置文件
4 ) 修改配置文件
进入/usr/local/hadoop/hadoop-2.7.6/etc/hadoop,
sudo gedit hadoop-env.sh 修改 java 安装路径
sudo gedit yarn-env.sh 修改 java 安装路径为/usr/local/java/jdk1.8.5_152
sudo gedit slaves 将 hadoop01,hadoop02,hadoop03 添加进去,注意一行一个
sudo gedit core-site.xml 修改 1.hadoop.tmp.dir 为/usr/local/hadoop/hadoop- 2.7.6/tmp;2.hadoop.proxyuser.root.hosts 中将 root 改为虚拟机的登录名(我的是 parallels)
sudo gedit hdfs-site.xml 修改 1.dfs.namenode.name.dir 部分为 /usr/local/hadoop/hadoop-2.7.6/dfs/name;2.data 的目录为/usr/local/hadoop/hadoop- 2.7.6/dfs/data
还有 mapred-site.xml,yarn-site.xml 这两个可以跟模版一致即可。
5) 通过 ssh 传输 hadoop 到 hadoop02/hadoop03
scp -r /usr/local/hadoop root@hadoop02:~/
scp -r /usr/local/hadoop root@hadoop03:~/
打开 hadoop02,hadoop03 将文件放到相同的目录下。默认传输过来是在 Home/Parallels 下。
6)sudo gedit /etc/profile 配置环境变量
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOM E/sbin
改完后保存退出,执行 source /etc/profile,在终端 hadoop -version 能看到
sudo gedit ~/.bashrc 最后增加一行: source /etc/profile 保证每次启动时环境变 量自动生效。
7.启动 Hadoop
在 hadoop01 上 root 用户启动
hadoop namenode -format
start-all.sh
8. hadoop01 终端 jps 查看进程:
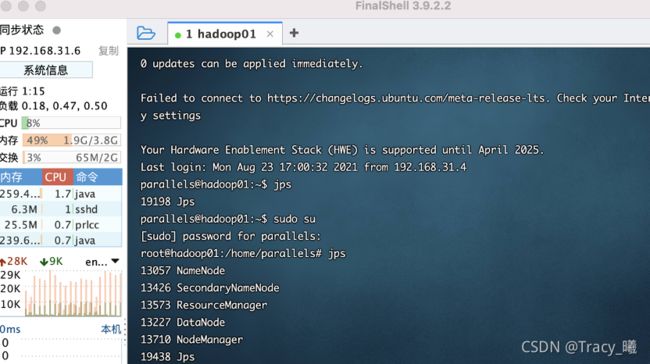
再启动历史服务:
mr-jobhistory-daemon.sh start historyserver
9.启动成功,打开 hadoop01 ip 地址的网页:
http://192.168.31.6:50070 namenode 端口
http://192.168.31.6:50090 secondarynamenode 端口
http://192.168.31.6:8088 resourcemanager 端口
http://192.168.31.6:19888 historyserver 端口

参考:
https://blog.csdn.net/baolibin528/article/details/43375231
https://blog.csdn.net/wk51920/article/details/51686038