《Hbase原理与实践》读书笔记——1.HBase概述
1.1 HBase前世今生
Google当年风靡一时的“三篇论文”:GFS -> HDFS , Mapreduce -> hadoop mapreduce , bigTable -> HBase。
HBase在国外起步很早,包括Facebook、Yahoo、Pinterest等大公司都大规模使用HBase作为基础服务。在国内HBase相对起步较晚,但现在各大公司对于HBase的使用已经越来越普遍,包括阿里巴巴、小米、华为、网易、京东、滴滴、中国电信、中国人寿等公司都使用HBase存储海量数据,服务于各种在线系统以及离线分析系统。
版本变迁:

1、0.94.x:HBase历史上第一个相对稳定的生产线版本,国内最早使用HBase的互联网公司(小米、阿里、网易等)都曾在生产线上大规模使用0.94.x作为服务版本。
2、0.96:实现了很多重大的功能改进,比如BucketCache、MSLAB、MTTR优化等,但也因为功能太多而引入了很多bug,导致生产线上真正投入使用的并不多。
3、0.98:修复了大量的bug,大大提升了系统可用性以及稳定性。不得不说,0.98版本是目前业界公认的HBase历史上最稳定的版本之一。
4、1.0.0:规范了HBase的版本号,此后的版本号都统一遵循semantic versioning语义

5、1.4.10:目前,HBase社区推荐使用的稳定版本为1.4.10
6、2.x:核心功能包括:大幅度减小GC影响的offheap read path/write path工作,极大提升系统稳定性的Procedure V2框架,支持多租户隔离的RegionServer Group功能,支持大对象存储的MOB功能
1.2 Hbase数据模型
1.2.1 Hbase基本概念

1.2.2 Hbase逻辑视图
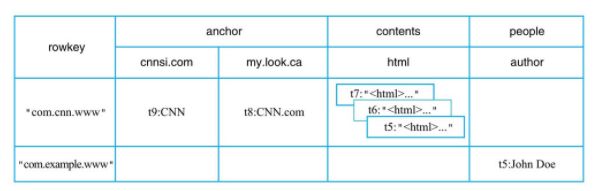
BigTable论文中称BigTable为"sparse,distributed, persistent multidimensional sorted map"——稀疏的、分布式的、持久性的、多维的以及排序的
逻辑视图中行"com.cnn.www"以及列"anchor:cnnsi.com"对应的数值"CNN"实际上在HBase中存储为如下KV结构:
{“com.cnn.www”, “anchor”, “cnnsi.com”, “put”, “t9”} -> “CNN”
特性解释:
1、多维:Hbase中的map的key是一个复合数据结构,由多维元素构成,包括rowkey、column family、column qualifier、type以及timestamp。
2、稀疏:比如逻辑表中行"com.example.www"可以看出,整整一行仅有一列(people:author)有值,其他列都为空值。对于HBase来说,空值不需要任何填充,从而节省了大量的空间,这也是hbase的列可以无限扩展的一个重要条件。
3、排序:构成HBase的KV在同一个文件中都是有序的,但规则并不是仅仅按照rowkey排序,而是按照KV中的key进行排序——先比较rowkey,rowkey小的排在前面;如果rowkey相同,再比较column,即column family:qualifier,column小的排在前面;如果column还相同,再比较时间戳timestamp,即版本信息,timestamp大的排在前面。这样的多维元素排序规则对于提升HBase的读取性能至关重要
4、分布式:构成HBase的所有Map并不集中在某台机器上,而是分布在整个集群中。
1.2.3 Hbase物理视图
HBase中的数据是按照列簇存储的,即将数据按照列簇分别存储在不同的目录中。比如列簇anchor的所有数据存储在一起:

1.2.4 行式存储、列式存储、列簇式存储
一、行式存储:行式存储系统会将一行数据存储在一起,一行数据写完之后再接着写下一行,最典型的如MySQL这类关系型数据库
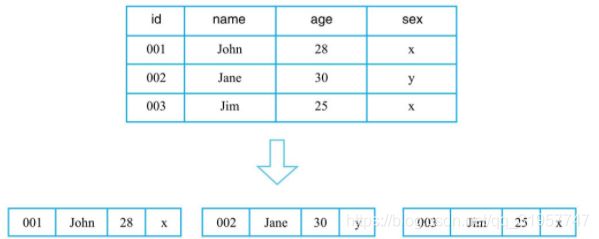
优势:
1、获取一行数据非常高效,仅适合处理OLTP类型的负载
劣势:
1、读取表指定列对应的数据,由于会先读取一行行数据,再在每一行数据中待查找目标列,引用了大量无用列的信息,从而导致大量内存占用,不擅长OLAP这类分析型负载。
二、**列式存储**:列式存储理论上会将一列数据存储在一起,不同列的数据分别集中存储,最典型的如Kudu、Parquet on HDFS等系统(文件格式)。

优势:
1、对于只查找某些列数据的请求非常高效,只需要连续读出所有待查目标列,然后遍历处理即可。
2、因为同一列的数据通常都具有相同的数据类型,因此列式存储具有天然的高压缩特性。
劣势:
1、对于获取一行的请求就不够高效了,需要多次IO读多个列数据,最终合并得到一行数据。
三、列簇式存储:介于行式存储和列式存储之间,可以通过不同的设计思路在行式存储和列式存储两者之间相互切换,比如
1、一张表只设置一个列簇,这个列簇包含所有用户的列。HBase中一个列簇的数据是存储在一起的,因此这种设计模式就等同于行式存储
2、一张表设置大量列簇,每个列簇下仅有一列,这种设计模式就等同于列式存储
1.3 Hbase体系架构
Hbase是典型的Master-Slaver架构,系统中有一个管理集群的Master节点以及大量实际服务用户读写的RegionServer节点。除此之外,HBase中所有数据最终都存储在HDFS系统中,这与BigTable实际数据存储在GFS中相对应;系统中还有一个ZooKeeper节点,协助Master对集群进行管理。

1.3.1 Hbase客户端
HBase客户端(Client)提供了Shell命令行接口(支持所有常见的DML操作以及DDL操作)、原生Java API编程接口、Thrift/REST API编程接口以及MapReduce编程接口。
HBase客户端访问数据行之前,首先需要通过元数据表定位目标数据所在RegionServer,之后才会发送请求到该RegionServer。同时这些元数据会被缓存在客户端本地,以方便之后的请求访问。如果集群RegionServer发生宕机或者执行了负载均衡等,从而导致数据分片发生迁移,客户端需要重新请求最新的元数据并缓存在本地。
1.3.2 Zookeeper
ZooKeeper(ZK)也是Apache Hadoop的一个顶级项目,主要用于协调管理分布式应用程序。在HBase系统中,主要有以下用途:
•实现Master高可用:通常情况下系统中只有一个Master工作,一旦ActiveMaster由于异常宕机,ZooKeeper会检测到该宕机事件,并通过一定机制选举出新的Master,保证系统正常运转。
•管理系统核心元数据:比如,管理当前系统中正常工作的RegionServer集合,保存系统元数据表hbase:meta所在的RegionServer地址等。
•参与RegionServer宕机恢复:ZooKeeper通过心跳可以感知到RegionServer是否宕机,并在宕机后通知Master进行宕机处理。
•实现分布式表锁:HBase中对一张表进行各种管理操作(比如alter操作)需要先加表锁,防止其他用户对同一张表进行管理操作,造成表状态不一致。
1.3.3 Master
Master主要负责HBase系统的各种管理工作:
•处理用户的各种管理请求,包括建表、修改表、权限操作、切分表、合并数据分片以及Compaction等。
•管理集群中所有RegionServer,包括RegionServer中Region的负载均衡、RegionServer的宕机恢复以及Region的迁移等。
•清理过期日志以及文件,Master会每隔一段时间检查HDFS中HLog是否过期、HFile是否已经被删除,并在过期之后将其删除。
1.3.4 RegionServer
RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。
• WAL(HLog):HLog在HBase中有两个核心作用
①用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复
②用于实现HBase集群间主从复制,通过回放主集群推送过来的HLog日志实现主从复制。
• BlockCache:HBase系统中的读缓存。客户端从磁盘读取数据之后通常会将数据缓存到系统内存中,后续访问同一行数据可以直接从内存中获取而不需要访问磁盘。
对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。BlockCache缓存对象是一系列Block块,一个Block默认为64K,由物理上相邻的多个KV数据组成。
• Region:数据表的一个分片,当数据表大小超过一定阈值就会“水平切分”,分裂为两个Region。Region是集群负载均衡的基本单位。通常一张表的Region会分布在整个集群的多台RegionServer上,一个RegionServer上会管理多个Region,当然,这些Region一般来自不同的数据表。
一个Region由一个或者多个Store构成,Store的个数取决于表中列簇(column family)的个数。HBase中,每个列簇的数据都集中存放在一起形成一个存储单元Store,因此建议将具有相同IO特性的数据设置在同一个列簇中。
每个Store由一个MemStore和一个或多个HFile组成。MemStore称为写缓存,用户写入数据时首先会写到MemStore,当MemStore写满之后(缓存数据超过阈值,默认128M)系统会异步地将数据flush成一个HFile文件。当HFile文件数超过一定阈值之后系统将会执行Compact操作,将这些小文件通过一定策略合并成一个或多个大文件。
1.3.5 HDFS
HBase底层依赖HDFS组件存储实际数据,包括用户数据文件、HLog日志文件等最终都会写入HDFS落盘。HDFS的数据默认三副本存储策略可以有效保证数据的高可靠性。HBase内部封装了一个名为DFSClient的HDFS客户端组件,负责对HDFS的实际数据进行读写访问。
1.4 HBase系统特性
1.4.1 优点
•容量巨大:HBase的单表可以支持千亿行、百万列的数据规模,数据容量可以达到TB甚至PB级别。传统的关系型数据库,如Oracle和MySQL等,如果单表记录条数超过亿行,读写性能都会急剧下降。
•良好的可扩展性:HBase集群可以非常方便地实现集群容量扩展,主要包括数据存储节点扩展以及读写服务节点扩展。HBase底层数据存储依赖于HDFS系统,HDFS可以通过简单地增加DataNode实现扩展,HBase读写服务节点也一样,可以通过简单的增加RegionServer节点实现计算层的扩展。
•稀疏性:HBase支持大量稀疏存储,即允许大量列值为空,并不占用任何存储空间。这与传统数据库不同,传统数据库对于空值的处理要占用一定的存储空间,这会造成一定程度的存储空间浪费。因此可以使用HBase存储多至上百万列的数据,即使表中存在大量的空值,也不需要任何额外空间。
•高性能:HBase目前主要擅长于OLTP场景,数据写操作性能强劲,对于随机单点读以及小范围的扫描读,其性能也能够得到保证。对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
•多版本:HBase支持多版本特性,即一个KV可以同时保留多个版本,用户可以根据需要选择最新版本或者某个历史版本。
•支持过期:HBase支持TTL过期特性,用户只需要设置过期时间,超过TTL的数据就会被自动清理,不需要用户写程序手动删除。
•Hadoop原生支持:HBase是Hadoop生态中的核心成员之一,很多生态组件都可以与其直接对接。HBase数据存储依赖于HDFS,这样的架构可以带来很多好处,比如用户可以直接绕过HBase系统操作HDFS文件,高效地完成数据扫描或者数据导入工作;再比如可以利用HDFS提供的多级存储特性(Archival Storage Feature),根据业务的重要程度将HBase进行分级存储,重要的业务放到SSD,不重要的业务放到HDD。或者用户可以设置归档时间,进而将最近的数据放在SSD,将归档数据文件放在HDD。
1.4.2 缺点
•HBase本身不支持很复杂的聚合运算(如Join、GroupBy等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark组件,前者主要应用于小规模聚合的OLTP场景,后者应用于大规模聚合的OLAP场景。
•HBase本身并没有实现二级索引功能,所以不支持二级索引查找。好在针对HBase实现的第三方二级索引方案非常丰富,比如目前比较普遍的使用Phoenix提供的二级索引功能。
•HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。