YOLO-V8训练自己的数据集之数据集划分
目录
六、划分数据集
6.1、模型训练数据集划分概述
6.1.1、数据集划分介绍
6.1.2、划分数据集的原因、作用及常用方法
6.2、划分数据集常见示例
6.3、数据集划分实操演示
6.3.1、将数据集划分为训练集和验证集
6.3.2、将数据集划分为训练集、验证集和测试集
六、划分数据集
6.1、模型训练数据集划分概述
6.1.1、数据集划分介绍
在深度学习模型训练中,对数据集的合理划分是至关重要的。通常,我们会将原始数据集划分为三个部分:训练集、验证集和测试集。
1. 训练集:训练集是模型用来学习和获取信息的数据,通常占总数据集的70%~80%。通过训练集中的数据,模型可以学习到数据的特征和规律。
2. 验证集:验证集不用于训练模型或调整参数,而是用来评估模型的性能和鲁棒性。它帮助我们选择最优的模型和调整超参数。
3. 测试集:测试集是用于在模型训练和验证后,进一步评估模型在未知数据上的性能。由于测试集在整个模型训练过程中都没有参与,所以它能更客观地反映出模型在实际应用中的性能。
此外,为了充分利用有限的数据资源并防止过拟合,我们通常会采用交叉验证法来进行模型的训练和验证。这种方法通过将数据集分为k个子集,然后依次使用其中的k-1个子集作为训练集,剩下的一个子集作为验证集,从而得到更为准确和稳定的模型性能评估。
6.1.2、划分数据集的原因、作用及常用方法
深度学习训练划分数据集的原因、作用及常用方法如下:
1. 原因:
- 过拟合与欠拟合:通过划分数据集,我们可以更好地评估模型在未知数据上的表现,从而避免过拟合或欠拟合。
- 模型选择与调参:验证集和测试集不可用于模型参数的调试,所以需要从训练数据集中分离出一部分数据作为验证数据集用来调参。
2. 作用:
- 评估模型性能:通过划分数据集,我们可以更准确地评估模型在未知数据上的性能。
- 防止过拟合:合理的数据集划分可以帮助我们检测模型是否过拟合,从而及时调整模型结构或参数。
3. 常用方法:
- 按比例划分为训练集和测试集:这种方法也称为保留法,通常取8-2、7-3、6-4、5-5比例切分,直接将数据随机划分为训练集和测试集。
- 交叉验证法:交叉验证一般采用k折交叉验证,即k-fold cross validation,往往k取为10。在这种数据集划分法中,我们将数据集划分为k个子集,每个子集均做一次测试集,每次将其余的作为训练集。
- 训练集、验证集、测试集法:对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可。
总之,合理的数据集划分是深度学习训练中不可或缺的一步,它可以帮助我们更好地评估模型性能并防止过拟合等问题。
6.2、划分数据集常见示例
在深度学习中,训练模型需要将原始数据划分为训练集、验证集和测试集。以下是一般的数据集划分方法:
1. 训练集(Training Set):是模型训练的基础数据集,通常占数据集的70%~80%。模型通过训练集来学习特征和规律,以优化模型的性能。
2. 验证集(Validation Set):是用来调整模型中超参数(如学习率、正则化系数)的重要数据集,通常占数据集的10%~15%。通过对验证集的交叉验证,可以选出最优的模型参数。
3. 测试集(Test Set):是将训练好的模型测试性能的数据集,通常占数据集的10%~20%。测试集应该是被模型未曾见过的数据,以验证模型的泛化能力。
数据集的划分方法应该尽可能遵循数据的独立性和随机性,以减少数据间的相关性和模型的过拟合。同时,数据集的划分应该保证每个样本只出现在一个集合中,避免模型出现重复学习和过拟合的情况。
以下是一个简单的深度模型训练划分数据集的示例代码:
import numpy as np
from sklearn.model_selection import train_test_split
# 假设数据是一个二维数组 X 和一个一维数组 y
X = np.array(...) # shape: (n_samples, n_features)
y = np.array(...) # shape: (n_samples,)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 在训练集中再将数据划分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
# 确认数据尺寸
print("训练集数据尺寸:", X_train.shape)
print("验证集数据尺寸:", X_val.shape)
print("测试集数据尺寸:", X_test.shape)
首先,我们将数据集 X 和 y 加载到 numpy 数组中,并使用 sklearn 中的 train_test_split 函数将数据集划分为训练集和测试集。我们选择测试集占总数据集的 20%,随机种子为 42 (这样可以确保每次运行代码都会得到相同的结果)。
接下来,我们将训练集再次划分为训练集和验证集。这一步的目的是使用验证集来调整模型的超参数,比如 learning rate 或者正则化参数。同样选择验证集占总数据集的 20%,随机种子为 42。
最后,我们打印出每个数据集的尺寸来确认划分是否成功。
6.3、数据集划分实操演示
6.3.1、将数据集划分为训练集和验证集
import os
import random
def PartitionDataset(image_dir,train_ratio=0.9):
file_list=[]
for file in os.listdir(image_dir):
image_file=os.path.join(image_dir,file)
file_list.append(image_file)
random.shuffle(file_list)
train_count=int(len(file_list)*train_ratio)
train_list=file_list[:train_count]
val_list=file_list[train_count:]
with open('train.txt','w') as f:
f.write('\n'.join(train_list))
with open('val.txt','w') as f:
f.write('\n'.join(val_list))
image_dir=r'C:\Users\24491\Desktop\convert\images'
PartitionDataset(image_dir)
这段代码的功能是将指定目录下的图片文件进行随机划分,生成训练集和验证集。具体步骤如下:
1. 导入os和random模块。
2. 定义一个名为PartitionDataset的函数,接收两个参数:image_dir(图片目录)和train_ratio(训练集比例,默认为0.9)。
3. 在函数内部,首先创建一个空列表file_list,用于存储图片文件的路径。
4. 使用os.listdir()函数遍历image_dir目录下的所有文件,将每个文件的完整路径添加到file_list中。
5. 使用random.shuffle()函数对file_list进行随机打乱。
6. 根据train_ratio计算训练集的数量train_count。
7. 将file_list的前train_count个元素作为训练集,剩余的元素作为验证集。
8. 分别将训练集和验证集写入到'train.txt'和'val.txt'文件中,每个文件的每一行对应一个图片文件的路径。
9. 最后,调用PartitionDataset函数,传入图片目录image_dir进行数据集划分。
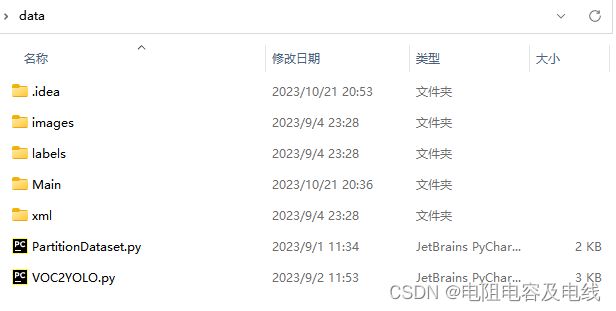
运行代码后实际输出结果如图所示(images文件夹存放数据集图片;xml文件夹存放VOC格式标注文件;labels文件夹存放转换后的YOLO格式标注文件;'train.txt'和'val.txt'为生成的训练集和验证集文件):

6.3.2、将数据集划分为训练集、验证集和测试集
import os
import random
import argparse
# 创建命令行参数解析器
parser = argparse.ArgumentParser()
# 添加输入XML标签路径的命令行参数
parser.add_argument('--xml_path', default='xml/', type=str, help='input xml label path')
# 添加输出txt标签路径的命令行参数
parser.add_argument('--txt_path', default='Main/', type=str, help='output txt label path')
opt = parser.parse_args()
# 设置训练集所占比例、验证集所占比例和测试集所占比例
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
# 获取XML文件路径和输出txt文件路径
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
# 如果输出txt文件路径不存在,则创建该目录
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
# 计算总的XML文件数量
num = len(total_xml)
# 生成一个包含所有XML文件索引的列表
list = list(range(num))
# 根据训练集比例计算训练集的数量
t_train = int(num * train_percent)
# 根据验证集比例计算验证集的数量
t_val = int(num * val_percent)
# 从列表中随机抽取训练集的索引
train = random.sample(list, t_train)
num1 = len(train)
for i in range(num1):
list.remove(train[i])
# 从剩余的列表中抽取验证集的索引
val_test = [i for i in list if not i in train]
val = random.sample(val_test, t_val)
num2 = len(val)
for i in range(num2):
list.remove(val[i])
# 打开训练集、验证集和测试集的txt文件
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
# 将训练集的XML文件名写入训练集的txt文件
for i in train:
name = total_xml[i][:-4] + '\n'
file_train.write(name)
# 将验证集的XML文件名写入验证集的txt文件
for i in val:
name = total_xml[i][:-4] + '\n'
file_val.write(name)
# 将测试集的XML文件名写入测试集的txt文件
for i in list:
name = total_xml[i][:-4] + '\n'
file_test.write(name)
# 关闭txt文件
file_train.close()
file_val.close()
file_test.close()
这段代码是一个用于将数据集划分为训练集、验证集和测试集的Python脚本。它使用了argparse库来解析命令行参数,指定了XML文件的路径和输出txt文件的路径。然后,根据给定的训练集比例、验证集比例和测试集比例,使用随机抽样的方法将数据集划分为三个部分。最后,将划分结果写入到相应的txt文件中。
这段代码首先通过argparse库解析命令行参数,获取XML文件的路径和输出txt文件的路径。然后,它计算出训练集、验证集和测试集的数量,并使用random库中的sample函数进行随机抽样。接下来,它将训练集、验证集和测试集的XML文件名分别写入到对应的txt文件中。最后,它关闭了打开的txt文件。
运行代码后实际输出结果如图所示(images文件夹存放数据集图片;xml文件夹存放VOC格式标注文件;labels文件夹存放转换后的YOLO格式标注文件;Main文件夹存放):